
Pytorch 彈性訓(xùn)練極簡(jiǎn)實(shí)現(xiàn)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá) 
由于工作需要,最近在補(bǔ)充分布式訓(xùn)練方面的知識(shí)。經(jīng)過(guò)一番理論學(xué)習(xí)后仍覺(jué)得意猶未盡,很多知識(shí)點(diǎn)無(wú)法準(zhǔn)確get到(例如:分布式原語(yǔ)scatter、all reduce等代碼層面應(yīng)該是什么樣的,ring all reduce 算法在梯度同步時(shí)是怎么使用的,parameter server參數(shù)是如何部分更新的)。
著名物理學(xué)家,諾貝爾獎(jiǎng)得主Richard Feynman辦公室的黑板上寫(xiě)了:"What I cannot create, I do not understand."。在程序員界也經(jīng)常有"show me the code"的口號(hào)。因此,我打算寫(xiě)一系列的分布式訓(xùn)練的文章,將以往抽象的分布式訓(xùn)練的概念以代碼的形式展現(xiàn)出來(lái),并保證每個(gè)代碼可執(zhí)行、可驗(yàn)證、可復(fù)現(xiàn),并貢獻(xiàn)出來(lái)源碼讓大家相互交流。
經(jīng)過(guò)調(diào)研發(fā)現(xiàn)pytorch對(duì)于分布式訓(xùn)練做好很好的抽象且接口完善,因此本系列文章將以pytorch為主要框架進(jìn)行,文章中的例子很多都來(lái)自pytorch的文檔,并在此基礎(chǔ)上進(jìn)行了調(diào)試和擴(kuò)充。
最后,由于分布式訓(xùn)練的理論介紹網(wǎng)絡(luò)上已經(jīng)很多了,理論部分的介紹不會(huì)是本系列文章的重點(diǎn),我會(huì)將重點(diǎn)放在代碼層面的介紹上面。
Pytorch - 分布式訓(xùn)練極簡(jiǎn)體驗(yàn):https://zhuanlan.zhihu.com/p/477073906
Pytorch - 分布式通信原語(yǔ)(附源碼):https://zhuanlan.zhihu.com/p/478953028
Pytorch - 手寫(xiě)allreduce分布式訓(xùn)練(附源碼):https://zhuanlan.zhihu.com/p/482557067
Pytorch - 算子間并行極簡(jiǎn)實(shí)現(xiàn)(附源碼):https://zhuanlan.zhihu.com/p/483640235
Pytorch - 多機(jī)多卡極簡(jiǎn)實(shí)現(xiàn)(附源碼):https://zhuanlan.zhihu.com/p/486130584
1. 介紹
Pytorch在1.9.0引入了torchrun,用其替代1.9.0以前版本的torch.distributed.launch。torchrun在torch.distributed.launch 功能的基礎(chǔ)上主要新增了兩個(gè)功能:
-
Failover: 當(dāng)worker訓(xùn)練失敗時(shí),會(huì)自動(dòng)重新啟動(dòng)所有worker繼續(xù)進(jìn)行訓(xùn)練; -
Elastic: 可以動(dòng)態(tài)增加或或刪除node節(jié)點(diǎn),本文將通過(guò)一個(gè)例子說(shuō)明Elastic Training應(yīng)該如何使用;
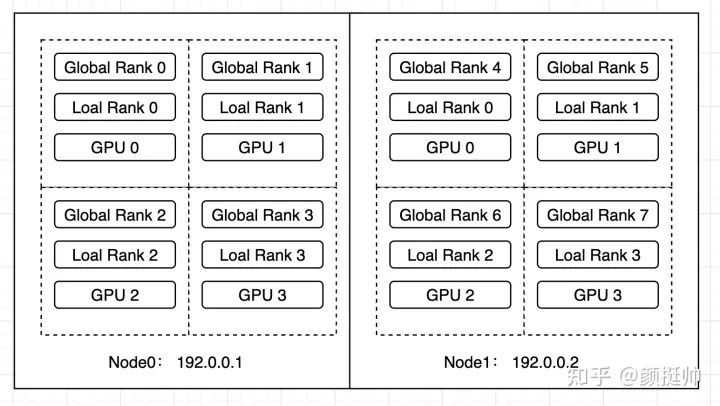
本例中會(huì)先在Node0上啟動(dòng)4 GPU的worker group ,等其訓(xùn)練一段時(shí)間后,會(huì)在Node1上再啟動(dòng)4 GPU的workers,并與Node1上的workers構(gòu)成一個(gè)新的worker group,最終構(gòu)成一個(gè)2機(jī)8卡的分布式訓(xùn)練。
2. 模型構(gòu)建
一個(gè)簡(jiǎn)單的全連接模型神經(jīng)網(wǎng)絡(luò)模型
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
3. checkpoint 處理
由于再每次增加或刪除node時(shí),會(huì)將所有worker kill掉,然后再重新啟動(dòng)所有worker進(jìn)行訓(xùn)練。因此,在訓(xùn)練代碼中要對(duì)訓(xùn)練的狀態(tài)進(jìn)行保存,以保證重啟后能接著上次的狀態(tài)繼續(xù)訓(xùn)練。
需要保存的信息一般有如下內(nèi)容:
-
model :模型的參數(shù)信息 -
optimizer :優(yōu)化器的參數(shù)信心 -
epoch:當(dāng)前執(zhí)行到第幾個(gè)epoch
save和load的代碼如下所示
-
