
語言模型將了解視覺世界?OpenAI 120億參數(shù)圖像版GPT-3發(fā)布
↑ 點(diǎn)擊藍(lán)字?關(guān)注極市平臺
作者丨賈偉 夢佳來源丨智源社區(qū)編輯丨極市平臺
極市導(dǎo)讀
?OpenAI的聯(lián)合創(chuàng)始人IIya Sutskever 曾在吳恩達(dá)編輯的 《The Batch周刊 - 2020年終特刊》上撰文稱“2021年,語言模型將開始了解視覺世界”。元旦之后,OpenAI 立馬為這個說法提供了佐證。?>>加入極市CV技術(shù)交流群,走在計算機(jī)視覺的最前沿
- DALL·E:一個利用文本-圖像數(shù)據(jù)集,有著120億參數(shù)的“GPT-3”,可以根據(jù)文本生成各種各樣的圖像;
- CLIP:可以通過自然語言的監(jiān)督來有效學(xué)習(xí)視覺概念,只需要提供要識別的視覺類別名稱,利用CLIP便能夠做任意的視覺分類,類似于GPT-2和GPT-3的 “Zero-shot”功能。
這兩項工作的突破性是無疑的,但同時作為前奏,也讓人更加期待 OpenAI 接下來的 GPT-4了。
 ?輸入:鱷梨形狀的扶手椅輸出:?
?輸入:鱷梨形狀的扶手椅輸出:? ?輸入:寫著“ OpenAI”的店面輸出:?
?輸入:寫著“ OpenAI”的店面輸出:? ?GPT-3 給人們帶來的深刻印象是,大模型可以執(zhí)行各種文本生成任務(wù)。在ICML 2020 上的一篇論文“Image GPT”中,作者表明相同類型的神經(jīng)網(wǎng)絡(luò)也可以用于生成高保真度的圖像。作為對比,DALL·E 的研究說明了,通過自然語言便可以直接做各種圖像生成任務(wù)。?與 GPT-3一樣,DALL·E 是一個transformer 語言模型,它同時接收文本和圖像作為一個單一數(shù)據(jù)流,其中包含1280個tokens(256個文本,1024個圖像),并利用最大似然訓(xùn)練并生成所有的 tokens。模型中的 64 個 self-attention層,每一個都有attention mask,這能夠使每個image token都可以參與到 text token。DALL·E 對 text tokens 使用標(biāo)準(zhǔn)的因果掩碼,對行、列或卷積注意力模式的image token使用稀疏注意力,具體這取決于每一層的情況。?與利用 GAN來做文本到圖像的生成不同,DALL·E能夠為大量五花八門的句子創(chuàng)造出似是而非的意象,這些句子很多時候本身就是對語言結(jié)構(gòu)的探索。在生成之后,DALL·E采用 CLIP進(jìn)行排序,從中選取最優(yōu)結(jié)果,整個過程不需要進(jìn)行任何篩選。?OpenAI的研究人員對DALL·E的結(jié)果進(jìn)行了探索,包括:
?GPT-3 給人們帶來的深刻印象是,大模型可以執(zhí)行各種文本生成任務(wù)。在ICML 2020 上的一篇論文“Image GPT”中,作者表明相同類型的神經(jīng)網(wǎng)絡(luò)也可以用于生成高保真度的圖像。作為對比,DALL·E 的研究說明了,通過自然語言便可以直接做各種圖像生成任務(wù)。?與 GPT-3一樣,DALL·E 是一個transformer 語言模型,它同時接收文本和圖像作為一個單一數(shù)據(jù)流,其中包含1280個tokens(256個文本,1024個圖像),并利用最大似然訓(xùn)練并生成所有的 tokens。模型中的 64 個 self-attention層,每一個都有attention mask,這能夠使每個image token都可以參與到 text token。DALL·E 對 text tokens 使用標(biāo)準(zhǔn)的因果掩碼,對行、列或卷積注意力模式的image token使用稀疏注意力,具體這取決于每一層的情況。?與利用 GAN來做文本到圖像的生成不同,DALL·E能夠為大量五花八門的句子創(chuàng)造出似是而非的意象,這些句子很多時候本身就是對語言結(jié)構(gòu)的探索。在生成之后,DALL·E采用 CLIP進(jìn)行排序,從中選取最優(yōu)結(jié)果,整個過程不需要進(jìn)行任何篩選。?OpenAI的研究人員對DALL·E的結(jié)果進(jìn)行了探索,包括:?
1、控制同一個對象的不同屬性
?輸入:一個五角形的綠色鐘輸出:? ?
