
【NLP】相當(dāng)全面:各種深度學(xué)習(xí)模型在文本分類任務(wù)上的應(yīng)用

論文標(biāo)題:Deep Learning Based Text Classification:A Comprehensive Review
論文鏈接:https://arxiv.org/pdf/2004.03705.pdf
論文介紹了各種深度學(xué)習(xí)模型在文本分類任務(wù)上的應(yīng)用,按照模型的結(jié)構(gòu)進(jìn)行分類介紹,基本上涵蓋了當(dāng)前大部分的深度結(jié)構(gòu),也可以當(dāng)作神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)入門參考。論文中討論了150多篇論文,由于能力與時間有限,本文只簡單介紹了小部分,詳細(xì)內(nèi)容請參考原論文與原論文參考文獻(xiàn)。
集大成系列會分享各個領(lǐng)域(方面)的綜述論文(建議大家看原論文),分享內(nèi)容主要來自于原論文,會有些整理與刪減,以及個人理解與應(yīng)用等等,其中涉及到的算法復(fù)現(xiàn)都會開源在:https://github.com/wellinxu/nlp_store
介紹 文本分類中的深度學(xué)習(xí)模型 前饋神經(jīng)網(wǎng)絡(luò)FNN 循環(huán)神經(jīng)網(wǎng)絡(luò)RNN 卷積神經(jīng)網(wǎng)絡(luò)CNN 膠囊神經(jīng)網(wǎng)絡(luò) 注意力機(jī)制 記憶增強(qiáng)網(wǎng)絡(luò) Transformers 圖神經(jīng)網(wǎng)絡(luò)GNN 孿生神經(jīng)網(wǎng)絡(luò)S2Net 混合模型 非監(jiān)督學(xué)習(xí) 文本分類數(shù)據(jù)集 實(shí)驗(yàn)性能分析 文本分類常用指標(biāo) 定量分析結(jié)果 挑戰(zhàn)與機(jī)遇 參考
介紹
文本分類是NLP中的經(jīng)典問題,主要的文本分類方式分為三種:
基于規(guī)則的方法
基于規(guī)則的方法,就是使用一組預(yù)先定義好的規(guī)則將文本分到不同的類別,這需要很深的領(lǐng)域知識。基于機(jī)器學(xué)習(xí)(數(shù)據(jù)驅(qū)動)的方法
基于機(jī)器學(xué)習(xí)的方法是根據(jù)已有的數(shù)據(jù)自動學(xué)習(xí)分類,這可以學(xué)習(xí)到文本與類別內(nèi)在的關(guān)系。混合方法
混合方法則是結(jié)合規(guī)則與機(jī)器學(xué)習(xí)兩種方式來預(yù)測。
機(jī)器學(xué)習(xí)模型今年多一直很受關(guān)注,經(jīng)典的機(jī)器學(xué)習(xí)主要有兩步,一是手動提取特征,主要包括詞袋模型及相關(guān)變體,二是將特征喂給模型進(jìn)行學(xué)習(xí)預(yù)測,主要包括NB、SVM、GBDT、RF、LR等等。2012年之后,基于深度學(xué)習(xí)的模型被大規(guī)模地應(yīng)用在各種文本分類任務(wù)上,同時也提高了各個任務(wù)的準(zhǔn)確性,主要包括:
情感分析
情感分析是分析文本數(shù)據(jù)(如產(chǎn)品評論、電影評論、推文)中人們的觀點(diǎn),提取他們的極性和觀點(diǎn)。情緒分類可以是二元問題(正負(fù)兩類),也可以是多類問題(細(xì)粒度的標(biāo)簽或多層次的強(qiáng)度)。新聞分類 主題分析
主題分類的目標(biāo)是為每個文檔分配一個或多個主題,以便于分析。問答(QA)
