本文帶你了解了Bagging思想及其原理,以及基于Bagging的隨機(jī)森林相關(guān)知識。
我們在生活中做出的許多決定都是基于其他人的意見,而通常情況下由一群人做出的決策比由該群體中的任何一個(gè)成員做出的決策會(huì)產(chǎn)生更好的結(jié)果,這被稱為群體的智慧。集成學(xué)習(xí)(Ensemble Learning)類似于這種思想,集成學(xué)習(xí)結(jié)合了來自多個(gè)模型的預(yù)測,旨在比集成該學(xué)習(xí)器的任何成員表現(xiàn)得更好,從而提升預(yù)測性能(模型的準(zhǔn)確率),預(yù)測性能也是許多分類和回歸問題的最重要的關(guān)注點(diǎn)。
集成學(xué)習(xí)(Ensemble Learning)是將若干個(gè)弱分類器(也可以是回歸器)組合從而產(chǎn)生一個(gè)新的分類器。(弱分類器是指分類準(zhǔn)確率略好于隨機(jī)猜想的分類器,即error rate < 0.5)。集成機(jī)器學(xué)習(xí)涉及結(jié)合來自多個(gè)熟練模型的預(yù)測,該算法的成功在于保證弱分類器的多樣性。而且集成不穩(wěn)定的算法也能夠得到一個(gè)比較明顯的性能提升。集成學(xué)習(xí)是一種思想。當(dāng)預(yù)測建模項(xiàng)目的最佳性能是最重要的結(jié)果時(shí),集成學(xué)習(xí)方法很受歡迎,通常是首選技術(shù)。(1) 性能更好:與任何單個(gè)模型的貢獻(xiàn)相比,集成可以做出更好的預(yù)測并獲得更好的性能;(2) 魯棒性更強(qiáng):集成減少了預(yù)測和模型性能的傳播或分散,平滑了模型的預(yù)期性能。(3) 更加合理的邊界:弱分類器間存在一定差異性,導(dǎo)致分類的邊界不同。多個(gè)弱分類器合并后,就可以得到更加合理的邊界,減少整體的錯(cuò)誤率,實(shí)現(xiàn)更好的效果;(4) 適應(yīng)不同樣本體量:對于樣本的過大或者過小,可分別進(jìn)行劃分和有放回的操作產(chǎn)生不同的樣本子集,再使用樣本子集訓(xùn)練不同的分類器,最后進(jìn)行合并;(5) 易于融合:對于多個(gè)異構(gòu)特征數(shù)據(jù)集,很難進(jìn)行融合,可以對每個(gè)數(shù)據(jù)集進(jìn)行建模,再進(jìn)行模型融合。機(jī)器學(xué)習(xí)建模的偏差和方差機(jī)器學(xué)習(xí)模型產(chǎn)生的錯(cuò)誤通常用兩個(gè)屬性來描述:偏差和方差。
偏差是衡量模型可以捕獲輸入和輸出之間的映射函數(shù)的接近程度。它捕獲了模型的剛性:模型對輸入和輸出之間映射的函數(shù)形式的假設(shè)強(qiáng)度。
模型的方差是模型在擬合不同訓(xùn)練數(shù)據(jù)時(shí)的性能變化量。它捕獲數(shù)據(jù)的細(xì)節(jié)對模型的影響。
理想情況下,我們更喜歡低偏差和低方差的模型,事實(shí)上,這也是針對給定的預(yù)測建模問題應(yīng)用機(jī)器學(xué)習(xí)的目標(biāo)。模型性能的偏差和方差是相關(guān)的,減少偏差通常可以通過增加方差來輕松實(shí)現(xiàn)。相反,通過增加偏差可以很容易地減少方差。
