
縮小規(guī)模,OpenAI文本生成圖像新模型GLIDE用35億參數(shù)媲美DALL-E
模型的參數(shù)規(guī)模并不需要那么大。





論文地址:https://arxiv.org/pdf/2112.10741.pdf
項(xiàng)目地址:https://github.com/openai/glide-text2im
首先,使用最終的 token 嵌入代替 ADM 模型中的類(lèi)嵌入;?
其次,最后一層的 token 嵌入(K 個(gè)特征向量序列)分別投影到 ADM 模型中每個(gè)注意力層,然后連接到每一層的注意力上下文。

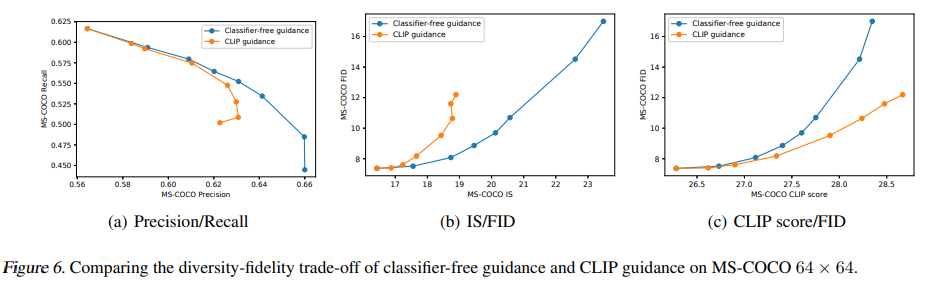
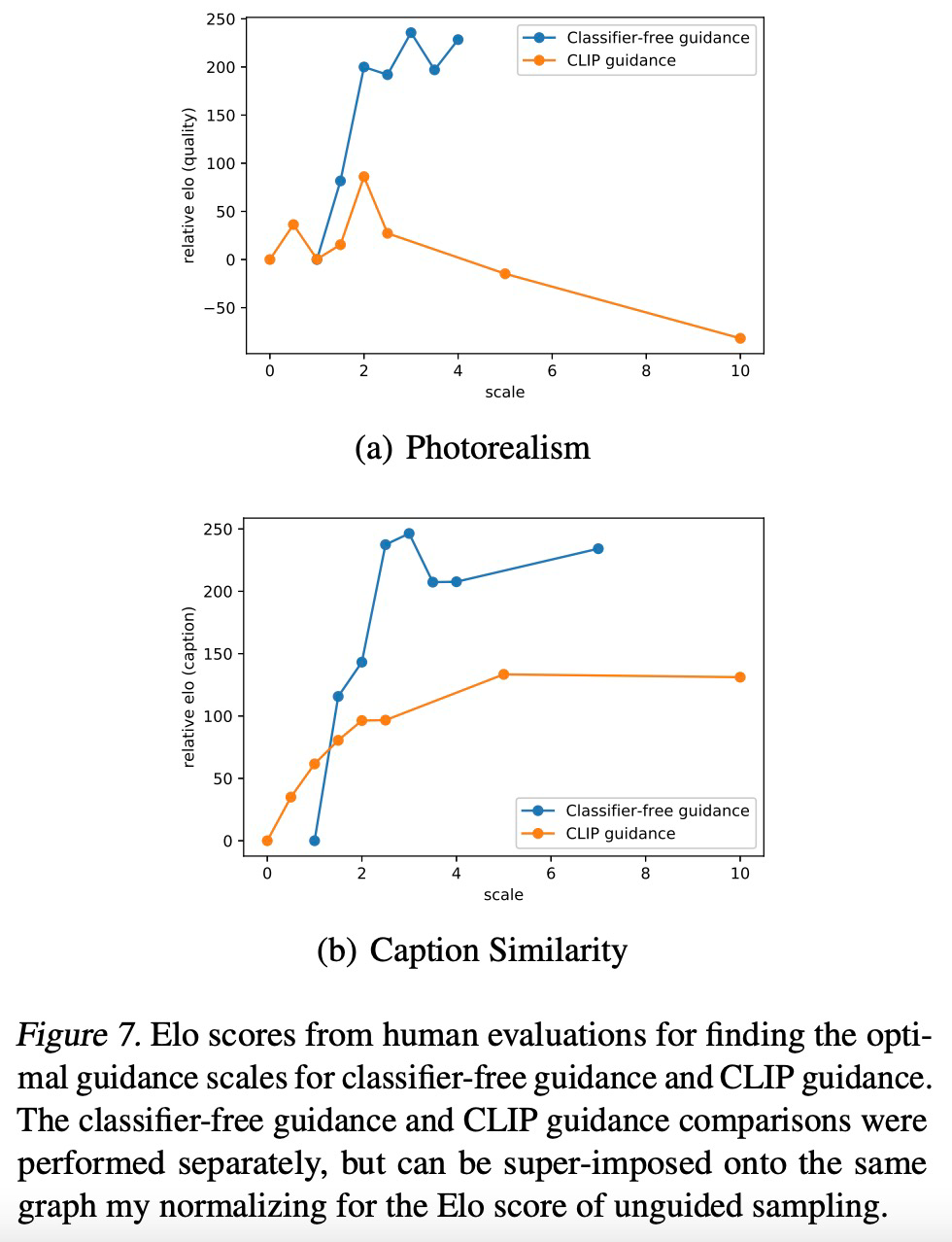

