
超詳細(xì)!聚類算法總結(jié)及對比!
一、聚類的簡介
聚類分析,也稱為聚類,是一種無監(jiān)督的機(jī)器學(xué)習(xí)任務(wù)。與監(jiān)督學(xué)習(xí)不同,聚類算法僅依賴輸入數(shù)據(jù),并致力于在特征空間中找到自然的組或群集。這些群集通常是特征空間中的密度區(qū)域,其中同一群集的數(shù)據(jù)點(diǎn)比其他群集更緊密地聚集在一起。
聚類在數(shù)據(jù)分析中扮演著重要角色,有助于深入了解問題域的內(nèi)在結(jié)構(gòu)和模式。這種分析有時(shí)被稱為模式發(fā)現(xiàn)或知識(shí)發(fā)現(xiàn),可以幫助我們洞察數(shù)據(jù)中隱藏的模式和關(guān)聯(lián)。 聚類還可以作為特征工程的一種手段。通過將數(shù)據(jù)點(diǎn)映射到已標(biāo)識(shí)的群集中,我們可以為現(xiàn)有和新的示例創(chuàng)建新的特征標(biāo)簽。
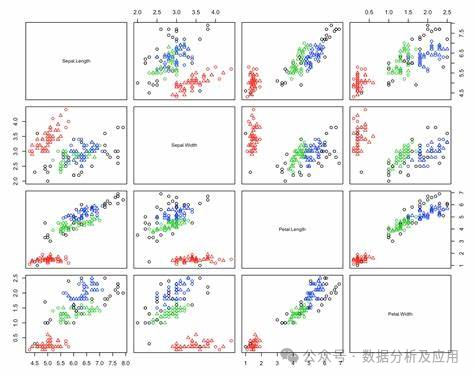
二、聚類方法匯總及對比
實(shí)際項(xiàng)目中Kmeans聚類應(yīng)該是最為常用的聚類模型,但其實(shí)聚類模型的種類還挺多的,每種聚類模型都有其獨(dú)特的特性和應(yīng)用場景。在實(shí)際應(yīng)用中,需要根據(jù)具體的數(shù)據(jù)情況、算力資源和業(yè)務(wù)需求來選擇合適的模型。
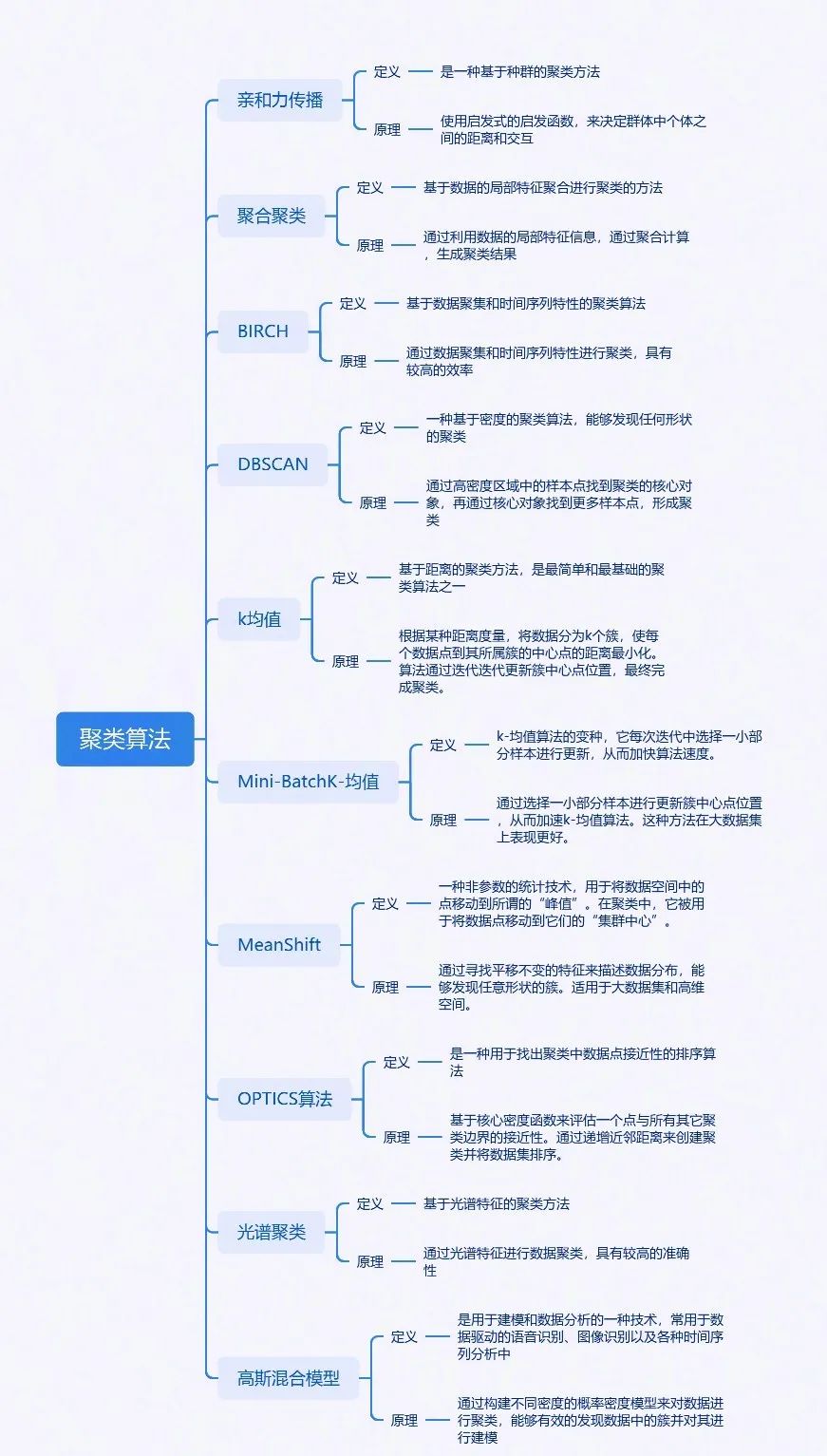
-
親和力傳播:這是一種基于傳播算法的聚類技術(shù),通過模擬信息傳播過程來實(shí)現(xiàn)聚類。它能夠快速有效地處理大規(guī)模數(shù)據(jù)集,特別適合用于社交網(wǎng)絡(luò)分析、推薦系統(tǒng)等領(lǐng)域。
-
聚合聚類:這是一種自下而上的聚類方法,通過逐步將相似的小規(guī)模對象合并為較大的簇,最終形成大規(guī)模的聚類。適合處理大規(guī)模數(shù)據(jù)集,并能夠發(fā)現(xiàn)任意形狀的簇。應(yīng)用場景包括市場細(xì)分、客戶分群等。
-
BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies):利用樹結(jié)構(gòu)進(jìn)行快速聚類和規(guī)約數(shù)據(jù)。通過構(gòu)建聚類特征樹,能夠快速發(fā)現(xiàn)數(shù)據(jù)的聚類結(jié)構(gòu)。適用于大規(guī)模數(shù)據(jù)集,尤其對于具有層次結(jié)構(gòu)的數(shù)據(jù)有較好的效果。應(yīng)用領(lǐng)域包括電子商務(wù)、市場分析等。
-
DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚類算法,能夠?qū)⒚芏认噙B的點(diǎn)劃分為簇,并在噪聲空間數(shù)據(jù)庫中發(fā)現(xiàn)任意形狀的聚類。適用于異常檢測、圖像分割等領(lǐng)域。
-
模糊C-means:一種基于模糊邏輯的聚類算法,與K-means相似,但允許一個(gè)數(shù)據(jù)點(diǎn)屬于多個(gè)簇,每個(gè)簇都有一定的隸屬度或概率。適合處理具有不確定性和模糊性的數(shù)據(jù),在市場細(xì)分、文本挖掘等領(lǐng)域有廣泛應(yīng)用。
-
K-means:經(jīng)典的基于距離的聚類算法,通過迭代計(jì)算將數(shù)據(jù)點(diǎn)劃分為K個(gè)簇,使得每個(gè)數(shù)據(jù)點(diǎn)到其所在簇中心的距離之和最小。應(yīng)用場景包括市場細(xì)分、客戶分群等。
-
K-medoids:改進(jìn)的K-means算法,通過選取簇中位置最中心的樣本點(diǎn)作為參照點(diǎn)來進(jìn)行聚類。對異常值不敏感,適合處理具有較大極端值的數(shù)據(jù)集。
-
Mean Shift:基于密度的非參數(shù)聚類算法,通過計(jì)算每個(gè)點(diǎn)到其他點(diǎn)的距離評估密度,找到密度增大的方向以發(fā)現(xiàn)聚類。適合處理形狀不規(guī)則的簇,并能夠處理噪聲和異常值。應(yīng)用場景包括圖像分割、異常檢測等。
-
OPTICS (Ordering Points To Identify the Clustering Structure):基于密度的聚類算法,通過計(jì)算每個(gè)點(diǎn)到其他點(diǎn)的距離評估密度,并生成排序列表以識(shí)別聚類結(jié)構(gòu)。能夠發(fā)現(xiàn)任意形狀和大小的簇,并處理噪聲和異常值。應(yīng)用領(lǐng)域包括時(shí)間序列分析、圖像分割等。
-
主題模型:用于發(fā)現(xiàn)數(shù)據(jù)集中潛在的主題或模式的概率模型。通過對文檔集合進(jìn)行建模,揭示其中的主題分布和詞語關(guān)系。適用于文本挖掘、信息檢索等領(lǐng)域。
-
高斯混合模型(GMM):一種概率模型,假設(shè)數(shù)據(jù)點(diǎn)是從多個(gè)高斯分布中生成的。能夠擬合復(fù)雜的數(shù)據(jù)分布,并給出每個(gè)數(shù)據(jù)點(diǎn)屬于各個(gè)簇的概率。適用于時(shí)間序列分析、語音識(shí)別等領(lǐng)域。
-
譜聚類:基于圖理論的聚類方法,通過構(gòu)建數(shù)據(jù)的相似性矩陣并將其轉(zhuǎn)化為圖,然后對圖進(jìn)行聚類以發(fā)現(xiàn)數(shù)據(jù)的內(nèi)在結(jié)構(gòu)。能夠發(fā)現(xiàn)任意形狀的簇,并處理噪聲和異常值。應(yīng)用場景包括圖像分割、文本挖掘等。
-
CLIQUE(Clustering In QUEst)是一種基于網(wǎng)格的聚類算法,它通過將數(shù)據(jù)空間劃分成多個(gè)網(wǎng)格單元,然后對每個(gè)網(wǎng)格單元進(jìn)行聚類,從而發(fā)現(xiàn)數(shù)據(jù)的分布模式。CLIQUE算法的特點(diǎn)是簡單、高效,適用于大規(guī)模數(shù)據(jù)集的聚類分析。它能夠處理各種形狀和密度的簇,并且對噪聲和異常值具有較強(qiáng)的魯棒性。然而,CLIQUE算法對網(wǎng)格單元的劃分非常敏感,過細(xì)或過粗的劃分可能會(huì)影響聚類的結(jié)果。
-
STING(Statistical Information Grid)是一種基于網(wǎng)格統(tǒng)計(jì)信息的聚類算法。與CLIQUE不同,STING在每個(gè)網(wǎng)格單元上計(jì)算統(tǒng)計(jì)信息,例如均值、方差、協(xié)方差等,然后基于這些統(tǒng)計(jì)信息進(jìn)行聚類。STING算法的特點(diǎn)是能夠處理高維數(shù)據(jù)集,并且能夠發(fā)現(xiàn)數(shù)據(jù)中的非線性模式。它還具有較強(qiáng)的魯棒性,能夠處理異常值和噪聲。然而,STING算法的計(jì)算復(fù)雜度較高,需要較大的內(nèi)存空間。
-
SKWAVECLUSTER是一種基于聲波聚類的算法。它利用聲波傳播的特性進(jìn)行聚類,將聲波的傳播路徑作為聚類的依據(jù)。SKWAVECLUSTER算法的特點(diǎn)是能夠發(fā)現(xiàn)數(shù)據(jù)中的任意形狀和大小的簇,并且具有較強(qiáng)的魯棒性。它適用于具有復(fù)雜分布模式的數(shù)據(jù)集,例如流數(shù)據(jù)、時(shí)間序列數(shù)據(jù)等。然而,SKWAVECLUSTER算法的計(jì)算復(fù)雜度較高,需要較長的運(yùn)行時(shí)間。
在工作或?qū)W習(xí)中,聚類算法是非常常見的算法之一。這里與大家剖析總結(jié)下常用的聚類算法:
1、親和力傳播 (Affinity Propagation)
模型原理
親和力傳播是一種基于實(shí)例的學(xué)習(xí)算法,用于聚類。它通過發(fā)送消息在數(shù)據(jù)點(diǎn)之間建立關(guān)系,并選擇最佳的聚類結(jié)果。
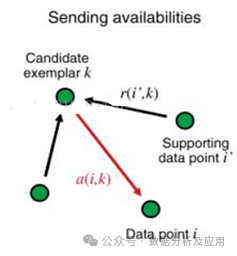
模型訓(xùn)練
訓(xùn)練過程通過不斷迭代,為兩對數(shù)據(jù)點(diǎn)之間相似度的輸入度量。在數(shù)據(jù)點(diǎn)之間交換實(shí)值消息,直到一組高質(zhì)量的范例和相應(yīng)的群集逐漸出現(xiàn),使數(shù)據(jù)點(diǎn)之間形成聚類。
優(yōu)點(diǎn)
-
無需預(yù)先設(shè)定聚類數(shù)量。
-
對異常值具有較強(qiáng)的魯棒性。
缺點(diǎn)
-
對初始參數(shù)敏感。
-
可能產(chǎn)生不完整的簇。
使用場景
適用于任何需要基于實(shí)例學(xué)習(xí)的聚類任務(wù)。
Python示例代碼
