
3D目標(biāo)檢測 | 視覺3D目標(biāo)檢測,從視覺幾何到BEV檢測
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號
重磅干貨,第一時(shí)間送達(dá)
作者丨Black@知乎
來源丨h(huán)ttps://zhuanlan.zhihu.com/p/541595850
編輯丨小書童
1. 前言
做為被動(dòng)傳感器的相機(jī),其感光元件僅接收物體表面反射的環(huán)境光,3D場景經(jīng)投影變換呈現(xiàn)在2D像平面上,成像過程深度信息丟失了。而當(dāng)我們僅有圖片時(shí),想要估計(jì)物體在真實(shí)3D場景中所處的位置,這將是一個(gè)欠約束的問題。
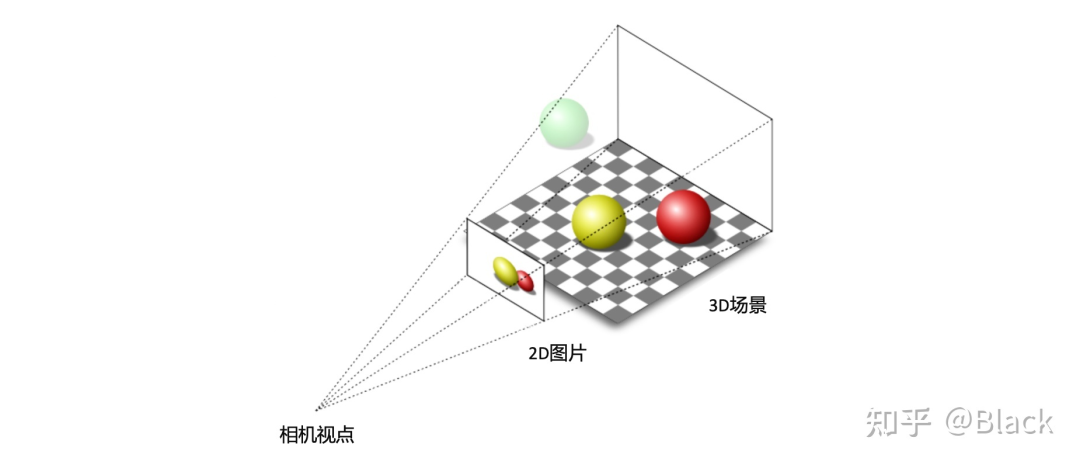
2. 幾何求解
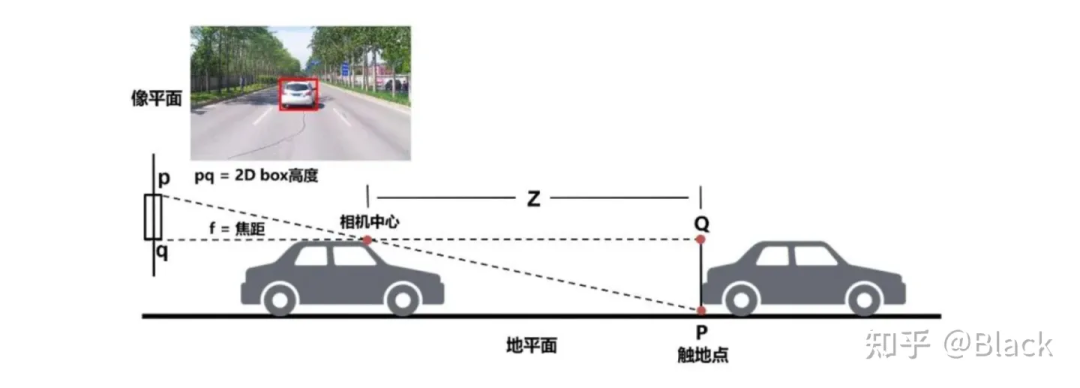
分類、2D目標(biāo)檢測等圖像任務(wù)已經(jīng)在工業(yè)界得到廣泛應(yīng)用,可以認(rèn)為是已經(jīng)解決了的問題,并且數(shù)據(jù)價(jià)格低廉。但2D目標(biāo)框無法滿足自動(dòng)駕駛、機(jī)器人等對障礙物有定位需求的領(lǐng)域。傳統(tǒng)算法利用2D檢測框的底部中心點(diǎn),基于平面假設(shè),求解近似三角形來獲得目標(biāo)離自車的距離。這類方法簡單輕量,數(shù)據(jù)驅(qū)動(dòng)的部分僅限于2D目標(biāo)檢測部分,但對地面有較強(qiáng)的假設(shè),面對車輛顛簸敏感(俯仰角變化),且對2D檢測框的完整性有較強(qiáng)的依賴。下圖來自apollo lite。
3. 單目3D目標(biāo)檢測
隨著標(biāo)注方法的升級,目標(biāo)的表示由原來的2D框?qū)屈c(diǎn)表示 進(jìn)化成了3D坐標(biāo)系下bounding box的表示 ,不同緯度表示了3D框的位置、尺寸、以及地面上的偏航角。有了數(shù)據(jù),原本用于2D檢測的深度神經(jīng)網(wǎng)絡(luò),也可以依靠監(jiān)督學(xué)習(xí)用于3D目標(biāo)框檢測。
這樣的3D數(shù)據(jù)業(yè)界目前主要有兩種獲取方式,一種是車輛除了配備了相機(jī),同時(shí)安裝了LiDAR這樣的3D傳感器,經(jīng)掃描,目標(biāo)輪廓以點(diǎn)云的形式被記錄下來,標(biāo)注員主要看點(diǎn)云來標(biāo)注。另一種是像特斯拉這樣僅配備相機(jī)的車輛,收集的只有圖像數(shù)據(jù),依靠多種交叉驗(yàn)證的離線算法,輔以人工來生成3D標(biāo)注數(shù)據(jù)。

焦距適中的相機(jī),F(xiàn)OV是有限的,想要檢測車身 目標(biāo),就要部署多個(gè)相機(jī),每個(gè)相機(jī)負(fù)責(zé)一定FOV范圍內(nèi)的感知。最終將各相機(jī)的檢測結(jié)果通過相機(jī)到車身的外參,轉(zhuǎn)換到統(tǒng)一的車輛坐標(biāo)系下。

但在有共視時(shí),會產(chǎn)生冗余檢測,即有多個(gè)攝像頭對同一目標(biāo)做了預(yù)測,現(xiàn)有方法,如FCOS3D,會在統(tǒng)一的坐標(biāo)系下對所有檢測結(jié)果做一遍NMS,有重合的目標(biāo)框僅留下一個(gè)分類指標(biāo)得分最高的。

冗余問題得到緩解,但要命的是被截?cái)嗟哪繕?biāo)往往在任一個(gè)相機(jī)里都只出現(xiàn)了一部分,多數(shù)情況是每個(gè)相機(jī)下的檢測質(zhì)量都堪憂。原因是多相機(jī)的圖片在深度神經(jīng)網(wǎng)絡(luò)是以 的形式傳遞的,傳統(tǒng)網(wǎng)絡(luò)中會有緯度 的特征間交互,也會有緯度 的空間交互,但唯獨(dú)沒有不同圖片間batch緯度的交互。簡單來說就是下圖中左邊圖片在檢測黑色客車時(shí),是無法用到右邊圖片的信息的。

4. 統(tǒng)一多視角相機(jī)的3D目標(biāo)檢測
4.1 看到哪算哪