與單個(gè)預(yù)測模型相比,集成用在預(yù)測建模問題上實(shí)現(xiàn)更好的預(yù)測性能。實(shí)現(xiàn)這一點(diǎn)的方式可以理解為模型通過添加偏差來減少預(yù)測誤差的方差分量(即權(quán)衡偏差-方差的情況下)。
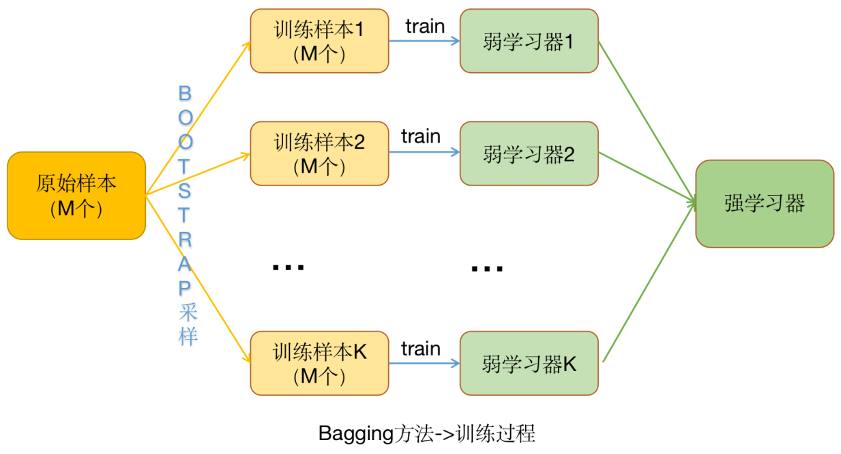
Bagging又稱自舉匯聚法(Bootstrap Aggregating),涉及在同一數(shù)據(jù)集的不同樣本上擬合許多學(xué)習(xí)器并對預(yù)測進(jìn)行平均,通過改變訓(xùn)練數(shù)據(jù)來尋找多樣化的集成成員。
Bagging思想就是在原始數(shù)據(jù)集上通過有放回的抽樣,重新選擇出N個(gè)新數(shù)據(jù)集來分別訓(xùn)練N個(gè)分類器的集成技術(shù)。模型訓(xùn)練數(shù)據(jù)中允許存在重復(fù)數(shù)據(jù)。
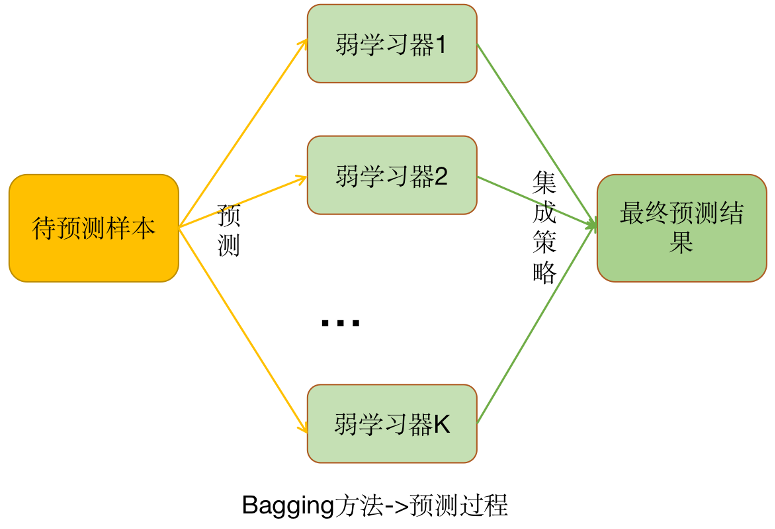
使用Bagging方法訓(xùn)練出來的模型在預(yù)測新樣本分類的時(shí)候,會(huì)使用多數(shù)投票或者取平均值的策略來統(tǒng)計(jì)最終的分類結(jié)果。
基于Bagging的弱學(xué)習(xí)器(分類器/回歸器)可以是基本的算法模型,如Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN、Naive Bayes等。
隨機(jī)森林是在Bagging策略的基礎(chǔ)上進(jìn)行修改后的一種算法,方法如下:
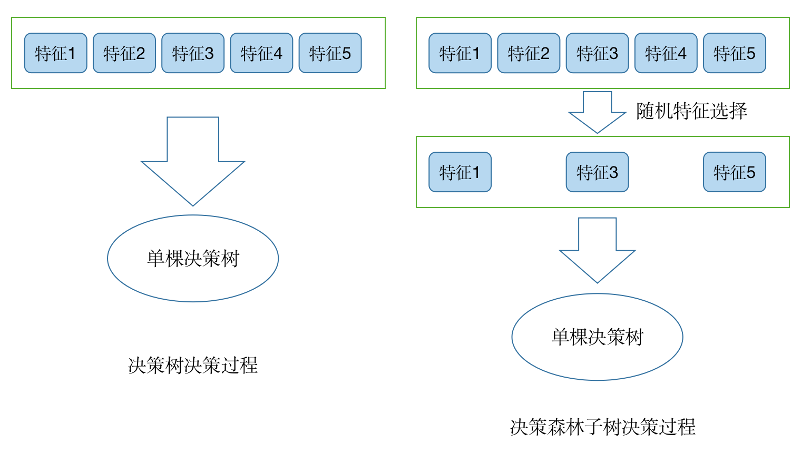
(1) 使用Bootstrap策略從樣本集中進(jìn)行數(shù)據(jù)采樣;(2) 從所有特征中隨機(jī)選擇K個(gè)特征,構(gòu)建正常決策樹;(3) 重復(fù)1,2多次,構(gòu)建多棵決策樹;(4) 集成多棵決策樹,形成隨機(jī)森林,通過投票表決或取平均值對數(shù)據(jù)進(jìn)行決策。
在隨機(jī)森林中可以發(fā)現(xiàn)Bootstrap采樣每次約有1/3的樣本不會(huì)出現(xiàn)在Bootstrap所采樣的樣本集合中,當(dāng)然也沒有參加決策樹的建立,而這部分?jǐn)?shù)據(jù)稱之為袋外數(shù)據(jù)OOB(out of bag),它可以用于取代測試集誤差估計(jì)方法。
對于已經(jīng)生成的隨機(jī)森林,用袋外數(shù)據(jù)測試其性能,假設(shè)袋外數(shù)據(jù)總數(shù)為O,用這O個(gè)袋外數(shù)據(jù)作為輸入,帶進(jìn)之前已經(jīng)生成的隨機(jī)森林分類器,分類器會(huì)給出O個(gè)數(shù)據(jù)相應(yīng)的分類,因?yàn)檫@O條數(shù)據(jù)的類型是已知的,則用正確的分類與隨機(jī)森林分類器的結(jié)果進(jìn)行比較,統(tǒng)計(jì)隨機(jī)森林分類器分類錯(cuò)誤的數(shù)目,設(shè)為X,則袋外數(shù)據(jù)誤差大小為X/O。
優(yōu)點(diǎn):這已經(jīng)經(jīng)過證明是無偏估計(jì)的,所以在隨機(jī)森林算法中不需要再進(jìn)行交叉驗(yàn)證或者單獨(dú)的測試集來獲取測試集誤差的無偏估計(jì)。
缺點(diǎn):當(dāng)數(shù)據(jù)量較小時(shí),Bootstrap采樣產(chǎn)生的數(shù)據(jù)集改變了初始數(shù)據(jù)集的分布,這會(huì)引入估計(jì)偏差。RF算法在實(shí)際應(yīng)用中具有比較好的特性,應(yīng)用也比較廣泛,主要應(yīng)用在:分類、歸回、特征轉(zhuǎn)換、異常點(diǎn)檢測等。以下為常見的RF變種算法:Extra-Trees(Extremely randomized trees,極端隨機(jī)樹)是由Pierre Geurts等人于2006年提出。是RF的一個(gè)變種,原理基本和RF一樣。但該算法與隨機(jī)森林有兩點(diǎn)主要的區(qū)別:
(1) 隨機(jī)森林會(huì)使用Bootstrap進(jìn)行隨機(jī)采樣,作為子決策樹的訓(xùn)練集,應(yīng)用的是Bagging模型;而ET使用所有的訓(xùn)練樣本對每棵子樹進(jìn)行訓(xùn)練,也就是ET的每個(gè)子決策樹采用原始樣本訓(xùn)練;(2) 隨機(jī)森林在選擇劃分特征點(diǎn)的時(shí)候會(huì)和傳統(tǒng)決策樹一樣(基于信息增益、信息增益率、基尼系數(shù)、均方差等),而ET是完全隨機(jī)的選擇劃分特征來劃分決策樹。
對于某棵決策樹,由于它的最佳劃分特征是隨機(jī)選擇的,因此它的預(yù)測結(jié)果往往是不準(zhǔn)確的,但是多棵決策樹組合在一起,就可以達(dá)到很好的預(yù)測效果。
當(dāng)ET構(gòu)建完成,我們也可以應(yīng)用全部訓(xùn)練樣本得到該ET的誤差。因?yàn)楸M管構(gòu)建決策樹和預(yù)測應(yīng)用的都是同一個(gè)訓(xùn)練樣本集,但由于最佳劃分屬性是隨機(jī)選擇的,所以我們?nèi)匀粫?huì)得到完全不同的預(yù)測結(jié)果,用該預(yù)測結(jié)果就可以與樣本的真實(shí)響應(yīng)值比較,從而得到預(yù)測誤差。如果與隨機(jī)森林相類比的話,在ET中,全部訓(xùn)練樣本都是OOB樣本,所以計(jì)算ET的預(yù)測誤差,也就是計(jì)算這個(gè)OOB誤差。
由于Extra Trees是隨機(jī)選擇特征值的劃分點(diǎn),會(huì)導(dǎo)致決策樹的規(guī)模一般大于RF所生成的決策樹。也就是說Extra Trees模型的方差相對于RF進(jìn)一步減少。在某些情況下,ET具有比隨機(jī)森林更強(qiáng)的泛化能力。
Totally Random Trees Embedding (TRTE)TRTE是一種非監(jiān)督學(xué)習(xí)的數(shù)據(jù)轉(zhuǎn)化方式。它將低維的數(shù)據(jù)映射到高維,從而讓映射到高維的數(shù)據(jù)更好的應(yīng)用于分類回歸模型。
