
從OpenAI發(fā)布DALL-E說(shuō)起,5年來(lái)圖像生成領(lǐng)域都有哪些大事

編譯:周熙
來(lái)源:ONEZERO
OpenAI因打造了一些A.I.行業(yè)最具未來(lái)感的產(chǎn)品雛形而名聲大噪。
這家由微軟支持的研究機(jī)構(gòu)現(xiàn)在由Y Combinator創(chuàng)始人Sam Altman領(lǐng)導(dǎo)。它最著名的是強(qiáng)大的文本生成器GPT-3,但在過(guò)去的幾年里,它還建立了一個(gè)教自己解魔方的機(jī)械手,一個(gè)像超人一樣的電子競(jìng)技算法團(tuán)隊(duì),一個(gè)能創(chuàng)作出令人感到舒適的音樂(lè)算法,以及能玩游戲和使用工具學(xué)習(xí)復(fù)雜策略的算法。
上周,OpenAI發(fā)布了DALL-E,這是一個(gè)可以根據(jù)書(shū)面文字生成圖像的A.I.系統(tǒng)。例如,針對(duì)提示 "一個(gè)牛油果形狀的皮包,一個(gè)模仿牛油果的皮包",該系統(tǒng)可以對(duì)牛油果皮包的想法生成幾十次迭代。
?
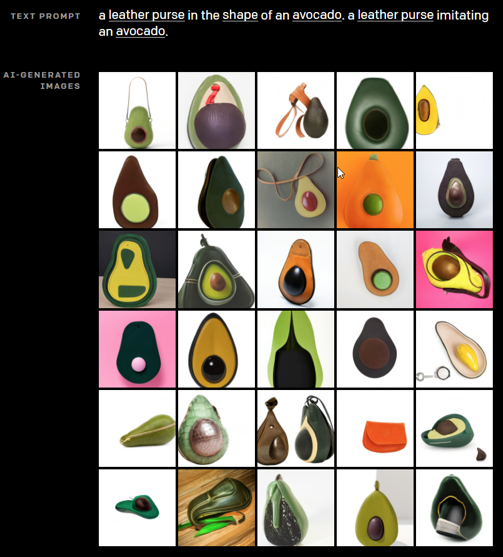
該公司還沒(méi)有向公眾甚至是它通常邀請(qǐng)?jiān)囉眯萝浖奶囟ㄩ_(kāi)發(fā)者群體提供DALL-E,但其網(wǎng)站上的例子表明,該系統(tǒng)可以創(chuàng)建極其逼真和清晰的圖像。該名稱(chēng)取自是薩爾瓦多-達(dá)利(Salvador Dalí)和WALL-E的混合體,DALL-E精通各種藝術(shù)風(fēng)格,包括插畫(huà)和風(fēng)景。它還可以生成文字來(lái)制作建筑物上的標(biāo)志,并分別劃分制作同一場(chǎng)景的草圖和全彩圖像。A.I.的研究人員將這種深遠(yuǎn)的能力稱(chēng)為泛化,這意味著該算法并不僅適用于特定任務(wù)或藝術(shù)風(fēng)格。
OpenAI將算法的熟練程度歸功于兩個(gè)主要因素。首先,該算法非常龐大。它使用了令人瞠目結(jié)舌的120億個(gè)參數(shù),這些參數(shù)可以被認(rèn)為是被算法轉(zhuǎn)動(dòng)的旋鈕,用來(lái)調(diào)整它如何理解想法。這120億個(gè)參數(shù)讓它在分析圖像和文本時(shí),可以學(xué)到不可思議的特征性。
然后,就是將這些圖片和文字材料輸入算法的方式。文字和圖像都被翻譯成算法更容易理解的tokens或文本。OpenAI在其關(guān)于DALL-E的博文中解釋說(shuō),tokens就像英文字母表中的字母一樣——它們以機(jī)器更容易計(jì)算的方式代表了零散的概念,并以一種為算法準(zhǔn)備的語(yǔ)言排列。這個(gè)機(jī)器字母表包含了16384個(gè)文本的標(biāo)記和8192個(gè)圖像的標(biāo)記。這種將人類(lèi)可讀的文字自動(dòng)翻譯成機(jī)器可讀的文字的方法被稱(chēng)為 "變換器模型"。
博文鏈接:
https://openai.com/blog/dall-e/
當(dāng)算法得到一個(gè)標(biāo)題,或圖像附帶的文字時(shí),它被翻譯成最多256個(gè)token,而圖像被翻譯成最多1,024個(gè)token。這使得該算法可以將相對(duì)較少的文字輸入與復(fù)雜得多的圖像進(jìn)行匹配。
該算法通過(guò)分析成對(duì)的圖像和標(biāo)題進(jìn)行學(xué)習(xí)。通過(guò)表層的數(shù)百萬(wàn)次迭代,它將文本片段與圖像的特定特征聯(lián)系起來(lái)。OpenAI還沒(méi)有公布這個(gè)數(shù)據(jù)集的大小,也沒(méi)有公布它包含哪些圖像。
該公司并不是第一個(gè)嘗試從文本生成圖像的公司,該算法也不是OpenAI的第一次嘗試。這只是這一類(lèi)算法中最新的、看起來(lái)能力最強(qiáng)的版本。雖然該公司還沒(méi)有發(fā)布描述該系統(tǒng)的論文,但該算法的創(chuàng)建者確實(shí)在其博客上引用了DALL-E的前身。通過(guò)對(duì)該算法的成長(zhǎng)歷程進(jìn)行可視化瀏覽,我們可以追溯該技術(shù)到底走了多遠(yuǎn)。
2016
這篇來(lái)自密歇根大學(xué)和Max Planck研究所的論文被OpenAI譽(yù)為振興當(dāng)前文本到圖像生成研究的論文,該論文使用生成式對(duì)抗網(wǎng)絡(luò),即GANs來(lái)生成圖像。GANs的功能是將兩種算法對(duì)立起來(lái)。一個(gè)用來(lái)生成圖像,另一個(gè)如果圖像看起來(lái)不夠真實(shí),就拒絕它。
論文鏈接:
https://arxiv.org/pdf/1605.05396.pdf
?