torch.save:利用python的pickle將python的object 進(jìn)行序列化,并保存到本地文件; -
torch.load: 將torch.save后的本地文件進(jìn)行反序列化,并加載到內(nèi)存中; -
model.state_dict():存儲(chǔ)了model 每個(gè)layer和其對(duì)應(yīng)的param信息 -
optimizer.state_dict():存儲(chǔ)了優(yōu)化器的參數(shù)信信息
def save_checkpoint(epoch, model, optimizer, path):
torch.save({
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimize_state_dict": optimizer.state_dict(),
}, path)
def load_checkpoint(path):
checkpoint = torch.load(path)
return checkpoint
4. 訓(xùn)練代碼
初始化邏輯如下:
-
1~3行: 輸出當(dāng)前worker的關(guān)鍵環(huán)境變量,用于后面的結(jié)果展示 -
5~8行:創(chuàng)建模型、優(yōu)化器和損失函數(shù) -
10~12行:初始化參數(shù)信息 -
14~19行:如果存在checkpoint,則加載checkpoint,并賦值給model、optimizer和firt_epoch
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) train worker starting...")
model = ToyModel().cuda(local_rank)
ddp_model = DDP(model, [local_rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
max_epoch = 100
first_epoch = 0
ckp_path = "checkpoint.pt"
if os.path.exists(ckp_path):
print(f"load checkpoint from {ckp_path}")
checkpoint = load_checkpoint(ckp_path)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimize_state_dict"])
first_epoch = checkpoint["epoch"]
訓(xùn)練邏輯:
-
1行:epoch執(zhí)行的次數(shù)為first_epoch到max_epoch,以便能夠在worker被重啟后繼續(xù)原有的epoch繼續(xù)訓(xùn)練; -
2行:為了展示動(dòng)態(tài)添加node效果,這里添加sleep函數(shù)來(lái)降低訓(xùn)練的速度; -
3~8行:模型訓(xùn)練流程; -
9行:為了簡(jiǎn)單,文本每個(gè)epoch進(jìn)行一次checkpoint保存;將當(dāng)前的epoch,model和optimizer保存到checkpoint中;
for i in range(first_epoch, max_epoch):
time.sleep(1) # 為了展示動(dòng)態(tài)添加node效果,這里添加sleep函數(shù)來(lái)降低訓(xùn)練的速度
outputs = ddp_model(torch.randn(20, 10).to(local_rank))
labels = torch.randn(20, 5).to(local_rank)
loss = loss_fn(outputs, labels)
loss.backward()
print(f"[{os.getpid()}] epoch {i} (rank = {rank}, local_rank = {local_rank}) loss = {loss.item()}\n")
optimizer.step()
save_checkpoint(i, model, optimizer, ckp_path)
5. 啟動(dòng)方式
由于我們使用torchrun來(lái)啟動(dòng)多機(jī)多卡任務(wù),無(wú)需使用spawn接口來(lái)啟動(dòng)多個(gè)進(jìn)程(torchrun會(huì)負(fù)責(zé)將我們的python script啟動(dòng)為一個(gè)process),因此直接調(diào)用上文編寫(xiě)的train函數(shù),并在前后分別添加DistributedDataParallel的初始化和效果函數(shù)即可。
下面代碼描述了上文train接口的調(diào)用。
def run():
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
train()
dist.destroy_process_group()
