
Kaggle競(jìng)賽入門實(shí)戰(zhàn)——機(jī)器學(xué)習(xí)預(yù)測(cè)房屋價(jià)格
本文會(huì)全面地介紹完成一個(gè)小項(xiàng)目的流程,如何在科學(xué)分析的輔助下預(yù)測(cè)出我們需要的目標(biāo)值。
(數(shù)據(jù)集和源碼下載見文末)

在分析之前我們應(yīng)該提前明確我們的目的,中途可能需要處理的問題,可以歸納成以下幾點(diǎn):
了解標(biāo)簽變量:可以通過目標(biāo)變量大致分析出解決問題是需要分類算法還是回歸算法。 粗略了解特征:因?yàn)樘卣鳂?biāo)簽都為英文,所以理解標(biāo)簽含義是最基本的,觀察每個(gè)特征的特點(diǎn),是數(shù)值型的、還是字符型的;是離散的、還是連續(xù)的;粗略聯(lián)想一下各個(gè)特征與目標(biāo)變量間的聯(lián)系。 數(shù)據(jù)預(yù)處理:針對(duì)性處理數(shù)據(jù)集中的缺失數(shù)據(jù)和異常數(shù)據(jù)。 研究主要特征:數(shù)據(jù)集中可能只有一部分特征與目標(biāo)變量間相關(guān)性極強(qiáng),重點(diǎn)分析這些特征與目標(biāo)變量間的聯(lián)系。 選擇性處理其他特征:除主要特征外,可能主觀上認(rèn)為某些特征也會(huì)影響目標(biāo)變量,也可以選擇性分析一下。 建模工作:選出最適合該問題的模型,進(jìn)行建模、調(diào)參等操作。
由于每個(gè)人的習(xí)慣不同,所以處理問題時(shí)的先后順序、選擇的方法自然也不同,比如說處理缺失值的方法就有很多種,本文提及的流程、方法只是個(gè)人的一點(diǎn)小思路,希望給伙伴們參考,但絕不局限于此,不論算法還是模型不都應(yīng)該向更優(yōu)處發(fā)展嘛。
首先一定要大致了解一下測(cè)試數(shù)據(jù)集,上圖只是數(shù)據(jù)集的一小部分,共80個(gè)特征+一個(gè)目標(biāo)變量“SalePrice”,共有1460個(gè)樣本。很明顯這個(gè)問題是需要通過房子的一些特征預(yù)測(cè)出相應(yīng)的價(jià)格,所以建模可以選擇回歸類算法。
缺失值處理
這個(gè)數(shù)據(jù)集許多特征都或多或少的含有一些缺失值,針對(duì)缺失值個(gè)數(shù)的多少,采取的處理方式也不同,像一些特征的缺失值占樣本個(gè)數(shù)超過三分之二,那么這些特征的意義也不大,所以選擇舍去這些特征:
# 很多特征還不及數(shù)據(jù)個(gè)數(shù)的三分之一,所以選擇舍去
data.drop(columns = ['Alley','FireplaceQu','PoolQC','Fence','MiscFeature'],axis = 1,inplace = True)
而對(duì)于缺失值較少的數(shù)值型特征,根據(jù)情況可以選擇填充眾數(shù)、中位數(shù)和平均數(shù):
#填補(bǔ)數(shù)值型缺失值
data['LotFrontage'].fillna(data['LotFrontage'].median(),inplace = True)
data['MasVnrArea'].fillna(data['MasVnrArea'].mean(),inplace = True)
而數(shù)據(jù)集中本身含有很多字符型特征,而對(duì)于這類特征的缺失值,是沒有中位數(shù)和平均數(shù)一說的,可以隨機(jī)填充或者填充出現(xiàn)頻率最多的元素,這里我選擇了后者:
#獲得含有缺失值的字符型特征標(biāo)簽
miss_index_list = data.isnull().any()[data.isnull().any().values == True].index.tolist()
miss_list = [] #存元素
for i in miss_index_list: #注意需要reshape規(guī)格
miss_list.append(data[i].values.reshape(-1,1))
這里填充缺失值的方式可以用上述方式,但前提是需要另寫一個(gè)函數(shù)計(jì)算特征的眾數(shù),另一種方式就是利用sklearn中自帶的API進(jìn)行填充:
from sklearn.impute import SimpleImputer
#用眾數(shù)填補(bǔ)數(shù)值型變量
for i in range(len(miss_list)):
imp_most = SimpleImputer(strategy='most_frequent') #實(shí)例化,參數(shù)選擇眾數(shù)
imp_most = imp_most.fit_transform(miss_list[i]) #訓(xùn)練
data.loc[:,miss_index_list[i]] = imp_most #替換原來的一列
當(dāng)然這種方式也適用于數(shù)值型,其中參數(shù)strategy也是可選的,像均值、中位數(shù)、眾數(shù)和自定義這幾種,代碼中most_frequent就代表眾數(shù)。對(duì)于填充缺失值的方式,numpy和pandas應(yīng)用較多,但這種利用API填充也比較便利,可以當(dāng)成一次拓展,自己了解一下。
處理字符型特征
對(duì)于某些回歸類算法,比如線性回歸,是通過計(jì)算繼而預(yù)測(cè)出最后的目標(biāo)變量,所以訓(xùn)練時(shí)傳入字符型元素是不合法的。但如果利用隨機(jī)森林可以避免,因?yàn)橛蓻Q策樹構(gòu)成的隨機(jī)森林只注重樣本特征的分布,但現(xiàn)在我們并不知道哪一種模型更適合該問題,因?yàn)樽詈笪覀円獜闹刑暨x出一個(gè)最優(yōu)的,那么我們?cè)谔幚頂?shù)據(jù)時(shí)就要兼顧我們將要選擇的所有模型。
這里選擇利用啞變量(也稱獨(dú)熱編碼)處理字符型數(shù)據(jù),可能有的人比較陌生,但介于篇幅問題不在過多闡述,可以自行查詢一下,或者過段時(shí)間也會(huì)寫一篇文章單獨(dú)講一下變量處理的相關(guān)知識(shí)。
我們只針對(duì)字符型特征進(jìn)行啞變量轉(zhuǎn)化,所以需要索引出字符型類的特征:
data_ = data.copy() #在一個(gè)新的數(shù)據(jù)集上操作
ob_features = data_.select_dtypes(include=['object']).columns.tolist()
然后就可以通過sklearn中自帶的API對(duì)字符型特征進(jìn)行啞變量轉(zhuǎn)換:
#啞變量/獨(dú)熱編碼
from sklearn.preprocessing import OneHotEncoder
OneHot = OneHotEncoder(categories='auto')#實(shí)例化
result = OneHot.fit_transform(data_.loc[:,ob_features]).toarray()#訓(xùn)練
打印一下result輸出如下:
這個(gè)矩陣中的每一列可以看成一個(gè)新的特征,而每個(gè)特征只包含0和1兩個(gè)元素,其中1代表有、0代表沒有。比如Street特征中包含兩個(gè)元素Grvl和Pave,而這兩個(gè)元素就可以通過啞變量轉(zhuǎn)化形成兩個(gè)新的特征。Street特征中為Grvl的樣本在Gral新一列中就為1,在Pave新一列中就為0,其他特征也是如此。
#獲取特征名
OneHotnames = OneHot.get_feature_names().tolist()
