
全球首個!7nm世界最大芯片打造AI集群,解鎖120萬億「大腦級」AI模型

新智元報道
新智元報道
來源:wired
編輯:yaxin su Catherine
【新智元導(dǎo)讀】突觸是神經(jīng)網(wǎng)絡(luò)的「橋梁」。今日,Cerebras 宣布世界首個「大腦級」AI 集群,能夠訓(xùn)練120萬億參數(shù)模型,擊敗人腦百萬億個突觸!
突觸,是神經(jīng)網(wǎng)絡(luò)的「橋梁」。
人類大腦有大約 100 萬億個突觸,860 億個神經(jīng)元。
因為有了突觸,才可以把神經(jīng)元的電信號傳遞到下一神經(jīng)元。
而現(xiàn)在,Cerebras 宣布了「第一個大腦級 AI 解決方案」!
一個可以支持 120 萬億參數(shù) AI 模型的單一系統(tǒng),擊敗了人腦萬億個突觸。

相比之下,最大的AI硬件集群大約占人類大腦規(guī)模的 1%,約 1 萬億個突觸(參數(shù))。
Cerebras 可以通過單個CS-2系統(tǒng)(85萬個內(nèi)核)實現(xiàn)首創(chuàng)!

世界第一!192個AI集群,解鎖萬億參數(shù)模型
參數(shù)越多,人工智能模型就越復(fù)雜。
谷歌在短短2年內(nèi)將模型參數(shù)的數(shù)量提高了大約1000倍。

參數(shù)的數(shù)量,所需的算力,都呈指數(shù)級增長。

Cerebras 的創(chuàng)始人兼首席執(zhí)行官Andrew Feldman表示,最新的處理器如此強(qiáng)大的原因就是,在晶片上打造而不是單個芯片上。

192個 CS-2 集中在一起,將使最大的人工智能神經(jīng)網(wǎng)絡(luò)的規(guī)模擴(kuò)大100倍。
Cerebras系統(tǒng)由其第二代晶圓WSE-2提供動力。
WSE-2 有2.6萬億個晶體管和85萬個AI優(yōu)化內(nèi)核,再次刷新記錄。

相比之下,最大的圖形處理器只有540億個晶體管,比 WSE-2少2.55萬億個晶體管。
與英偉達(dá)相比,WSE-2還擁有內(nèi)核數(shù)是A100的123倍;緩存是其1000倍;可提供的內(nèi)存帶寬,則達(dá)到了A100的13萬倍。
「大腦級」 AI 解決方案
首個大腦級 AI 解決方案如何誕生呢?
除了用到最大芯片,Cerebras還揭露了4項新技術(shù)。
這種技術(shù)組合可以輕松組建大腦規(guī)模的神經(jīng)網(wǎng)絡(luò),并將工作分配到人工智能優(yōu)化的核心集群上。

一、Cerebras Weight Streaming:分解計算和內(nèi)存
這是一種新的軟件執(zhí)行模式,可以將計算和參數(shù)存儲分解,使規(guī)模和速度得以獨立且靈活地擴(kuò)展,同時解決了小型處理器集群存在的延遲和內(nèi)存帶寬問題。
具體來說,這項技術(shù)首次實現(xiàn)了在芯片外存儲模型參數(shù),同時提供與在芯片上相同的訓(xùn)練和推理性能。
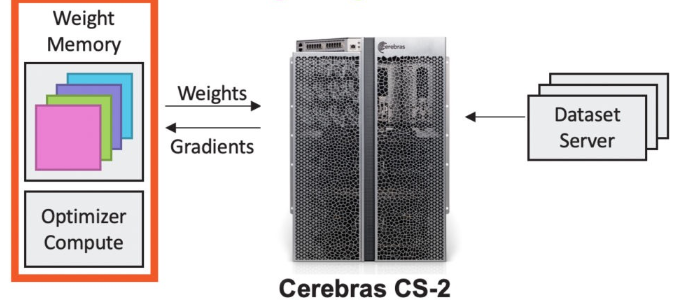
建立在WSE龐大規(guī)模的基礎(chǔ)上,一個小型參數(shù)存儲可以連接包含數(shù)千萬個內(nèi)核的許多晶圓,或者說,120 萬億個參數(shù)模型需要的 2.4 PB 存儲可以分配給單個 CS-2。
模型權(quán)重保存在中央芯片外,它們被傳輸?shù)骄希糜谏窠?jīng)網(wǎng)絡(luò)每一層的計算。
在神經(jīng)網(wǎng)絡(luò)的增量訓(xùn)練中,梯度從晶圓流到中央存儲,然后被用于更新權(quán)重。