from sklearn.cluster import AffinityPropagationfrom sklearn import metricsfrom sklearn.datasets import make_blobs
# 生成樣本數(shù)據(jù)centers = [[1, 1], [-1, -1], [1, -1]]X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.4, random_state=0)
# 訓(xùn)練模型af = AffinityPropagation(preference=-50).fit(X)cluster_centers_indices = af.cluster_centers_indices_labels = af.labels_
n_clusters_ = len(cluster_centers_indices)print('Estimated number of clusters: %d' % n_clusters_)print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))print("Adjusted Rand Index (ARI): %0.3f"% metrics.adjusted_rand_score(labels_true, labels))print("Adjusted Mutual Information (AMI): %0.3f"% metrics.adjusted_mutual_info_score(labels_true, labels))
2、聚合聚類 (Agglomerative Clustering)
模型原理
聚合聚類是一種自底向上的聚類方法。它從數(shù)據(jù)點(diǎn)(或稱為觀測值)的集合開始,然后將這些點(diǎn)視為初始的簇。接著,算法逐步合并這些簇,直到滿足某個(gè)停止條件,如達(dá)到預(yù)設(shè)的簇?cái)?shù)量或達(dá)到某個(gè)特定的簇大小。在這個(gè)過程中,算法通過計(jì)算簇之間的距離來確定哪些簇應(yīng)該被合并。
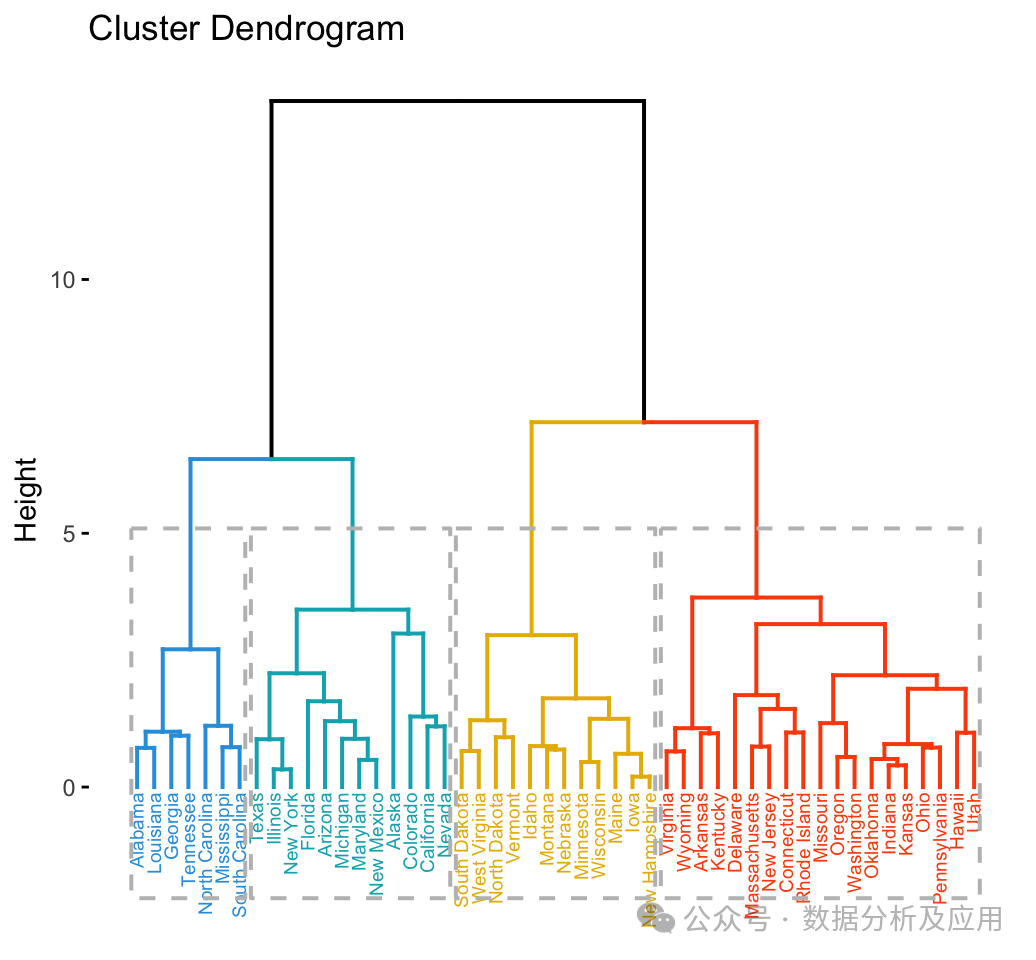
模型訓(xùn)練
-
初始化:每個(gè)數(shù)據(jù)點(diǎn)被視為一個(gè)簇。
-
合并:根據(jù)某種距離度量(如歐氏距離、余弦相似度等),將最近的簇合并為一個(gè)新的簇。
-
重復(fù):重復(fù)步驟2,直到滿足停止條件。
-
輸出:返回合并后的簇結(jié)果。
優(yōu)點(diǎn)
- 層次結(jié)構(gòu):能夠生成數(shù)據(jù)的層次結(jié)構(gòu)或嵌套聚類,這在某些應(yīng)用中非常有用。
- 可解釋性:由于是自底向上的方法,可以更容易地解釋和可視化結(jié)果。
-
處理大型數(shù)據(jù)集:由于不需要一次性處理所有數(shù)據(jù),因此可以有效地處理大型數(shù)據(jù)集。
缺點(diǎn)
-
時(shí)間復(fù)雜度: 隨著數(shù)據(jù)集規(guī)模的增加,時(shí)間復(fù)雜度可能會(huì)迅速增加。
-
不平衡簇: 可能產(chǎn)生不平衡的簇,即某些簇包含大量數(shù)據(jù)點(diǎn),而其他簇則包含很少的數(shù)據(jù)點(diǎn)。
-
初始化敏感: 對初始化的選擇敏感,可能會(huì)導(dǎo)致不同的聚類結(jié)果。
使用場景
- 層次聚類:適用于需要層次結(jié)構(gòu)的聚類任務(wù),如市場細(xì)分或社交網(wǎng)絡(luò)分析。
- 異常檢測:可以通過觀察聚類結(jié)果中的離群點(diǎn)來檢測異常值。
-
數(shù)據(jù)預(yù)處理:在某些機(jī)器學(xué)習(xí)任務(wù)中,可以使用聚合聚類作為預(yù)處理步驟來簡化數(shù)據(jù)或提取特征。
Python示例代碼(使用scikit-learn庫):
from sklearn.cluster import AgglomerativeClustering # 導(dǎo)入AgglomerativeClustering類from sklearn import datasets # 導(dǎo)入datasets用于生成樣本數(shù)據(jù)from sklearn.preprocessing import StandardScaler # 導(dǎo)入StandardScaler進(jìn)行標(biāo)準(zhǔn)化處理import matplotlib.pyplot as plt # 導(dǎo)入繪圖庫
?