OneHotDf = pd.DataFrame(result,columns=OneHotnames)
利用get_feature_names方法可以獲取特征的標(biāo)簽,將上述矩陣轉(zhuǎn)化為一個(gè)DataFrame: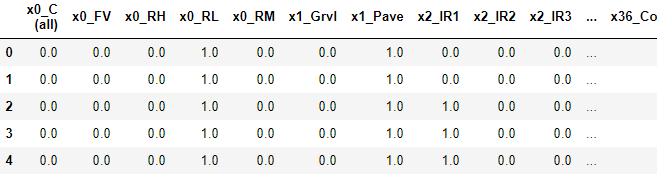
過濾方差
因?yàn)檗D(zhuǎn)化為啞變量之后許多特征都是由0和1組成的,仍然用Street舉例,會(huì)不會(huì)有種可能就是所有樣本的Street中的元素都為Grvl呢?如果這樣啞變量轉(zhuǎn)化后的Grvl一列皆為1,而Pave一列皆為0,那么這兩個(gè)新的特征對(duì)于最后的目標(biāo)變量的預(yù)測(cè)是沒有一點(diǎn)用處的,是可以直接刪去的,所以利用方差過濾掉類似的情況,將閾值設(shè)為0.1,方差低于0.1的特征都將被過濾掉。
from sklearn.feature_selection import VarianceThreshold
#過濾掉方差小于0.1的特征
transfer = VarianceThreshold(threshold=0.1)
new_data1 = transfer.fit_transform(data_)
#get_support得到的需要留下的下標(biāo)索引
var_index = transfer.get_support(True).tolist()
data1 = data_.iloc[:,var_index]
最后利用該方法過濾掉了188個(gè)特征,原本的270個(gè)特征還剩下82個(gè)特征。
相關(guān)性過濾
82個(gè)特征仍然太多了,一定還有一些無關(guān)緊要的特征,需要繼續(xù)特征降維,如果一個(gè)特征對(duì)于目標(biāo)變量的預(yù)測(cè)有幫助,那么這個(gè)特征與目標(biāo)變量間一定有某種聯(lián)系,那么這個(gè)特征與目標(biāo)變量之間的相關(guān)性一定是比較高的,所以可以通過特征與目標(biāo)變量間的相關(guān)系數(shù)過濾一些特征。
#皮爾遜相關(guān)系數(shù)
from scipy.stats import pearsonr
pear_num = [] #存系數(shù)
pear_name = [] #存特征名稱
feature_names = data1.columns.tolist()
#得到每個(gè)特征與SalePrice間的相關(guān)系數(shù)
for i in range(0,len(feature_names)-1):
print('%s和%s之間的皮爾遜相關(guān)系數(shù)為%f'%(feature_names[i],feature_names[-1],pearsonr(data1[feature_names[i]],data1[feature_names[-1]])[0]))
if (abs(pearsonr(data1[feature_names[i]],data1[feature_names[-1]])[0])>0.5):
pear_num.append(pearsonr(data1[feature_names[i]],data1[feature_names[-1]])[0])
pear_name.append(feature_names[i])
我們?cè)O(shè)定閾值為0.5,留下相關(guān)系數(shù)絕對(duì)值大于0.5的特征,因?yàn)椴恢拐嚓P(guān)有影響,負(fù)相關(guān)也是對(duì)預(yù)測(cè)有一定作用的。
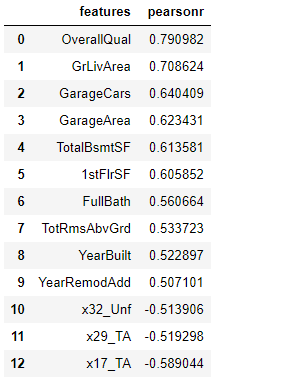
經(jīng)過濾后只剩下13個(gè)特征,上述計(jì)算的是特征與目標(biāo)變量之間的相關(guān)性,我們可以再從特征與特征之間的相關(guān)性找一找聯(lián)系,可不可以再降幾維呢?
