
超參自動(dòng)優(yōu)化方法總結(jié)
本文旨在介紹當(dāng)前被大家廣為所知的超參自動(dòng)優(yōu)化方法,像網(wǎng)格搜索、隨機(jī)搜索、貝葉斯優(yōu)化和Hyperband,并附有相關(guān)的樣例代碼供大家學(xué)習(xí)。
一、網(wǎng)格搜索(Grid Search)
網(wǎng)格搜索是暴力搜索,在給定超參搜索空間內(nèi),嘗試所有超參組合,最后搜索出最優(yōu)的超參組合。sklearn已實(shí)現(xiàn)該方法,使用樣例如下:
from sklearn import svm, datasetsfrom sklearn.model_selection import GridSearchCVimport pandas as pd# 導(dǎo)入數(shù)據(jù)iris = datasets.load_iris()#?定義超參搜索空間parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}#?初始化模型svc = svm.SVC()#?網(wǎng)格搜索clf = GridSearchCV(estimator = svc,? ? ? ? ? ? ? ? ? param_grid = parameters,? ? ? ? ? ? ? ? ? scoring = 'accuracy',? ? ? ? ? ? ? ? ? n_jobs = -1,? ? ? ? ? ? ? ? ? cv = 5)clf.fit(iris.data, iris.target)返回:GridSearchCV(cv=5, estimator=SVC(), n_jobs=-1,? ? ? ? ? ? ? ? ? param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')},? ? ? ? ? ? ? ? ? scoring='accuracy')# 打印結(jié)果print('詳細(xì)結(jié)果:\n', pd.DataFrame.from_dict(clf.cv_results_))print('最佳分類器:\n', clf.best_estimator_)print('最佳分?jǐn)?shù):\n', clf.best_score_)print('最佳參數(shù):\n', clf.best_params_).返回:詳細(xì)結(jié)果:? ?mean_fit_time ?std_fit_time ?mean_score_time ?std_score_time param_C ?... split3_test_score split4_test_score ?mean_test_score ?std_test_score ?rank_test_score0 ? ? ? 0.000788 ? ? ?0.000394 ? ? ? ? 0.000194 ? ? ? ?0.000389 ? ? ? 1 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.980000 ? ? ? ?0.016330 ? ? ? ? ? ? ? ?11 ? ? ? 0.000804 ? ? ?0.000402 ? ? ? ? 0.000199 ? ? ? ?0.000399 ? ? ? 1 ?... ? ? ? ? ?0.933333 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.966667 ? ? ? ?0.021082 ? ? ? ? ? ? ? ?42 ? ? ? 0.000593 ? ? ?0.000484 ? ? ? ? 0.000593 ? ? ? ?0.000484 ? ? ?10 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.973333 ? ? ? ?0.038873 ? ? ? ? ? ? ? ?33 ? ? ? 0.000593 ? ? ?0.000484 ? ? ? ? 0.000399 ? ? ? ?0.000489 ? ? ?10 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.980000 ? ? ? ?0.016330 ? ? ? ? ? ? ? ?1[4 rows x 15 columns]最佳分類器:SVC(C=1, kernel='linear')最佳分?jǐn)?shù):0.9800000000000001最佳參數(shù):{'C': 1, 'kernel': 'linear'}