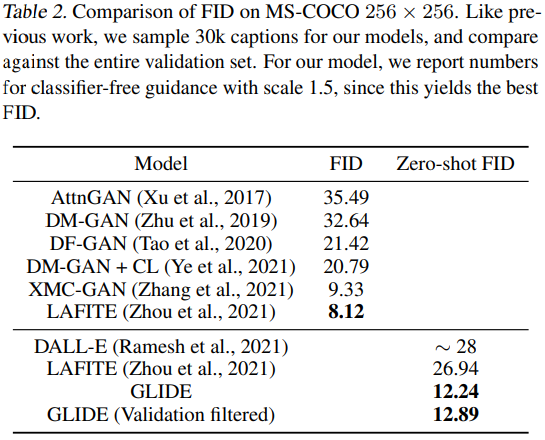
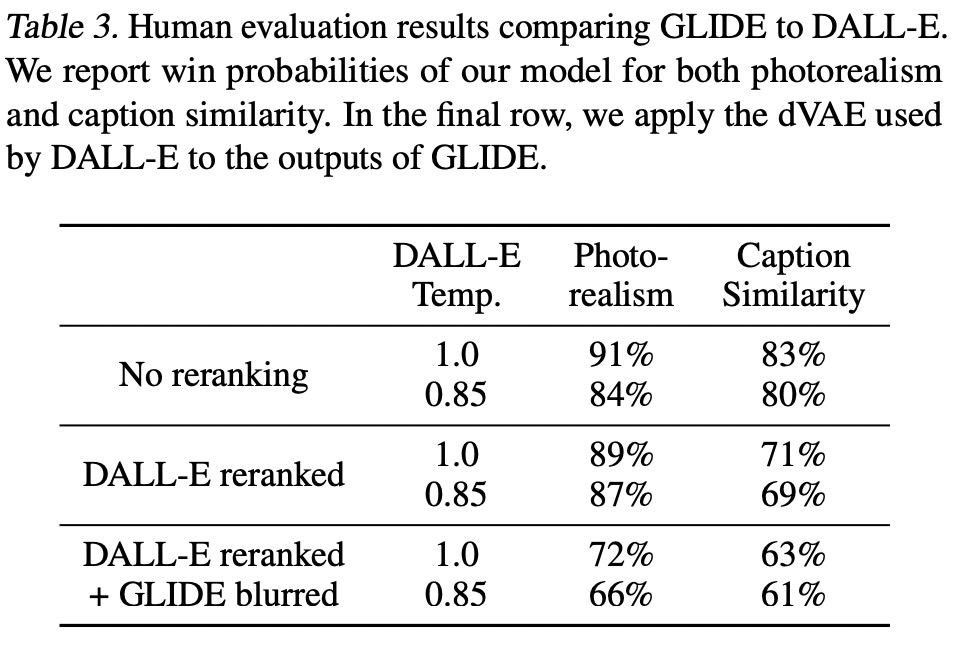
??THE END?
轉(zhuǎn)載請(qǐng)聯(lián)系原公眾號(hào)獲得授權(quán)
投稿或?qū)で髨?bào)道:[email protected]

點(diǎn)個(gè)在看 paper不斷!
評(píng)論
圖片
表情