
【NLP】Transformer的中年危機(jī)?
最近Transformer被各種「質(zhì)疑」,上周CV圈已經(jīng)殺瘋了,多個(gè)大佬接連發(fā)文,把早已過(guò)時(shí)的MLP又?jǐn)[了出來(lái):
5月4日,谷歌掛出《MLP-Mixer An all-MLP Architecture for Vision》 5月5日,清華圖形學(xué)實(shí)驗(yàn)室掛出《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》 5月5日,清華軟院掛出《RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition》 5月6日,牛津掛出《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》
好家伙,題目一個(gè)比一個(gè)扎心。

然而CV圈扎完了,娘家的NLPer也不甘示弱,就在昨天我刷Arxiv的時(shí)候,一篇谷歌的文章映入眼簾:

大佬們指出,雖然Transformer老哥的效果確實(shí)好,但這個(gè)效果到底是模型結(jié)構(gòu)帶來(lái)的、還是預(yù)訓(xùn)練帶來(lái)的呢? 畢竟之前也沒(méi)人這么暴力地訓(xùn)過(guò)對(duì)不對(duì)。
那既然沒(méi)人訓(xùn)過(guò),這不idea就來(lái)了嘛
接下來(lái)我腦補(bǔ)了一下模型選擇的問(wèn)題,經(jīng)典的就那么幾個(gè):
MLP:好!但谷歌18年的USE模型已經(jīng)證明了MLP沒(méi)Transformer效果好,畢竟NLP還是需要序列信息的 LSTM:不錯(cuò)!用這個(gè)把大模型訓(xùn)出來(lái),今年的kpi就算了,明年的可以沖刺一下 CNN:這個(gè)好!速度又快又輕便,根據(jù)經(jīng)驗(yàn)來(lái)說(shuō)在簡(jiǎn)單任務(wù)上表現(xiàn)也不差,穩(wěn)得一批
結(jié)果一訓(xùn)真的是,瞬間ACL+1:
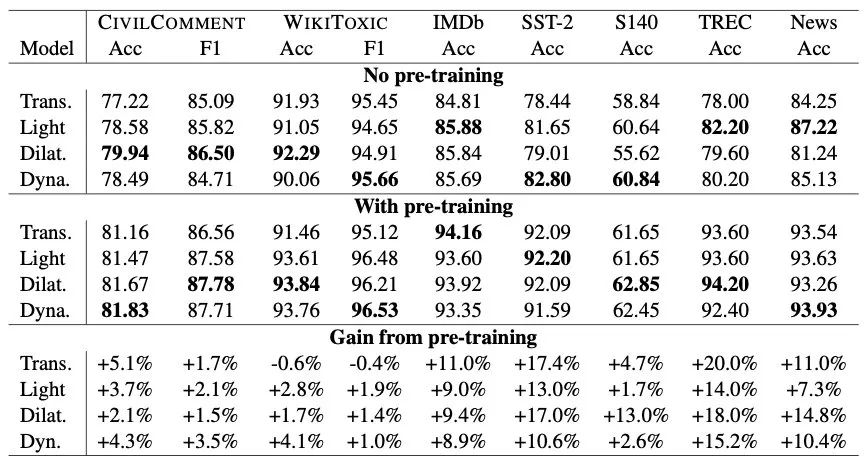
上圖中 Lightweight CNN、Dilated CNN、Dynamic CNN 分別是不同的變種,可以得出以下結(jié)論:
不管有沒(méi)有預(yù)訓(xùn)練,CNN的一些變種在NLP分類任務(wù)上都有比肩Transformer的效果 不只是Transformer,預(yù)訓(xùn)練對(duì)于CNN網(wǎng)絡(luò)也是有提升的,在1%-18%之間 Dilated CNN、Dynamic CNN 這兩個(gè)變種的表現(xiàn)更好 結(jié)構(gòu)、預(yù)訓(xùn)練對(duì)于最終表現(xiàn)都有影響,可能不預(yù)訓(xùn)練的時(shí)候A>B,預(yù)訓(xùn)練之后A<B
不過(guò),表中數(shù)據(jù)展示的都是文本分類,雖然附加的一個(gè)生成式語(yǔ)義分析上表現(xiàn)也不錯(cuò),但大佬們也十分清楚CNN在其他更難的任務(wù)上表現(xiàn)有限。
CNN在設(shè)計(jì)上沒(méi)考慮句子間的交互,只抽取了局部特征。比如在句子pair拼接的分類任務(wù)上(MultiNLI、SQuAd),就比Transformer甩掉了10-20個(gè)點(diǎn)。有趣的是作者在給CNN加了一層cross-attention之后效果就上去了,在MultiNLI把差距縮小到了1個(gè)點(diǎn)。同時(shí)他們也指出,在雙塔式的分類任務(wù)上CNN應(yīng)該有更好的表現(xiàn)(就像USE模型用MLP也能達(dá)到不錯(cuò)的效果)。
所以,文章讀到這里,發(fā)現(xiàn)Transformer還是穩(wěn)坐NLP第一把交椅。這也是它的 ?? ?? 之處,無(wú)論別人怎么搞,都沒(méi)法在general層面打過(guò)它。前段時(shí)間谷歌還有篇文章分析了Transformer的各種變種,發(fā)現(xiàn)大部分都只是在個(gè)別任務(wù)有所提升(攤手)。
但在做實(shí)際落地任務(wù)時(shí),還是會(huì)有各種速度上的限制,這篇文章就是告訴我們?cè)谌蝿?wù)簡(jiǎn)單、數(shù)據(jù)量充足、速度受限的情況下可以用CNN及變種來(lái)解決問(wèn)題。TextCNN is all you need。
最后再說(shuō)幾個(gè)我疑惑的點(diǎn),歡迎留言討論:
文章用的都是CNN變種,為什么沒(méi)嘗試最經(jīng)典的CNN呢?會(huì)不會(huì)是表現(xiàn)太差了,不能支持結(jié)論 文章的預(yù)訓(xùn)練模型是參考T5的結(jié)構(gòu),為什么不用更普遍的BERT結(jié)構(gòu)?還提到T5是「current state-of-the-art」,那20年下的GPT3去哪兒了?難道是寫的時(shí)間太早?為什么現(xiàn)在才發(fā)?
這些問(wèn)題都不得而知了,所以短期內(nèi)我還是繼續(xù)無(wú)腦精調(diào)BERT吧,做個(gè)懶人。
往期精彩回顧
本站qq群851320808,加入微信群請(qǐng)掃碼: