
圖神經(jīng)網(wǎng)絡(luò)上的預(yù)訓(xùn)練模型,思考與總結(jié)



點(diǎn)擊上方 藍(lán)字關(guān)注我們
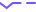
本文轉(zhuǎn)自人工智能前沿講習(xí)@微信公眾號
作者:知乎—荷戟彷徨
地址:https://www.zhihu.com/people/li-xun-huan-47-95
目前,transformer在NLP和CV領(lǐng)域流行已經(jīng)是一個不爭的事實(shí)了。在這樣的一個既定事實(shí)之上,基于pretrain+fine-tuning的思路去進(jìn)行工業(yè)化應(yīng)用也似乎達(dá)成了一種共識。但是,GNN GNN 領(lǐng)域似乎倒還停留在設(shè)計(jì)更好的圖卷積結(jié)構(gòu)這一層面上。于是,便也漸漸有一些論文開始聚焦于如何將transformer在NLP和CV領(lǐng)域的成功移植在graph上,并憑借于此衍生出一些或?qū)a(chǎn)生一定意義的論文。本文便是對這一類論文的一個淺顯的總結(jié)。

01在圖上做預(yù)訓(xùn)練模型同傳統(tǒng)的transformer有什么區(qū)別
在進(jìn)行對論文的梳理之前,應(yīng)當(dāng)先思索一個問題:在圖上做預(yù)訓(xùn)練模型,和常見的基于自然語言文本去做,二者之間有什么區(qū)別呢?
這里面其實(shí)有很大的區(qū)別,我所想到的有:
1.1 處理的對象(輸入)在結(jié)構(gòu)形態(tài)上不同
對于NLP中的一個Seqence,當(dāng)我們限定了它的最大長度之后,便可以使用一個矩陣將該seqence的全部信息進(jìn)行表達(dá)。但是,對于一個圖,這個圖本身就需要兩個矩陣(節(jié)點(diǎn)特征構(gòu)成的矩陣(特征矩陣)與表示節(jié)點(diǎn)間連接關(guān)系的矩陣(鄰接矩陣))。
同時,圖存在的問題是,這樣的兩個矩陣是不定長的,也就是說,這兩個矩陣的大小會隨著圖的變化而變化,而對于Seqence,由于限定了一個maxlength,一個模型可以應(yīng)付所有不定長的seq。
那么,針對于這個問題,是不是我們也為節(jié)點(diǎn)個數(shù)限定一個maxnum,問題就迎刃而解了呢?
或許是這樣的!也或許不是。seqence具有一種天生的順序性,甚至在transformer中還研究了【此處需要貼一個網(wǎng)頁鏈接】各種各樣的position encoding方式來使得模型的效果更好。但是,想象有一堆節(jié)點(diǎn)大小不同的圖,如何對每一張圖中的所有節(jié)點(diǎn)去構(gòu)筑順序,這其實(shí)是一個很棘手的問題。大概率情況下,訓(xùn)練得到的模型最好應(yīng)當(dāng)是不需要這種順序性的(是嗎?)。
1.2 任務(wù)不同
當(dāng)然,粗略的看,NLP的兩大任務(wù)和graph上的任務(wù)有一些共通之處,但是Graph上的任務(wù)花樣還是要多一點(diǎn)的。雖然這兩種東西的任務(wù)最終都是可以通過模型輸出的embedding做一點(diǎn)變化得到。
在NLP里,主要就是NLU和NLG兩大任務(wù)。NLG先按下不表【此處放置一個鏈接】,NLU則是圍繞著seqence或token兩個級別進(jìn)行的。常見的NLU任務(wù)多以seqence為代表,比如兩個句子是否是一個意思,從諸多選項(xiàng)里選出一個答案等等。token級別的任務(wù)主要是對seqence的每一個原子進(jìn)行分類,比如判斷一些詞的詞性、實(shí)體識別等。
在Graph中,由于多了一種信息維度,所以任務(wù)可以劃分為三個層次:節(jié)點(diǎn),邊,圖。
圖上的任務(wù)多是理解性的,也就是判斷該圖屬于什么類型。節(jié)點(diǎn)層面的就有點(diǎn)類似于token級別的操作了,而邊的預(yù)測更為復(fù)雜一點(diǎn),但是也沒有離開理解的范疇。所以,在圖上的任務(wù)基本上都是理解性質(zhì)(也就是預(yù)測、分類這種)的,生成性質(zhì)的工作似乎不是那么惹眼。此處所說的“生成”不是生成一個兩個節(jié)點(diǎn),而是生成一張圖。這當(dāng)然或許是因?yàn)閳D太復(fù)雜了,或者沒有這類需求?