if __name__ == "__main__":
run()
本例中使用torchrun來(lái)執(zhí)行多機(jī)多卡的分布式訓(xùn)練任務(wù)(注:torch.distributed.launch 已經(jīng)被pytorch淘汰了,盡量不要再使用)。啟動(dòng)腳本描述如下(注:node0和node1均通過(guò)該腳本進(jìn)行啟動(dòng))
-
--nnodes=1:3:表示當(dāng)前訓(xùn)練任務(wù)接受最少1個(gè)node,最多3個(gè)node參與分布式訓(xùn)練; -
--nproc_per_node=4:表示每個(gè)node上節(jié)點(diǎn)有4個(gè)process -
--max_restarts=3: worker group最大的重啟次數(shù);這里需要注意的是,node fail、node scale down和node scale up都會(huì)導(dǎo)致restart; -
--rdzv_id=1:一個(gè)unique的job id,所有node均使用同一個(gè)job id; -
--rdzv_backend: rendezvous的backend實(shí)現(xiàn),默認(rèn)支持c10d和etcd兩種;rendezvous用于多個(gè)node之間的通信和協(xié)調(diào); -
--rdzv_endpoint:rendezvous的地址,應(yīng)該為一個(gè)node的host ip和port;
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.py
6. 結(jié)果分析
代碼:BetterDL - train_elastic.py:https://github.com/tingshua-yts/BetterDL/blob/master/test/pytorch/DDP/train_elastic.py
運(yùn)行環(huán)境: 2臺(tái)4卡 v100機(jī)器
image: pytorch/pytorch:1.11.0-cuda11.3-cudnn8-runtime
gpu: v100
先在node0上執(zhí)行執(zhí)行啟動(dòng)腳本
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.py
得到如下結(jié)果
-
2~5行:當(dāng)前啟動(dòng)的是單機(jī)4卡的訓(xùn)練任務(wù),因此WORLD_SIZE為4, LOCAL_WORKD_SIZE也為4 -
6~9行:共有4個(gè)rank參與了分布式訓(xùn)練,rank0~rank3 -
10~18行: rank0~rank3 均從epoch=0開(kāi)始訓(xùn)練
r/workspace/DDP# sh run_elastic.sh
[4031] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4030] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4032] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] (rank = 0, local_rank = 0) train worker starting...
[4030] (rank = 1, local_rank = 1) train worker starting...
[4032] (rank = 3, local_rank = 3) train worker starting...
[4031] (rank = 2, local_rank = 2) train worker starting...
[4101] epoch 0 (rank = 1, local_rank = 1) loss = 0.9288564920425415
[4103] epoch 0 (rank = 3, local_rank = 3) loss = 0.9711472988128662
[4102] epoch 0 (rank = 2, local_rank = 2) loss = 1.0727070569992065
[4100] epoch 0 (rank = 0, local_rank = 0) loss = 0.9402943253517151
[4100] epoch 1 (rank = 0, local_rank = 0) loss = 1.0327017307281494
[4101] epoch 1 (rank = 1, local_rank = 1) loss = 1.4485043287277222
[4103] epoch 1 (rank = 3, local_rank = 3) loss = 1.0959293842315674
[4102] epoch 1 (rank = 2, local_rank = 2) loss = 1.0669530630111694
...
