
HiveSQL常用優(yōu)化方法全面總結(jié)
Hive作為大數(shù)據(jù)領(lǐng)域常用的數(shù)據(jù)倉庫組件,在平時設(shè)計和查詢時要特別注意效率。影響Hive效率的幾乎從不是數(shù)據(jù)量過大,而是數(shù)據(jù)傾斜、數(shù)據(jù)冗余、job或I/O過多、MapReduce分配不合理等等。對Hive的調(diào)優(yōu)既包含對HiveQL語句本身的優(yōu)化,也包含Hive配置項(xiàng)和MR方面的調(diào)整。
目錄
列裁剪和分區(qū)裁剪
謂詞下推
sort by代替order by
group by代替distinct
group by配置調(diào)整
map端預(yù)聚合
傾斜均衡配置項(xiàng)
join基礎(chǔ)優(yōu)化
build table(小表)前置
多表join時key相同
利用map join特性
分桶表map join
傾斜均衡配置項(xiàng)
優(yōu)化SQL處理join數(shù)據(jù)傾斜
空值或無意義值
單獨(dú)處理傾斜key
不同數(shù)據(jù)類型
build table過大
MapReduce優(yōu)化
調(diào)整mapper數(shù)
調(diào)整reducer數(shù)
合并小文件
啟用壓縮
JVM重用
并行執(zhí)行與本地模式
嚴(yán)格模式
采用合適的存儲格式

-??列裁剪和分區(qū)裁剪?-
最基本的操作。所謂列裁剪就是在查詢時只讀取需要的列,分區(qū)裁剪就是只讀取需要的分區(qū)。以我們的日歷記錄表為例:
select uid,event_type,record_data
from calendar_record_log
where pt_date >= 20190201 and pt_date <= 20190224
and status = 0;當(dāng)列很多或者數(shù)據(jù)量很大時,如果select *或者不指定分區(qū),全列掃描和全表掃描效率都很低。
Hive中與列裁剪優(yōu)化相關(guān)的配置項(xiàng)是hive.optimize.cp,與分區(qū)裁剪優(yōu)化相關(guān)的則是hive.optimize.pruner,默認(rèn)都是true。在HiveQL解析階段對應(yīng)的則是ColumnPruner邏輯優(yōu)化器。
-??謂語下推?-
在關(guān)系型數(shù)據(jù)庫如MySQL中,也有謂詞下推(Predicate Pushdown,PPD)的概念。它就是將SQL語句中的where謂詞邏輯都盡可能提前執(zhí)行,減少下游處理的數(shù)據(jù)量。
例如以下HiveQL語句:
select a.uid,a.event_type,b.topic_id,b.title
from calendar_record_log a
left outer join (
select uid,topic_id,title from forum_topic
where pt_date = 20190224 and length(content) >= 100
) b on a.uid = b.uid
where a.pt_date = 20190224 and status = 0;對forum_topic做過濾的where語句寫在子查詢內(nèi)部,而不是外部。Hive中有謂詞下推優(yōu)化的配置項(xiàng)hive.optimize.ppd,默認(rèn)值true,與它對應(yīng)的邏輯優(yōu)化器是PredicatePushDown。該優(yōu)化器就是將OperatorTree中的FilterOperator向上提,見下圖。
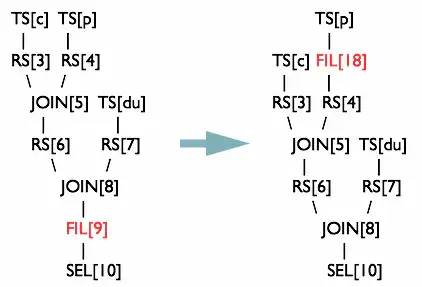
圖來自https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
上面的鏈接中是一篇講解HiveQL解析與執(zhí)行過程的好文章,前文提到的優(yōu)化器、OperatorTree等概念在其中也有詳細(xì)的解釋,非常推薦。
sort by代替order by
HiveQL中的order by與其他SQL方言中的功能一樣,就是將結(jié)果按某字段全局排序,這會導(dǎo)致所有map端數(shù)據(jù)都進(jìn)入一個reducer中,在數(shù)據(jù)量大時可能會長時間計算不完。
如果使用sort by,那么還是會視情況啟動多個reducer進(jìn)行排序,并且保證每個reducer內(nèi)局部有序。為了控制map端數(shù)據(jù)分配到reducer的key,往往還要配合distribute by一同使用。如果不加distribute by的話,map端數(shù)據(jù)就會隨機(jī)分配到reducer。