從二者的共通之處出發(fā),就可以察覺到,將transformer移植到graph上是有前途的。但是圖本身所依賴的信息同樣十分有特色。所以一些pretrian模型不約而同地依據(jù)圖上需要把握的信息的特點(diǎn)設(shè)定了適應(yīng)于圖上的預(yù)訓(xùn)練任務(wù)中。
1.3 最后一個問題:在圖上做預(yù)訓(xùn)練模型,主要改進(jìn)點(diǎn)在哪里?
依照目前的論文來看,主要包括兩部分:
1. 模型架構(gòu)上。也就是說,使用一種固定的預(yù)訓(xùn)練GNN結(jié)構(gòu)去處理一類的圖。這一部分的工作比較符合NLP里對transformer的改進(jìn)。
2. 訓(xùn)練任務(wù)上。模型的結(jié)構(gòu)仍然是GNN(一般適用于目前常用的所有GNN聚合算法),但是卻使用了一些無監(jiān)督的學(xué)習(xí)任務(wù)去預(yù)先對GNN進(jìn)行訓(xùn)練,之后再進(jìn)行有監(jiān)督的訓(xùn)練。這一類工作的創(chuàng)新便是訓(xùn)練任務(wù)。
下面的工作將覆蓋上述兩種類型。
02相關(guān)工作
上面啰嗦了好多廢話,竟然還沒有開始談?wù)撐模?/p>
2.1 GPT-GNN 生成式GNN模型
Hu, Ziniu, et al. "Gpt-gnn: Generative pre-training of graph neural networks." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
GPT名聲在外,以至于大家忘了這是一個通用的縮寫:Generative Pre-Training,也就是生成式預(yù)訓(xùn)練。所以,這篇工作的亮點(diǎn)不必多說,肯定就是借用類似于GPT的訓(xùn)練思路去訓(xùn)練GNN模型了。