# 生成樣本數(shù)據(jù)iris = datasets.load_iris() # 使用Iris數(shù)據(jù)集作為示例X = iris["data"] # 提取特征矩陣
# 數(shù)據(jù)標(biāo)準(zhǔn)化scaler = StandardScaler()X = scaler.fit_transform(X) # 對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理
# 設(shè)置聚類數(shù)n_clusters = 2 # 根據(jù)需求設(shè)置聚類數(shù)# 創(chuàng)建AgglomerativeClustering對象并擬合數(shù)據(jù)clustering = AgglomerativeClustering(n_clusters=n_clusters)labels = clustering.fit_predict(X) # 獲取每個(gè)樣本點(diǎn)的聚類標(biāo)簽# 可視化結(jié)果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 使用viridis色彩映射繪制結(jié)果圖plt.show() # 顯示結(jié)果圖 ```
3、BIRCH 聚類模型
模型原理
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)是一種基于層次的聚類方法。它通過構(gòu)建一個(gè)聚類特征樹(Clustering Feature Tree,CF Tree)來組織和存儲(chǔ)數(shù)據(jù)點(diǎn),并利用該樹進(jìn)行聚類。BIRCH的核心思想是利用聚類特征(Clustering Feature,CF)來描述數(shù)據(jù)點(diǎn)的聚類信息,并通過逐步合并最相似的聚類對來形成層次聚類。
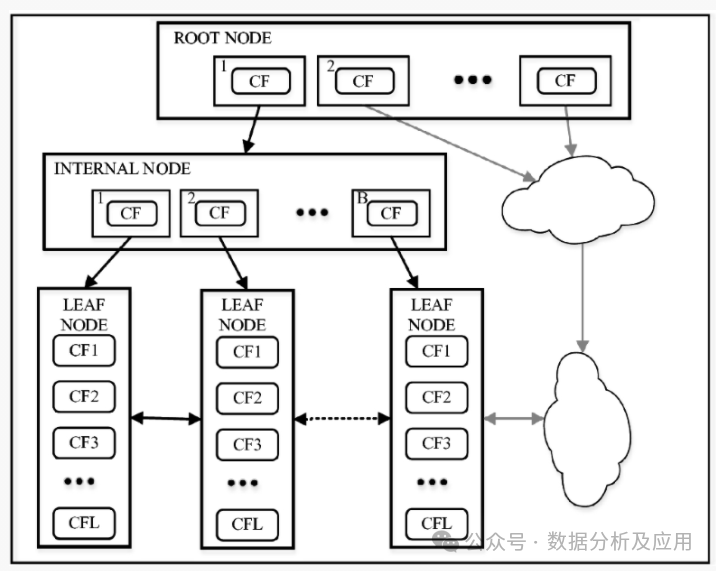
模型訓(xùn)練
-
初始化:為每個(gè)數(shù)據(jù)點(diǎn)創(chuàng)建一個(gè)聚類特征(CF)。
-
合并:根據(jù)相似度度量,合并最相似的CF對。
-
重復(fù):重復(fù)步驟2,直到滿足停止條件(如達(dá)到預(yù)設(shè)的簇?cái)?shù)量或達(dá)到某個(gè)特定的簇大小)。
-
輸出:返回合并后的簇結(jié)果。
優(yōu)點(diǎn)
- 高效性:對于大規(guī)模數(shù)據(jù)集,BIRCH具有較高的效率。
- 可擴(kuò)展性:由于其基于樹的存儲(chǔ)結(jié)構(gòu),BIRCH在處理大量數(shù)據(jù)時(shí)具有良好的可擴(kuò)展性。
-
靈活性:能夠處理不同類型的數(shù)據(jù),包括非數(shù)值型數(shù)據(jù)。
缺點(diǎn)
- 參數(shù)敏感性:BIRCH對參數(shù)的選擇較為敏感,如CF樹的構(gòu)建參數(shù)和相似度度量方法等。
- 不平衡簇:可能產(chǎn)生不平衡的簇,尤其是當(dāng)數(shù)據(jù)分布不均時(shí)。
-
計(jì)算復(fù)雜度:對于高維數(shù)據(jù),BIRCH的計(jì)算復(fù)雜度可能較高。
使用場景
- 大規(guī)模數(shù)據(jù)集:BIRCH適用于處理大規(guī)模數(shù)據(jù)集,特別是那些需要高效和可擴(kuò)展聚類的場景。
- 多維數(shù)據(jù):適用于處理多維特征的數(shù)據(jù),能夠有效地處理非數(shù)值型數(shù)據(jù)。
-
層次聚類:適用于需要層次結(jié)構(gòu)的聚類任務(wù),如市場細(xì)分或社交網(wǎng)絡(luò)分析。
Python示例代碼(使用pyclustering庫):
from pyclustering.cluster.birch import birch # 導(dǎo)入BIRCH聚類算法from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer # 導(dǎo)入中心初始化器from pyclustering.samples.definitions import FCPS_SAMPLES # 導(dǎo)入樣本數(shù)據(jù)集from pyclustering.utils import read_sample # 導(dǎo)入讀取樣本數(shù)據(jù)的工具from pyclustering.view.gplot import gplot # 導(dǎo)入繪圖庫from pyclustering.view.dendrogram import dendrogram # 導(dǎo)入層次聚類結(jié)果的顯示工具from pyclustering.metrics.pairwise import euclidean_distance # 導(dǎo)入歐氏距離度量函數(shù)import matplotlib.pyplot as plt # 導(dǎo)入繪圖庫import numpy as np # 導(dǎo)入numpy庫進(jìn)行數(shù)組操作