QA有兩種類型:抽取式和生成式。抽取式QA可以看作是特殊的文本分類。給定一個問題和一組候選答案(例如,SQuAD中給定文檔中的文本范圍),將每個候選答案分類為正確或不正確。論文中涉及的是抽取式QA。自然語言推理(NLI)
NLI也被稱為識別文本蘊(yùn)涵(RTE),判斷是否可以從一個文本中推斷出另一個文本的意義。
深度學(xué)習(xí)模型通過端到端的方式,學(xué)習(xí)特征的表達(dá)然后進(jìn)行分類。論文中,分析了超過150個深度學(xué)習(xí)模型,根據(jù)其神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行分類,并討論了各個模型的技術(shù)貢獻(xiàn)、相似性、優(yōu)點(diǎn)等等。之后論文提供了40多個文本分類任務(wù)數(shù)據(jù)集,并在16個基準(zhǔn)集上測試了不同的深度學(xué)習(xí)模型,最后討論了當(dāng)前的難點(diǎn)與未來的方向。
文本分類中的深度學(xué)習(xí)模型
本小節(jié)中回顧了150多個文本分類領(lǐng)域的深度學(xué)習(xí)模型,根據(jù)這些模型的主要結(jié)構(gòu)進(jìn)行分類介紹。這里假設(shè)大家對基礎(chǔ)深度學(xué)習(xí)模型較熟悉,如果想知道模型的更多細(xì)節(jié),請參考【1】。
前饋神經(jīng)網(wǎng)絡(luò)FNN
FNN雖然結(jié)構(gòu)簡單,但在很多文本分類任務(wù)上都有較高的準(zhǔn)確性。這類模型將文本看作詞袋,然后為每一個詞學(xué)習(xí)一個向量表示(類似word2vec,Glove),然后取所有向量的和或者平均,傳遞給前向傳播層(也叫多層感知機(jī)MLP),最后在輸入分類器(LR、NB、SVM等等)進(jìn)行分類。比如DAN模型,其結(jié)構(gòu)如下圖所示。與之類似的,如Facebook提出的FastText【2】模型,F(xiàn)astText較大的改進(jìn)是使用了n-gram作為補(bǔ)充特征。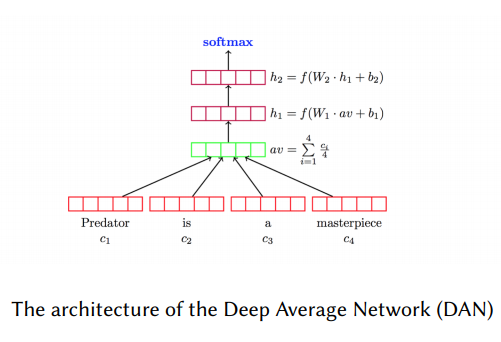
doc2vec使用非監(jiān)督方法,學(xué)習(xí)一段文本(句子、段落或篇章)的向量表示。如下圖所示,doc2vec的結(jié)構(gòu)跟CBOW模型相似,唯一的區(qū)別是doc2vec增加了一個段落token。doc2vec用前三個詞并結(jié)構(gòu)文檔向量預(yù)測第四個詞,文檔向量可以作為文檔主題記憶。在訓(xùn)練之后,文檔向量可以用作分類,在doc2vec發(fā)表的時候,在幾個文本分類以及情感分析任務(wù)上取得了SOTA的效果。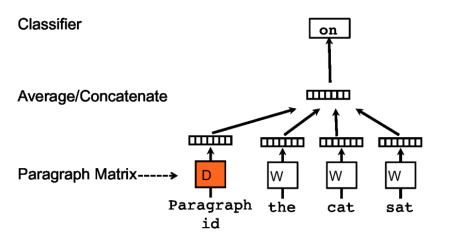
循環(huán)神經(jīng)網(wǎng)絡(luò)RNN
RNN類的模型將文本看作詞序列(如下圖左邊所示),通過獲取詞之間的依賴以及文本結(jié)構(gòu)信息進(jìn)行分類。RNN類最常見的結(jié)構(gòu)是LSTM,其緩解了RNN梯度消失的問題。Tree-LSTM是LSTM的樹型結(jié)構(gòu)擴(kuò)展(如下圖右邊所示),可以學(xué)到更豐富的語義表示,在情感分析與句子相似性判斷任務(wù)上證明了其有效性。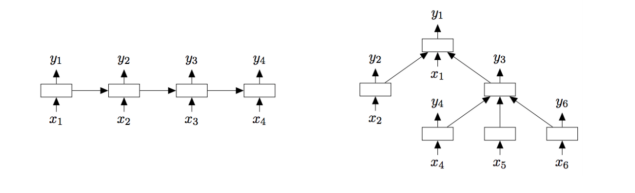
為了給長距離詞關(guān)系建模,研究人員使用記憶網(wǎng)絡(luò)替代了LSTM中的單個記憶單元,這在語言模型、情感分析、NLI任務(wù)上取得了很好的結(jié)果。MT-LSTM通過獲取不同時間尺度上的信息來給長文本建模,MT-LSTM將標(biāo)準(zhǔn)LSTM模型中隱藏狀態(tài)分成多個組,每組會在不同的時間階段激活并更新。TopicRNN結(jié)合了RNN與主題模型的有點(diǎn),用RNN獲取局部(句法)信息,用主題模型獲取全局(語義)信息,該模型在情感分析任務(wù)上取得了不錯的結(jié)果。
卷積神經(jīng)網(wǎng)絡(luò)CNN
RNN可以跨時間識別模式,而CNN可以跨空間識別模型。DCNN是最開始使用CNN做文本分類的模型之一,DCNN動態(tài)進(jìn)行k維最大池化(k根據(jù)語句長度與卷積層次進(jìn)行動態(tài)選擇),其結(jié)構(gòu)如下圖所示,輸入是詞向量,然后交替使用寬卷積層和動態(tài)池化層,該結(jié)構(gòu)可以捕獲詞語與短語間的長短期關(guān)系。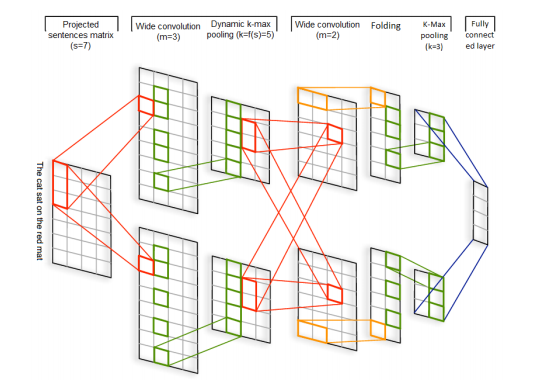
相比DCNN,TextCNN【3】的結(jié)構(gòu)更加簡單,如下圖所示,TextCNN只使用一層卷積,然后將整個文本序列的每一個卷積核的結(jié)果池化成一個值,拼接所有池化結(jié)果進(jìn)行最終預(yù)測。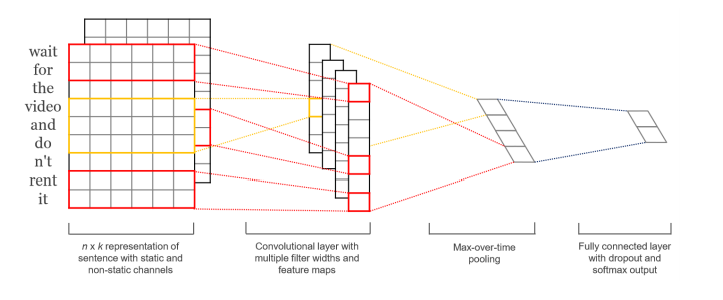
字符級別的CNN也被處理文本分類,如下圖所示模型結(jié)構(gòu),以固定長度的字符作為輸入,通過6層帶池化的卷積層和3層全連接層進(jìn)行預(yù)測。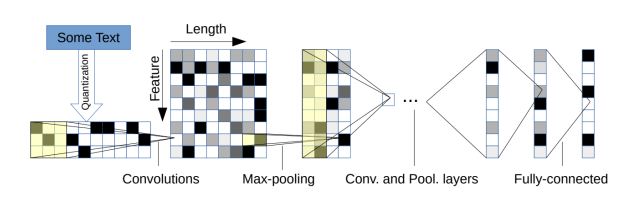
受VGG與ResNets的影響,研究人員提出了VDCNN模型,其也是直接處理字符輸入,且只是用了小卷積跟池化操作,研究表明隨著深度增加VDCNN的效果也在提高。后續(xù)有人對VDCNN做了改進(jìn),將模型大小壓縮了10到20倍,精度只損失了0.4%-0.3%。研究人員發(fā)現(xiàn),當(dāng)文本以字符序列作為輸入的時候,深層模型比淺層模型表現(xiàn)更好,但如果用詞作為輸入,一個淺且寬的模型(比如DenseNet)比深層模型效果更好。后續(xù)的論文發(fā)現(xiàn),使用非靜態(tài)的詞向量(word2vec、Glove)與最大池化操作可以獲得更優(yōu)的結(jié)果。
膠囊神經(jīng)網(wǎng)絡(luò)
CNN中的池化層會丟失一些信息,為了解決這個問題,Hinton提出了膠囊網(wǎng)絡(luò)(CapsNets)。一個膠囊是一組神經(jīng)元,神經(jīng)元中的向量表示實(shí)體的不同屬性,向量的長度表示實(shí)體存在的概率,方向表示實(shí)體的屬性。與池化操作不同,膠囊使用路由的方式,從底層的各個膠囊上路由到上層的父膠囊上,路由可以通過按協(xié)議動態(tài)路由或者EM等不同算法來實(shí)現(xiàn)。
基于膠囊網(wǎng)絡(luò),研究人員提出了對應(yīng)的文本分類模型,其包含一個n-gram卷積層,一個膠囊層,一個卷積膠囊層,一個全連接膠囊層。如下圖所示,他們研究了兩種膠囊網(wǎng)絡(luò),Capsule-A跟CapsNet比較類似,Capsule-B使用了帶有不同窗口大小過濾器的三個并行網(wǎng)絡(luò),試圖學(xué)習(xí)更全面的文本表示,實(shí)驗(yàn)中B的效果更好。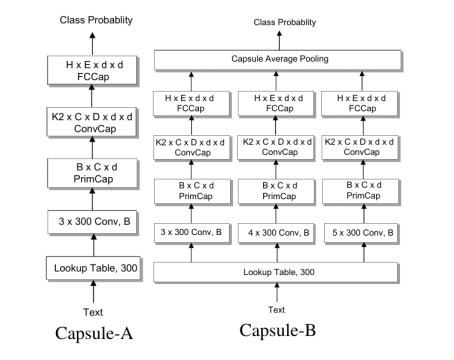
后續(xù)研究人員發(fā)現(xiàn),相比較于圖像,物體在文本中可以更加隨意地組合在一起,比如一些語句的順序改變,但文本的語義還可以保持一致,而不像人臉圖像,眼睛跟鼻子的位子變換,則就不能認(rèn)為是臉了。所以他們提出了一種靜態(tài)路由模式,在文本分類任務(wù)上,取得了優(yōu)于動態(tài)路由的效果。
注意力機(jī)制
注意力在NLP領(lǐng)域被廣泛使用,簡單來說,語言模型中的注意力就是一組重要性權(quán)重的向量。研究人員提出了層次注意力網(wǎng)絡(luò)來進(jìn)行文本分類,其主要有兩個特點(diǎn):反映了文檔的層次結(jié)構(gòu),在詞級別與句子級別分別使用了注意力機(jī)制,這個模型在6個文本分類任務(wù)上都取得了較大進(jìn)步。
在配對排序跟匹配任務(wù)上,研究人員提出了注意力池化(AP)方法。AP可以讓池化層知道當(dāng)前輸入對,來自兩個輸入的信息一定層度上可以直接影響對方的表示結(jié)果。如下圖所示,AP是一種獨(dú)立于底層表示學(xué)習(xí)的框架,也可以應(yīng)用在CNN、RNN等模型上。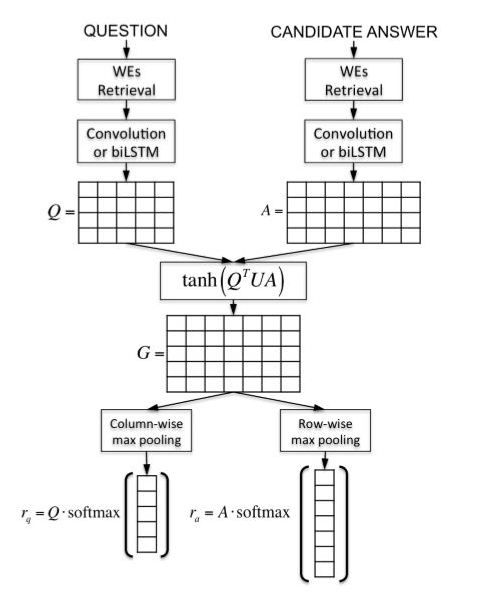
還有研究人員,將文本分類問題看作是標(biāo)簽-文本的匹配問題,如下圖所示,通過注意力框架與cosine相似度度量文本序列與標(biāo)簽之間的向量相似度。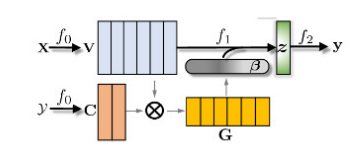
記憶增強(qiáng)網(wǎng)絡(luò)
在編碼過程中注意力模型里保存的隱藏向量可以認(rèn)為是模型的內(nèi)部記憶,記憶增強(qiáng)網(wǎng)絡(luò)結(jié)合了神經(jīng)網(wǎng)絡(luò)與外部記憶(模型可以讀出與寫入)。針對文本分類與QA任務(wù),研究人員提出了一種記憶增強(qiáng)網(wǎng)絡(luò)NSE(Neural Semantic Encoder),如下圖所示,NSE具有一個大小可變的編碼記憶存儲器,隨著時間進(jìn)行改變,并通過讀入、生成、寫入操作來保存對輸入序列的理解。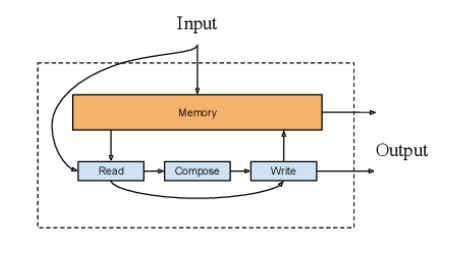
同樣針對QA任務(wù),有人將一系列的狀態(tài)(記憶實(shí)體)提供給模型,作為對問題的支持事實(shí),模型會學(xué)習(xí)如何根據(jù)問題與歷史檢索記憶來檢索實(shí)體,后續(xù)研究中,將該模型拓展為端到端的形式,通過注意力機(jī)制來實(shí)現(xiàn)實(shí)體檢索。
Transformers
RNN類模型在處理序列問題時需要很大的計算資源,而Transformers則避免了這一點(diǎn),通過使用self-attention來并行計算序列中每一個詞跟其他所有其的關(guān)系。自2018年開始,出現(xiàn)了很多基于Transformers的預(yù)訓(xùn)練語言模型(PLM),PLM一般具有很深的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),并且會在非常大的語料上進(jìn)行預(yù)訓(xùn)練(通過語言模型等任務(wù)來學(xué)習(xí)文本表示)。使用PLM進(jìn)行微調(diào),在很多下游NLP任務(wù)上都取得了SOTA的效果。
PLM大體可以分為兩類:自回歸與自編碼模型。OpenGPT就是自回歸模型之一,從左到右(或從右到左)在文本序列上一個詞一個詞預(yù)測的單向模型。如下圖所示,OpenGPT包含12層Transformer,每一個Transformers由遮蔽的多頭attention與全連接層組成,其中每一層都會加上殘差并做層標(biāo)準(zhǔn)化操作。文本分類任務(wù)可以作為其下游任務(wù),使用相關(guān)的線性分類器并在具體任務(wù)數(shù)據(jù)上微調(diào)就可以。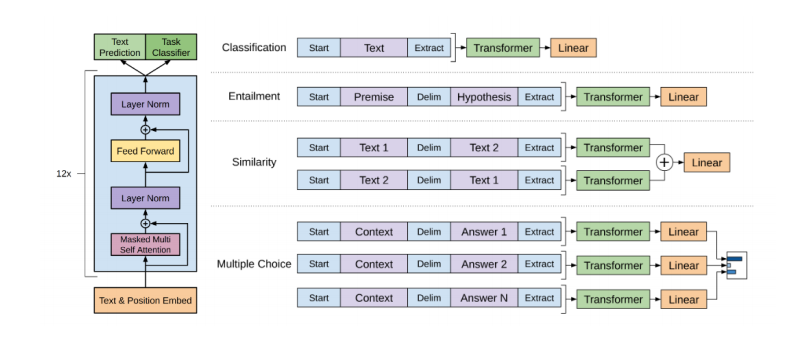
最為流行的自編碼預(yù)訓(xùn)練模型就是BERT了,BERT使用的是遮蔽語言模型來做訓(xùn)練,就是隨機(jī)遮蔽句子中的token,然后用雙向的Transformers根據(jù)上下文給遮蔽的token進(jìn)行編碼,從而預(yù)測被遮蔽的token。后續(xù)有很多BERT的拓展工作,RoBERTa在更大的訓(xùn)練集上進(jìn)行訓(xùn)練,使用了動態(tài)遮蔽的方式,并丟棄了下一句預(yù)測任務(wù),具有更魯棒的效果。ALBERT降低了模型的大小并提高了訓(xùn)練速度。DistillBERT在預(yù)訓(xùn)練過程使用知識蒸餾的方式,模型大小減少40%,保留了99%的精度,且推斷速度提高了60%。SpanBERT則能更好的表示與預(yù)測文本span。BERT類的模型在QA、文本分類、NLI等各種NLP任務(wù)上,都取得了很好的結(jié)果。
也有結(jié)合自回歸模型與自編碼模型各自有點(diǎn)的,比如XLNet,在預(yù)訓(xùn)練過程中那個,使用排序操作來同時獲取上下文信息。XLNet引入了雙流self-attention模式來處理排序語言模型,如下圖所示,它包含兩個attention,內(nèi)容attention(下圖a)就是標(biāo)準(zhǔn)的attention結(jié)構(gòu),查詢attention(下圖b)則不能看到當(dāng)前的token語義信息,只有當(dāng)前token的位置信息。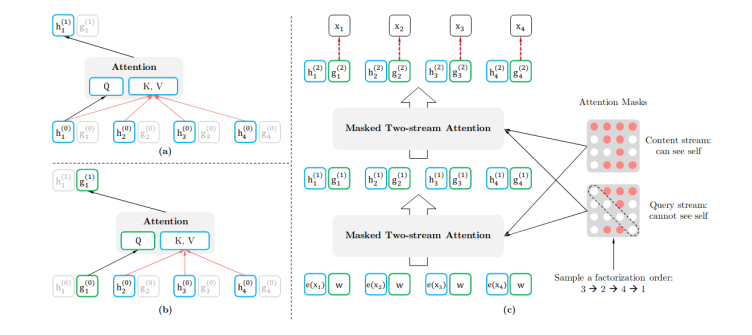 除此之外,UniLM(Unified language Model)使用了三種語言模型任務(wù)來進(jìn)行預(yù)訓(xùn)練:單向、雙向和seq2seq預(yù)測。如下圖所示,UniLM模型通過共享Transformers網(wǎng)絡(luò)來實(shí)現(xiàn),其中以特定的self-attention遮蔽來控制預(yù)測條件的上下文。
除此之外,UniLM(Unified language Model)使用了三種語言模型任務(wù)來進(jìn)行預(yù)訓(xùn)練:單向、雙向和seq2seq預(yù)測。如下圖所示,UniLM模型通過共享Transformers網(wǎng)絡(luò)來實(shí)現(xiàn),其中以特定的self-attention遮蔽來控制預(yù)測條件的上下文。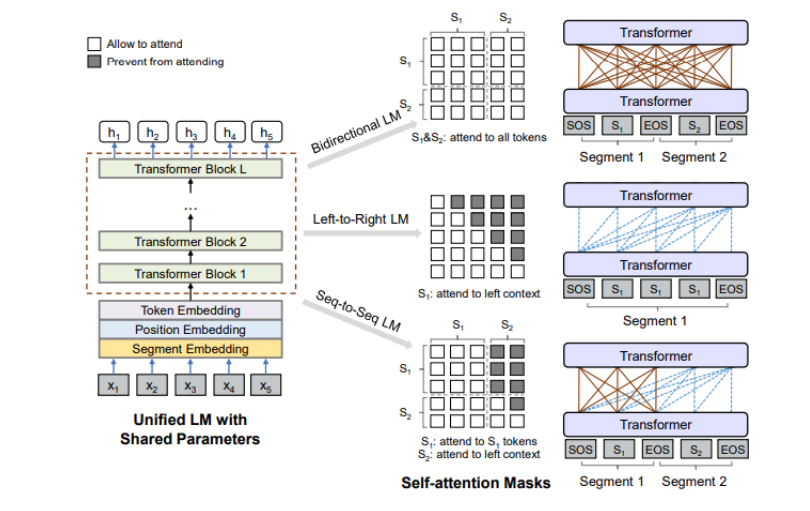
圖神經(jīng)網(wǎng)絡(luò)GNN
雖然文本是以序列的形式展現(xiàn),但其中也包含了圖結(jié)構(gòu),如句法和語義樹。NLP中最早的圖模型之一是TextRank,將文本看作一個圖,各種類型的文本單位,如單詞、搭配、整個句子等,可看作節(jié)點(diǎn),而節(jié)點(diǎn)之間的各種關(guān)系,如詞法或語義關(guān)系、上下文重疊等,可看作邊。
在GNN的各種類別中,GCN(Graph Convolutional Network)以及其變體是最流行的結(jié)構(gòu),因?yàn)槠溆行腋咝В诤芏鄳?yīng)用上都取得了SOTA的效果。如下圖所示,研究人員提出了基于graph-CNN模型,首先將文本轉(zhuǎn)換成詞圖,然后用圖卷積操作來處理詞圖,他們的實(shí)驗(yàn)表明,詞圖的表示能夠獲取文本中的非連續(xù)和長距離語義,并且CNN可以學(xué)習(xí)到不同層次的語義信息。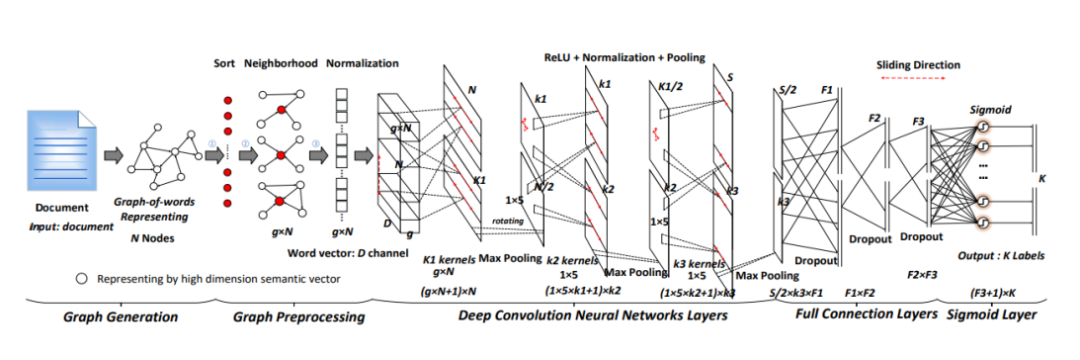
類似的,有研究人員提出了GCNN【4】方式來進(jìn)行文本分類,GCNN將整個語料構(gòu)建成一個單一的圖,通過詞貢獻(xiàn)關(guān)系與文檔-詞關(guān)系。如下圖所示,詞與文檔都是節(jié)點(diǎn),隨機(jī)初始化節(jié)點(diǎn)表示,然后用已知標(biāo)簽的文檔進(jìn)行有監(jiān)督訓(xùn)練,從而學(xué)到詞跟文檔的向量。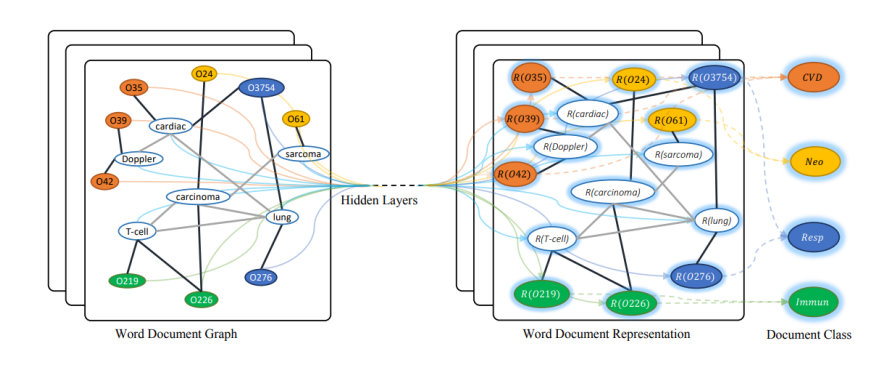