2017
一年后,Rutgers大學(xué)、Lehigh大學(xué)和香港中文大學(xué)的研究人員采取了另一種GAN方法——"疊加 "成對(duì)算法。第一對(duì)算法將場(chǎng)景的形狀和顏色鋪設(shè)出來(lái),第二對(duì)算法完善細(xì)節(jié)。
論文鏈接:
https://arxiv.org/pdf/1710.10916.pdf
?

2019
2019年,另一個(gè)主要隸屬于微軟的團(tuán)隊(duì)嘗試了一種不同的兩步法。第一步是生成一張物體在場(chǎng)景中的位置圖,第二步是以這張位置圖為指導(dǎo),生成物體,形成想要的畫(huà)面。
論文鏈接:
https://arxiv.org/pdf/1902.10740.pdf
?

2020
而在去年年底,Allen AI 研究所發(fā)表了一項(xiàng)研究,使用了一個(gè)與OpenAI相同的轉(zhuǎn)換器模型。Allen研究所的研究人員沒(méi)有去追求模型的純粹大小,而是依靠 "masking"。麻省理工學(xué)院科技評(píng)論的Karen Hao在一篇解釋該論文的大文章中進(jìn)一步詳細(xì)介紹了masking,他將masking描述為:"在句子中隱藏不同的單詞,并要求模型填入空白"。通過(guò)讓算法學(xué)習(xí)進(jìn)行這些直觀的跳躍,研究人員發(fā)現(xiàn),圖像生成的質(zhì)量得到了極大的提高。
研究論文鏈接:
https://arxiv.org/pdf/2009.11278.pdf
解釋文章鏈接:
https://www.technologyreview.com/2020/09/25/1008921/ai-allen-institute-generates-images-from-captions/

通過(guò)查看這些過(guò)去研究的例子,很明顯,OpenAI的DALL-E真的是一個(gè)很大的飛躍。OneZero專(zhuān)欄作家歐文-威廉姆斯(Owen Williams)說(shuō):“最先進(jìn)的技術(shù)已經(jīng)從生成可怕的斑點(diǎn)發(fā)展到了他真的會(huì)買(mǎi)的牛油果椅子。如果這沒(méi)有讓一代家具設(shè)計(jì)師,股票繪圖師和任何在線藝術(shù)家害怕,我不知道什么會(huì)。”
相關(guān)報(bào)道:

?