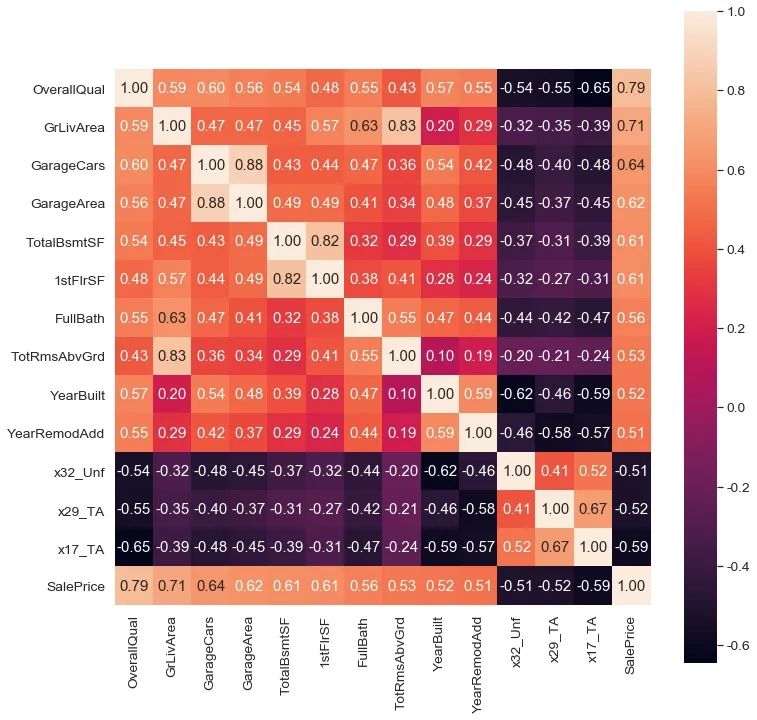
TotalBsmtSF(房間總數(shù))和GrLivArea(地面以上居住面積)相關(guān)系數(shù)0.83; GarageCars(車庫可裝車輛個(gè)數(shù))和GarageArea(車庫面積)相關(guān)系數(shù)0.88; TotalBsmtSF(地下室總面積)和1stFlrSF(第一層面積)相關(guān)系數(shù)0.82;
個(gè)人覺得可以將TotalBsmtSF和GrLivArea都保留,因?yàn)榉块g面積和房間總數(shù)不會(huì)過于沖突,可能在房間面積相同的情況下,房間個(gè)數(shù)越多的房子價(jià)格會(huì)更高一些呢?而剩下的四個(gè)特征從意思上就有一些沖突,可以取GarageArea和otalBsmtSF兩個(gè)特征。
可視化分析
我們可以通過可視化驗(yàn)證一下過濾后的特征與目標(biāo)變量之間是否存在上文我們預(yù)想的某種聯(lián)系,這里推薦用箱線圖繪制數(shù)據(jù)較為離散的特征、用散點(diǎn)圖繪制數(shù)據(jù)較為連續(xù)的特征,前者方便比較,后者方便觀察分布,利于找出聯(lián)系。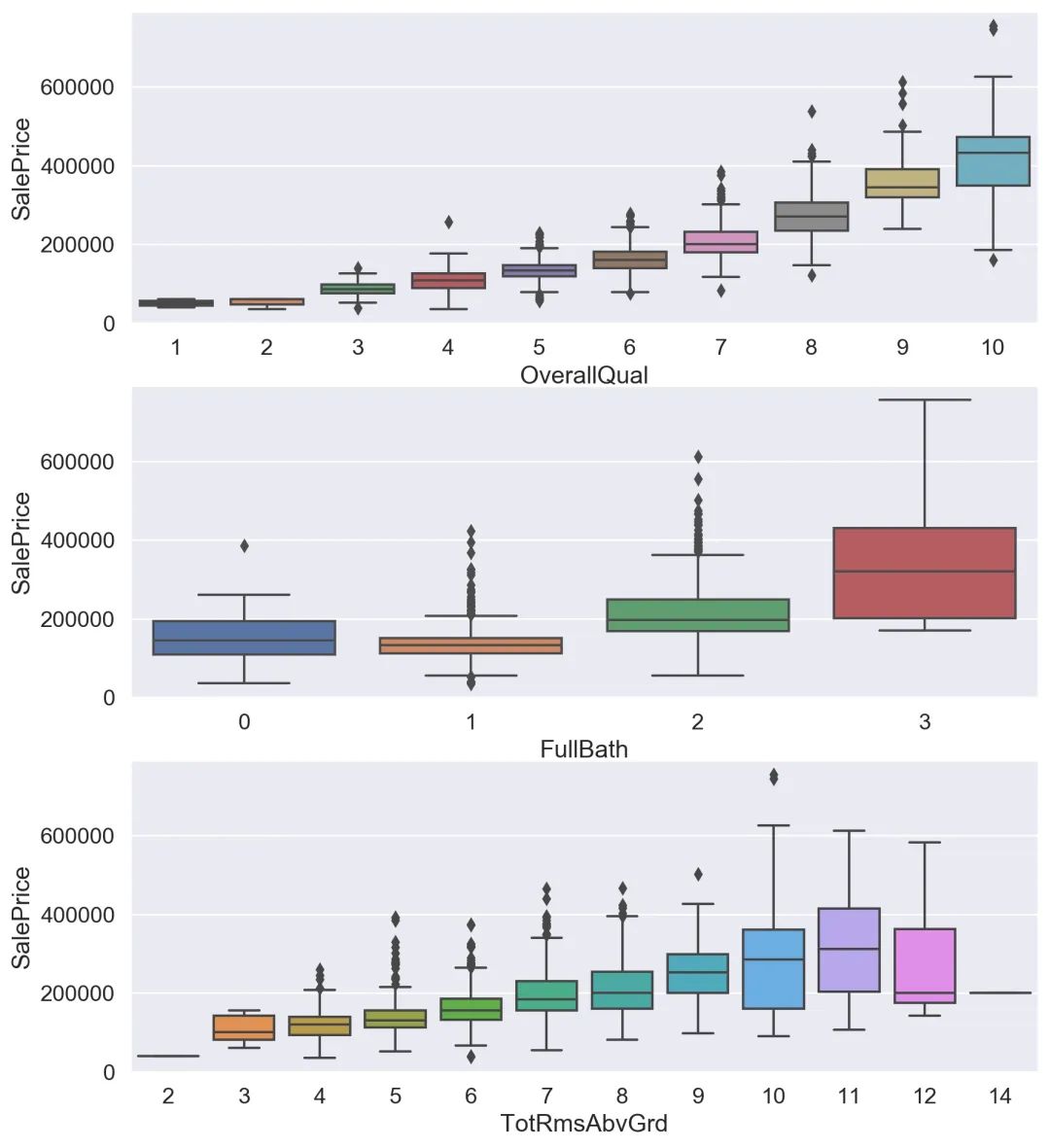
可以看到OverallQual(總體評(píng)價(jià))對(duì)于價(jià)格的影響真的巨大,所以買賣口碑真的是非常重要呀,其他離散特征與目標(biāo)變量間的聯(lián)系也是具有很明顯的趨勢(shì)的。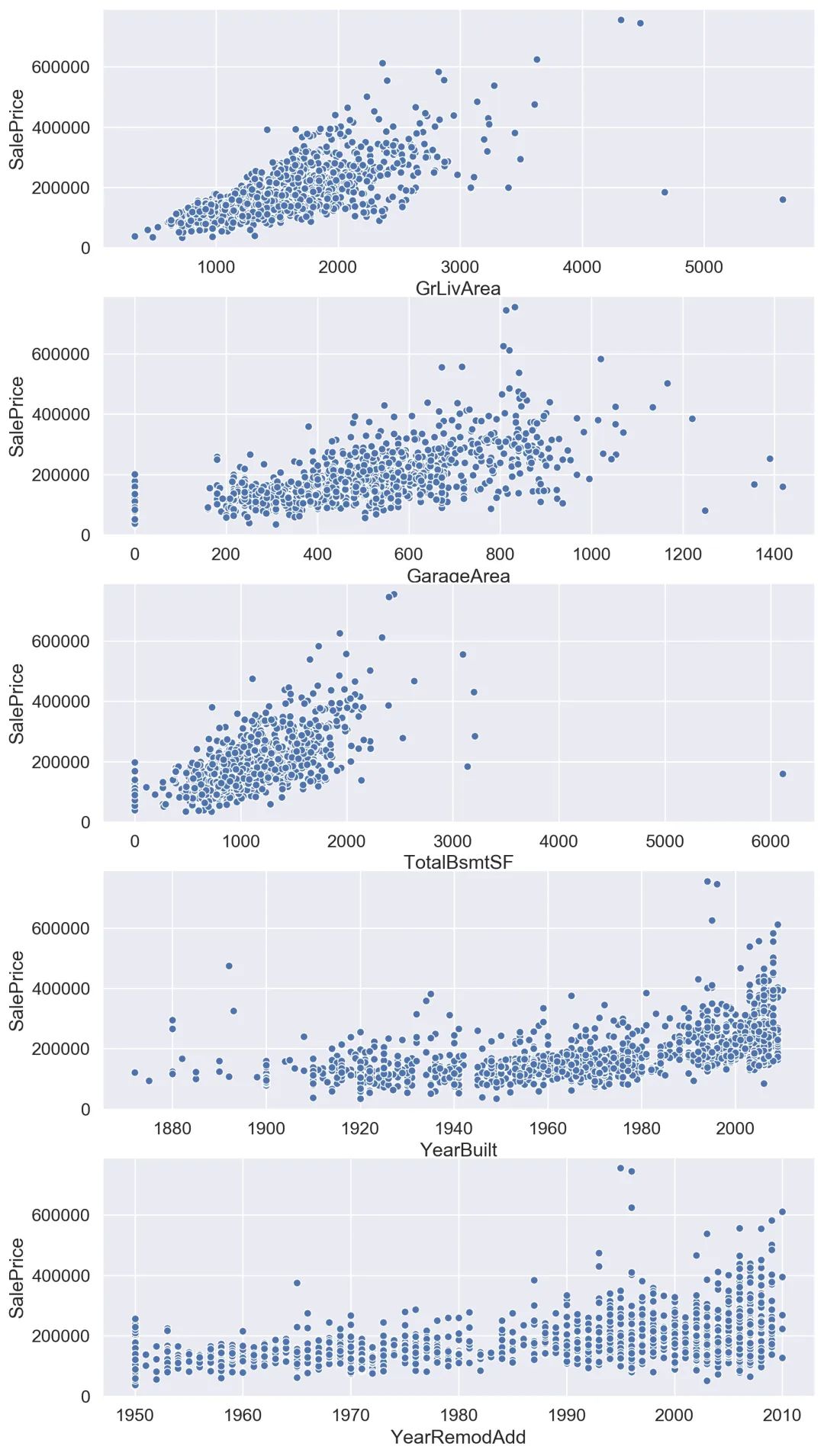