sklearn.model_selection.GridSearchCV[1]的重要參數(shù)說明:
estimator: scikit-learn模型。
param_grid: 超參搜索空間,即超參數(shù)字典。
scoring: 在交叉驗(yàn)證中使用的評(píng)估策略。
n_jobs: 并行任務(wù)數(shù),-1為使用所有CPU。
cv: 決定采用幾折交叉驗(yàn)證。
二、隨機(jī)搜索(Randomized Search)
隨機(jī)搜索是在搜索空間中采樣出超參組合,然后選出采樣組合中最優(yōu)的超參組合。隨機(jī)搜索的好處如下圖所示:
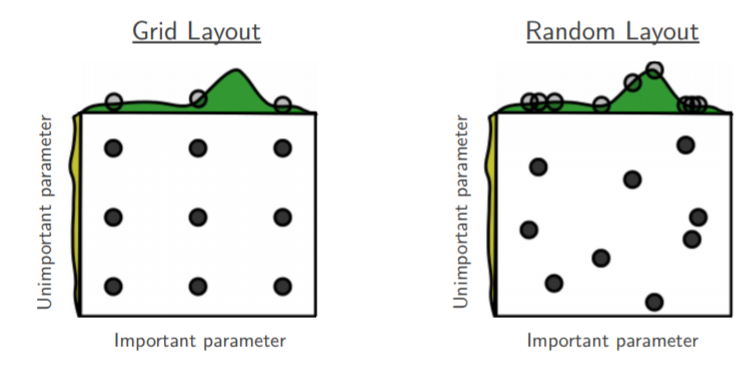
圖1: 網(wǎng)格搜索和隨機(jī)搜索的對(duì)比[2]
解釋圖1,如果目前我們要搜索兩個(gè)參數(shù),但參數(shù)A重要而另一個(gè)參數(shù)B并沒有想象中重要,網(wǎng)格搜索9個(gè)參數(shù)組合(A, B),而由于模型更依賴于重要參數(shù)A,所以只有3個(gè)參數(shù)值是真正參與到最優(yōu)參數(shù)的搜索工作中。反觀隨機(jī)搜索,隨機(jī)采樣9種超參組合,在重要參數(shù)A上會(huì)有9個(gè)參數(shù)值參與到搜索工作中,所以,在某些參數(shù)對(duì)模型影響較小時(shí),使用隨機(jī)搜索能讓我們有更多的探索空間。
同樣地,sklearn實(shí)現(xiàn)了隨機(jī)搜索[3],樣例代碼如下:
from sklearn import svm, datasetsfrom sklearn.model_selection import RandomizedSearchCVimport pandas as pdfrom scipy.stats import uniform# 導(dǎo)入數(shù)據(jù)iris?=?datasets.load_iris()# 定義超參搜索空間distributions?=?{'kernel':['linear',?'rbf'],?'C':uniform(loc=1,?scale=9)}# 初始化模型svc?=?svm.SVC()# 網(wǎng)格搜索clf = RandomizedSearchCV(estimator = svc,? ? ? ? ? ? ? ? ? ? ? ? param_distributions = distributions,? ? ? ? ? ? ? ? ? ? ? ? n_iter = 4,? ? ? ? ? ? ? ? ? ? ? ? scoring = 'accuracy',? ? ? ? ? ? ? ? ? ? ? ? cv = 5,? ? ? ? ? ? ? ? ? ? ? ? n_jobs = -1,? ? ? ? ? ? ? ? ? ? ? ? random_state = 2021)clf.fit(iris.data, iris.target)返回:RandomizedSearchCV(cv=5, estimator=SVC(), n_iter=4, n_jobs=-1,? ? ? ? ? ? ? ? ? ? ? ? param_distributions={'C':0x000001F372F9A190 >,? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?'kernel': ['linear', 'rbf']},? ? ? ? ? ? ? ? ? ? ? ? random_state=2021, scoring='accuracy')# 打印結(jié)果print('詳細(xì)結(jié)果:\n', pd.DataFrame.from_dict(clf.cv_results_))print('最佳分類器:\n', clf.best_estimator_)print('最佳分?jǐn)?shù):\n', clf.best_score_)print('最佳參數(shù):\n', clf.best_params_)返回:詳細(xì)結(jié)果:? ?mean_fit_time ?std_fit_time ?mean_score_time ?std_score_time ?param_C ?... split3_test_score split4_test_score ?mean_test_score ?std_test_score ?rank_test_score0 ? ? ? 0.000598 ? ? ?0.000489 ? ? ? ? 0.000200 ? ? ? ?0.000400 ? 6.4538 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.986667 ? ? ? ?0.016330 ? ? ? ? ? ? ? ?11 ? ? ? 0.000997 ? ? ?0.000002 ? ? ? ? 0.000000 ? ? ? ?0.000000 ?4.99782 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.980000 ? ? ? ?0.026667 ? ? ? ? ? ? ? ?32 ? ? ? 0.000798 ? ? ?0.000399 ? ? ? ? 0.000399 ? ? ? ?0.000488 ?3.81406 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.980000 ? ? ? ?0.016330 ? ? ? ? ? ? ? ?33 ? ? ? 0.000598 ? ? ?0.000488 ? ? ? ? 0.000200 ? ? ? ?0.000399 ?5.36286 ?... ? ? ? ? ?0.966667 ? ? ? ? ? ? ? 1.0 ? ? ? ? 0.986667 ? ? ? ?0.016330 ? ? ? ? ? ? ? ?1[4 rows x 15 columns]最佳分類器:SVC(C=6.453804509266643)最佳分?jǐn)?shù):0.9866666666666667最佳參數(shù):{'C': 6.453804509266643, 'kernel': 'rbf'}
相比于網(wǎng)格搜索,sklearn隨機(jī)搜索中主要改變的參數(shù)是param_distributions,負(fù)責(zé)提供超參值分布范圍。
三、貝葉斯優(yōu)化(Bayesian Optimization)
我寫本文的目的主要是沖著貝葉斯優(yōu)化來的,一直有所耳聞卻未深入了解,所以我就來查漏補(bǔ)缺了。以下內(nèi)容主要基于Duane Rich在《How does Bayesian optimization work?》[4]的回答。
調(diào)優(yōu)的目的是要找到一組最優(yōu)的超參組合,能使目標(biāo)函數(shù)f達(dá)到全局最小值。
假設(shè)我們的真實(shí)的目標(biāo)函數(shù)?
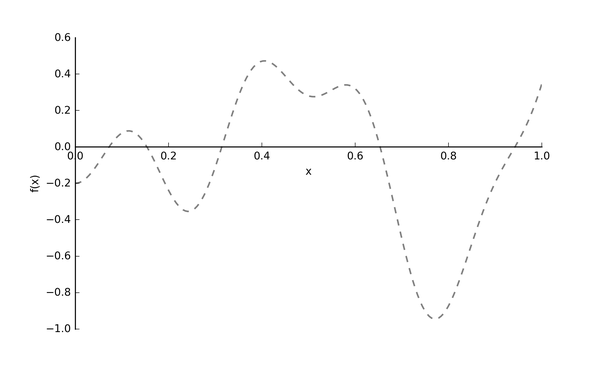
圖2: 目標(biāo)函數(shù)f(x)[4]
注意: 目標(biāo)函數(shù)?
現(xiàn)在,我們?cè)趺凑业?
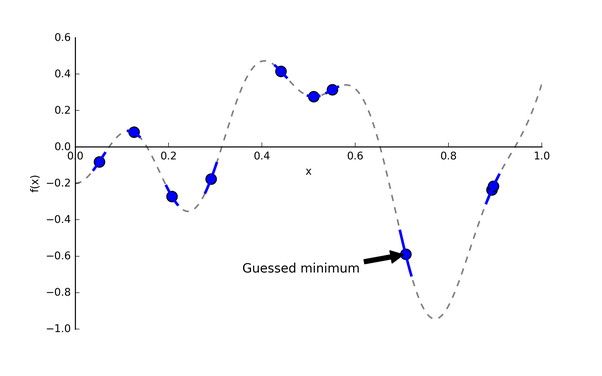
圖3: 隨機(jī)采樣10個(gè)點(diǎn)的目標(biāo)函數(shù)f(x)[4]
圖3里確實(shí)有個(gè)點(diǎn)挺靠近全局最優(yōu)點(diǎn)的,那是不是在它附近再采樣幾個(gè)點(diǎn),不斷重復(fù)就行了?沒那么簡(jiǎn)單,萬(wàn)一起始采樣點(diǎn)在局部最小值附近,那這種方法會(huì)很容易陷入局部最優(yōu)。關(guān)于“如何找到下一個(gè)合適的點(diǎn)”這個(gè)問題,我們先放一放,因?yàn)槲覀兟┑粢粋€(gè)重點(diǎn):每次嘗試一種超參值?