# 讀取樣本數(shù)據(jù)集[two_diamonds]sample = read_sample(FCPS_SAMPLES.SAMPLE_TWO_DIAMONDS)# 使用K-Means++初始化方法為BIRCH算法生成中心點(diǎn)(兩個(gè)中心點(diǎn))initial_centers = kmeans_plusplus_initializer(sample, 2).initialize()# 創(chuàng)建BIRCH聚類對象并使用中心點(diǎn)初始化其內(nèi)部結(jié)構(gòu)birch_instance = birch(sample, initial_centers, dist_metric=euclidean_distance)
# 執(zhí)行聚類操作birch_instance.process()# 獲取聚類結(jié)果clusters = birch_instance.get_clusters() # 獲取簇的索引列表# 可視化結(jié)果gplot(birch_instance.get_data(),BirchDataVisualizer(clusters),'birch') # BirchDataVisualizer是用于可視化BIRCH數(shù)據(jù)的自定義工具類 ```
4、DBSCAN 聚類模型
模型原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一種基于密度的聚類方法。它的主要思想是:一個(gè)簇是由一個(gè)密度足夠大的區(qū)域所組成的,并且這個(gè)區(qū)域是核心對象所連接的稠密區(qū)域。DBSCAN將簇定義為具有足夠高密度的區(qū)域,并且通過噪聲點(diǎn)將簇與相鄰的密度區(qū)域分開。
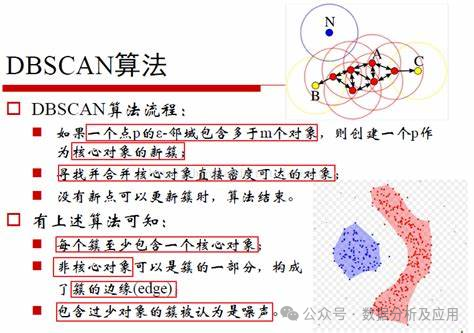
模型訓(xùn)練
- 初始化:選擇一個(gè)未被訪問過的點(diǎn)作為當(dāng)前點(diǎn)。
- 密度估計(jì):如果當(dāng)前點(diǎn)的ε-鄰域內(nèi)的點(diǎn)數(shù)量大于等于MinPts,則當(dāng)前點(diǎn)為核心點(diǎn)。否則,當(dāng)前點(diǎn)為噪聲點(diǎn)。
- 擴(kuò)展簇:從核心點(diǎn)開始,將其標(biāo)記為簇的一部分,并遞歸地訪問其ε-鄰域內(nèi)的所有點(diǎn)。如果某個(gè)點(diǎn)的ε-鄰域內(nèi)的點(diǎn)數(shù)量大于等于MinPts,則該點(diǎn)為核心點(diǎn),并將其標(biāo)記為已訪問。
- 重復(fù):重復(fù)步驟2和3,直到所有點(diǎn)都被訪問。
-
輸出:返回所有簇的結(jié)果。
優(yōu)點(diǎn)
- 密度敏感:能夠發(fā)現(xiàn)任何形狀的簇,并處理異常值和噪聲。
- 可擴(kuò)展性:對于大規(guī)模數(shù)據(jù)集,DBSCAN具有較好的可擴(kuò)展性。
-
無需預(yù)設(shè)簇?cái)?shù)量:與其他基于距離的聚類方法相比,DBSCAN不需要預(yù)設(shè)簇的數(shù)量。
缺點(diǎn)
- 參數(shù)敏感:對參數(shù)ε和MinPts的選擇較為敏感,不同的參數(shù)值可能會(huì)導(dǎo)致不同的聚類結(jié)果。
- 計(jì)算量大:對于高維數(shù)據(jù),DBSCAN的計(jì)算量可能會(huì)很大。
-
對噪聲和異常值敏感:如果數(shù)據(jù)集中存在大量噪聲或異常值,可能會(huì)影響聚類的效果。
使用場景
- 異常檢測:由于DBSCAN對噪聲和異常值敏感,因此可以用于異常檢測任務(wù)。
- 任意形狀的簇:對于需要發(fā)現(xiàn)任意形狀的簇的應(yīng)用,如社交網(wǎng)絡(luò)分析、圖像分割等,DBSCAN是一個(gè)很好的選擇。
-
數(shù)據(jù)預(yù)處理:在某些機(jī)器學(xué)習(xí)任務(wù)中,可以使用DBSCAN對數(shù)據(jù)進(jìn)行預(yù)處理,以便進(jìn)一步的分析或分類。
Python示例代碼(使用scikit-learn庫):
from sklearn.cluster import DBSCAN # 導(dǎo)入DBSCAN聚類算法from sklearn import datasets # 導(dǎo)入datasets用于生成樣本數(shù)據(jù)import matplotlib.pyplot as plt # 導(dǎo)入繪圖庫