在node1上執(zhí)行與上面相同的腳本
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.py
node1上結(jié)果如下:
-
2~5行:由于添加node1,當(dāng)前執(zhí)行的是2機(jī)8卡的分布式訓(xùn)練任務(wù),因此WORLD_SIZE=8, LOCAL_WORLD_SIZE=4 -
6~9行:當(dāng)前node1上workers的rank為rank4 ~rank7 -
13~20行: 由于node1是在node0上work訓(xùn)練到epoch35的時(shí)候加入的,因此其接著epoch 35開(kāi)始訓(xùn)練
/workspace/DDP# sh run_elastic.sh
[696] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[695] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[694] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] (rank = 7, local_rank = 3) train worker starting...
[695] (rank = 5, local_rank = 1) train worker starting...
[694] (rank = 4, local_rank = 0) train worker starting...
[696] (rank = 6, local_rank = 2) train worker starting...
load checkpoint from checkpoint.ptload checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
[697] epoch 35 (rank = 7, local_rank = 3) loss = 1.1888569593429565
[694] epoch 35 (rank = 4, local_rank = 0) loss = 0.8916441202163696
[695] epoch 35 (rank = 5, local_rank = 1) loss = 1.5685604810714722
[696] epoch 35 (rank = 6, local_rank = 2) loss = 1.11683189868927
[696] epoch 36 (rank = 6, local_rank = 2) loss = 1.3724170923233032
[694] epoch 36 (rank = 4, local_rank = 0) loss = 1.061527967453003
[695] epoch 36 (rank = 5, local_rank = 1) loss = 0.96876460313797
[697] epoch 36 (rank = 7, local_rank = 3) loss = 0.8060566782951355
...
node0上結(jié)果如下:
-
6~9行: node0上的works在執(zhí)行到epoch 35時(shí),node1上執(zhí)行了訓(xùn)練腳本,請(qǐng)求加入到訓(xùn)練任務(wù)中 -
10~13行:所有workers重新啟動(dòng),由于添加了node1,當(dāng)前執(zhí)行的是2機(jī)8卡的分布式訓(xùn)練任務(wù),因此WORLD_SIZE=8, LOCAL_WORLD_SIZE=4 -
14~17行:當(dāng)前node1上works的rank為rank0~rank3 -
18~21行:加載checkpoint -
22~30行:接著checkpoint中的model、optimizer和epoch繼續(xù)訓(xùn)練
...
[4100] epoch 35 (rank = 0, local_rank = 0) loss = 1.0746158361434937
[4101] epoch 35 (rank = 1, local_rank = 1) loss = 1.1712706089019775
[4103] epoch 35 (rank = 3, local_rank = 3) loss = 1.1774182319641113
[4102] epoch 35 (rank = 2, local_rank = 2) loss = 1.0898035764694214
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4100 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4101 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4102 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4103 closing signal SIGTERM
[4164] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4165] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4162] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4163] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4162] (rank = 0, local_rank = 0) train worker starting...
[4163] (rank = 1, local_rank = 1) train worker starting...
[4164] (rank = 2, local_rank = 2) train worker starting...
[4165] (rank = 3, local_rank = 3) train worker starting...
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
[4165] epoch 35 (rank = 3, local_rank = 3) loss = 1.3437936305999756
[4162] epoch 35 (rank = 0, local_rank = 0) loss = 1.5693414211273193
[4163] epoch 35 (rank = 1, local_rank = 1) loss = 1.199862003326416
[4164] epoch 35 (rank = 2, local_rank = 2) loss = 1.0465545654296875
[4163] epoch 36 (rank = 1, local_rank = 1) loss = 0.9741991758346558
[4162] epoch 36 (rank = 0, local_rank = 0) loss = 1.3609280586242676
[4164] epoch 36 (rank = 2, local_rank = 2) loss = 0.9585908055305481
[4165] epoch 36 (rank = 3, local_rank = 3) loss = 0.9169824123382568
...
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。
下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車(chē)道線檢測(cè)、車(chē)輛計(jì)數(shù)、添加眼線、車(chē)牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。
下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~