舉個例子,假如要以UID為key,以上傳時間倒序、記錄類型倒序輸出記錄數(shù)據(jù):
select uid,upload_time,event_type,record_data
from calendar_record_log
where pt_date >= 20190201 and pt_date <= 20190224
distribute by uid
sort by upload_time desc,event_type desc;group by代替distinct
當(dāng)要統(tǒng)計某一列的去重數(shù)時,如果數(shù)據(jù)量很大,count(distinct)就會非常慢,原因與order by類似,count(distinct)邏輯只會有很少的reducer來處理。這時可以用group by來改寫:
select count(1) from (
select uid from calendar_record_log
where pt_date >= 20190101
group by uid
) t;但是這樣寫會啟動兩個MR job(單純distinct只會啟動一個),所以要確保數(shù)據(jù)量大到啟動job的overhead遠(yuǎn)小于計算耗時,才考慮這種方法。當(dāng)數(shù)據(jù)集很小或者key的傾斜比較明顯時,group by還可能會比distinct慢。
那么如何用group by方式同時統(tǒng)計多個列?下面是解決方法:
select t.a,sum(t.b),count(t.c),count(t.d) from (
select a,b,null c,null d from some_table
union all
select a,0 b,c,null d from some_table group by a,c
union all
select a,0 b,null c,d from some_table group by a,d
) t;group by配置調(diào)整
map端預(yù)聚合
group by時,如果先起一個combiner在map端做部分預(yù)聚合,可以有效減少shuffle數(shù)據(jù)量。預(yù)聚合的配置項(xiàng)是hive.map.aggr,默認(rèn)值true,對應(yīng)的優(yōu)化器為GroupByOptimizer,簡單方便。
通過hive.groupby.mapaggr.checkinterval參數(shù)也可以設(shè)置map端預(yù)聚合的行數(shù)閾值,超過該值就會分拆job,默認(rèn)值100000。
傾斜均衡配置項(xiàng)
group by時如果某些key對應(yīng)的數(shù)據(jù)量過大,就會發(fā)生數(shù)據(jù)傾斜。Hive自帶了一個均衡數(shù)據(jù)傾斜的配置項(xiàng)hive.groupby.skewindata,默認(rèn)值false。
其實(shí)現(xiàn)方法是在group by時啟動兩個MR job。第一個job會將map端數(shù)據(jù)隨機(jī)輸入reducer,每個reducer做部分聚合,相同的key就會分布在不同的reducer中。第二個job再將前面預(yù)處理過的數(shù)據(jù)按key聚合并輸出結(jié)果,這樣就起到了均衡的效果。
但是,配置項(xiàng)畢竟是死的,單純靠它有時不能根本上解決問題,因此還是建議自行了解數(shù)據(jù)傾斜的細(xì)節(jié),并優(yōu)化查詢語句。
join基礎(chǔ)優(yōu)化
join優(yōu)化是一個復(fù)雜的話題,下面先說5點(diǎn)最基本的注意事項(xiàng)。
build table(小表)前置
在最常見的hash join方法中,一般總有一張相對小的表和一張相對大的表,小表叫build table,大表叫probe table。如下圖所示。
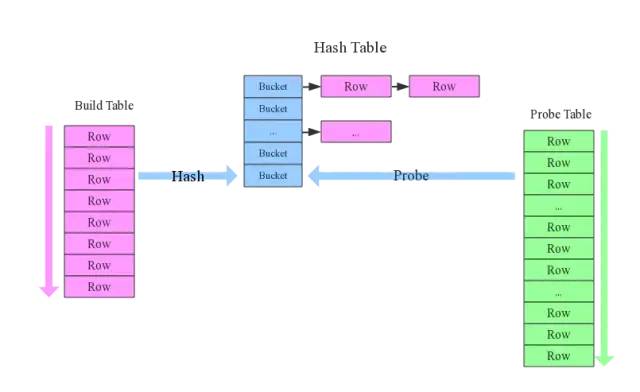
Hive在解析帶join的SQL語句時,會默認(rèn)將最后一個表作為probe table,將前面的表作為build table并試圖將它們讀進(jìn)內(nèi)存。如果表順序?qū)懛矗琾robe table在前面,引發(fā)OOM的風(fēng)險就高了。
在維度建模數(shù)據(jù)倉庫中,事實(shí)表就是probe table,維度表就是build table。假設(shè)現(xiàn)在要將日歷記錄事實(shí)表和記錄項(xiàng)編碼維度表來join:
select a.event_type,a.event_code,a.event_desc,b.upload_time
from calendar_event_code a
inner join (
select event_type,upload_time from calendar_record_log
where pt_date = 20190225
) b on a.event_type = b.event_type;-??多表join時key相同?-
這種情況會將多個join合并為一個MR job來處理,例如:
select a.event_type,a.event_code,a.event_desc,b.upload_time
from calendar_event_code a
inner join (
select event_type,upload_time from calendar_record_log
where pt_date = 20190225
) b on a.event_type = b.event_type
inner join (
select event_type,upload_time from calendar_record_log_2
where pt_date = 20190225
) c on a.event_type = c.event_type;如果上面兩個join的條件不相同,比如改成a.event_code = c.event_code,就會拆成兩個MR job計算。
負(fù)責(zé)這個的是相關(guān)性優(yōu)化器CorrelationOptimizer,它的功能除此之外還非常多,邏輯復(fù)雜,參考Hive官方的文檔可以獲得更多細(xì)節(jié):https://cwiki.apache.org/confluence/display/Hive/Correlation+Optimizer。
-??利用map join特性?-
map join特別適合大小表join的情況。Hive會將build table和probe table在map端直接完成join過程,消滅了reduce,效率很高。
select /*+mapjoin(a)*/ a.event_type,b.upload_time
from calendar_event_code a
inner join (
select event_type,upload_time from calendar_record_log
where pt_date = 20190225
) b on a.event_type < b.event_type;上面的語句中加了一條map join hint,以顯式啟用map join特性。早在Hive 0.8版本之后,就不需要寫這條hint了。map join還支持不等值連接,應(yīng)用更加靈活。
map join的配置項(xiàng)是hive.auto.convert.join,默認(rèn)值true,對應(yīng)邏輯優(yōu)化器是MapJoinProcessor。
還有一些參數(shù)用來控制map join的行為,比如hive.mapjoin.smalltable.filesize,當(dāng)build table大小小于該值就會啟用map join,默認(rèn)值25000000(25MB)。還有hive.mapjoin.cache.numrows,表示緩存build table的多少行數(shù)據(jù)到內(nèi)存,默認(rèn)值25000。
分桶表map join
map join對分桶表還有特別的優(yōu)化。由于分桶表是基于一列進(jìn)行hash存儲的,因此非常適合抽樣(按桶或按塊抽樣)。
它對應(yīng)的配置項(xiàng)是hive.optimize.bucketmapjoin,優(yōu)化器是BucketMapJoinOptimizer。但我們的業(yè)務(wù)中用分桶表較少,所以就不班門弄斧了,只是提一句。
傾斜均衡配置項(xiàng)
這個配置與上面group by的傾斜均衡配置項(xiàng)異曲同工,通過hive.optimize.skewjoin來配置,默認(rèn)false。
如果開啟了,在join過程中Hive會將計數(shù)超過閾值hive.skewjoin.key(默認(rèn)100000)的傾斜key對應(yīng)的行臨時寫進(jìn)文件中,然后再啟動另一個job做map join生成結(jié)果。通過hive.skewjoin.mapjoin.map.tasks參數(shù)還可以控制第二個job的mapper數(shù)量,默認(rèn)10000。
再重復(fù)一遍,通過自帶的配置項(xiàng)經(jīng)常不能解決數(shù)據(jù)傾斜問題。join是數(shù)據(jù)傾斜的重災(zāi)區(qū),后面還要介紹在SQL層面處理傾斜的各種方法。
