
DBSCAN聚類(lèi)算法原理總結(jié)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

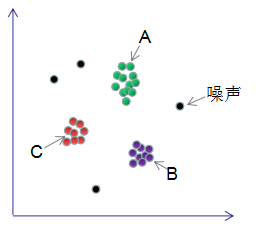
DBSCAN是基于密度空間的聚類(lèi)算法,在機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘領(lǐng)域有廣泛的應(yīng)用,其聚類(lèi)原理通俗點(diǎn)講是每個(gè)簇類(lèi)的密度高于該簇類(lèi)周?chē)拿芏龋肼暤拿芏刃∮谌我淮仡?lèi)的密度。如下圖簇類(lèi)ABC的密度大于周?chē)拿芏龋肼暤拿芏鹊陀谌我淮仡?lèi)的密度,因此DBSCAN算法也能用于異常點(diǎn)檢測(cè)。本文對(duì)DBSCAN算法進(jìn)行了詳細(xì)總結(jié) 。
目錄
1. DBSCAN算法的樣本點(diǎn)組成
2. DBSCAN算法原理
3. DBSCAN算法的參數(shù)估計(jì)
4. DBSCAN算法實(shí)戰(zhàn)
5 DBSCAN算法的優(yōu)缺點(diǎn)
DBSCAN算法處理后的聚類(lèi)樣本點(diǎn)分為:核心點(diǎn)(core points),邊界點(diǎn)(border points)和噪聲點(diǎn)(noise),這三類(lèi)樣本點(diǎn)的定義如下:
核心點(diǎn):對(duì)某一數(shù)據(jù)集D,若樣本p的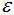 -領(lǐng)域內(nèi)至少包含MinPts個(gè)樣本(包括樣本p),那么樣本p稱(chēng)核心點(diǎn)。
-領(lǐng)域內(nèi)至少包含MinPts個(gè)樣本(包括樣本p),那么樣本p稱(chēng)核心點(diǎn)。
即:
稱(chēng)p為核心點(diǎn),其中 -領(lǐng)域
-領(lǐng)域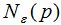 的表達(dá)式為:
的表達(dá)式為:
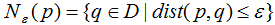
邊界點(diǎn):對(duì)于非核心點(diǎn)的樣本b,若b在任意核心點(diǎn)p的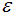 -領(lǐng)域內(nèi),那么樣本b稱(chēng)為邊界點(diǎn)。
-領(lǐng)域內(nèi),那么樣本b稱(chēng)為邊界點(diǎn)。
即:

稱(chēng)b為邊界點(diǎn)。
噪聲點(diǎn):對(duì)于非核心點(diǎn)的樣本n,若n不在任意核心點(diǎn)p的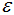 -領(lǐng)域內(nèi),那么樣本n稱(chēng)為噪聲點(diǎn)。
-領(lǐng)域內(nèi),那么樣本n稱(chēng)為噪聲點(diǎn)。
即:

稱(chēng)n為噪聲點(diǎn)。
假設(shè)MinPts=4,如下圖的核心點(diǎn)、非核心點(diǎn)與噪聲的分布:
由上節(jié)可知,DBSCAN算法劃分?jǐn)?shù)據(jù)集D為核心點(diǎn),邊界點(diǎn)和噪聲點(diǎn),并按照一定的連接規(guī)則組成簇類(lèi)。介紹連接規(guī)則前,先定義下面這幾個(gè)概念:
密度直達(dá)(directly density-reachable):若q處于p的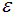 -鄰域內(nèi),且p為核心點(diǎn),則稱(chēng)q由p密度直達(dá);