自下而上的方法,手頭的信息看到哪算哪。下圖來自CaDNN這篇文章,很好的描述了這一類方法,包括Lift、BEVDet、BEVDepth。這類方法預(yù)測每個(gè)像素的深度/深度分布,有的方法隱式的預(yù)測,有的方法利用LiDAR點(diǎn)云當(dāng)監(jiān)督信號(推理時(shí)沒有LiDAR),雖然只用在訓(xùn)練階段,但不太能算在純視覺的方法里比較精度,工程使用的時(shí)候可能涉及部署車輛和數(shù)據(jù)采集車輛割裂的尷尬。總之,有了深度就可以由相機(jī)內(nèi)外參計(jì)算此像素在3D空間中的位置,然后把圖像特征塞入對應(yīng)位置。可以理解為由圖片生成3D“點(diǎn)云”,多視角相機(jī)形成的“點(diǎn)云”拼在一起,有了“點(diǎn)云”就可以利用現(xiàn)有的點(diǎn)云3D目標(biāo)檢測器了(如PointPillars, CenterPoint)。
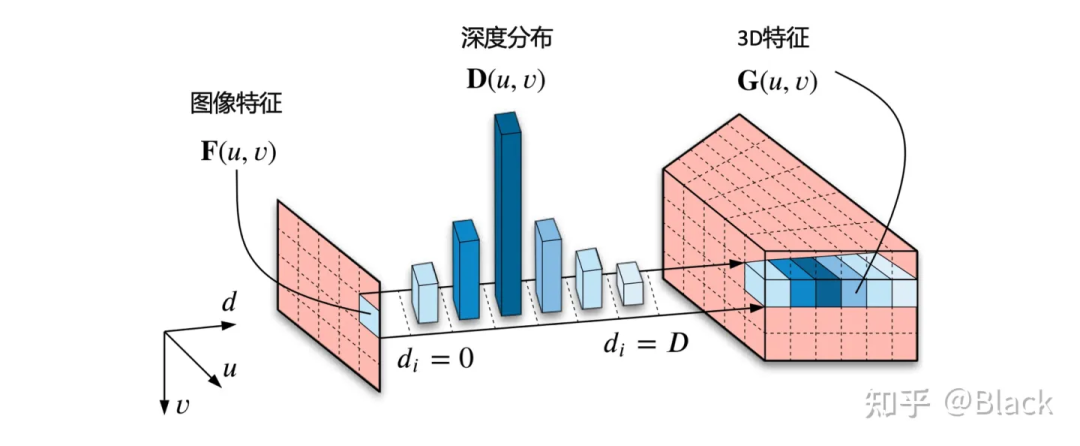
4.2 先決定看哪
自上而下的方法,先確定關(guān)注的地方(但可能手頭不寬裕,不配關(guān)注這個(gè)地方... 比如想關(guān)注自車后方,可后方視野完全被一輛大車遮擋了的情況)。關(guān)于這類的方法,下圖碰瓷一下特斯拉,簡單來說就是先確定空間中要關(guān)注的位置(圖中網(wǎng)格代表的車身周圍的地方),由這些位置去各個(gè)圖像中“搜集”特征,然后做判斷。根據(jù)“搜集”方式的不同衍生出了下面幾種方法。
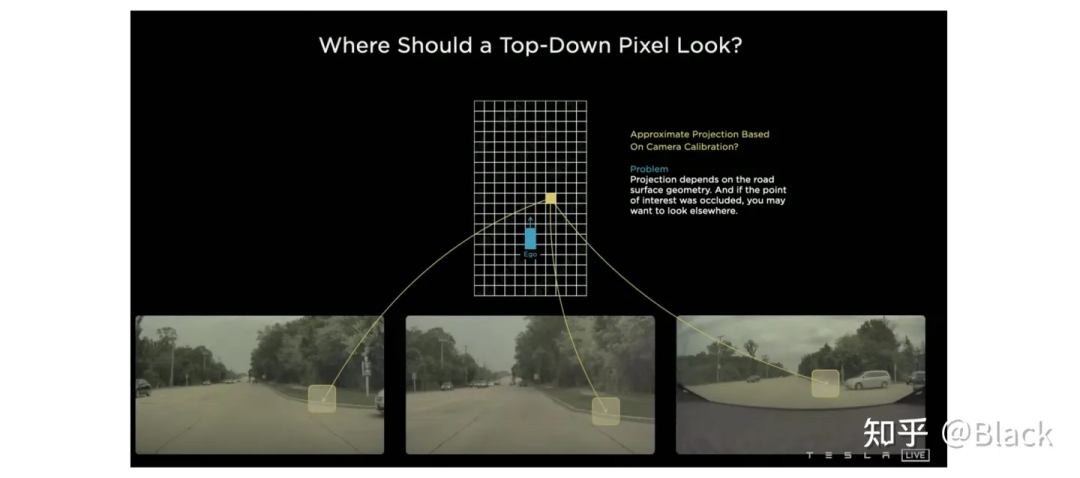
4.2.1 關(guān)鍵點(diǎn)采樣
下圖來自DETR3D,其作為將DETR框架用于3D目標(biāo)的先鋒工作,由一群可學(xué)習(xí)的3D空間中離散的位置(包含于object queries),根據(jù)相機(jī)內(nèi)外參轉(zhuǎn)換投影到圖片上,來索引圖像特征,每個(gè)3D位置僅對應(yīng)一個(gè)像素坐標(biāo)(會提取不同尺度特征圖的特征)。
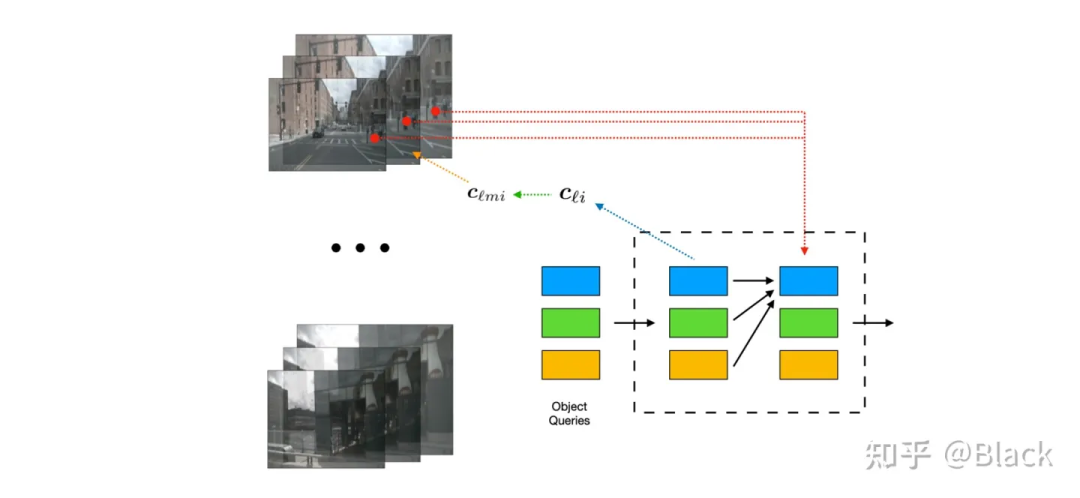
4.2.2 局部注意力