優(yōu)化SQL處理join數(shù)據(jù)傾斜
上面已經(jīng)多次提到了數(shù)據(jù)傾斜,包括已經(jīng)寫過的sort by代替order by,以及group by代替distinct方法,本質(zhì)上也是為了解決它。join操作更是數(shù)據(jù)傾斜的重災(zāi)區(qū),需要多加注意。
空值或無意義值
這種情況很常見,比如當(dāng)事實(shí)表是日志類數(shù)據(jù)時,往往會有一些項(xiàng)沒有記錄到,我們視情況會將它置為null,或者空字符串、-1等。如果缺失的項(xiàng)很多,在做join時這些空值就會非常集中,拖累進(jìn)度。
因此,若不需要空值數(shù)據(jù),就提前寫where語句過濾掉。需要保留的話,將空值key用隨機(jī)方式打散,例如將用戶ID為null的記錄隨機(jī)改為負(fù)值:
select a.uid,a.event_type,b.nickname,b.age
from (
select
(case when uid is null then cast(rand()*-10240 as int) else uid end) as uid,
event_type from calendar_record_log
where pt_date >= 20190201
) a left outer join (
select uid,nickname,age from user_info where status = 4
) b on a.uid = b.uid;單獨(dú)處理傾斜key
這其實(shí)是上面處理空值方法的拓展,不過傾斜的key變成了有意義的。一般來講傾斜的key都很少,我們可以將它們抽樣出來,對應(yīng)的行單獨(dú)存入臨時表中,然后打上一個較小的隨機(jī)數(shù)前綴(比如0~9),最后再進(jìn)行聚合。SQL語句與上面的相仿,不再贅述。
不同數(shù)據(jù)類型
這種情況不太常見,主要出現(xiàn)在相同業(yè)務(wù)含義的列發(fā)生過邏輯上的變化時。
舉個例子,假如我們有一舊一新兩張日歷記錄表,舊表的記錄類型字段是(event_type int),新表的是(event_type string)。為了兼容舊版記錄,新表的event_type也會以字符串形式存儲舊版的值,比如'17'。當(dāng)這兩張表join時,經(jīng)常要耗費(fèi)很長時間。其原因就是如果不轉(zhuǎn)換類型,計算key的hash值時默認(rèn)是以int型做的,這就導(dǎo)致所有“真正的”string型key都分配到一個reducer上。所以要注意類型轉(zhuǎn)換:
select a.uid,a.event_type,b.record_data
from calendar_record_log a
left outer join (
select uid,event_type from calendar_record_log_2
where pt_date = 20190228
) b on a.uid = b.uid and b.event_type = cast(a.event_type as string)
where a.pt_date = 20190228;build table過大
有時,build table會大到無法直接使用map join的地步,比如全量用戶維度表,而使用普通join又有數(shù)據(jù)分布不均的問題。這時就要充分利用probe table的限制條件,削減build table的數(shù)據(jù)量,再使用map join解決。代價就是需要進(jìn)行兩次join。舉個例子:
select /*+mapjoin(b)*/ a.uid,a.event_type,b.status,b.extra_info
from calendar_record_log a
left outer join (
select /*+mapjoin(s)*/ t.uid,t.status,t.extra_info
from (select distinct uid from calendar_record_log where pt_date = 20190228) s
inner join user_info t on s.uid = t.uid
) b on a.uid = b.uid
where a.pt_date = 20190228;-??Map Reduce優(yōu)化?-

調(diào)整mapper數(shù)