?2、同時控制多個對象以及它們的屬性和空間關(guān)系
?輸入:一個小企鵝的表情,身著藍(lán)帽子,紅手套,綠襯衫,黃褲子輸出: ?從上面生成的例子看,雖然大多數(shù)情況生成的圖片是符合要求的,但也有少量錯誤的案例。?雖然 DALL·E可以提供對少量對象屬性和位置的某種程度的可控性,但成功率似乎取決于文本的措辭。從上面幾個例子來看,隨著引入對象的增多,DALL·E 越來越容易混淆對象和顏色之間的關(guān)聯(lián),成功率也急劇下降。?作者提到,DALL·E對文本的措辭非常脆弱,有時候用語義上等價的標(biāo)題替代,會產(chǎn)生非常錯誤的結(jié)果。?
?從上面生成的例子看,雖然大多數(shù)情況生成的圖片是符合要求的,但也有少量錯誤的案例。?雖然 DALL·E可以提供對少量對象屬性和位置的某種程度的可控性,但成功率似乎取決于文本的措辭。從上面幾個例子來看,隨著引入對象的增多,DALL·E 越來越容易混淆對象和顏色之間的關(guān)聯(lián),成功率也急劇下降。?作者提到,DALL·E對文本的措辭非常脆弱,有時候用語義上等價的標(biāo)題替代,會產(chǎn)生非常錯誤的結(jié)果。?3、視覺透視與立體:控制場景的視點(diǎn),并渲染場景的 3D風(fēng)格
?輸入:一只用體素做成的水豚坐在田野里輸出:? ?
?4、內(nèi)部/外部結(jié)構(gòu)可視化
?輸入:核桃的橫截面圖輸出:? ?
?5、推斷背景細(xì)節(jié)
?將文本翻譯成圖像的任務(wù)具有不唯一性:給出一個文本,通常會有“無限多”中可能的圖像。例如,“日出時分,一只水豚坐在田野上”,根據(jù)水豚的方向,可能需要畫一個陰影,盡管這個細(xì)節(jié)在文本中并沒有被明確地提及。?輸入:日出時分,一只水豚坐在田野上輸出: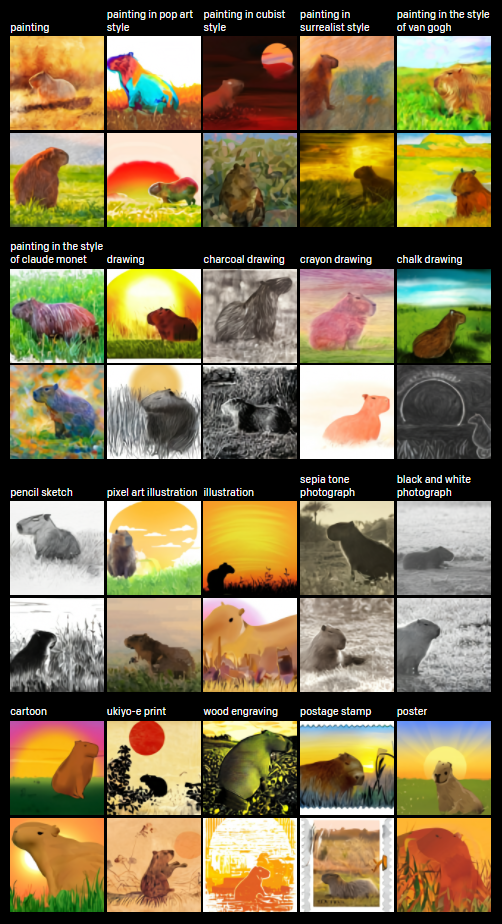 ?
?6、時裝設(shè)計、室內(nèi)設(shè)計
?輸入:一個穿著黑色皮夾克和金色百褶裙的女性模特輸出: ?輸入:起居室里有兩把白色扶手椅和一幅斗獸場的油畫,油畫被安裝在一個現(xiàn)代壁爐上方輸出:
?輸入:起居室里有兩把白色扶手椅和一幅斗獸場的油畫,油畫被安裝在一個現(xiàn)代壁爐上方輸出: ?
?7、將不相關(guān)的概念進(jìn)行結(jié)合
?語言的組合特性使我們能夠把完全不相關(guān)的概念放在一起,從而來描述真實的或想象的事物。利用DALL·E,可以將語言的這種特性快速地轉(zhuǎn)移到圖像上。?輸入:一只豎琴做的蝸牛輸出:? ??
??8、動物插圖
?除了真實世界中不相關(guān)概念之間結(jié)合外,在藝術(shù)創(chuàng)作里面,有大量的可探索空間:?輸入:一只長頸鹿和烏龜嵌合體輸出:? ?