我們先看看論文中講的故事:首先,這篇論文處理的對象是一種規(guī)模特別大的圖(節(jié)點(diǎn)規(guī)模在10^8,邊的規(guī)模在10^9),如Open Academic Graph(學(xué)術(shù)引用), Amazon Review Recommendation data等。在這么一類的圖中,由于一張圖本身的規(guī)模特別大,所以其實(shí)圖的數(shù)量就很少——只有一個。并且,在這么一張圖中,絕大多數(shù)的節(jié)點(diǎn)都是沒有標(biāo)簽的,只有少量的節(jié)點(diǎn)有標(biāo)簽。
下圖展示了這樣一種預(yù)訓(xùn)練模型的用途——相當(dāng)于一種上游的預(yù)訓(xùn)練,以獲得一個相對而言更好的起始模型結(jié)果。
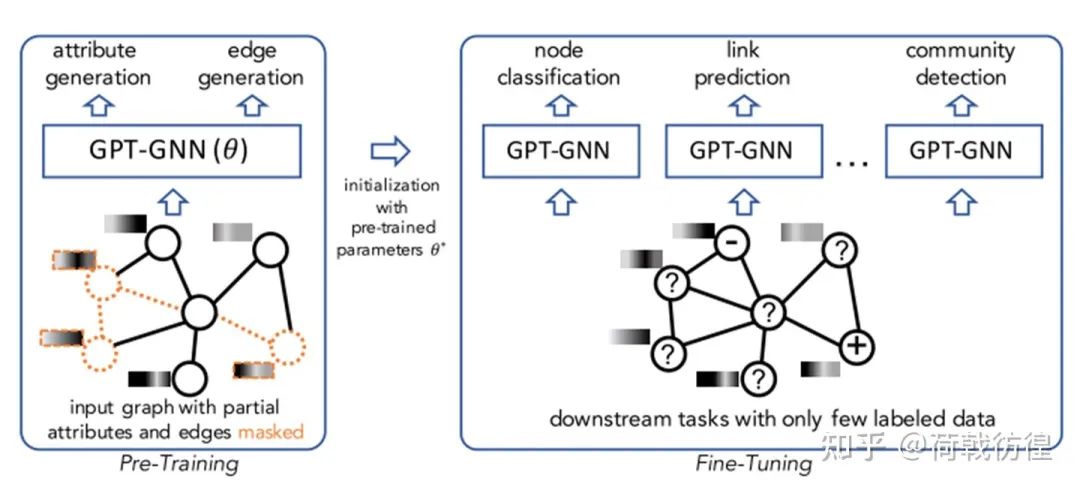
對于這樣的一個問題,其實(shí)早有一些無監(jiān)督的GNN算法可以完成這類任務(wù),比如GAE(Graph Auto-Encoder),Graph SAGE,Graph Infomax等等。但是,這篇論文找到了新的噱頭,它使用類比于GPT的方法重新做了一遍。下面的公式是這篇論文的核心思路。可以看出,這個公式和auto-regressive的形式是相當(dāng)類似的,只不過預(yù)測的變量變多了。
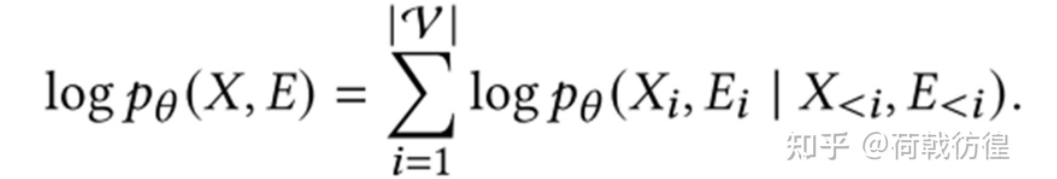
下面詳細(xì)介紹其過程。圖片看不太清楚,現(xiàn)列舉文字過程:
1. 對圖中的節(jié)點(diǎn)排好順序(這樣就形成了類似于文本的seqence);
2. 對于每一個輸入節(jié)點(diǎn), 預(yù)測它的attribute向量,預(yù)測它和前面所有的邊的連接關(guān)系。需要注意的是,此處的attribute向量是指節(jié)點(diǎn)在一開始所保有的向量。比如,在一個論文引用網(wǎng)絡(luò)里,每篇論文的題目、作者、年份、等等東西所形成的結(jié)果。
3. 將預(yù)測值和真實(shí)值放入損失函數(shù),反向傳播。
這樣一個過程應(yīng)當(dāng)如何實(shí)現(xiàn)呢?