mapper數(shù)量與輸入文件的split數(shù)息息相關(guān),在Hadoop源碼org.apache.hadoop.mapreduce.lib.input.FileInputFormat類中可以看到split劃分的具體邏輯。這里不貼代碼,直接敘述mapper數(shù)是如何確定的。
可以直接通過參數(shù)
mapred.map.tasks(默認(rèn)值2)來設(shè)定mapper數(shù)的期望值,但它不一定會生效,下面會提到。設(shè)輸入文件的總大小為
total_input_size。HDFS中,一個塊的大小由參數(shù)dfs.block.size指定,默認(rèn)值64MB或128MB。在默認(rèn)情況下,mapper數(shù)就是:default_mapper_num = total_input_size / dfs.block.size。參數(shù)
mapred.min.split.size(默認(rèn)值1B)和mapred.max.split.size(默認(rèn)值64MB)分別用來指定split的最小和最大大小。split大小和split數(shù)計算規(guī)則是:split_size = MAX(mapred.min.split.size, MIN(mapred.max.split.size, dfs.block.size));split_num = total_input_size / split_size。得出mapper數(shù):
mapper_num = MIN(split_num, MAX(default_num, mapred.map.tasks))。
可見,如果想減少mapper數(shù),就適當(dāng)調(diào)高mapred.min.split.size,split數(shù)就減少了。如果想增大mapper數(shù),除了降低mapred.min.split.size之外,也可以調(diào)高mapred.map.tasks。
一般來講,如果輸入文件是少量大文件,就減少mapper數(shù);如果輸入文件是大量非小文件,就增大mapper數(shù);至于大量小文件的情況,得參考下面“合并小文件”一節(jié)的方法處理。
調(diào)整reducer數(shù)
reducer數(shù)量的確定方法比mapper簡單得多。使用參數(shù)mapred.reduce.tasks可以直接設(shè)定reducer數(shù)量,不像mapper一樣是期望值。但如果不設(shè)這個參數(shù)的話,Hive就會自行推測,邏輯如下:
參數(shù)
hive.exec.reducers.bytes.per.reducer用來設(shè)定每個reducer能夠處理的最大數(shù)據(jù)量,默認(rèn)值1G(1.2版本之前)或256M(1.2版本之后)。參數(shù)
hive.exec.reducers.max用來設(shè)定每個job的最大reducer數(shù)量,默認(rèn)值999(1.2版本之前)或1009(1.2版本之后)。得出reducer數(shù):
reducer_num = MIN(total_input_size / reducers.bytes.per.reducer, reducers.max)。
reducer數(shù)量與輸出文件的數(shù)量相關(guān)。如果reducer數(shù)太多,會產(chǎn)生大量小文件,對HDFS造成壓力。如果reducer數(shù)太少,每個reducer要處理很多數(shù)據(jù),容易拖慢運(yùn)行時間或者造成OOM。
合并小文件
輸入階段合并
需要更改Hive的輸入文件格式,即參數(shù)hive.input.format,默認(rèn)值是org.apache.hadoop.hive.ql.io.HiveInputFormat,我們改成org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。
這樣比起上面調(diào)整mapper數(shù)時,又會多出兩個參數(shù),分別是mapred.min.split.size.per.node和mapred.min.split.size.per.rack,含義是單節(jié)點(diǎn)和單機(jī)架上的最小split大小。如果發(fā)現(xiàn)有split大小小于這兩個值(默認(rèn)都是100MB),則會進(jìn)行合并。具體邏輯可以參看Hive源碼中的對應(yīng)類。輸出階段合并
直接將hive.merge.mapfiles和hive.merge.mapredfiles都設(shè)為true即可,前者表示將map-only任務(wù)的輸出合并,后者表示將map-reduce任務(wù)的輸出合并。