-鄰域內(nèi),且p為核心點(diǎn),則稱(chēng)q由p密度直達(dá);
密度可達(dá)(density-reachable):若q處于p的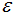 -鄰域內(nèi),且p,q均為核心點(diǎn),則稱(chēng)q的鄰域點(diǎn)由p密度可達(dá);
-鄰域內(nèi),且p,q均為核心點(diǎn),則稱(chēng)q的鄰域點(diǎn)由p密度可達(dá);
密度相連(density-connected):若p,q均為非核心點(diǎn),且p,q處于同一個(gè)簇類(lèi)中,則稱(chēng)q與p密度相連。
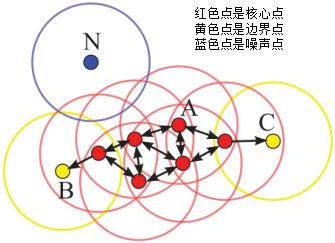
下圖給出了上述概念的直觀顯示(MinPts):
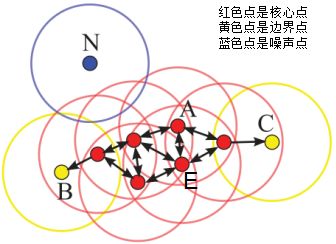
其中核心點(diǎn)E由核心點(diǎn)A密度直達(dá),邊界點(diǎn)B由核心點(diǎn)A密度可達(dá),邊界點(diǎn)B與邊界點(diǎn)C密度相連,N為孤單的噪聲點(diǎn)。
DBSCAN是基于密度的聚類(lèi)算法,原理為:只要任意兩個(gè)樣本點(diǎn)是密度直達(dá)或密度可達(dá)的關(guān)系,那么該兩個(gè)樣本點(diǎn)歸為同一簇類(lèi),上圖的樣本點(diǎn)ABCE為同一簇類(lèi)。因此,DBSCAN算法從數(shù)據(jù)集D中隨機(jī)選擇一個(gè)核心點(diǎn)作為“種子”,由該種子出發(fā)確定相應(yīng)的聚類(lèi)簇,當(dāng)遍歷完所有核心點(diǎn)時(shí),算法結(jié)束。
DBSCAN算法的偽代碼:
# DB為數(shù)據(jù)集,distFunc為樣本間的距離函數(shù)
# eps為樣本點(diǎn)的領(lǐng)域,MinPts為簇類(lèi)的最小樣本數(shù)
DBSCAN(DB,distFunc,eps,minPts){
C = 0 # 初始化簇類(lèi)個(gè)數(shù)
# 數(shù)據(jù)集DB被標(biāo)記為核心點(diǎn)和噪聲點(diǎn)
for each point P in database DB{ # 遍歷數(shù)據(jù)集
if label(P) != undefined then continue # 如果樣本已經(jīng)被標(biāo)記了,跳過(guò)此次循環(huán)
Neighbors N = RangeQuery(DB,distFunc,P,eps) # 計(jì)算樣本點(diǎn)P在eps鄰域內(nèi)的個(gè)數(shù),包含樣本點(diǎn)本身
if |N| < minPts then { # 密度估計(jì)
label(P) = Noise # 若樣本點(diǎn)P的eps鄰域內(nèi)個(gè)數(shù)小于MinPts,則為噪聲
continue
}
C = C + 1 # 增加簇類(lèi)個(gè)數(shù)
label(P) = C # 初始化簇類(lèi)標(biāo)記
Seed set S = N \{P} # 初始化種子集,符號(hào)\表示取補(bǔ)集
for each point Q in S{
if label(Q) = Noise then label(Q) = C # 核心點(diǎn)P的鄰域?yàn)樵肼朁c(diǎn),則該噪聲點(diǎn)重新標(biāo)記為邊界點(diǎn)