一種類似于樸素貝葉斯的想法是,假設(shè)邊的預(yù)測和節(jié)點(diǎn)的預(yù)測是彼此獨(dú)立的。這樣,下面的公式
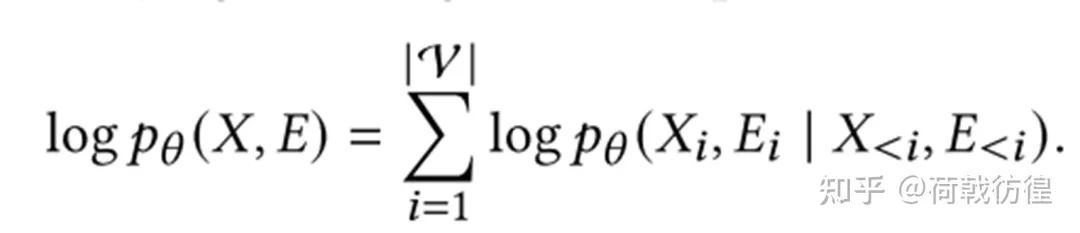
就變成了下面的公式
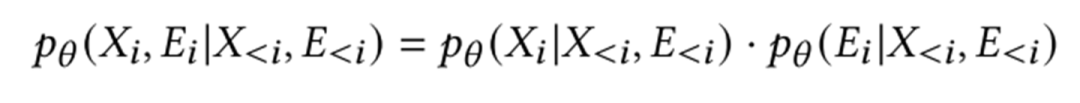
但是,這樣的做法肯定是不好的,因?yàn)樵趫D里,連接關(guān)系非常重要。因此,論文里對之進(jìn)行了折衷:能否暴露一部分連接關(guān)系,然后去推斷其他的連接關(guān)系,最終給出屬性的預(yù)測。
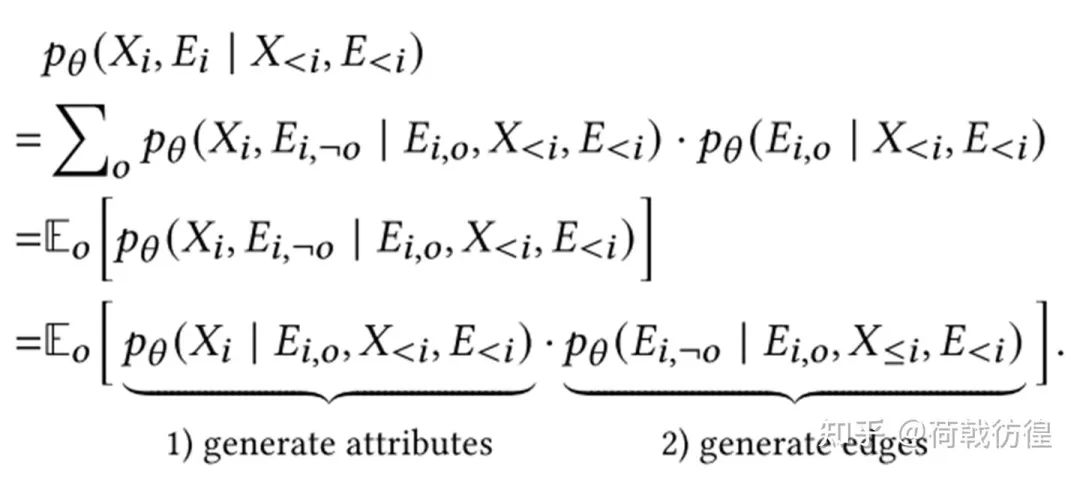
上面的公式大約是用全概率公式、概率密度的數(shù)學(xué)期望推出來的。
具體的實(shí)現(xiàn)上是這個樣子的:使用某一種GNN(如GAT)作為encoder,選擇一種合適的decoder(如MLP),然后基于下列的損失函數(shù)進(jìn)行訓(xùn)練。訓(xùn)練完成后,Decoder舍棄,GNN就訓(xùn)練完成了。
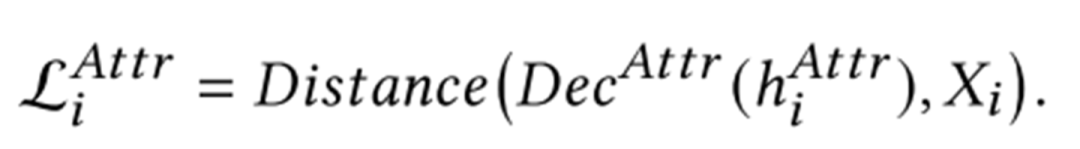
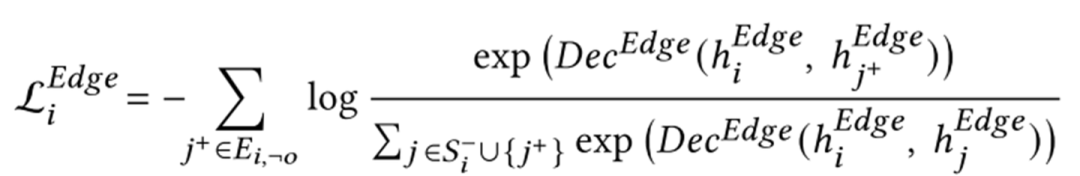
最后關(guān)心一下實(shí)驗(yàn)。下表展示了加入這種預(yù)訓(xùn)練任務(wù)前后的效果提升。
