資深數(shù)據(jù)產(chǎn)品經(jīng)理:如何從0到1構建埋點體系

首次開荒指南 埋點體系迭代指南
體系落地指南
數(shù)據(jù)埋點實操案例
一、開荒
二、迭代



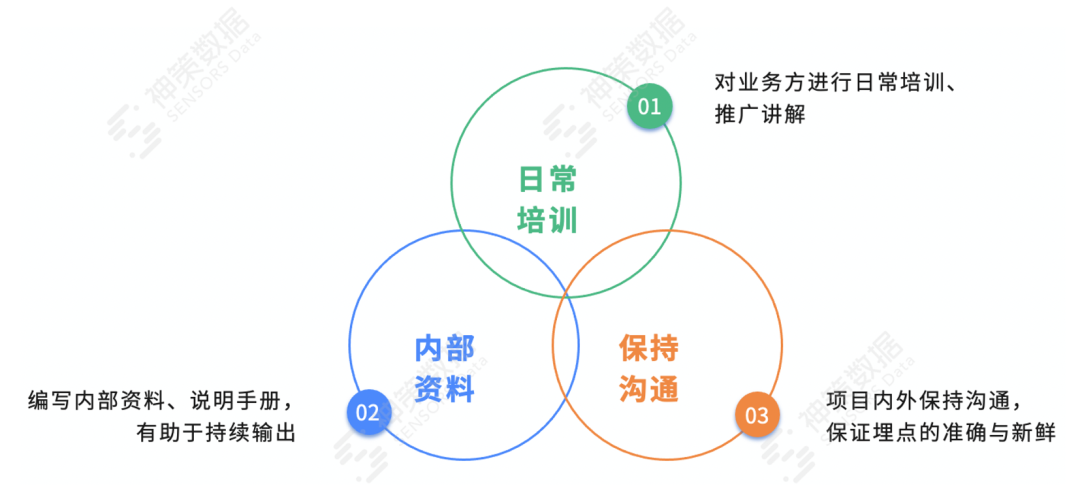
三、如何落實應用?

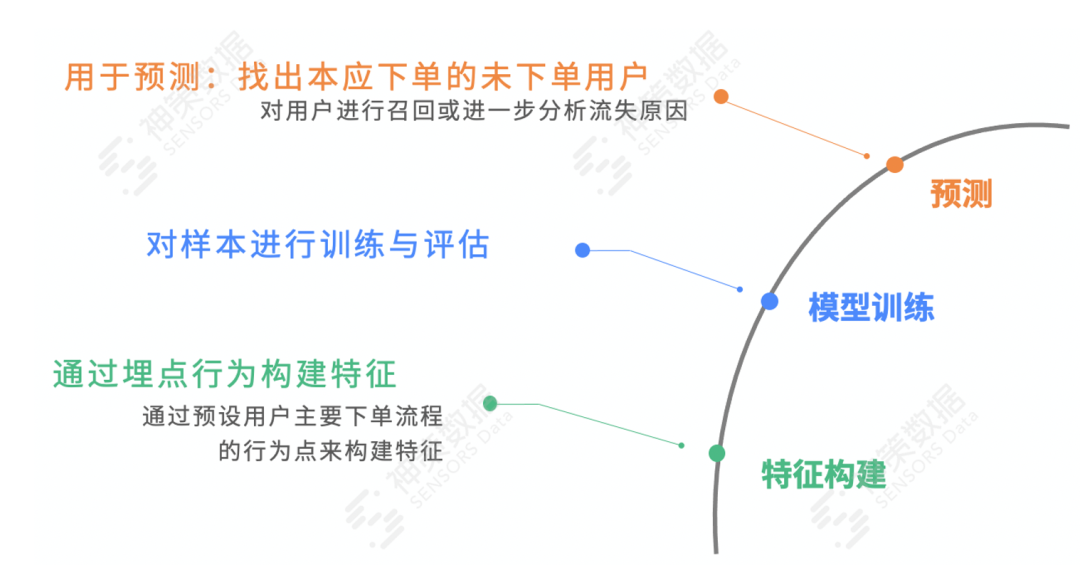
四、數(shù)據(jù)埋點實操案例

評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP
埋點體系迭代指南
體系落地指南
數(shù)據(jù)埋點實操案例
<b id="afajh"><abbr id="afajh"></abbr></b>