貝葉斯優(yōu)化使用了高斯過程(gasussian processes, GP)去構(gòu)建代理模型,高斯過程的細(xì)節(jié)這里暫時(shí)不講,有興趣的小伙伴可以自行查閱資料了解。基于給定的輸入和輸出,GP會(huì)推斷出一個(gè)模型(這里為代理模型)。假設(shè)我們從昂貴的?
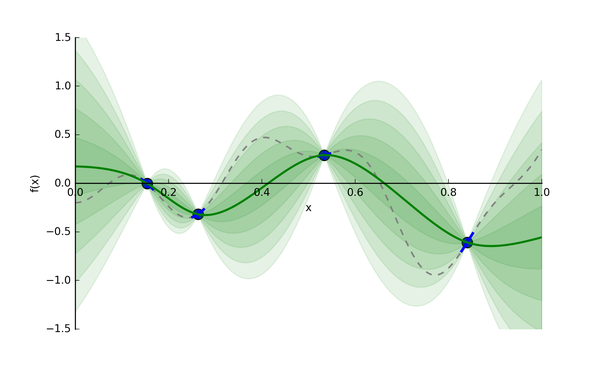
圖4: 目標(biāo)函數(shù)f(x)和代理模型[4]
綠色實(shí)線就是GP猜的代理模型,綠色條帶是輸出分布的標(biāo)準(zhǔn)差(即為Uncertainty)。我們有了代理模型,后續(xù)我們?nèi)フ蚁乱粋€(gè)合適的超參值,就能帶入到計(jì)算開銷相對(duì)較小的代理模型中,評(píng)估給定超參值的情況。
現(xiàn)在,我們來思考回之前提到的問題:"如何找到下一個(gè)合適的點(diǎn)?",這個(gè)問題本質(zhì)是在問:“哪里有全局最小的點(diǎn)?”,為了解決這個(gè)問題,我們要關(guān)注兩個(gè)地方:
(1) 已開發(fā)區(qū)域: 在綠色實(shí)線上最低的超參點(diǎn)。因?yàn)楹芸赡芩浇嬖谌肿顑?yōu)點(diǎn)。
(2) 未探索區(qū)域: 綠色實(shí)線上還未被探索的區(qū)域。比如圖4,相比于0.15-0.25區(qū)間,0.65-0.75區(qū)間更具有探索價(jià)值(即該區(qū)間Uncertainty更大)。探索該區(qū)域有利于減少我們猜測(cè)的方差。
為了實(shí)現(xiàn)以上探索和開發(fā)的平衡(exploration-exploitation trade-off),貝葉斯優(yōu)化使用了采集函數(shù)(acquisition function),它能平衡好全局最小值的探索和開發(fā)。采集函數(shù)有很多選擇,其中最常見的是expectated of improvement(EI)[5],我們先看一個(gè)utility function:
具有最高的EI的超參值?
(1) 減少均值函數(shù)?
(2) 增加方差?
所以EI的提高是建立在均值和方差的trade-off,也是exploration和exploitation的trade-off。
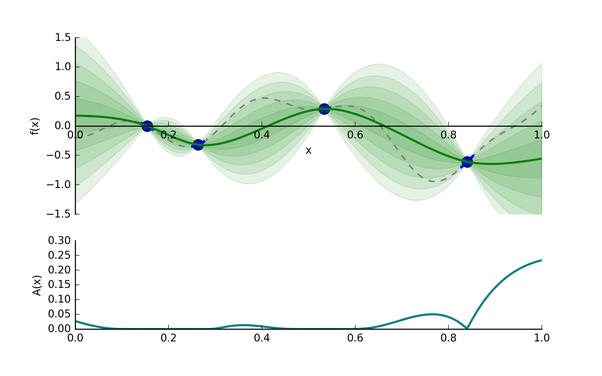
圖5: 采集函數(shù)A(x)
圖5我們可以看到,?