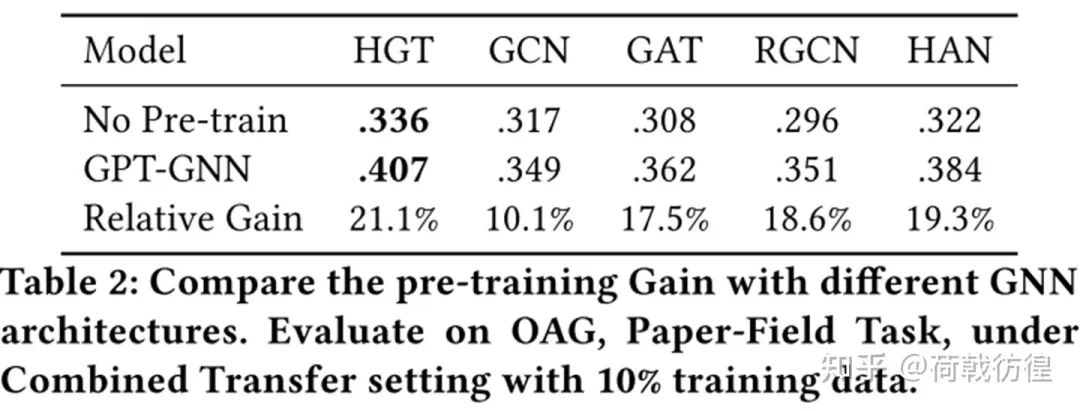
當(dāng)然,這是在訓(xùn)練數(shù)據(jù)很少的前提之下。
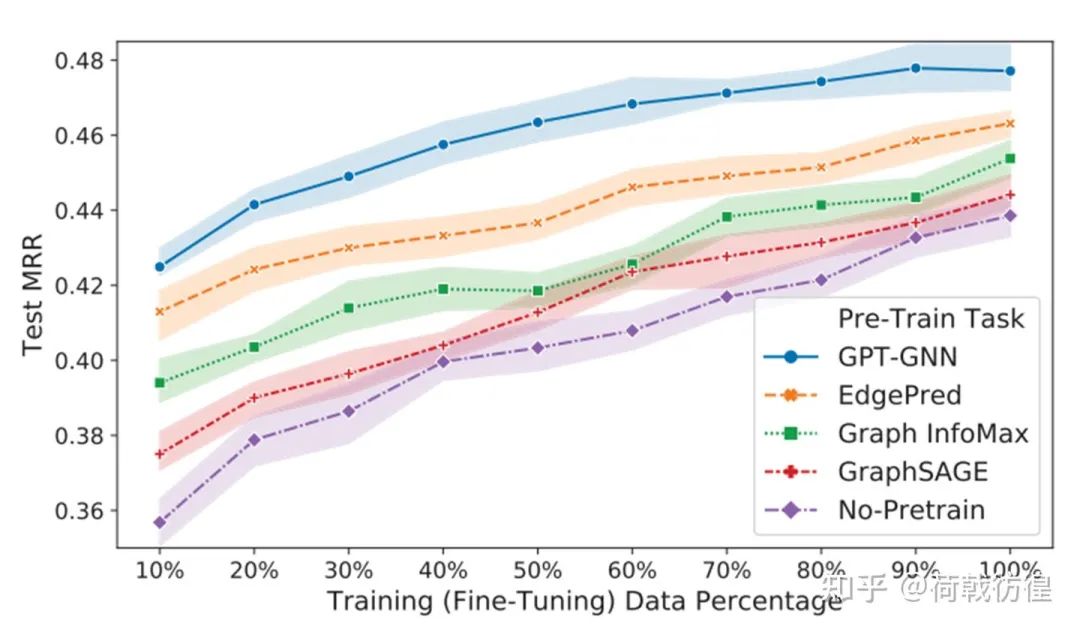
上圖展示了相對于其他的一些無監(jiān)督學(xué)習(xí)方法,GPT-GNN的效果。
2.2 基于對圖的理解來設(shè)計(jì)任務(wù)
Hu, Weihua, et al. "Strategies for Pre-training Graph Neural Networks." arXiv preprint arXiv:1905.12265 (2019). ICLR 2020 Stanford University
在進(jìn)行后續(xù)的介紹之前,不得不澄清一下,此處的圖已經(jīng)不再是上篇論文中所看到的“一場大圖”了,而變成了一些相對而言比較小的圖,如化學(xué)分子式等。與之帶來的轉(zhuǎn)變就是,圖的數(shù)量也開始增多,因此,一些對圖的理解也變成了任務(wù)之一。
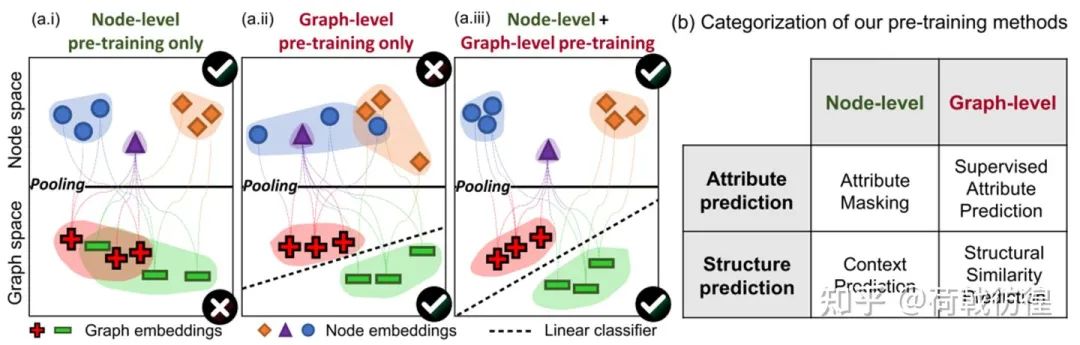
這篇論文所側(cè)重的也是預(yù)訓(xùn)練任務(wù)的設(shè)計(jì)。其講故事的思路是這個樣子的:對于圖上的任務(wù),主要包括節(jié)點(diǎn)層面和圖層面兩種。而這兩種任務(wù)恰恰在訓(xùn)練上容易造成一方很好另一方很差的情形。