在大量文本上使用GNN代價比較大,一般會通過降低模型復(fù)雜度或者改變模型訓(xùn)練策略來減少成本。比如SGC(Simple Graph Convolution)【5】就是前面一種方法,移除了連續(xù)層之間的非線性轉(zhuǎn)換操作。后面一種方式則會對文檔層次進(jìn)行構(gòu)建圖,而不對整個語料構(gòu)圖。
孿生神經(jīng)網(wǎng)絡(luò)S2Net
S2Net或者其變體DSSM(Deep Structured Semantic Model)【6】主要是針對文本匹配問題的。如下圖所示,DSSM(或者S2Net)包含了一對DNN結(jié)構(gòu)(f1、f2),將x、y分別映射到一個低緯語義空間,然后根據(jù)cosine距離(或其他方法)計算其相似度。S2Net中假設(shè)f1與f2具有一樣的結(jié)果甚至一樣的參數(shù),但在DSSM中這兩個可以根據(jù)實(shí)際情況具有不同的結(jié)構(gòu)。因?yàn)槲谋疽孕蛄械男问秸宫F(xiàn),所以通常會用RNN類的結(jié)構(gòu)來實(shí)現(xiàn)f1、f2,后來也有人使用CNN等其他結(jié)構(gòu),在BERT出現(xiàn)之后,也有不少基于BERT的模型,比如SBERT、TwinBERT等等。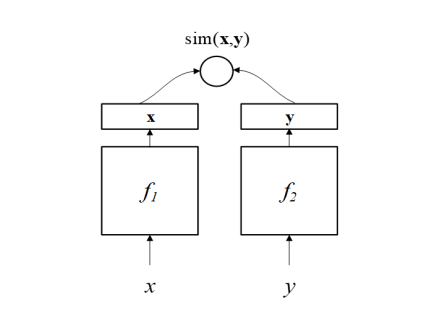
混合模型
很多混合模型都會結(jié)合LSTM與CNN結(jié)構(gòu)來獲取局部特征與全局特征,比如C-LSTM(Convolutional LSTM)與DSCNN(Dependency Sensitive CNN)。如下圖a所示,C-LSTM先用CNN提取文本短語(n-gram)表示,然后輸入LSTM獲取句子的表示。而DSCNN如下圖b所示,先用LSTM獲取學(xué)習(xí)句向量,然后輸入CNN生成文本表示。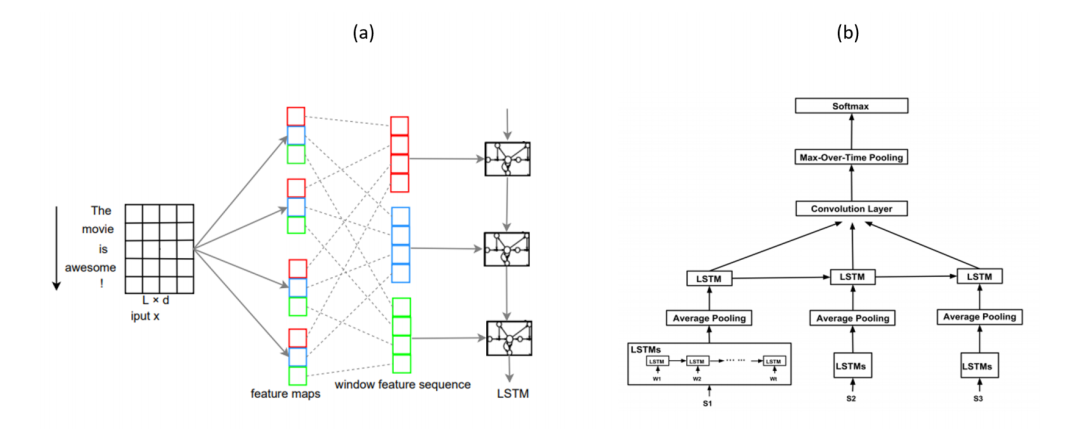
針對閱讀理解中的多步推理,有人提出了SAN模型(Stochastic Answer Network),如下圖所示,SAN包含了很多結(jié)構(gòu),如記憶網(wǎng)絡(luò)、注意力機(jī)制、LSTM、CNN。其中Bi-LSTM組件來獲取問題與短文的內(nèi)容表示,再用基于問題感知的注意力機(jī)制學(xué)習(xí)短文表示。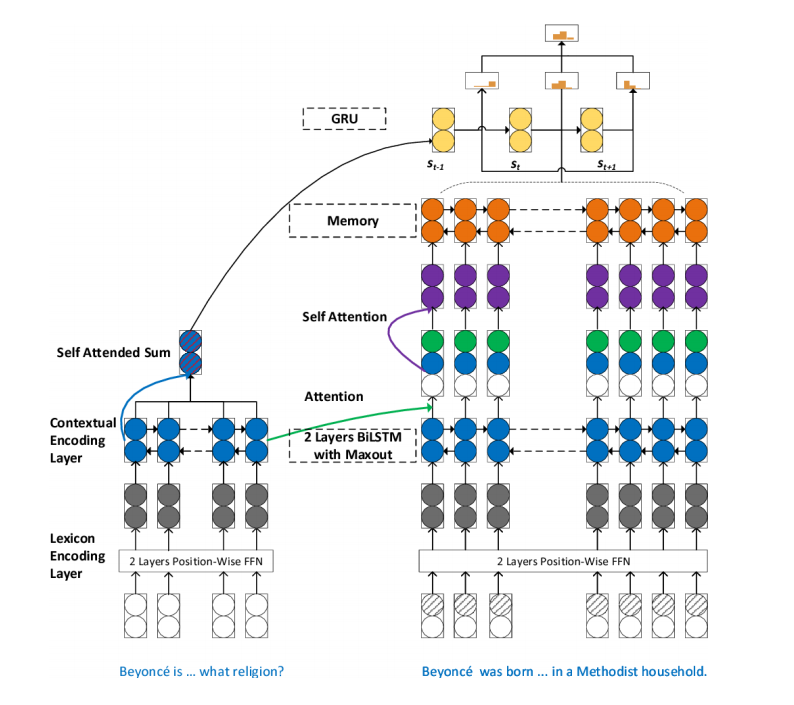
還有一些研究聚焦于“高速公路”網(wǎng)絡(luò),隨著模型深度的增加,基于梯度訓(xùn)練的網(wǎng)絡(luò)就變得更加困難,“高速公路”網(wǎng)絡(luò)就是設(shè)計來解決這種問題,其允許信息在多個層上無阻地流動,有點(diǎn)類似于ResNet。如下圖結(jié)構(gòu)所示,是一種基于字符的語言模型,先用CNN獲取詞表示,然后輸入到“高速公路”網(wǎng)絡(luò),然后接LSTM模型,最后用softmax來預(yù)測每個詞的概率。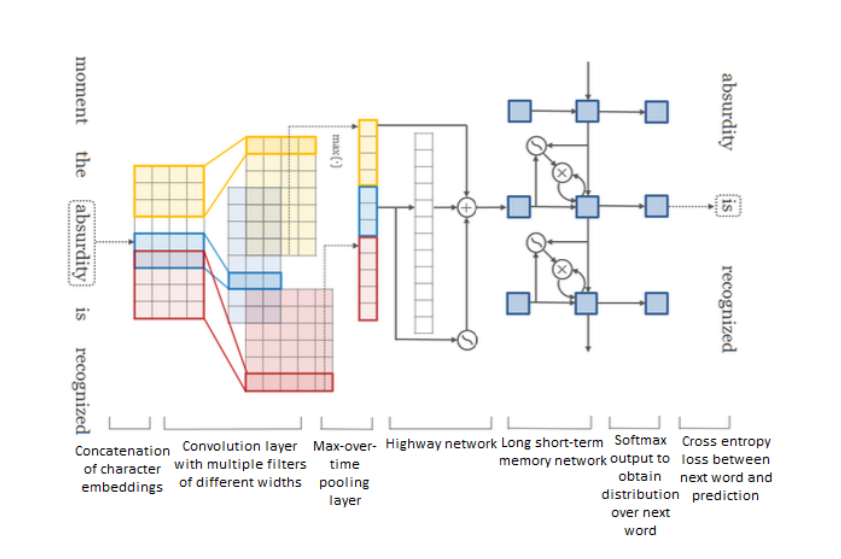
非監(jiān)督學(xué)習(xí)
自編碼的無監(jiān)督學(xué)習(xí)
跟詞向量類似,通過優(yōu)化一些輔助目標(biāo),如自編碼器的重構(gòu)loss,可以用非監(jiān)督的形式學(xué)習(xí)句子的表示。對抗訓(xùn)練
對抗訓(xùn)練是提高分類器泛化能力的一種方法,通過擾動輸入數(shù)據(jù)生成對抗樣本,來提高模型的魯棒性。強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)是訓(xùn)練代理根據(jù)策略執(zhí)行某些動作的方法,通常用最大化獎勵來進(jìn)行訓(xùn)練。
文本分類數(shù)據(jù)集
情感分析數(shù)據(jù)集
Yelp