下圖來自BEVFormer,該方法預(yù)先生成稠密的空間位置(含不同的高度,且不隨訓(xùn)練更新),每個(gè)位置投影到各圖片后,會和投影位置局部的數(shù)個(gè)像素塊發(fā)生交互來提取特征(基于deformable detr),相比于DETR3D,每個(gè)3D點(diǎn)可以提取到了更多的特征。最終提取的3D稠密特征圖在高度緯度會被壓扁,形成一張BEV視角下稠密的2D特征圖,后續(xù)基于此特征圖做目標(biāo)檢測。BEVFormer相比DETR3D在精度上有提升(結(jié)構(gòu)上也多了額外的BEV decoders),在BEV視角下,目標(biāo)尺度被統(tǒng)一了,不會出現(xiàn)圖像視角下目標(biāo)近大遠(yuǎn)小的問題。一張稠密的BEV特征圖還可以做車道線檢測/道路分割等任務(wù),缺點(diǎn)是計(jì)算量大,顯存占用大。
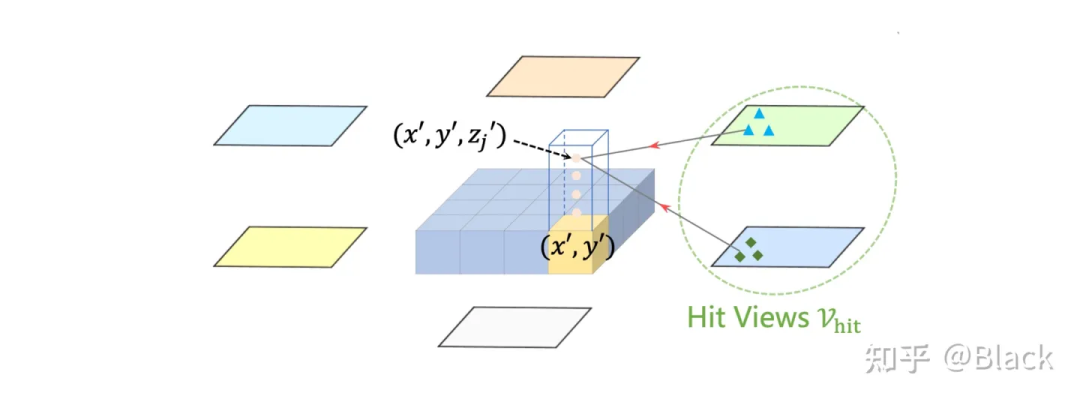
4.2.3 全局注意力
典型方法如PETR,該方法強(qiáng)調(diào)保持2D目標(biāo)檢測器DETR的框架,探索3D檢測需要做哪些適配。PETR同樣利用稀疏的3D點(diǎn)(來自object queries)來“搜索”圖像特征,但不像DETR3D或BEVFormer把3D點(diǎn)投影回圖片,而是基于標(biāo)準(zhǔn)的attention模塊,每個(gè)3D點(diǎn)會和來自全部圖片的所有像素交互。相似度(attention matrix)計(jì)算遵循 ,其中 來自object queries,里面包含的信息和3D bounding box的信息強(qiáng)相關(guān)(暫不討論query也包含的表觀信息),而 來自圖像(可以理解為和RGB信息強(qiáng)相關(guān),原生DETR中還會加入像素位置編碼),這兩個(gè)向量計(jì)算相似度缺乏可解釋性(直接訓(xùn)練也不怎么work)。可以理解為下圖描述的場景,很難說一個(gè)3D框和哪個(gè)像素相似。

PETR對矩陣下手,為每個(gè)像素編碼了3D位置相關(guān)的信息,使得相似度得以計(jì)算。實(shí)現(xiàn)上簡單來說是相機(jī)光心到像素的射線上每隔一段距離采樣一個(gè)點(diǎn)的 ,并轉(zhuǎn)換到query坐標(biāo)系下。