講到這里,我們來看下完整的貝葉斯優(yōu)化步驟是怎樣的:

圖6: 貝葉斯優(yōu)化-SMBO
SMBO是簡(jiǎn)潔版的貝葉斯優(yōu)化,偽代碼如圖6所示,具體如下:
(1) 準(zhǔn)備輸入: expensive blackbox function ?
(2) 基于?
(3) 循環(huán)選?
用當(dāng)前數(shù)據(jù)集?
?擬合代理模型? ?,實(shí)現(xiàn)模型更新。 選擇使采集函數(shù)?
?最大的超參組合? ?。 將?
?帶入? ?中,得到輸出值? ?。(注意這里? ?的計(jì)算開銷大) 將新的?
?加入到現(xiàn)有數(shù)據(jù)集? ?中。
目前,Hyperopt[6]開源代碼庫(kù)已實(shí)現(xiàn)基于TPE(Tree-structured Parzen Estimator Approach)的貝葉斯優(yōu)化,圖6我們能看到GP構(gòu)建的概率模型是?
from sklearn import svm, datasetsfrom sklearn.model_selection import cross_val_scorefrom hyperopt import hp, fmin, tpe, space_evalimport pandas as pd# 導(dǎo)入數(shù)據(jù)iris = datasets.load_iris()# step1: 定義目標(biāo)函數(shù)def objective(params):? ? ?# 初始化模型并交叉驗(yàn)證? ? ?svc = svm.SVC(**params)? ? ?cv_scores = cross_val_score(svc, iris.data, iris.target, cv=5)? ? ?# 返回loss = 1 - accuracy (loss必須被最小化)? ? ?loss = 1 - cv_scores.mean()? ? ?return loss# step2: 定義超參搜索空間space = {'kernel':hp.choice('kernel', ['linear', 'rbf']),? ? ? ? 'C':hp.uniform('C', 1, 10)}# step3: 在給定超參搜索空間下,最小化目標(biāo)函數(shù)best = fmin(objective, space, algo=tpe.suggest, max_evals=100)返回: best_loss: 0.013333333333333308(即accuracy為0.9866666666666667)# step4: 打印結(jié)果print(best)返回:{'C': 6.136181888987526, 'kernel': 1}(PS:kernel為0-based index,這里1指rbf)
四、Hyperband
除了格子搜索、隨機(jī)搜索和貝葉斯優(yōu)化,還有其它自動(dòng)調(diào)參方式。例如Hyperband optimization[8],Hyperband本質(zhì)上是隨機(jī)搜索的一種變種,它使用早停策略和Sccessive Halving算法去分配資源,結(jié)果是Hyperband能評(píng)估更多的超參組合,同時(shí)在給定的資源預(yù)算下,比貝葉斯方法收斂更快,下圖展示了Hyperband的早停和資源分配:
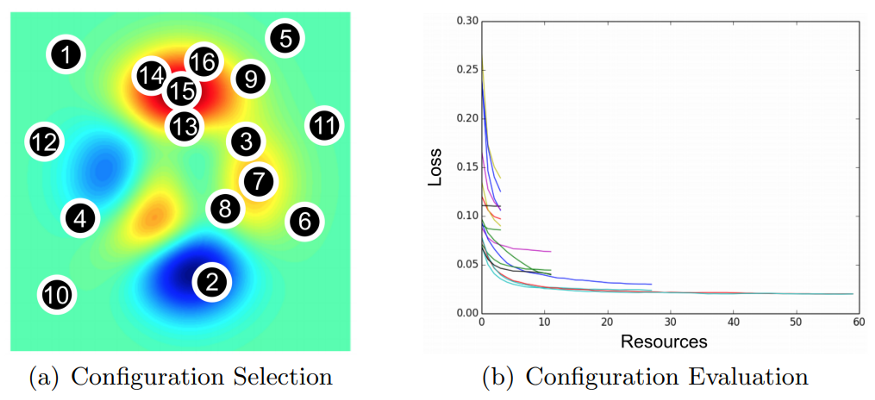
圖7: Hyperband的超參選擇和評(píng)估
在Hyperband之后,還出現(xiàn)了BOHB,它混合了貝葉斯優(yōu)化和Hyperband。Hyperband和BOHB的開源代碼可參考HpBandSter庫(kù)[9],這里不展開細(xì)講。
五、總結(jié)
上面我們用Iris鳶尾花數(shù)據(jù)集試了不同的超參自動(dòng)調(diào)優(yōu)方法,發(fā)現(xiàn)貝葉斯優(yōu)化和隨機(jī)搜索都比格子搜索好。從一些論文反映,貝葉斯優(yōu)化是更香的,但是貝葉斯優(yōu)化好像在實(shí)踐中用的不是那么多,網(wǎng)上也有很多分享者,像Nagesh Singh Chauhan,說的那樣:
As?a?general?rule?of?thumb,?any?time?you?want?to?optimize?tuning?hyperparameters,?think?Grid?Search?and?Randomized?Search! [10]