# 生成樣本數(shù)據(jù)iris = datasets.load_iris() # 使用Iris數(shù)據(jù)集作為示例X = iris["data"] # 提取特征矩陣
# 創(chuàng)建DBSCAN對象并擬合數(shù)據(jù)dbscan = DBSCAN(eps=0.3, min_samples=5) # eps是鄰域半徑,min_samples是形成核心對象的最小點(diǎn)數(shù)labels = dbscan.fit_predict(X) # 獲取每個(gè)樣本點(diǎn)的聚類標(biāo)簽
# 可視化結(jié)果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 使用viridis色彩映射繪制結(jié)果圖plt.show() # 顯示結(jié)果圖 ```
5、K-Means 聚類模型
模型原理
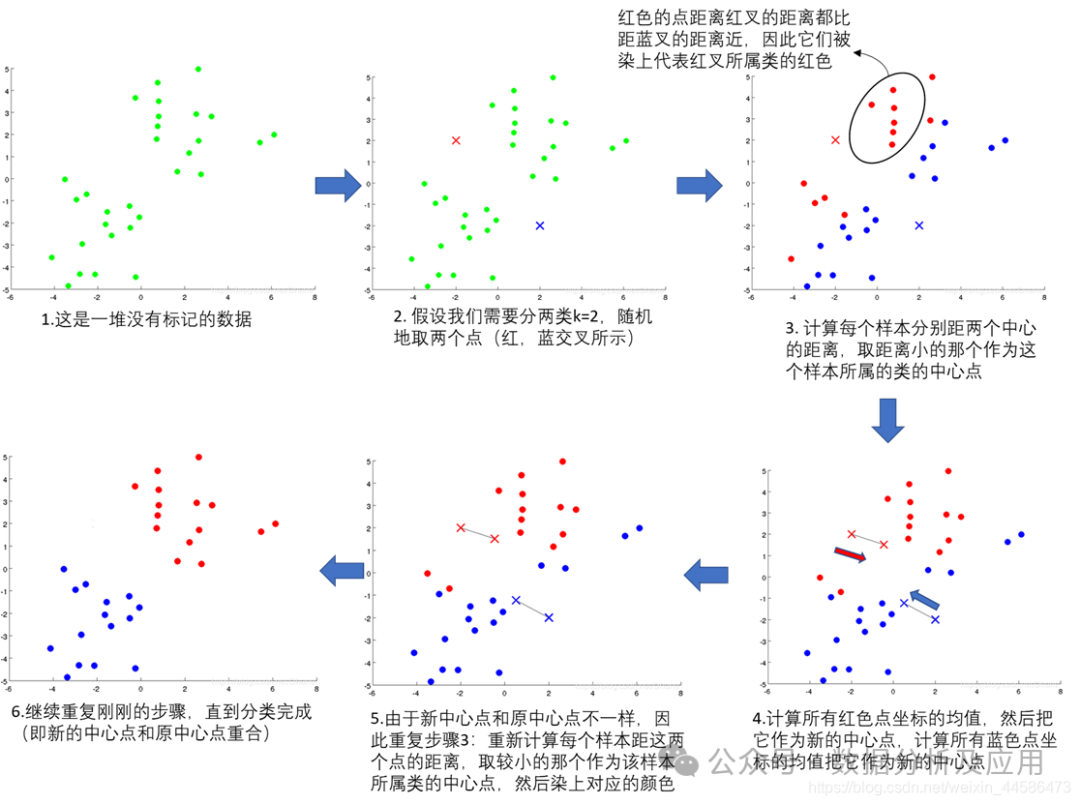
K-Means聚類是一種基于距離的聚類方法,通過最小化每個(gè)數(shù)據(jù)點(diǎn)到其所屬簇中心點(diǎn)的距離之和,將數(shù)據(jù)點(diǎn)劃分為K個(gè)簇。算法的主要思想是:每個(gè)簇有一個(gè)中心點(diǎn),數(shù)據(jù)點(diǎn)被分配到最近的中心點(diǎn)所在的簇中。通過迭代更新每個(gè)簇的中心點(diǎn),使得所有數(shù)據(jù)點(diǎn)到其所屬簇的中心點(diǎn)的距離之和最小。

模型訓(xùn)練
- 初始化:隨機(jī)選擇K個(gè)中心點(diǎn)。
- 分配數(shù)據(jù)點(diǎn):將每個(gè)數(shù)據(jù)點(diǎn)分配到最近的中心點(diǎn)所在的簇中。
- 更新中心點(diǎn):重新計(jì)算每個(gè)簇的中心點(diǎn),即簇中所有數(shù)據(jù)點(diǎn)的均值。
- 重復(fù):重復(fù)步驟2和3,直到中心點(diǎn)不再發(fā)生顯著變化或達(dá)到預(yù)設(shè)的迭代次數(shù)。
-
輸出:返回K個(gè)簇的結(jié)果。
優(yōu)點(diǎn)
- 簡單易理解:K-Means聚類模型簡單直觀,易于理解。
- 可擴(kuò)展性:對于大規(guī)模數(shù)據(jù)集,K-Means算法具有較好的可擴(kuò)展性。
- 無監(jiān)督學(xué)習(xí):K-Means是一種無監(jiān)督學(xué)習(xí)方法,適用于未標(biāo)記的數(shù)據(jù)集。
-
對異常值不敏感:由于是基于距離的聚類方法,異常值對聚類結(jié)果的影響較小。
缺點(diǎn)
- 參數(shù)敏感:對初始選擇的K值和初始中心點(diǎn)敏感,不同的初始參數(shù)可能導(dǎo)致不同的聚類結(jié)果。
- 易陷入局部最優(yōu)解:可能陷入局部最優(yōu)解,而非全局最優(yōu)解。
- 形狀限制:只能發(fā)現(xiàn)球形簇,對于非球形簇的形狀可能無法準(zhǔn)確識(shí)別。
-
計(jì)算量大:對于高維數(shù)據(jù),計(jì)算量較大。
使用場景
- 異常檢測:K-Means聚類可以用于異常檢測,將異常值識(shí)別為與其它數(shù)據(jù)點(diǎn)距離較遠(yuǎn)的簇。
- 市場細(xì)分:在市場營銷領(lǐng)域,可以使用K-Means聚類將客戶劃分為不同的細(xì)分市場。
- 圖像分割:在圖像處理中,可以使用K-Means聚類進(jìn)行圖像分割,將圖像劃分為多個(gè)區(qū)域或?qū)ο蟆?/span>
-
特征提取:通過K-Means聚類可以提取數(shù)據(jù)的內(nèi)在結(jié)構(gòu)特征,用于分類或預(yù)測任務(wù)。
Python示例代碼(使用scikit-learn庫):
from sklearn.cluster import KMeans # 導(dǎo)入K-Means聚類算法from sklearn import datasets # 導(dǎo)入datasets用于生成樣本數(shù)據(jù)import matplotlib.pyplot as plt # 導(dǎo)入繪圖庫
# 生成樣本數(shù)據(jù)iris = datasets.load_iris() # 使用Iris數(shù)據(jù)集作為示例X = iris["data"] # 提取特征矩陣
# 創(chuàng)建K-Means對象并擬合數(shù)據(jù)kmeans = KMeans(n_clusters=3) # 假設(shè)有3個(gè)簇labels = kmeans.fit_predict(X) # 獲取每個(gè)樣本點(diǎn)的聚類標(biāo)簽
# 可視化結(jié)果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 使用viridis色彩映射繪制結(jié)果圖plt.show() # 顯示結(jié)果圖 ```
6、高斯混合模型