相比之下,DETR3D和BEVFormer都遵循了deformable detr的方式,由query預(yù)測權(quán)重來加權(quán)“搜集”來的特征,規(guī)避掉了點(diǎn)積相似度的計(jì)算,PETR是正面硬剛這個(gè)問題了屬于是。下圖是PETR單位置編碼相似度效果圖(達(dá)到了跨相機(jī)相似的效果),只是這個(gè)相似度是“虛假”的,跟真實(shí)場景沒關(guān)系,也不會變化。很快,PETRv2中加上了圖像特征,效果也有提升。不過全局注意力算力消耗巨大,PETR只用了單尺度特征圖,一般顯卡還需利用混合精度、checkpoint等降顯存的方法才能訓(xùn)練起來。
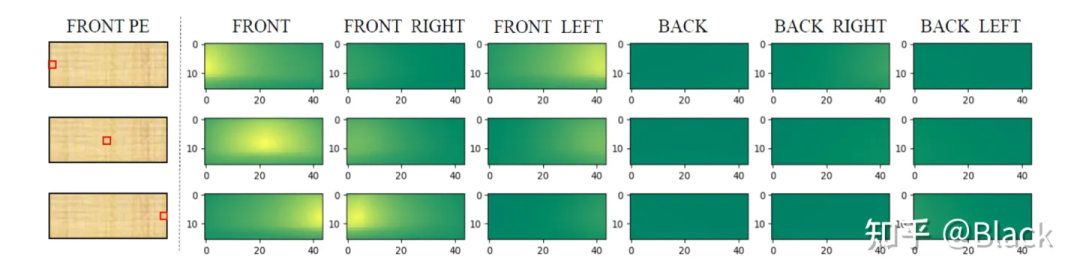
5. 參考文獻(xiàn)
[1] nuscenes: A multimodal dataset for autonomous driving. CVPR 2020.
[2] Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. ECCV 2020.
[3] Categorical Depth DistributionNetwork for Monocular 3D Object Detection. CVPR 2021.
[4] BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View. arXiv:2112.11790 2021.
[5] DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries. CoRL 2021.
[6] Deformable DETR: Deformable Transformers for End-to-End Object Detection. ICLR 2021.
[7] BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. ECCV 2022.
[8] Petr: Position embedding transformation for multi-view 3d object detection. ECCV 2022.
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。