
輕量級語義分割網絡:ENet
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

? ?作者:石文華 ? ? ? ? ??
作者&編輯:石文華? ? ? ? ? ?
章節(jié)目錄
介紹
網絡結構
設計選擇
實驗
代碼
01
介紹
為了減少浮點運算的次數和內存占用以及推理時間,提出了Enet,采用編碼器-解碼器架構,相比SegNet,速度提升18倍,計算量減少75倍,參數量減少79倍。并且具有相當的精度,它是一個實時的語義分割網絡結構。ENet分割圖像的示例如下圖所示:

02
網絡結構
網絡結構如下表所示:
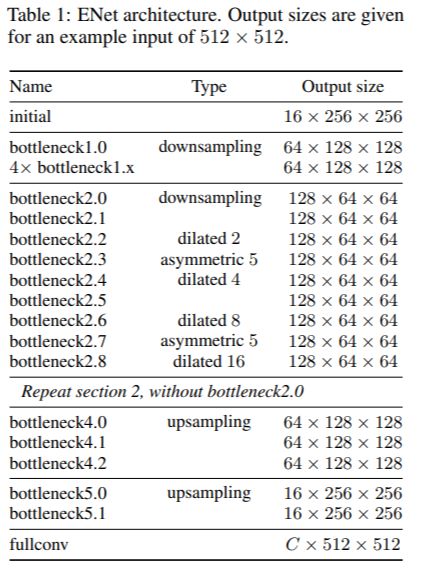
網絡的輸入大小是512x512,有兩種網絡模塊,分別是initial和bottleneck,如下圖所示:
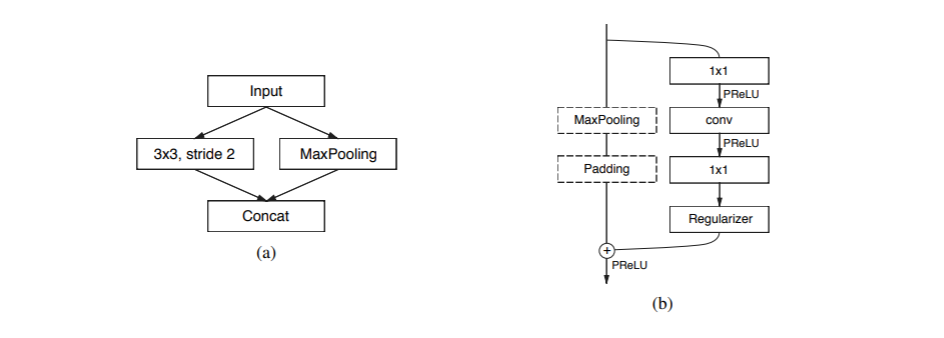
圖(a)是initial模塊,MaxPooling為步長2的2x2的filter,卷積有13個filter,Concat后的特征映射總計為16個,起到特征提取、壓縮輸入圖像”體積”、除去圖像中的視覺冗余信息的作用。圖(b)是bottleneck 模塊,采用殘差連接的思想,包含三個卷積層:一個1 x 1的降維卷積,一個主卷積層,一個1 x 1擴張卷積,bn和PReLU放在中間。對于下采樣的bottleneck模塊,主分支添加最大池層,第一個1×1卷積被替換為步長為2的2×2卷積,中間的主卷積有三種可能的選擇:Conv普通卷積,asymmetric分解卷積(如分解成 5 × 1 和 1 × 5 ),Dilated空洞卷積。對于正則化方式,使用了Spatial Dropout,在bottleneck 2.0之前p=0.01,之后p=0.1。由網絡結構表格可以看到,初始階段包含一個塊,接著是階段1由5個bottleneck 組成,而階段2和階段3具有相同的結構,階段3在開始時沒有對輸入進行降采樣。階段1到3是編碼器。階段4和5屬于解碼器。
細節(jié):
(1)為了減少內核調用和內存操作,沒有在任何投影中使用bias,因為cuDNN會使用單獨的內核進行卷積和bias相加。這種方式對準確性沒有任何影響。
(2)在每個卷積層和隨后的非線性之間,都使用了bn進行處理。
(3)在解碼器中,用max unpooling代替max pooling,用無bias的spatial convolution代替padding。
(4)在最后一個上采樣模塊中,沒有使用池化索引,因為初始塊在輸入幀的3個通道上操作,而最終輸出具有C特征映射(對象類的數量)。
(5)出于性能原因,只在網絡的最后一個模塊設置一個完全卷積,僅這一項就占用了解碼器處理時間的很大一部分。
03
設計選擇
?1、Feature map resolution:
????語義分割中的圖像下采樣有兩個主要缺點:一是降低特征圖的分辨率意味著丟失精確邊緣形狀等空間信息;二是全像素分割要求輸出與輸入具有相同的分辨率。這意味著進行了多少次下采樣將需要同樣次數的上采樣,這將增加模型尺寸和計算成本。第一個問題在FCN中通過編碼器生成的特征映射之間的add得到了解決,在SegNet中通過保存在max pooling層中選擇的元素的索引,并使用它們在解碼器中生成稀疏的上采樣映射得到了解決。作者遵循SegNet方法,因為它減少了對內存需求。盡管如此,還是發(fā)現(xiàn)下采樣會損害準確性,需要盡可能的限制下采樣。當然,下采樣能夠擴大感受野,學習到更多的上下文特征用于逐像素的分類。
?2、Early downsampling:
????高分辨率的輸入會耗費大量計算資源,ENet的初始化模塊會大大減少輸入圖像的大小,并且只使用了少量的feature maps,初始化模塊充當良好的特性提取器,并且只對網絡稍后部分的輸入進行預處理。
?3、Decoder size:
??? ENet的Encoder和Decoder不對稱,由一個較大的Encoder和一個較小的Decoder組成,作者認為Encoder和分類模型相似,主要進行特征信息的處理和過濾,而decoder主要是對encoder的輸出做上采樣,對細節(jié)做細微調。
4、Nonlinear operations:
????作者發(fā)現(xiàn)ENet上使用ReLU卻降低了精度。相反,刪除網絡初始層中的大多數ReLU可以改善結果。用PReLU替換了網絡中的所有ReLU,對每個特征映射PReLU有一個附加參數,目的是學習非線性的負斜率。
?5、Information-preserving dimensionality changes:
????選擇在使用步長2的卷積的同時并行執(zhí)行池化操作,并將得到的特征圖拼接(concatenate)起來。這種技術可以將初始塊的推理時間提高10倍。此外,在原始ResNet架構中發(fā)現(xiàn)了一個問題。下采樣時,卷積分支中的第一個1×1卷積在兩個維度上以2的步長滑動,直接丟棄了75%的輸入。而ENet將卷積核的大小增加到了2×2,這樣可以讓整個輸入都參與下采樣,從而提高信息流和精度。雖然這使得這些層的計算成本增加了4倍,但是在ENET中這些層的數量很少,開銷并不明顯。
6、Factorizing filters:
????卷積權重存在大量冗余,并且每個n x n卷積可以分解成一個n x 1濾波和一個1 x n濾波,稱為非對稱卷積。本文采用n = 5的非對稱卷積,它的操作相當于一個3 x 3的卷積,增加了模塊的學習能力并增加了感受野,更重要的是,在瓶頸模塊中使用的一系列操作(投影、卷積、投影)可以被視為將一個大卷積層分解為一系列更小和更簡單的操作,即其低階近似。這樣的因子分解可以極大地減少參數的數量,從而減少冗余。此外,由于在層之間插入的非線性操作,特征也變得更豐富了。
7、Dilated convolutions:
大的感受野對分割任務也是非常重要的,可以參考更多的上下文特征對像素進行分類,為了避免對特征圖進行過度的下采樣,使用空洞卷積,在最小分辨率下運行的階段中,幾個瓶頸模塊內的主要卷積層都使用了空洞卷積。在沒有增加額外計算開銷的情況下,便提高了準確度。當作者將空洞卷積與其他bottleneck(常規(guī)和非對稱卷積)交織時,即不是按順序排列它們,獲得了最佳效果。
8、Regularization:
為了防止過擬合,把Spatial Dropout放在卷積分支的末端,就在加法之前。
04
實驗
1、性能比較:
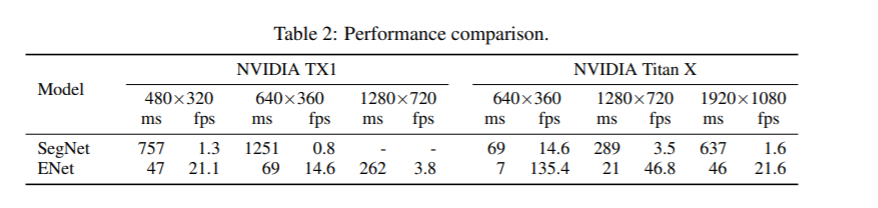
2、硬件要求比較:
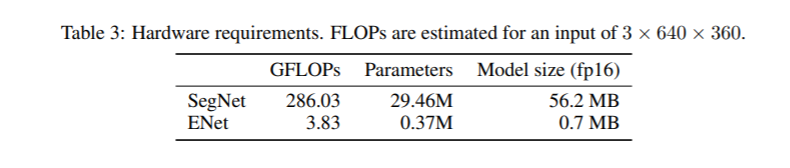
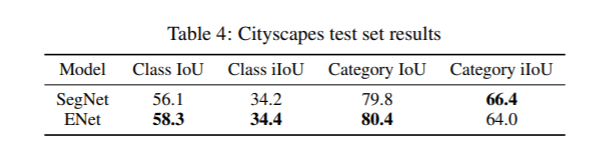
3、Cityscapes測試集上的結果比較:
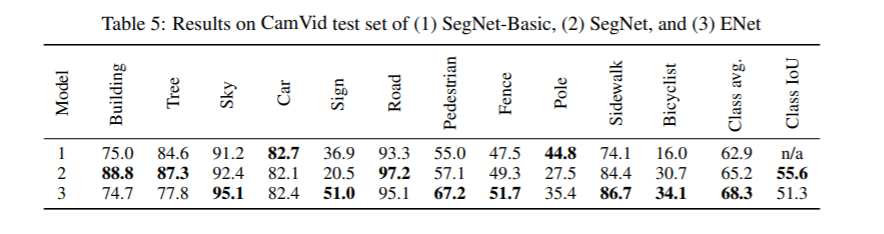
4、CamVid數據集上不同模型的比較:
05
代碼
網絡結構部分的代碼詳見:
https://github.com/cswhshi/segmentation/blob/master/ENet.py
歡迎大家指正和star~
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~