高斯混合模型是一種概率模型,用于表示數(shù)據(jù)點(diǎn)集合的混合高斯分布。在聚類任務(wù)中,高斯混合模型將數(shù)據(jù)點(diǎn)劃分為K個(gè)簇,每個(gè)簇的數(shù)據(jù)點(diǎn)都遵循一個(gè)高斯分布(正態(tài)分布)。

高斯混合模型的原理基于以下幾個(gè)假設(shè):
- 每個(gè)簇的數(shù)據(jù)點(diǎn)都遵循一個(gè)高斯分布:每個(gè)簇的分布參數(shù)(均值和協(xié)方差)由該簇中的數(shù)據(jù)點(diǎn)估計(jì)得出。
- 簇之間相互獨(dú)立:每個(gè)簇的高斯分布是獨(dú)立的,不同簇之間沒有依賴關(guān)系。
-
數(shù)據(jù)點(diǎn)屬于各個(gè)簇的概率已知:通過概率模型計(jì)算每個(gè)數(shù)據(jù)點(diǎn)屬于各個(gè)簇的概率。
模型訓(xùn)練
- 初始化:隨機(jī)選擇K個(gè)中心點(diǎn),每個(gè)中心點(diǎn)初始化為數(shù)據(jù)集中的一個(gè)數(shù)據(jù)點(diǎn)。
- 分配數(shù)據(jù)點(diǎn):計(jì)算每個(gè)數(shù)據(jù)點(diǎn)到每個(gè)中心點(diǎn)的距離,將數(shù)據(jù)點(diǎn)分配到最近的中心點(diǎn)所在的簇中。
- 更新中心點(diǎn)和協(xié)方差:重新計(jì)算每個(gè)簇的中心點(diǎn)和協(xié)方差(均值和方差)。
- 重新分配數(shù)據(jù)點(diǎn):根據(jù)新的中心點(diǎn)和協(xié)方差,重新分配數(shù)據(jù)點(diǎn)到各個(gè)簇中。
- 重復(fù):重復(fù)步驟3和4,直到中心點(diǎn)和協(xié)方差不再發(fā)生顯著變化或達(dá)到預(yù)設(shè)的迭代次數(shù)。
-
輸出:返回K個(gè)簇的結(jié)果,每個(gè)簇具有其高斯分布的參數(shù)(均值和協(xié)方差)。
優(yōu)點(diǎn)
- 適用于任意形狀的簇:高斯混合模型能夠發(fā)現(xiàn)任意形狀的簇,因?yàn)楦咚狗植伎梢詳M合各種形狀的數(shù)據(jù)分布。
- 概率模型:高斯混合模型是一個(gè)概率模型,能夠計(jì)算每個(gè)數(shù)據(jù)點(diǎn)屬于各個(gè)簇的概率,便于后續(xù)的分析或應(yīng)用。
-
無參數(shù)依賴性:高斯混合模型的性能不依賴于特定的參數(shù)設(shè)置,只需指定簇的數(shù)量K。
缺點(diǎn)
- 對初始參數(shù)敏感:初始選擇的中心點(diǎn)和初始簇的數(shù)量K對最終的聚類結(jié)果有一定影響,可能需要多次嘗試來獲得最佳結(jié)果。
- 計(jì)算量大:隨著數(shù)據(jù)集規(guī)模的增大,高斯混合模型的計(jì)算量也會(huì)顯著增加。
-
需要預(yù)設(shè)簇?cái)?shù)量K:需要預(yù)先指定簇的數(shù)量K,如果K值選擇不當(dāng),可能導(dǎo)致聚類結(jié)果不佳。
使用場景
- 聚類任務(wù):高斯混合模型廣泛應(yīng)用于各種聚類任務(wù),如圖像分割、文本聚類、市場細(xì)分等。
- 異常檢測:通過比較數(shù)據(jù)點(diǎn)到各個(gè)簇中心的距離,可以檢測異常值。
- 推薦系統(tǒng):結(jié)合概率模型的特點(diǎn),可以用于推薦系統(tǒng)中的內(nèi)容推薦。
-
生物信息學(xué)和化學(xué)信息學(xué):在基因表達(dá)數(shù)據(jù)分析、蛋白質(zhì)分類等生物信息學(xué)領(lǐng)域以及化學(xué)信息學(xué)領(lǐng)域有廣泛應(yīng)用。
Python示例代碼(使用scikit-learn庫):
from sklearn.mixture import GaussianMixture # 導(dǎo)入高斯混合模型from sklearn import datasets # 導(dǎo)入datasets用于生成樣本數(shù)據(jù)import matplotlib.pyplot as plt # 導(dǎo)入繪圖庫
# 生成樣本數(shù)據(jù)iris = datasets.load_iris() # 使用Iris數(shù)據(jù)集作為示例X = iris["data"] # 提取特征矩陣
# 創(chuàng)建高斯混合模型對象并擬合數(shù)據(jù)gmm = GaussianMixture(n_components=3) # 假設(shè)有3個(gè)簇labels = gmm.fit_predict(X) # 獲取每個(gè)樣本點(diǎn)的聚類標(biāo)簽
# 可視化結(jié)果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 使用viridis色彩映射繪制結(jié)果圖plt.show() # 顯示結(jié)果圖 ```
三、聚類評估指標(biāo)