散點(diǎn)圖可視化出的結(jié)果也是非常明顯,所以我們選取的這幾個(gè)特征都是不錯(cuò)的,但是這不代表其他特征與目標(biāo)變量之間沒有聯(lián)系,之前也提及過可以選取一些主觀上感覺有聯(lián)系的特征再進(jìn)行二次分析。我自己猜測(cè)Neighborhood(地理位置)和HeatingQC(加熱質(zhì)量)對(duì)于價(jià)格應(yīng)該會(huì)有影響,但是可視化出的結(jié)果顯示聯(lián)系并不大。
選模、調(diào)參
模型測(cè)試我選擇用線性回歸和隨機(jī)森林,由于線性回歸對(duì)傳入數(shù)據(jù)的要求以及要通過均方誤差判斷哪一個(gè)模型更優(yōu),所以需要先對(duì)訓(xùn)練集和測(cè)試集進(jìn)行標(biāo)準(zhǔn)化,然后計(jì)算兩個(gè)模型對(duì)應(yīng)的均方誤差,代碼如下:
#計(jì)算模型的均方誤差
clfs = {'rfr':RandomForestRegressor(),
'LR':LinearRegression()}
for clf in clfs:
clfs[clf].fit(x_train_sta,y_train_sta)
prediction = clfs[clf].predict(x_test_sta)