Hyperparameter Optimization for Machine Learning Models - Nagesh Singh Chauhan
為什么呢?我想原因是貝葉斯的開銷太大了,前面有提到,在每次循環(huán)選超參值的時(shí)候,貝葉斯優(yōu)化都需要將?
寫這篇文章的過程中,我主要學(xué)到了2點(diǎn),一是隨機(jī)搜索在某些時(shí)候會(huì)比格子搜索好,二是了解貝葉斯優(yōu)化的機(jī)理。這里,談?wù)勎冶荣惡蛡€(gè)人實(shí)踐中的體會(huì),我很少會(huì)花過多時(shí)間在超參的調(diào)優(yōu)上,因?yàn)樗鼛淼氖找媸怯邢薜模芏鄷r(shí)候比起壓榨模型來說,思考和挖掘數(shù)據(jù)特征能帶來更多的收益,所以我想這也是為什么上面說:在任何想要調(diào)優(yōu)超參時(shí),先用格子搜索或隨機(jī)搜索吧。總之,希望這篇文章對(duì)大家有幫助,我們下期再見~
參考資料
[1]??sklearn.model_selection.GridSearchCV, 官方文檔: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
[2] Bergstra, J., & Bengio, Y. (2012). Random search for hyper-parameter optimization. Journal of machine learning research, 13(2).
[3] sklearn.model_selection.RandomizedSearchCV, 官方文檔: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html#sklearn.model_selection.RandomizedSearchCV
[4] Quora: How does Bayesian optimization work? - Duane Rich, 回答: https://www.quora.com/How-does-Bayesian-optimization-work
[5] Bayesian Optimization (2018). - Cse.wustl.edu. 課程N(yùn)ote: https://www.cse.wustl.edu/~garnett/cse515t/spring_2015/files/lecture_notes/12.pdf
[6] Hyperopt: Distributed Hyperparameter Optimization, 代碼: https://github.com/hyperopt/hyperopt#getting-started
[7] Bergstra, J., Bardenet, R., Bengio, Y., & Kégl, B. (2011, December). Algorithms for hyper-parameter optimization. In 25th annual conference on neural information processing systems (NIPS 2011) (Vol. 24). Neural Information Processing Systems Foundation.
[8] Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., & Talwalkar, A. (2017). Hyperband: A novel bandit-based approach to hyperparameter optimization. The Journal of Machine Learning Research, 18(1), 6765-6816.
[9] HpBandSter開源代碼庫(kù), 代碼: https://github.com/automl/HpBandSte
[10] Hyperparameter Optimization for Machine Learning Models - Nagesh Singh Chauhan, 文章: [https://www.kdnuggets.com/2020/05/hyperparameter-optimization-machine-learning-models.html
[11] 為什么基于貝葉斯優(yōu)化的自動(dòng)調(diào)參沒有大范圍使用?- 知乎, 問答: https://www.zhihu.com/question/33711002