比如說,在上圖左示例的樣子,當(dāng)只使用節(jié)點(diǎn)層面的預(yù)訓(xùn)練方法的時候,在圖空間上的表示就不是很好;而在僅僅使用圖層面的預(yù)訓(xùn)練任務(wù)時,節(jié)點(diǎn)層面的表示也不會很好。最好的方法是,同時進(jìn)行兩個層面的訓(xùn)練。
本著上述原則,作者對預(yù)訓(xùn)練方法進(jìn)行了分類。從層面上來看,自然就是包括之前所說的節(jié)點(diǎn)層面和圖層面。論文中主要包括了四個任務(wù)。但是,可以看出來,圖層面的兩個任務(wù)應(yīng)該都是有監(jiān)督的。因此,論文里著重筆墨的是節(jié)點(diǎn)層面的兩個任務(wù)(好哇!繞了一圈,工作還是只在節(jié)點(diǎn)層面!)。下面依次介紹之。
1. Attribute Masking。這個任務(wù)顯然是依照BERT等模型的masking想出來的。
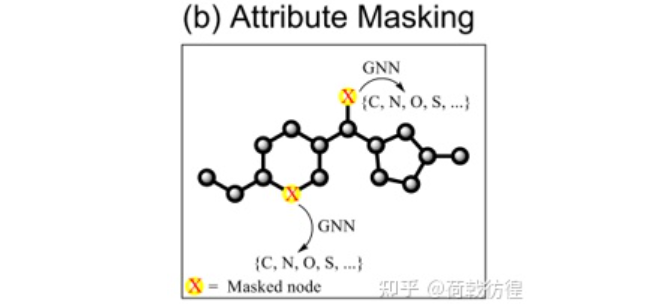
如上圖所示,在一個化學(xué)分子式里隨機(jī)遮擋住若干個原子,然后讓GNN去猜被遮擋住的原子是什么,以此來構(gòu)成自監(jiān)督學(xué)習(xí)任務(wù)。