Yelp有兩種數(shù)據(jù)集,Yelp-5(細(xì)粒度情感標(biāo)簽)、Yelp-2(正負(fù)情感)。Yelp-5的每個類別都有650000個訓(xùn)練樣本,50000個測試樣本,Yelp-2一共包含560000個訓(xùn)練樣本和38000個測試樣本。IMDB
IMDB是影視評論數(shù)據(jù)集,包含同樣數(shù)目的正例與負(fù)列,訓(xùn)練集與測試集各有25000個。Movie Review(MR)
MR也是正負(fù)兩極的影評數(shù)據(jù),正負(fù)樣本數(shù)量一致,共10662條。SST
SST是MR數(shù)據(jù)集的拓展,有兩類SST-1(細(xì)粒度標(biāo)簽,5類)、SST-2(兩類標(biāo)簽)。SST-1中包含8455個訓(xùn)練樣本1101個驗(yàn)證樣本和2210個測試樣本。SST-2中包行6920個訓(xùn)練樣本872個樣本樣本和1821個測試樣本。MPQA
MPQA是兩個標(biāo)簽的意見語料庫,有3311個正樣本,7293個負(fù)樣本。Amazon Amazon是商品評價數(shù)據(jù)集,也有兩種:Amazon-2(2標(biāo)簽)、Amazon-5(5標(biāo)簽)。Amazon-2分別有3600000個訓(xùn)練數(shù)據(jù)和400000個測試數(shù)據(jù),Amazon-5有3000000個訓(xùn)練數(shù)據(jù)650000個測試數(shù)據(jù)。 其他
SemEval-2014、Twitter、SentiHood。新聞分類數(shù)據(jù)集
AG News
AG News4標(biāo)簽的短文本學(xué)術(shù)新聞數(shù)據(jù),有120000個訓(xùn)練樣本和7600個測試樣本。20 Newsgroups
20 Newsgroups有20個類別,最流行的一版有18821個樣本,每個類別樣本量一致。Sougo News
中文分類數(shù)據(jù)集Reuters news
Reuters-21578有90個類別,7769個訓(xùn)練數(shù)據(jù)和3019個測試數(shù)據(jù)。其他
Bing news, NYTimes, BBC, Google news。主題分類數(shù)據(jù)集
DBpedia
DBpedia數(shù)據(jù)集是一個大規(guī)模的、多語言的知識庫,是從Wikipedia中最常用的信息框創(chuàng)建的。DBpedia每月發(fā)布一次,在每次發(fā)布中添加或刪除一些類和屬性。DBpedia最流行的版本包含560,000個訓(xùn)練樣本和70,000個測試樣本,每個樣本都有一個14個類的標(biāo)簽。Ohsumed
Ohsumed集合是MEDLINE數(shù)據(jù)庫的一個子集。Ohsumed包含7400個文檔。每個文檔都是醫(yī)學(xué)摘要,從23種心血管疾病類別中選出一個或多個類別作為標(biāo)簽。EUR-Lex
該數(shù)據(jù)集最流行的版本基于歐盟法律的不同方面,有19,314個文檔和3,956個類別。WOS
科學(xué)網(wǎng)絡(luò)(WOS)數(shù)據(jù)集是科學(xué)網(wǎng)絡(luò)上可獲得的已發(fā)表論文的數(shù)據(jù)和元數(shù)據(jù)的集合。PubMed
PubMed是美國國家醫(yī)學(xué)圖書館為醫(yī)學(xué)和生物科學(xué)論文開發(fā)的搜索引擎。其他
PubMed 200k RCT,Irony。問答數(shù)據(jù)集
SQuAD
斯坦福問答數(shù)據(jù)集是一個從維基百科文章衍生的問答對的集合。SQuAD1.1包含536篇文章與107785個問答對。SQuAD2.0包含了1.1中的10000個問答對以及50000個沒有答案的問題。MS MARCO