if label(Q) != undefined then continue # 如果樣本已經(jīng)被標(biāo)記了(如上次已經(jīng)被標(biāo)記的噪聲),跳過(guò)此次循環(huán)
label(Q) = C # 核心點(diǎn)P的鄰域都標(biāo)記為簇類(lèi)C
Neighbors N = RangeQuery(DB,distFunc,Q,eps) # 計(jì)算樣本Q的鄰域個(gè)數(shù)
if N >= minPts then{ # 密度檢測(cè),檢測(cè)Q是否為核心樣本
S = S.append(N) # 鄰域Q樣本添加到種子集
}
}
}
}其中計(jì)算樣本Q鄰域個(gè)數(shù)的偽代碼:
# 計(jì)算樣本Q的eps鄰域集
RangeQuery(DB,distFunc,Q,eps){
Neighbors = empty list # 初始化Q樣本的鄰域?yàn)榭占?/span>
for each point P in database DB{
if distFunc(Q,P) <= eps then {
Neighbors = Neighbors.append(Q) # 若Q在P的eps鄰域內(nèi),則鄰域集增加該樣本
}
}
return Neighbors
}其中計(jì)算樣本P與Q的距離函數(shù)dist(P,Q)不同,鄰域形狀也不同,若我們使用的距離是曼哈頓(manhattan)距離,則鄰域性狀為矩形;若使用的距離是歐拉距離,則鄰域形狀為圓形。
DBSCAN算法可以抽象為以下幾步:
1)找到每個(gè)樣本的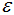 -鄰域內(nèi)的樣本個(gè)數(shù),若個(gè)數(shù)大于等于MinPts,則該樣本為核心點(diǎn);
-鄰域內(nèi)的樣本個(gè)數(shù),若個(gè)數(shù)大于等于MinPts,則該樣本為核心點(diǎn);
2)找到每個(gè)核心樣本密度直達(dá)和密度可達(dá)的樣本,且該樣本亦為核心樣本,忽略所有的非核心樣本;
3)若非核心樣本在核心樣本的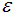 -鄰域內(nèi),則非核心樣本為邊界樣本,反之為噪聲。
-鄰域內(nèi),則非核心樣本為邊界樣本,反之為噪聲。
由上一節(jié)可知,DBSCAN主要包含兩個(gè)參數(shù):
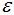 :兩個(gè)樣本的最小距離,它的含義為:如果兩個(gè)樣本的距離小于或等于值
:兩個(gè)樣本的最小距離,它的含義為:如果兩個(gè)樣本的距離小于或等于值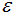 ,那么這兩個(gè)樣本互為鄰域。
,那么這兩個(gè)樣本互為鄰域。
MinPts:形成簇類(lèi)所需的最小樣本個(gè)數(shù),比如MinPts等于5,形成簇類(lèi)的前提是至少有一個(gè)樣本的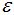 -鄰域大于等于5。
-鄰域大于等于5。
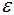 參數(shù)和MinPts參數(shù)估計(jì):
參數(shù)和MinPts參數(shù)估計(jì):
如下圖,如果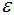 值取的太小,部分樣本誤認(rèn)為是噪聲點(diǎn)(白色);
值取的太小,部分樣本誤認(rèn)為是噪聲點(diǎn)(白色);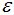 值取的多大,大部分的樣本會(huì)合并為同一簇類(lèi)。