TRTE算法的轉(zhuǎn)換過程類似RF算法的方法,建立T個(gè)決策樹來擬合數(shù)據(jù)。當(dāng)決策樹構(gòu)建完成后,數(shù)據(jù)集里的每個(gè)數(shù)據(jù)在T個(gè)決策子樹中葉子節(jié)點(diǎn)的位置就定下來了,將位置信息轉(zhuǎn)換為向量就完成了特征轉(zhuǎn)換操作。
例如,有3棵決策樹,每棵決策樹有5個(gè)葉子節(jié)點(diǎn),某個(gè)數(shù)據(jù)特征x劃分到第一個(gè)決策樹的第3個(gè)葉子節(jié)點(diǎn),第二個(gè)決策樹的第1個(gè)葉子節(jié)點(diǎn),第三個(gè)決策樹的第5個(gè)葉子節(jié)點(diǎn)。則x映射后的特征編碼為(0,0,1,0,0 1,0,0,0,0 0,0,0,0,1),有15維的高維特征。特征映射到高維之后,就可以進(jìn)一步進(jìn)行監(jiān)督學(xué)習(xí)。
Isolation Forest (IForest)IForest是一種異常點(diǎn)檢測算法,使用類似RF的方式來檢測異常點(diǎn);IForest算法和RF算法的區(qū)別在于:
(1) 在隨機(jī)采樣的過程中,一般只需要少量數(shù)據(jù)即可;(2) 在進(jìn)行決策樹構(gòu)建過程中,IForest算法會(huì)隨機(jī)選擇一個(gè)劃分特征,并對劃分特征隨機(jī)選擇一個(gè)劃分閾值;(3) IForest算法構(gòu)建的決策樹一般深度max_depth是比較小的。
IForest的目的是異常點(diǎn)檢測,所以只要能夠區(qū)分異常數(shù)據(jù)即可,不需要大量數(shù)據(jù);另外在異常點(diǎn)檢測的過程中,一般不需要太大規(guī)模的決策樹。
對于異常點(diǎn)的判斷,則是將測試樣本x擬合到T棵決策樹上。計(jì)算在每棵樹上該樣本的葉子結(jié)點(diǎn)的深度ht(x)。從而計(jì)算出平均深度h(x);然后就可以使用下列公式計(jì)算樣本點(diǎn)x的異常概率值,p(s,m)的取值范圍為[0,1],越接近于1,則是異常點(diǎn)的概率越大。m為樣本個(gè)數(shù),ξ 為歐拉常數(shù)隨機(jī)森林優(yōu)缺點(diǎn)總結(jié)本期AI小課堂我們一起了解了Bagging思想及其原理,以及基于Bagging的隨機(jī)森林相關(guān)知識。最后,讓我們一起總結(jié)下隨機(jī)森林的優(yōu)缺點(diǎn):(1) 訓(xùn)練可以并行化,對于大規(guī)模樣本的訓(xùn)練具有速度的優(yōu)勢;(2) 由于進(jìn)行隨機(jī)選擇決策樹劃分特征列表,這樣在樣本維度比較高的時(shí)候,仍然具有比較好的訓(xùn)練性能;(3) 由于存在隨機(jī)抽樣,訓(xùn)練出來的模型方差小,泛化能力強(qiáng);
(2) 取值比較多的劃分特征對RF的決策會(huì)產(chǎn)生更大的影響,從而有可能影響模型的效果。校對:林亦霖

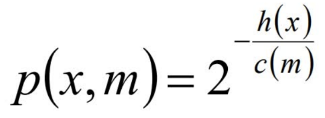
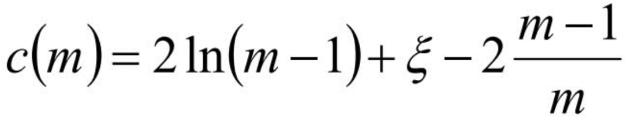
 下載APP
下載APP