?9、零樣本視覺推理
?GPT-3可以執(zhí)行多種任務(wù),根據(jù)描述和提示來生成答案,而不需要任何額外的培訓(xùn)。例如,當(dāng)提示語“ here is the sentence‘ a person walking his dog in the park’ translated into French: ”時,GPT-3回答“ un homme qui promène son chien dans le parc. ”這種能力稱為零樣本推理。DALL·E 可以將這種能力擴(kuò)展到視覺領(lǐng)域,并且能夠以正確的方式提示執(zhí)行圖像到圖像的轉(zhuǎn)換任務(wù)。?輸入:和上面的真貓一模一樣的貓的草圖輸出:?
 ?輸入:和上面第一列完全相同的茶壺,上面寫著“ gpt”輸出:?
?輸入:和上面第一列完全相同的茶壺,上面寫著“ gpt”輸出:? ?輸入:一系列的幾何圖形列表輸出:?
?輸入:一系列的幾何圖形列表輸出:? ?
?10、地理概念
?作者發(fā)現(xiàn) DALL·E ?已經(jīng)習(xí)得了地理知識、地標(biāo)和社區(qū)等概念。它對這些概念的了解在某些方面呈現(xiàn)出驚人的精確,而在其他方面又有一定缺陷。?輸入:一張中國菜的照片輸出:(有些食物看起來怪怪的)
 ?
?11、時間概念
?除了探索 DALL·E 對于不同空間的認(rèn)知,作者也探索了其對時間變化的認(rèn)知。?輸入:20年代電話的照片?
2 CLIP:零樣本學(xué)習(xí)神器?與DALL·E 一同發(fā)布的還有神經(jīng)網(wǎng)絡(luò)CLIP(對比式語言-圖像預(yù)訓(xùn)練,Contrastive Language–Image Pre-training)。?簡單來說,它可以從自然語言監(jiān)督中有效地學(xué)習(xí)視覺概念。CLIP 可適用于任何視覺分類基準(zhǔn),只需提供要識別的視覺類別的名稱,類似于 GPT-2和 GPT-3 的“零樣本學(xué)習(xí)”(zero-shot)能力。

1、方法
?如下圖所示,是CLIP的結(jié)構(gòu)圖:?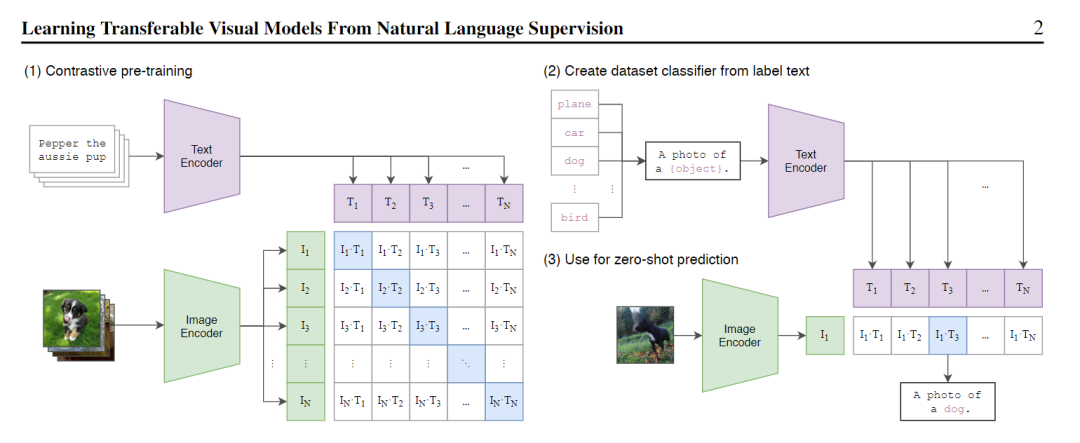 ?標(biāo)準(zhǔn)的圖像模型,聯(lián)合訓(xùn)練圖像特征提取器和線性分類器,預(yù)測一些標(biāo)簽。CLIP再聯(lián)合訓(xùn)練圖像編碼器和文本編碼器,從而預(yù)測一批(圖像,文本)對。在測試時,學(xué)習(xí)的文本編碼器通過嵌入目標(biāo)數(shù)據(jù)集類別的名稱或描述,來合成zero-shot線性分類器。?具體來說,作者使用了大量可用的監(jiān)管資源,包括文本和在網(wǎng)上能夠找到的圖像配對。利用這些數(shù)據(jù),CLIP可以訓(xùn)練出一個proxy,當(dāng)給定一張圖片時,便能預(yù)測在32768個隨機(jī)采樣的文本片段集中哪個片段更匹配。這里的方案是,CLIP模型將學(xué)習(xí)識別圖像中的多種視覺概念,然后將它們與圖像名字進(jìn)行關(guān)聯(lián)。?這種方式的結(jié)果是,CLIP模型在隨后可以應(yīng)用到幾乎任意的視覺分類任務(wù)當(dāng)中。?例如,如果數(shù)據(jù)集的任務(wù)是對“狗”和“貓”的圖像進(jìn)行分類,那么便可以針對每個圖像進(jìn)行檢查,確認(rèn)CLIP模型是否會預(yù)測響應(yīng)的文本“狗的照片”、“貓的照片”來與之配對。?
