
4種聚類算法及可視化(Python)

來源:數(shù)據(jù)STUDIO 算法進(jìn)階 本文約2300字,建議閱讀12分鐘
在這篇文章中,基于20家公司的股票價(jià)格時(shí)間序列數(shù)據(jù)。
蘋果(AAPL),亞馬遜(AMZN),F(xiàn)acebook(META),特斯拉(TSLA),Alphabet(谷歌)(GOOGL),殼牌(SHEL),Suncor能源(SU),埃克森美孚公司(XOM),Lululemon(LULU),沃爾瑪(WMT),Carters(CRI)、 Childrens Place (PLCE), TJX Companies (TJX), Victoria's Secret & Co (VSCO), Macy's (M), Wayfair (W), Dollar Tree (DLTR), CVS Caremark (CVS), Walgreen (WBA), Curaleaf Holdings Inc. (CURLF)
correlation_mat=df_combined.corr()
定義一個(gè)效用函數(shù)來顯示集群和屬于該集群的公司。
# 用來打印公司名稱和它們所分配的集群的實(shí)用函數(shù)
def print_clusters(df_combined,cluster_labels):
cluster_dict = {}
for i, label in enumerate(cluster_labels):
if label not in cluster_dict:
cluster_dict[label] = []
cluster_dict[label].append(df_combined.columns[i])
# 打印出每個(gè)群組中的公司 -- 建議關(guān)注@公眾號(hào):數(shù)據(jù)STUDIO 定時(shí)推送更多優(yōu)質(zhì)內(nèi)容
for cluster, companies in cluster_dict.items():
print(f"Cluster {cluster}: {', '.join(companies)}")
方法1:K-means聚類法
from sklearn.cluster import KMeans
# Perform k-means clustering with four clusters
clustering = KMeans(n_clusters=4, random_state=0).fit(correlation_mat)
# Print the cluster labels
cluster_labels=clustering.labels_
print_clusters(df_combined,cluster_labels)
k-means聚類的結(jié)果
from sklearn.cluster import AgglomerativeClustering
# 進(jìn)行分層聚類
clustering = AgglomerativeClustering(n_clusters=n_clusters,
affinity='precomputed',
linkage='complete'
).fit(correlation_mat)
# Display the cluster labels
print_clusters(df_combined,clustering.labels_)
分層聚類的結(jié)果
from sklearn.cluster import AffinityPropagation
# 用默認(rèn)參數(shù)進(jìn)行親和傳播聚類
clustering = AffinityPropagation(affinity='precomputed').fit(correlation_mat)
# Display the cluster labels
print_clusters(df_combined,clustering.labels_)

from sklearn.cluster import DBSCAN
# Removing negative values in correlation matrix
correlation_mat_pro = 1 + correlation_mat
# Perform DBSCAN clustering with eps=0.5 and min_samples=5
clustering = DBSCAN(eps=0.5, min_samples=5, metric='precomputed').fit(correlation_mat_pro)
# Print the cluster labels
print_clusters(df_combined,clustering.labels_)

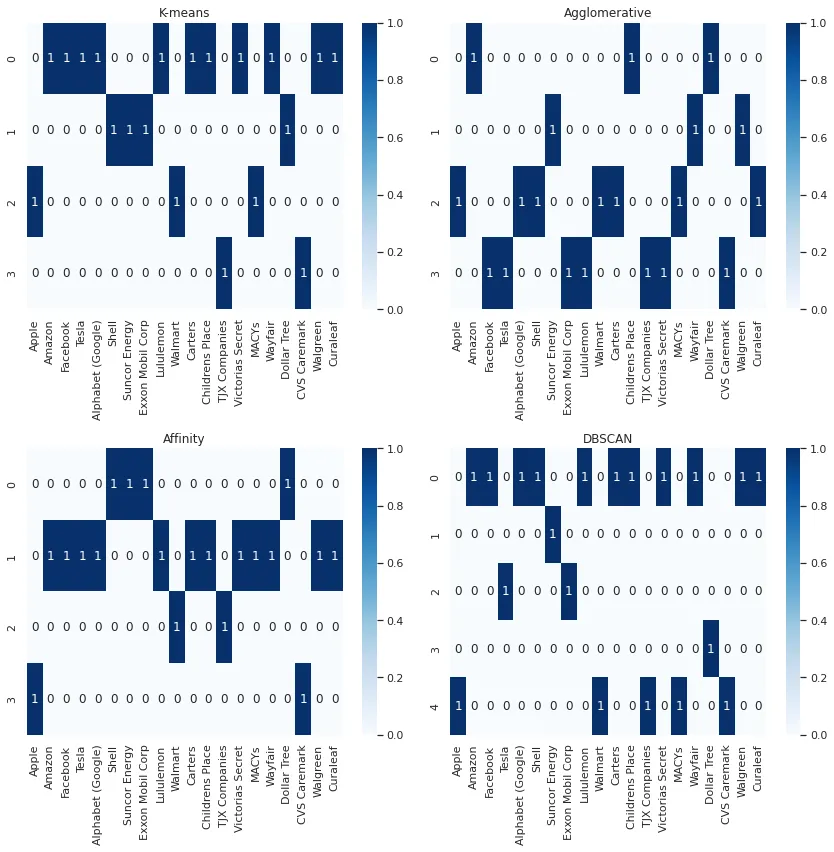
def plot_cluster_heatmaps(cluster_results, companies):
# 從字典中提取key和value
methods = list(cluster_results.keys())
labels = list(cluster_results.values())
# 定義每個(gè)方法的熱圖數(shù)據(jù)
heatmaps = []
for i in range(len(methods)):
heatmap = np.zeros((len(np.unique(labels[i])), len(companies)))
for j in range(len(companies)):
heatmap[labels[i][j], j] = 1
heatmaps.append(heatmap)
# Plot the heatmaps in a 2x2 grid
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 12))
for i in range(len(methods)):
row = i // 2
col = i % 2
sns.heatmap(heatmaps[i], cmap="Blues", annot=True, fmt="g", xticklabels=companies, ax=axs[row, col])
axs[row, col].set_title(methods[i])
plt.tight_layout()
plt.show()
companies=df_combined.columns
plot_cluster_heatmaps(cluster_results, companies)
評(píng)論
圖片
表情