值取的多大,大部分的樣本會(huì)合并為同一簇類(lèi)。
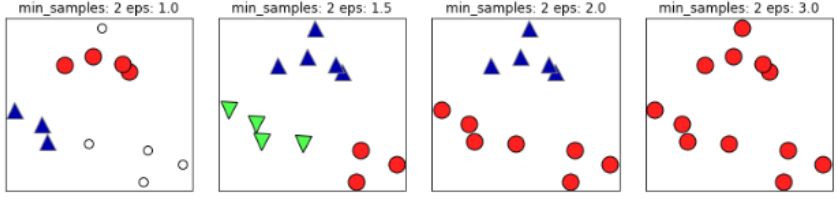
同樣的,若MinPts值過(guò)小,則所有樣本都可能為核心樣本;MinPts值過(guò)大時(shí),部分樣本誤認(rèn)為是噪聲點(diǎn)(白色),如下圖:
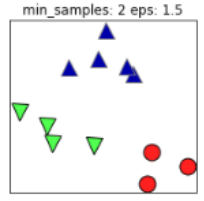
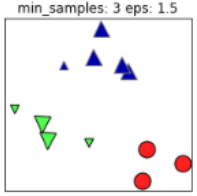
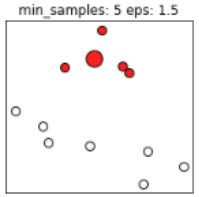
根據(jù)經(jīng)驗(yàn),minPts的最小值可以從數(shù)據(jù)集的維數(shù)D得到,即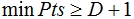 。若minPts=1,含義為所有的數(shù)據(jù)集樣本都為核心樣本,即每個(gè)樣本都是一個(gè)簇類(lèi);若minPts≤2,結(jié)果和單連接的層次聚類(lèi)相同;因此minPts必須大于等于3,因此一般認(rèn)為minPts=2*dim,若數(shù)據(jù)集越大,則minPts的值選擇的亦越大。
。若minPts=1,含義為所有的數(shù)據(jù)集樣本都為核心樣本,即每個(gè)樣本都是一個(gè)簇類(lèi);若minPts≤2,結(jié)果和單連接的層次聚類(lèi)相同;因此minPts必須大于等于3,因此一般認(rèn)為minPts=2*dim,若數(shù)據(jù)集越大,則minPts的值選擇的亦越大。
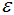 值常常用k-距離曲線(k-distance graph)得到,計(jì)算每個(gè)樣本與所有樣本的距離,選擇第k個(gè)最近鄰的距離并從大到小排序,得到k-距離曲線,曲線拐點(diǎn)對(duì)應(yīng)的距離設(shè)置為
值常常用k-距離曲線(k-distance graph)得到,計(jì)算每個(gè)樣本與所有樣本的距離,選擇第k個(gè)最近鄰的距離并從大到小排序,得到k-距離曲線,曲線拐點(diǎn)對(duì)應(yīng)的距離設(shè)置為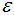 ,如下圖:
,如下圖:
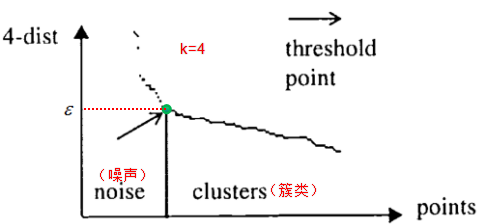
由圖可知或者根據(jù)k-距離曲線的定義可知:樣本點(diǎn)第k個(gè)近鄰距離值小于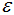 歸為簇類(lèi),大于
歸為簇類(lèi),大于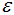 的樣本點(diǎn)歸為噪聲點(diǎn)。根據(jù)經(jīng)驗(yàn),一般選擇
的樣本點(diǎn)歸為噪聲點(diǎn)。根據(jù)經(jīng)驗(yàn),一般選擇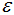 值等于第(minPts-1)的距離,計(jì)算樣本間的距離前需要對(duì)數(shù)據(jù)進(jìn)行歸一化,使所有特征值處于同一尺度范圍,有利于
值等于第(minPts-1)的距離,計(jì)算樣本間的距離前需要對(duì)數(shù)據(jù)進(jìn)行歸一化,使所有特征值處于同一尺度范圍,有利于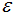 參數(shù)的設(shè)置。
參數(shù)的設(shè)置。