?標(biāo)準(zhǔn)的圖像模型,聯(lián)合訓(xùn)練圖像特征提取器和線性分類器,預(yù)測一些標(biāo)簽。CLIP再聯(lián)合訓(xùn)練圖像編碼器和文本編碼器,從而預(yù)測一批(圖像,文本)對。在測試時,學(xué)習(xí)的文本編碼器通過嵌入目標(biāo)數(shù)據(jù)集類別的名稱或描述,來合成zero-shot線性分類器。?具體來說,作者使用了大量可用的監(jiān)管資源,包括文本和在網(wǎng)上能夠找到的圖像配對。利用這些數(shù)據(jù),CLIP可以訓(xùn)練出一個proxy,當(dāng)給定一張圖片時,便能預(yù)測在32768個隨機(jī)采樣的文本片段集中哪個片段更匹配。這里的方案是,CLIP模型將學(xué)習(xí)識別圖像中的多種視覺概念,然后將它們與圖像名字進(jìn)行關(guān)聯(lián)。?這種方式的結(jié)果是,CLIP模型在隨后可以應(yīng)用到幾乎任意的視覺分類任務(wù)當(dāng)中。?例如,如果數(shù)據(jù)集的任務(wù)是對“狗”和“貓”的圖像進(jìn)行分類,那么便可以針對每個圖像進(jìn)行檢查,確認(rèn)CLIP模型是否會預(yù)測響應(yīng)的文本“狗的照片”、“貓的照片”來與之配對。?2、優(yōu)缺點(diǎn)
?CLIP的方法可以解決基于標(biāo)準(zhǔn)深度學(xué)習(xí)做計算機(jī)視覺所遇到的許多問題,例如:?數(shù)據(jù)集昂貴:深度學(xué)習(xí)需要大量人工標(biāo)注的數(shù)據(jù),這些數(shù)據(jù)集構(gòu)建的成本很高。ImageNet 需要超過25000名工作人員為22000個對象標(biāo)注1400萬張圖像;相比之下,CLIP 可以從互聯(lián)網(wǎng)上已經(jīng)公開可用的文本圖像中學(xué)習(xí)。?應(yīng)用范圍狹窄:在ImageNet 上訓(xùn)練的模型,即使可以預(yù)測1000個 ImageNet 類別,但也僅限于此,如果想要執(zhí)行其他新數(shù)據(jù)集上的任務(wù),就還需要進(jìn)行調(diào)整。相比之下,CLIP 可以適用于執(zhí)行各種各樣的視覺分類任務(wù),而不需要額外的訓(xùn)練示例。?現(xiàn)實場景中表現(xiàn)不佳:現(xiàn)有模型多能夠在實驗室環(huán)境中超過人類,但一旦部署到現(xiàn)實場景,性能便會大幅下降,原因在于模型僅通過優(yōu)化基準(zhǔn)性能來“欺騙”,就像一個通過僅研究過去幾年考試中的問題而通過考試的學(xué)生一樣。相反,CLIP模型可以根據(jù)基準(zhǔn)進(jìn)行評估,而無需訓(xùn)練其數(shù)據(jù),于是這種“欺騙”方式便不再存在。?當(dāng)然 CLIP 的局限性也很明顯,?- 它在較為抽象或者系統(tǒng)性的任務(wù)(例如計算圖像中的對象數(shù)量)和更為復(fù)雜的任務(wù)(例如預(yù)測圖像中最近的汽車有多遠(yuǎn))上,表現(xiàn)并不是很好,僅比隨機(jī)猜測好一點(diǎn)點(diǎn)。
- 對于訓(xùn)練集未覆蓋的圖像的概括性較差,例如盡管CLIP學(xué)習(xí)了更為復(fù)雜的OCR系統(tǒng)的數(shù)據(jù),但在對MNIST數(shù)據(jù)集進(jìn)行評估時,準(zhǔn)確率僅為88%(人類為99.95%)
- CLIP的zero-shot分類器對文本的措辭表現(xiàn)敏感。
代碼地址:
https://github.com/openai/CLIP
論文地址:
https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language.pdf
參考鏈接:
https://openai.com/blog/dall-e/
https://techcrunch.com/2021/01/05/openais-dall-e-creates-plausible-images-of-literally-anything-you-ask-it-to/
推薦閱讀
添加極市小助手微信(ID : cvmart2),備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳),即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群:每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
△長按添加極市小助手
△長按關(guān)注極市平臺,獲取最新CV干貨
覺得有用麻煩給個在看啦~??

評論
圖片
表情