另外,hive.merge.size.per.task可以指定每個task輸出后合并文件大小的期望值,hive.merge.size.smallfiles.avgsize可以指定所有輸出文件大小的均值閾值,默認(rèn)值都是1GB。如果平均大小不足的話,就會另外啟動一個任務(wù)來進(jìn)行合并。
啟用壓縮
壓縮job的中間結(jié)果數(shù)據(jù)和輸出數(shù)據(jù),可以用少量CPU時間節(jié)省很多空間。壓縮方式一般選擇Snappy,效率最高。
要啟用中間壓縮,需要設(shè)定hive.exec.compress.intermediate為true,同時指定壓縮方式hive.intermediate.compression.codec為org.apache.hadoop.io.compress.SnappyCodec。另外,參數(shù)hive.intermediate.compression.type可以選擇對塊(BLOCK)還是記錄(RECORD)壓縮,BLOCK的壓縮率比較高。
輸出壓縮的配置基本相同,打開hive.exec.compress.output即可。
JVM重用
在MR job中,默認(rèn)是每執(zhí)行一個task就啟動一個JVM。如果task非常小而碎,那么JVM啟動和關(guān)閉的耗時就會很長。可以通過調(diào)節(jié)參數(shù)mapred.job.reuse.jvm.num.tasks來重用。例如將這個參數(shù)設(shè)成5,那么就代表同一個MR job中順序執(zhí)行的5個task可以重復(fù)使用一個JVM,減少啟動和關(guān)閉的開銷。但它對不同MR job中的task無效。
并行執(zhí)行與本地模式
并行執(zhí)行
Hive中互相沒有依賴關(guān)系的job間是可以并行執(zhí)行的,最典型的就是多個子查詢union all。在集群資源相對充足的情況下,可以開啟并行執(zhí)行,即將參數(shù)hive.exec.parallel設(shè)為true。另外hive.exec.parallel.thread.number可以設(shè)定并行執(zhí)行的線程數(shù),默認(rèn)為8,一般都夠用。本地模式
Hive也可以不將任務(wù)提交到集群進(jìn)行運(yùn)算,而是直接在一臺節(jié)點(diǎn)上處理。因?yàn)橄颂峤坏郊旱膐verhead,所以比較適合數(shù)據(jù)量很小,且邏輯不復(fù)雜的任務(wù)。
設(shè)置hive.exec.mode.local.auto為true可以開啟本地模式。但任務(wù)的輸入數(shù)據(jù)總量必須小于hive.exec.mode.local.auto.inputbytes.max(默認(rèn)值128MB),且mapper數(shù)必須小于hive.exec.mode.local.auto.tasks.max(默認(rèn)值4),reducer數(shù)必須為0或1,才會真正用本地模式執(zhí)行。
嚴(yán)格模式
所謂嚴(yán)格模式,就是強(qiáng)制不允許用戶執(zhí)行3種有風(fēng)險的HiveQL語句,一旦執(zhí)行會直接失敗。這3種語句是:
查詢分區(qū)表時不限定分區(qū)列的語句;
兩表join產(chǎn)生了笛卡爾積的語句;
用order by來排序但沒有指定limit的語句。
要開啟嚴(yán)格模式,需要將參數(shù)hive.mapred.mode設(shè)為strict。
采用合適的存儲格式
在HiveQL的create table語句中,可以使用stored as ...指定表的存儲格式。Hive表支持的存儲格式有TextFile、SequenceFile、RCFile、Avro、ORC、Parquet等。
存儲格式一般需要根據(jù)業(yè)務(wù)進(jìn)行選擇,在我們的實(shí)操中,絕大多數(shù)表都采用TextFile與Parquet兩種存儲格式之一。
TextFile是最簡單的存儲格式,它是純文本記錄,也是Hive的默認(rèn)格式。雖然它的磁盤開銷比較大,查詢效率也低,但它更多地是作為跳板來使用。RCFile、ORC、Parquet等格式的表都不能由文件直接導(dǎo)入數(shù)據(jù),必須由TextFile來做中轉(zhuǎn)。
Parquet和ORC都是Apache旗下的開源列式存儲格式。列式存儲比起傳統(tǒng)的行式存儲更適合批量OLAP查詢,并且也支持更好的壓縮和編碼。我們選擇Parquet的原因主要是它支持Impala查詢引擎,并且我們對update、delete和事務(wù)性操作需求很低。
這里就不展開講它們的細(xì)節(jié),可以參考各自的官網(wǎng):
https://parquet.apache.org/
https://orc.apache.org/