
多模態(tài)圖像版「GPT-3」來了!OpenAI推出DALL-E模型,一句話即可生成對應(yīng)圖像

??新智元報道??
??新智元報道??
來源:OpenAI
編輯:Q、小勻
【新智元導(dǎo)讀】OpenAI又放大招了!今天,其博客宣布,推出了兩個結(jié)合計算機視覺和NLP結(jié)合的多模態(tài)模型:DALL-E和CLIP,它們可以通過文本,直接生成對應(yīng)圖像,堪稱圖像版「GPT-3」。?









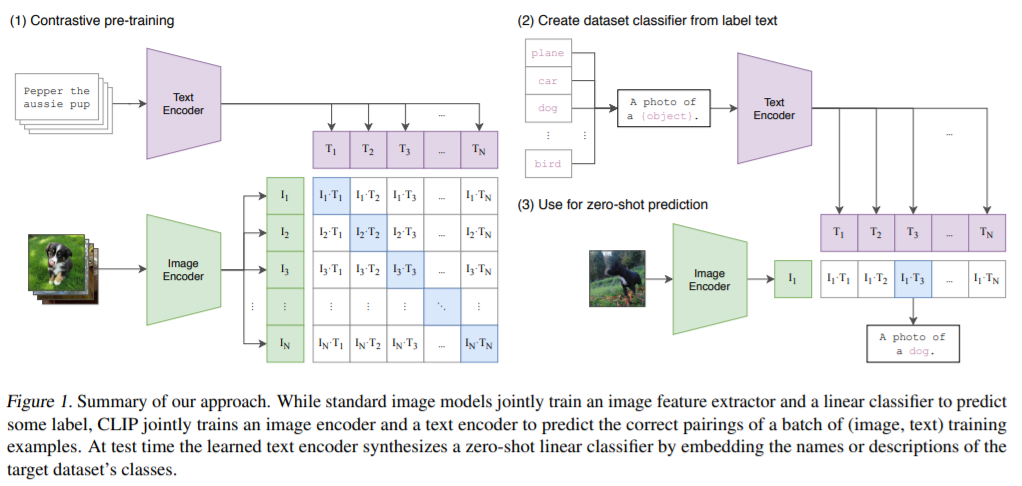
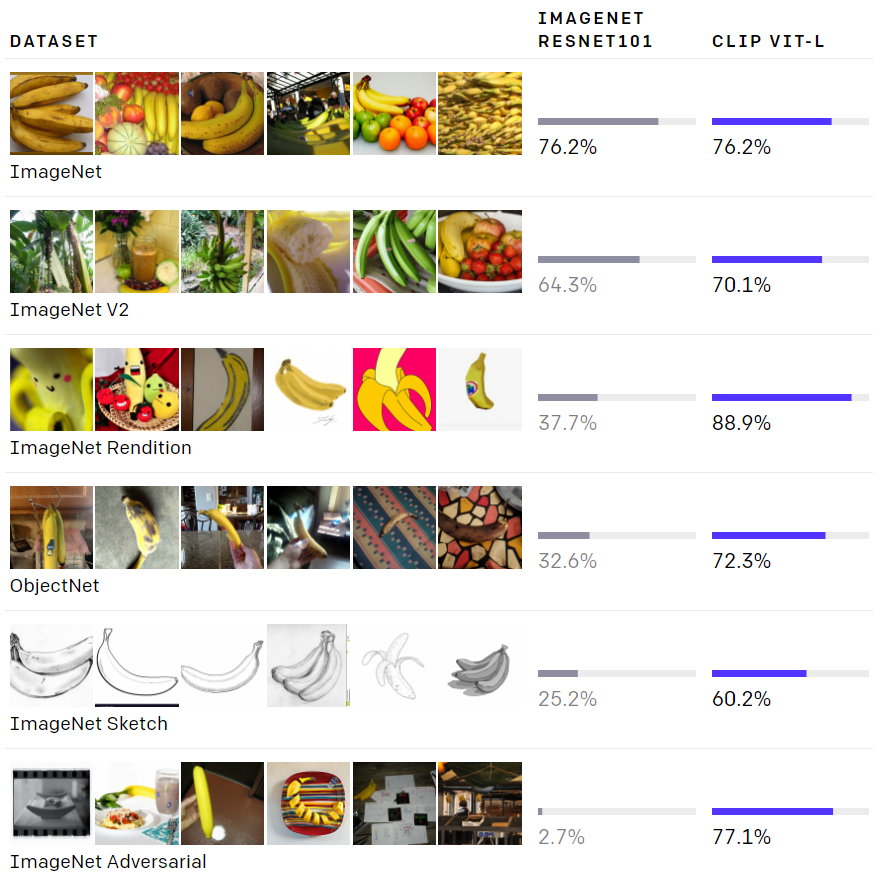
?
DALL-E和CLIP等類似的一系列生成模型,都具有模擬或扭曲現(xiàn)實來預(yù)測人們?nèi)绾卫L制風(fēng)景和靜物藝術(shù)的能力。比如StyleGAN,就表現(xiàn)出了種族偏見的傾向。
?
而從事CLIP和DALL-E的OpenAI研究人員呼吁對這兩個系統(tǒng)的潛在社會影響進行更多的研究。GPT-3顯示出顯著的黑人偏見,因此同樣的缺點也可存在于DALL-E中。在CLIP論文中包含的偏見測試發(fā)現(xiàn),該模型最有可能將20歲以下的人錯誤地歸類為罪犯或非人類,被歸類為男性的人相比女性更有可能被貼上罪犯的標簽,這表明數(shù)據(jù)集中包含的一些標簽數(shù)據(jù)存在嚴重的性別差異。
?
?
參考鏈接:
https://openai.com/blog/dall-e/


評論
圖片
表情