最終,用戶可以將 CS-2 的使用數(shù)量從1個擴(kuò)展到192個,同時無需更改軟件。
二、Cerebras MemoryX:啟用百萬億參數(shù)模型
這是一種一內(nèi)存擴(kuò)展技術(shù),它使模型參數(shù)能夠存儲在芯片外,并有效地流式傳輸?shù)?CS-2,實現(xiàn)同在芯片上那樣的性能。
這一架構(gòu)靈活性極強(qiáng),支持4TB 到 2.4PB 的存儲配置,2000 億到 120 萬億的參數(shù)大小。
也就是說,最終,WSE 2可以提供高達(dá) 2.4 PB 的高性能內(nèi)存,CS-2 可以支持具有多達(dá) 120 萬億個參數(shù)的模型。
三、Cerebras SwarmX:提供更大、更高效的集群
這是一種人工智能優(yōu)化的高性能通信結(jié)構(gòu),可將 Cerebras的芯片內(nèi)結(jié)構(gòu)擴(kuò)展到芯片外,從而擴(kuò)展AI集群,而且使其性能實現(xiàn)線性擴(kuò)展。
也就是說,10 個 CS-2 有望實現(xiàn)比單個 CS-2 快 10 倍的相同解決方案。
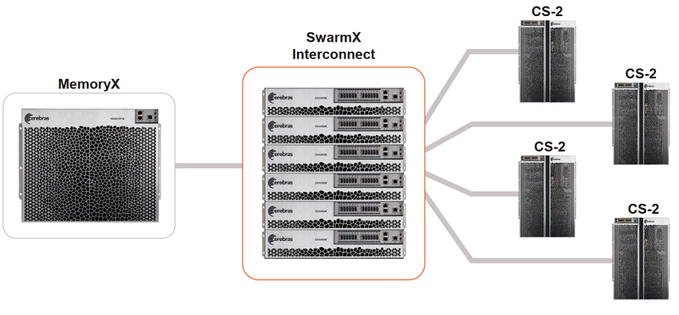
最終,SwarmX 可以將CS-2 系統(tǒng)從2個擴(kuò)展到192 個,鑒于每個 CS-2 提供85萬個 AI 優(yōu)化內(nèi)核,Cerebras 便可連接 1.63 億個 AI 優(yōu)化內(nèi)核集群。
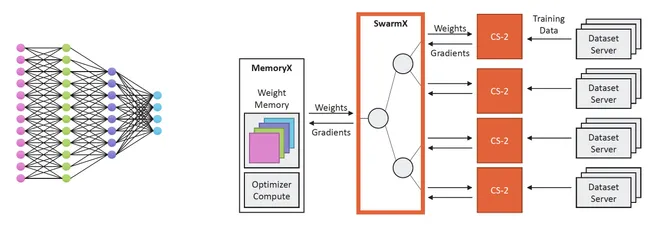
連接SwarmX的 CS-2 計算機(jī)接收神經(jīng)網(wǎng)絡(luò)的權(quán)重流、分割后的訓(xùn)練數(shù)據(jù),同時計算傳送到 MemoryX 的反向傳播梯度。
四、Selectable Sparsity:縮短時間
Cerebras WSE 基于細(xì)粒度數(shù)據(jù)流架構(gòu),其 85萬個 AI 優(yōu)化計算內(nèi)核可以單獨忽略零。
Cerebras 架構(gòu)獨有的數(shù)據(jù)流調(diào)度和巨大的內(nèi)存帶寬,使這種類型的細(xì)粒度處理能夠加速所有形式的稀疏性。

Cerebras
簡言之,用戶可以在他們的模型中選擇權(quán)重稀疏程度,直接減少 FLOPs 和解決時間。
比iPad還大,「巨無霸」芯片迭代史
「巨芯」一代問世,大有可為
科技行業(yè)日新月異,變化發(fā)展飛快。芯片行業(yè)更是如此,之前再先進(jìn)的工藝,兩年后就有可能面臨淘汰。這是信息時代不可逆轉(zhuǎn)的趨勢。
作為全球芯片龍頭,NVIDIA依然占據(jù)著龐大的市場份額。
位于美國硅谷的AI創(chuàng)企Cerebras雖然沒有NVIDIA那么全面,但其技術(shù)解決方案顯然已經(jīng)吸引到了許多客戶。
早在2019年,Cerebras曾發(fā)布了第一代WSE(Wafer Scale Engine)芯片。
這款芯片是有史以來最大的AI芯片,有40萬個內(nèi)核和1.2萬億個晶體管,使用臺積電16nm工藝制程。

與多數(shù)芯片不同,一代「巨芯」不是在12英寸硅晶圓上制作的,而是在單個晶圓上通過互聯(lián)實現(xiàn)的單芯片。互聯(lián)設(shè)計可保持高速運(yùn)行,使萬億個晶體管同時工作。
與傳統(tǒng)芯片相比,WSE還包含3000倍的高速片上存儲器,并具有10000倍的存儲器帶寬。WSE的總帶寬為每秒100 petabits,不需要諸如TCP/IP和MPI之類的通信協(xié)議支持。
由于大芯片可以更快處理信息,減少訓(xùn)練時間,研究人員能夠測試更多想法。WSE的問世在當(dāng)時消除了整個行業(yè)進(jìn)步的主要瓶頸。
「巨芯」二代另辟蹊徑,良率更高
2021年,Cerebras推出了最新的Wafer Scale Engine 2(WSE-2)芯片,該芯片為超級計算任務(wù)而構(gòu)建,具有破紀(jì)錄的2.6萬億個晶體管和85萬顆AI優(yōu)化內(nèi)核,采用臺積電的7nm工藝制造。
與第一代WSE芯片相比,二代芯片更加先進(jìn)。

WSE-2的晶體管數(shù)、內(nèi)核數(shù)、內(nèi)存、內(nèi)存帶寬和結(jié)構(gòu)帶寬等性能特征增加了一倍以上。
在先進(jìn)工藝的支持下,Cerebras 可以在同樣的8*8英寸,面積約46225mm2的芯片中塞進(jìn)更多的晶體管。
而且,正是采用了臺積電的7nm工藝,電路之間的寬度僅有七十億分之一米。
當(dāng)有內(nèi)核發(fā)生故障時,單獨的故障內(nèi)核并不影響芯片的使用。況且在臺積電這樣的晶圓代工廠中,很少會出現(xiàn)連續(xù)的內(nèi)核缺陷。
由此可見,二代「巨芯」的良率較高。
參考資料:
https://www.wired.com/story/cerebras-chip-cluster-neural-networks-ai/
https://www.tomshardware.com/news/worlds-largest-chip-unlocks-brain-sized-ai-models-with-163-million-core-cluster