常用評估指標(biāo)包括外部評價(jià)指標(biāo)和內(nèi)部評價(jià)指標(biāo)。 外部評價(jià)指標(biāo)是在已知真實(shí)標(biāo)簽的情況下評估聚類結(jié)果的準(zhǔn)確性,而內(nèi)部評價(jià)指標(biāo)則是在不知道真實(shí)標(biāo)簽的情況下評估聚類結(jié)果的質(zhì)量。 外部評價(jià)指標(biāo):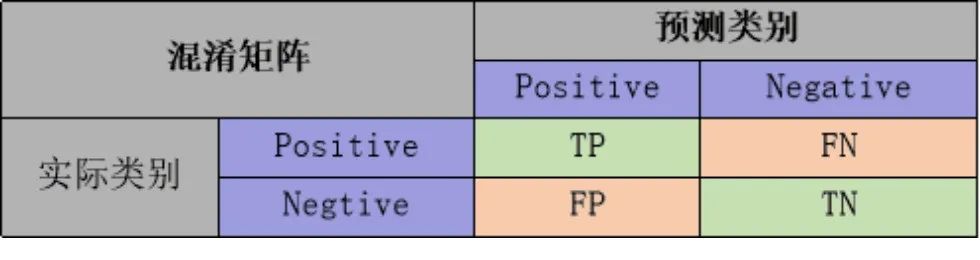 準(zhǔn)確率(accuracy):即所有的預(yù)測正確(TP+TN)的占總數(shù)(TP+FP+TN+FN)的比例; 查準(zhǔn)率P(precision): 是指分類器預(yù)測為Positive的正確樣本(TP)的個(gè)數(shù)占所有預(yù)測為Positive樣本個(gè)數(shù)(TP+FP)的比例; 查全率R(recall): 是指分類器預(yù)測為Positive的正確樣本(TP)的個(gè)數(shù)占所有的實(shí)際為Positive樣本個(gè)數(shù)(TP+FN)的比例。 F1-score 是查準(zhǔn)率P、查全率R的調(diào)和平均:
準(zhǔn)確率(accuracy):即所有的預(yù)測正確(TP+TN)的占總數(shù)(TP+FP+TN+FN)的比例; 查準(zhǔn)率P(precision): 是指分類器預(yù)測為Positive的正確樣本(TP)的個(gè)數(shù)占所有預(yù)測為Positive樣本個(gè)數(shù)(TP+FP)的比例; 查全率R(recall): 是指分類器預(yù)測為Positive的正確樣本(TP)的個(gè)數(shù)占所有的實(shí)際為Positive樣本個(gè)數(shù)(TP+FN)的比例。 F1-score 是查準(zhǔn)率P、查全率R的調(diào)和平均:
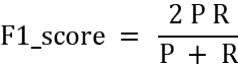
調(diào)整蘭德系數(shù)(Adjusted Rand Index, ARI): 衡量聚類結(jié)果與真實(shí)標(biāo)簽的匹配程度,取值范圍為[-1,1],值越大表示聚類效果越好。
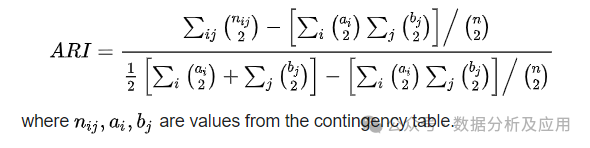 內(nèi)部評價(jià)指標(biāo):
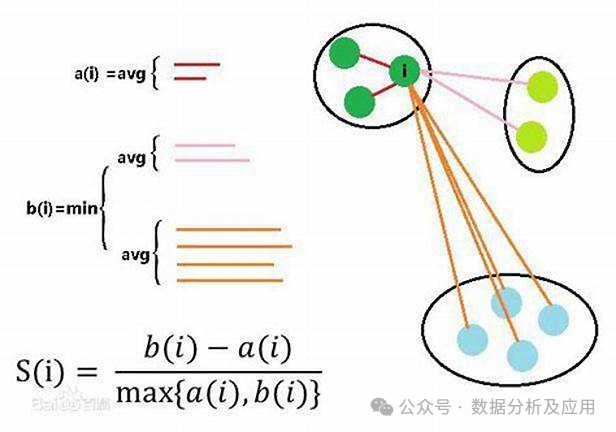
內(nèi)部評價(jià)指標(biāo): 輪廓系數(shù)(Silhouette Coefficient): 通過計(jì)算同類樣本間的平均距離和不同類樣本間的平均距離來評估聚類效果,取值范圍為[-1,1],值越大表示聚類效果越好。
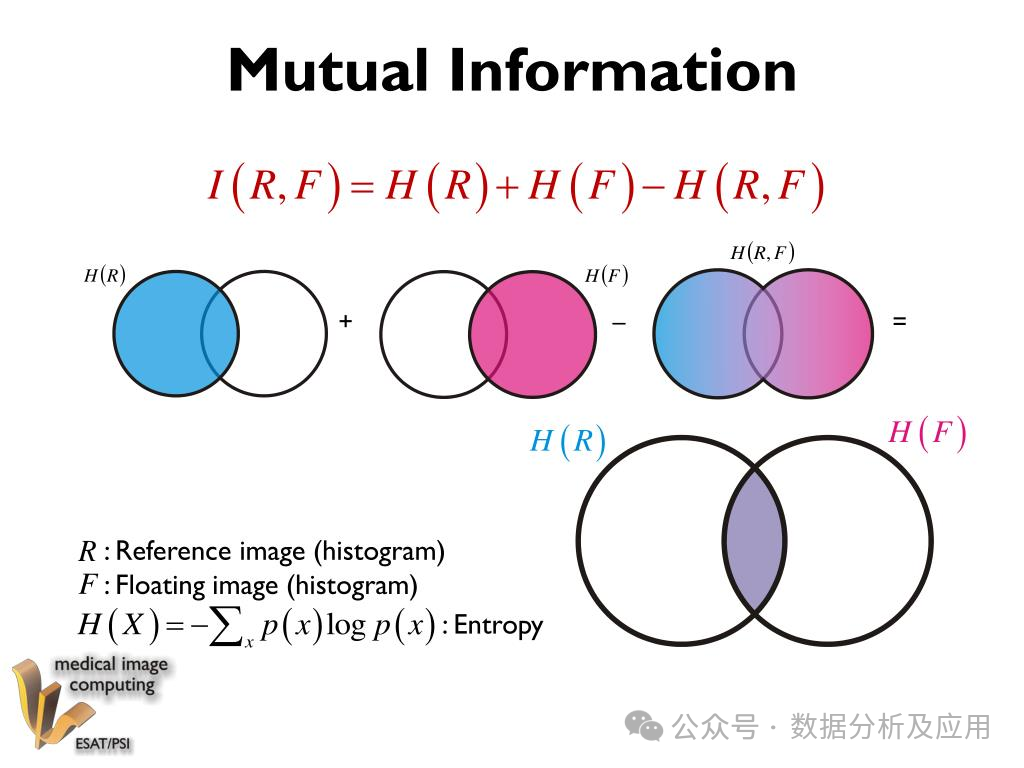
 標(biāo)準(zhǔn)化互信息(Normalized Mutual Information, NMI): 衡量聚類結(jié)果與真實(shí)標(biāo)簽的相似性,取值范圍為[0,1],值越大表示聚類效果越好。 互信息(Mutual Information, MI): 類似于NMI,但不需要對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理。
標(biāo)準(zhǔn)化互信息(Normalized Mutual Information, NMI): 衡量聚類結(jié)果與真實(shí)標(biāo)簽的相似性,取值范圍為[0,1],值越大表示聚類效果越好。 互信息(Mutual Information, MI): 類似于NMI,但不需要對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理。
聚類評估指標(biāo)對比: 準(zhǔn)確率、召回率和F值: 簡單易用,但可能不適用于非平衡數(shù)據(jù)集。
ARI: 對異常值不敏感,但計(jì)算復(fù)雜度較高,且對參數(shù)設(shè)置敏感。 輪廓系數(shù): 考慮了樣本間的相對距離,能夠更準(zhǔn)確地反映聚類效果,但計(jì)算復(fù)雜度較高。 NMI和MI: 能夠準(zhǔn)確地評估聚類效果,尤其適用于樣本分布不均勻的情況,但計(jì)算復(fù)雜度較高。 在處理實(shí)際問題時(shí),可以嘗試多種指標(biāo),以便更全面地評估聚類效果。同時(shí), 雖然存在多種量化聚類質(zhì)量的指標(biāo), 但對聚類群的實(shí)際評估往往是主觀的,并很經(jīng)常需要結(jié)合領(lǐng)域的業(yè)務(wù)經(jīng)驗(yàn)。