print(clf + " RMSE:" + str(np.sqrt(metrics.mean_squared_error(y_test_sta,prediction))))
'''
rfr RMSE:0.38292937665826626
LR RMSE:0.5534982168680332
'''
在不調(diào)整參數(shù)的情況下,rfr的均方誤差小于LR,隨機(jī)森林在該問題上是要優(yōu)于線性回歸的,所以選定隨機(jī)森林作為最后建模要用的算法,然后利用網(wǎng)格搜索或者學(xué)習(xí)曲線對(duì)算法進(jìn)行調(diào)參。
這里省略很多很多調(diào)參步驟。
最后我自己嘗試調(diào)出的最佳參數(shù)如下,調(diào)參之后的模型得分大約為84%,前后相比大約提高了大約2%。
rf = RandomForestRegressor(n_estimators=300,max_depth =20,
max_features =5,min_samples_leaf =2,
min_samples_split=2)
grid = GridSearchCV(rf,param_grid=param_grid,cv = 5)
grid.fit(x_train,y_train)
rf_reg = grid.best_estimator_#最佳模型
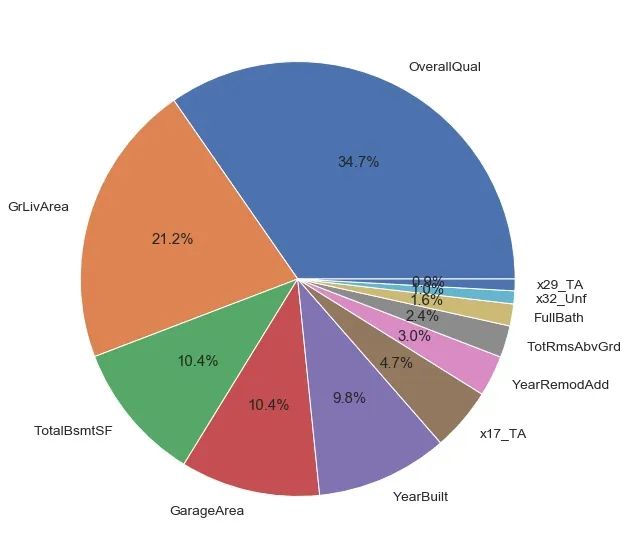
可以在模型的基礎(chǔ)上分析一下特征重要程度,其中OverallQual(總體評(píng)價(jià))和GrLivArea(居住面積)兩者重要程度占比就已經(jīng)超過五成,反觀x32_Unf(未完成地下室面積)和x29_TA(廚房質(zhì)量)影響甚微。