如果(k+1)-距離曲線和k-距離曲線沒(méi)有明顯差異,那么minPts設(shè)置為k值。例如k=4和k>4的距離曲線沒(méi)有明顯差異,而且k>4的算法計(jì)算量大于k=4的計(jì)算量,因此設(shè)置MinPts=4。
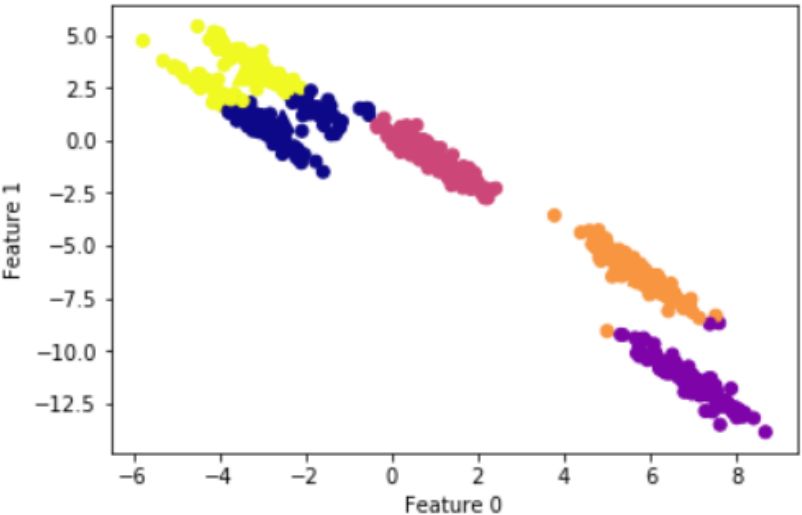
k-means聚類(lèi)算法假設(shè)簇類(lèi)所有方向是同等重要的,若遇到一些奇怪的形狀(如對(duì)角線)時(shí),k-means的聚類(lèi)效果很差,本節(jié)采用DBSCAN算法以及簡(jiǎn)單的介紹下如何去選擇參數(shù)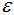 和MinPts。
和MinPts。
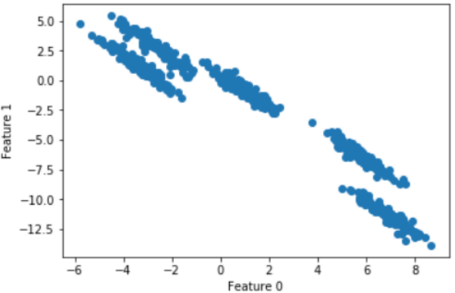
隨機(jī)生成五個(gè)簇類(lèi)的二維數(shù)據(jù):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 生成隨機(jī)簇類(lèi)數(shù)據(jù)
X, y =make_blobs(random_state=170,n_samples=600,centers=5)
rng = np.random.RandomState(74)
# 數(shù)據(jù)拉伸
transformation = rng.normal(size=(2,2))
X = np.dot(X,transformation)
# 繪制延伸圖
plt.scatter(X[:,0],X[:,1])
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()散點(diǎn)圖為:
k-means聚類(lèi)結(jié)果:
按照經(jīng)驗(yàn)MinPts=2*ndims,因此我們?cè)O(shè)置MinPts=4。
為了方便參數(shù)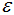 的選擇,我們首先對(duì)數(shù)據(jù)的特征進(jìn)行歸一化:
的選擇,我們首先對(duì)數(shù)據(jù)的特征進(jìn)行歸一化:
#特征歸一化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)假設(shè)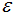 =0.5:
=0.5:
# dbscan聚類(lèi)算法
t0=time.time()
dbscan = DBSCAN(eps=0.12,min_samples = 4)
clusters = dbscan.fit_predict(X_scaled)
# 繪制dbscan聚類(lèi)結(jié)果
plt.scatter(X[:,0],X[:,1],c=clusters,cmap="plasma")
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.title("eps=0.5,minPts=4")
plt.show()
t1=time.time()
print(t1-t0)查看聚類(lèi)結(jié)果:
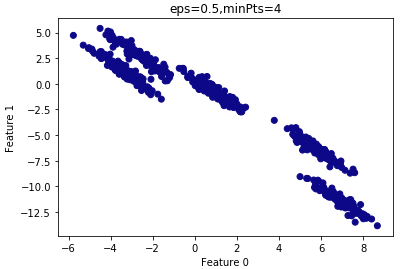
由上圖可知,所有的樣本都?xì)w為一類(lèi),因此 設(shè)置的過(guò)大,需要減小
設(shè)置的過(guò)大,需要減小 。
。
設(shè)置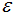 =0.2的結(jié)果:
=0.2的結(jié)果:
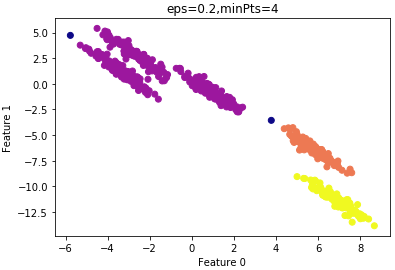
由上圖可知,大部分樣本還是歸為一類(lèi),因此 設(shè)置的過(guò)大,仍需要減小
設(shè)置的過(guò)大,仍需要減小 。
。
設(shè)置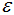 =0.12的結(jié)果:
=0.12的結(jié)果:
結(jié)果令人滿意,看看聚類(lèi)性能度量指數(shù):
# 性能評(píng)價(jià)指標(biāo)ARI
from sklearn.metrics.cluster import adjusted_rand_score
# ARI指數(shù)
print("ARI=",round(adjusted_rand_score(y,clusters),2))
#>
ARI= 0.99由上節(jié)可知,為了較少算法的計(jì)算量,我們嘗試減小MinPts的值。
設(shè)置MinPts=2的結(jié)果:
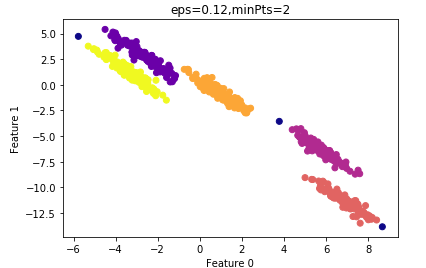
其ARI指數(shù)為:0.99
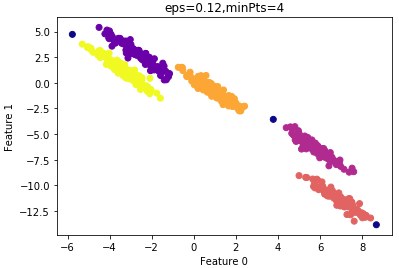
算法的運(yùn)行時(shí)間較minPts=4時(shí)要短,因此我們最終選擇的參數(shù):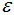 =0.12,minPts=4。
=0.12,minPts=4。
這是一個(gè)根據(jù)經(jīng)驗(yàn)的參數(shù)優(yōu)化算法,實(shí)際項(xiàng)目中,我們首先根據(jù)先驗(yàn)經(jīng)驗(yàn)去設(shè)置參數(shù)的值,確定參數(shù)的大致范圍,然后根據(jù)性能度量去選擇最優(yōu)參數(shù)。
優(yōu)點(diǎn):
1)DBSCAN不需要指定簇類(lèi)的數(shù)量;
2)DBSCAN可以處理任意形狀的簇類(lèi);
3)DBSCAN可以檢測(cè)數(shù)據(jù)集的噪聲,且對(duì)數(shù)據(jù)集中的異常點(diǎn)不敏感;
4)DBSCAN結(jié)果對(duì)數(shù)據(jù)集樣本的隨機(jī)抽樣順序不敏感(細(xì)心的讀者會(huì)發(fā)現(xiàn)樣本的順序不一樣,結(jié)果也可能不一樣,如非核心點(diǎn)處于兩個(gè)聚類(lèi)的邊界,若核心點(diǎn)抽樣順序不同,非核心點(diǎn)歸于不同的簇類(lèi));
缺點(diǎn):
1)DBSCAN最常用的距離度量為歐式距離,對(duì)于高維數(shù)據(jù)集,會(huì)帶來(lái)維度災(zāi)難,導(dǎo)致選擇合適的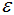 值很難;
值很難;
2)若不同簇類(lèi)的樣本集密度相差很大,則DBSCAN的聚類(lèi)效果很差,因?yàn)檫@類(lèi)數(shù)據(jù)集導(dǎo)致選擇合適的minPts和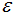 值非常難,很難適用于所有簇類(lèi)。
值非常難,很難適用于所有簇類(lèi)。
好消息!
小白學(xué)視覺(jué)知識(shí)星球
開(kāi)始面向外開(kāi)放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車(chē)道線檢測(cè)、車(chē)輛計(jì)數(shù)、添加眼線、車(chē)牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~