該數(shù)據(jù)集由微軟發(fā)布,其中有部分答案是生成式的,所以該數(shù)據(jù)集也可以用來開發(fā)生成式問答系統(tǒng)。TREC-QA
這個數(shù)據(jù)集有兩個版本,稱為TREC-6(6個類型問題)和TREC-50(50個類型的問題)。這兩個版本,訓(xùn)練和測試數(shù)據(jù)集分別包含5452和500個問題。WikiQA
該模型還包含沒有答案的問題。Quora
Quora數(shù)據(jù)集是為檢測重復(fù)問題,其中包含400000個問題對。其他
SWAG、WikiQA、SelQA。自然語言推理數(shù)據(jù)集
SNLI
斯坦福自然語言推斷(SNLI)數(shù)據(jù)集被廣泛用于NLI。該數(shù)據(jù)集由550,152,10,000和10,000句對組成,分別用于訓(xùn)練,開發(fā)和測試。每一對都標(biāo)注有三個標(biāo)簽:中性,含蓄,矛盾。Multi-NLI
該語料庫是SNLI的延伸,由433k個句子對組成的集合。SICK
SICK共有10000對句子對,同樣包含中性,含蓄,矛盾三種標(biāo)簽。MSRP
MSRP是常見的文本相似度數(shù)據(jù)集,包含4076條訓(xùn)練樣本與1725條測試樣本。其他
STS、RTE、SciTail。
下圖顯示了各個數(shù)據(jù)集以及數(shù)據(jù)量的大小。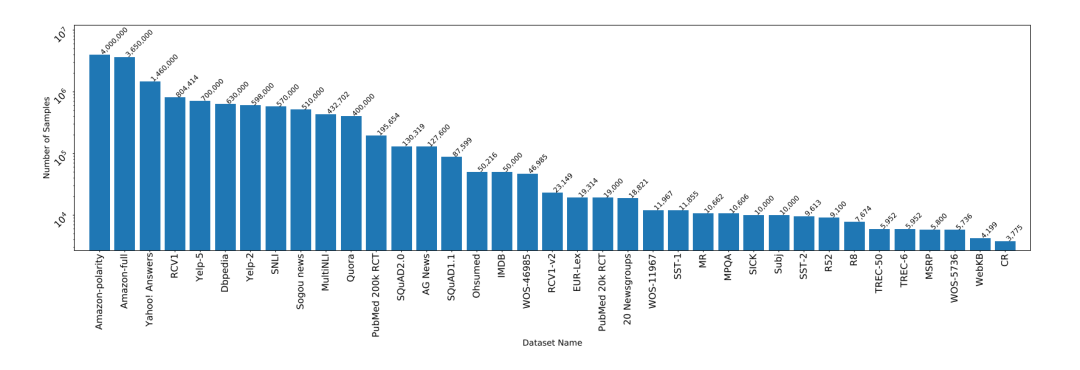
實(shí)驗(yàn)性能分析
文本分類常用指標(biāo)
準(zhǔn)確度和錯誤率 精度/召回/ F1得分 精確匹配(EM)
EM是問答系統(tǒng)的常用指標(biāo),其衡量了預(yù)測值跟任意一個正確答案匹配的比例。平均倒數(shù)排序(MRR)
MRR用來衡量排序問題或者QA問題,計算公式如下,其中Q表示所有預(yù)測答案,表示第i個預(yù)測答案在真實(shí)答案中的排序。
其他
NAP,ACU等。
定量分析結(jié)果
情感分析結(jié)果 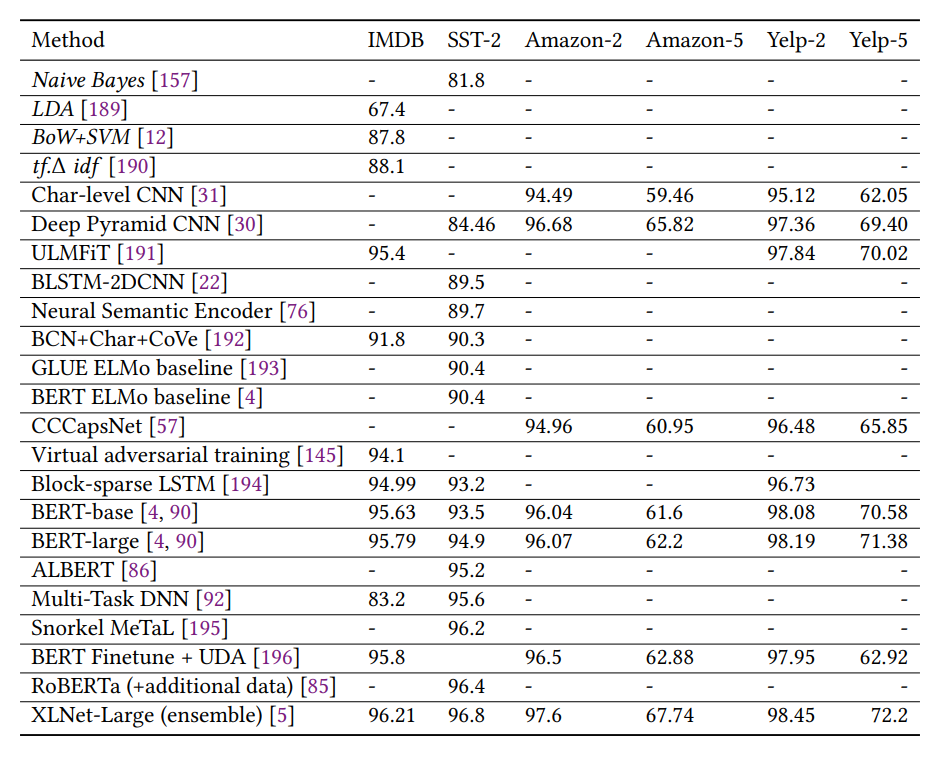
新聞分類和主題分類結(jié)果 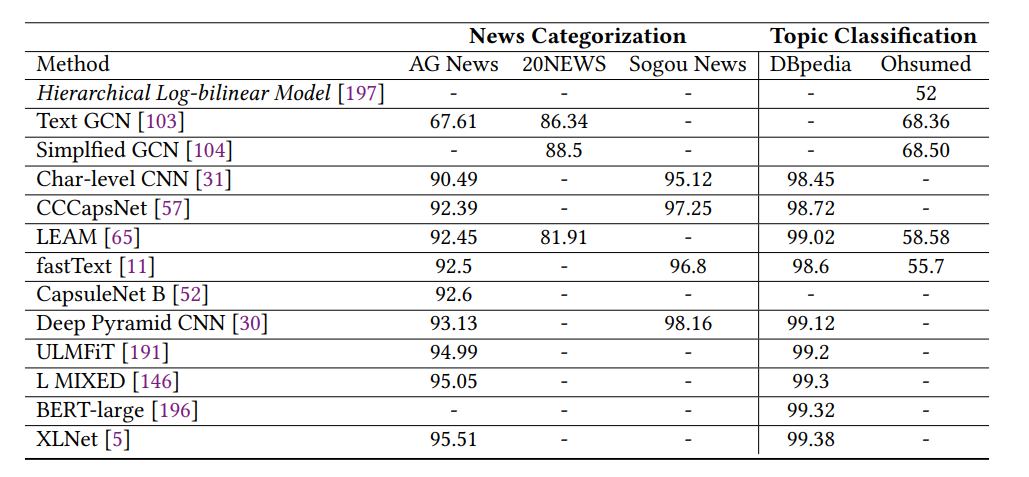
問答結(jié)果 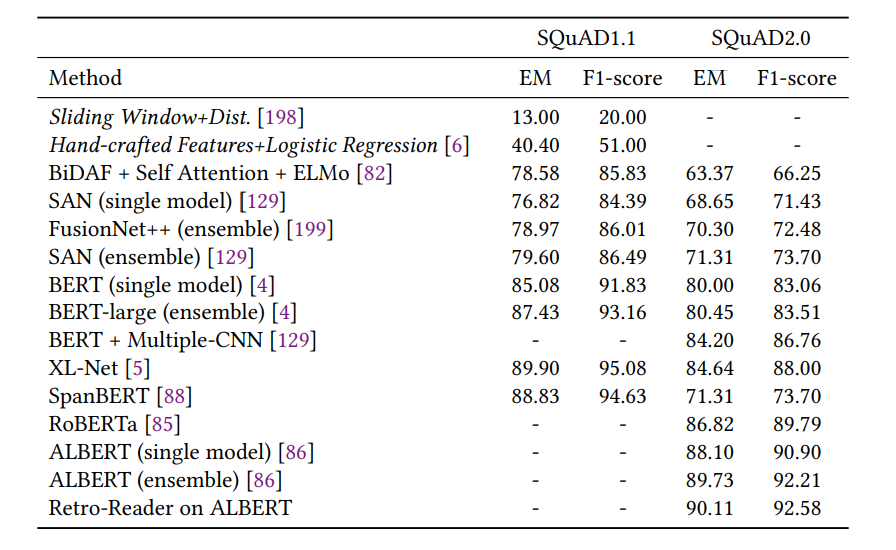
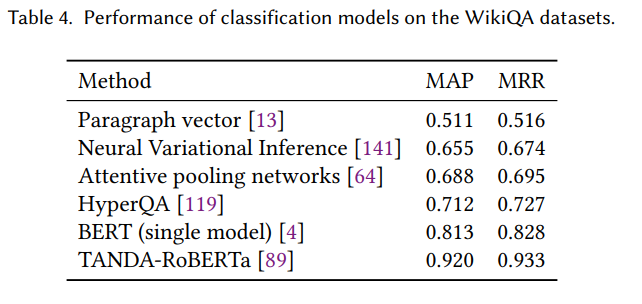
自然語言推理結(jié)果 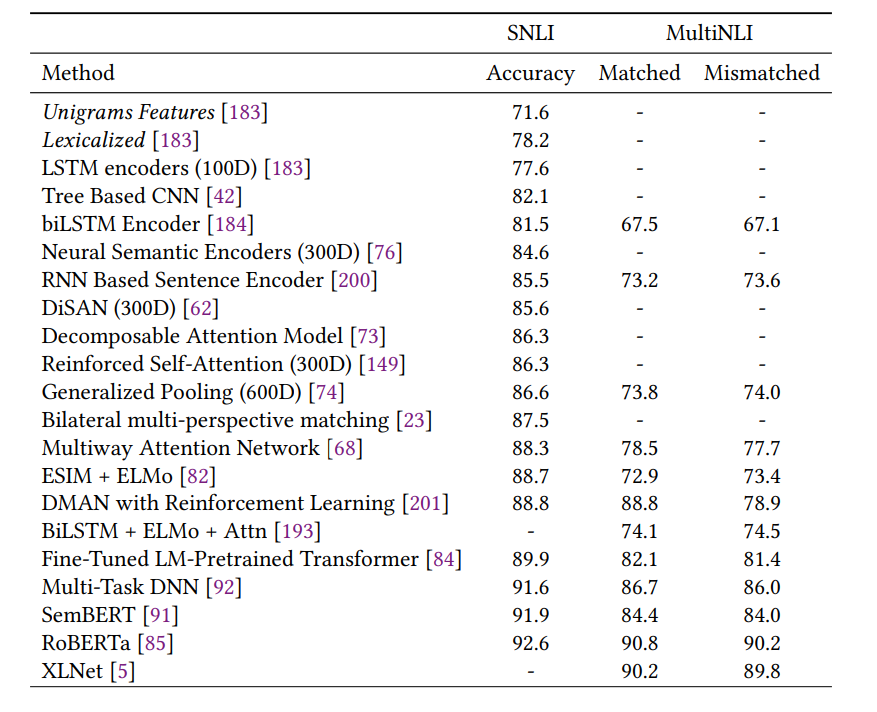
挑戰(zhàn)與機(jī)遇
更有挑戰(zhàn)性的新數(shù)據(jù)集 常識知識模型化 深度學(xué)習(xí)模型的可解釋性 模型容量高效化 少樣本或零樣本學(xué)習(xí)
參考
【1】Deep learning
【2】FASTTEXT.ZIP:COMPRESSING TEXT CLASSIFICATION MODELS
【3】Convolutional Neural Networks for Sentence Classi?cation
【4】Graph Convolutional Networks for Text Classification
【5】Simplifying Graph Convolutional Networks
【6】Learning Deep Structured Semantic Models ?for Web Search using Clickthrough Data
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群請掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請說明):