需要對(duì)測(cè)試集做與訓(xùn)練集一致的操作,例如缺失值處理、啞變量轉(zhuǎn)化等,然后索引出測(cè)試集中這些重要特征并傳入建好的模型中,得出最終的預(yù)測(cè)結(jié)果"SalePrice",然后將"Id"和"SalePrice"導(dǎo)出一個(gè)名為submission的csv文件,最后需要在Kaggle需要上傳這份文件,就可以得到自己的排名啦。
submission_Id = pd.read_csv("house_test.csv",usecols=['Id'])
SalePrice = pd.DataFrame(test_value_y,columns=['SalePrice'])
Submission = pd.concat([submission_Id,SalePrice],axis=1)
Submission.to_csv("submission.csv",index = False)
總結(jié)
綜上可以發(fā)現(xiàn)完成一個(gè)小項(xiàng)目五成的時(shí)間用來處理分析數(shù)據(jù)、四成的時(shí)間用來調(diào)參、最后一成時(shí)間用來選模建模,而最終模型的好壞五成取決數(shù)據(jù)本身、四成取決于你的特征工程、最后一成取決于你的調(diào)參,所以需要把更多時(shí)間更多精力放在數(shù)據(jù)處理、特征工程上才能得到讓自己滿意的一個(gè)結(jié)果。