2. context prediction。這個在歸類時被歸為了structure prediction。其基本做法是這樣的:選取指定節(jié)點(diǎn)的k階鄰居節(jié)點(diǎn),并依照他們生成一些圖結(jié)構(gòu),這些圖結(jié)構(gòu)的表示同GNN提取的中心節(jié)點(diǎn)的表示被要求盡可能的相似,也就是:
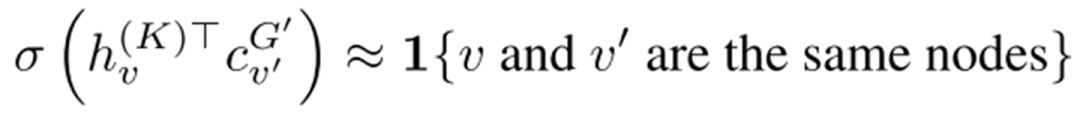
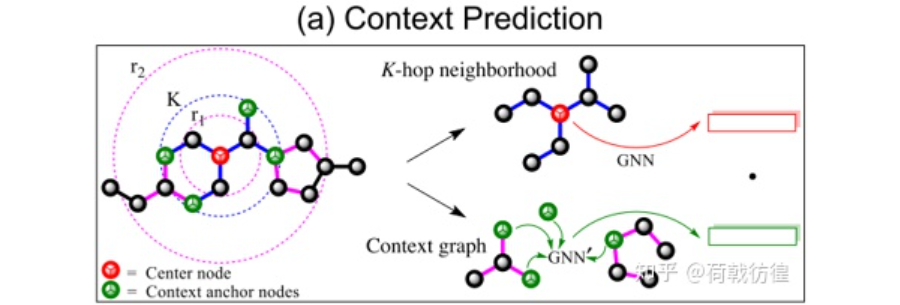
作者同樣給出了是否使用這類預(yù)訓(xùn)練方式時,產(chǎn)生的增益可以有多少:

總結(jié)一下上述兩篇論文的工作,可以發(fā)現(xiàn):他們都是設(shè)計(jì)了一些新的訓(xùn)練任務(wù),而非提出了一種新的GNN模型。那么,有沒有一些工作是從模型結(jié)構(gòu)上去做改進(jìn)的呢?下面以一篇論文作此代表。
2.3 Graph Transformer
Rong, Yu, et al. "Self-Supervised Graph Transformer on Large-Scale Molecular Data." Advances in Neural Information Processing Systems 33 (2020). THU, Tencent AI.
這篇論文的工作對象同樣也是化學(xué)分子相關(guān)的圖。對于這樣的圖,論文沒有再去使用GNN做處理,而是直接上了transformer。是的,就是直接上了transformer。
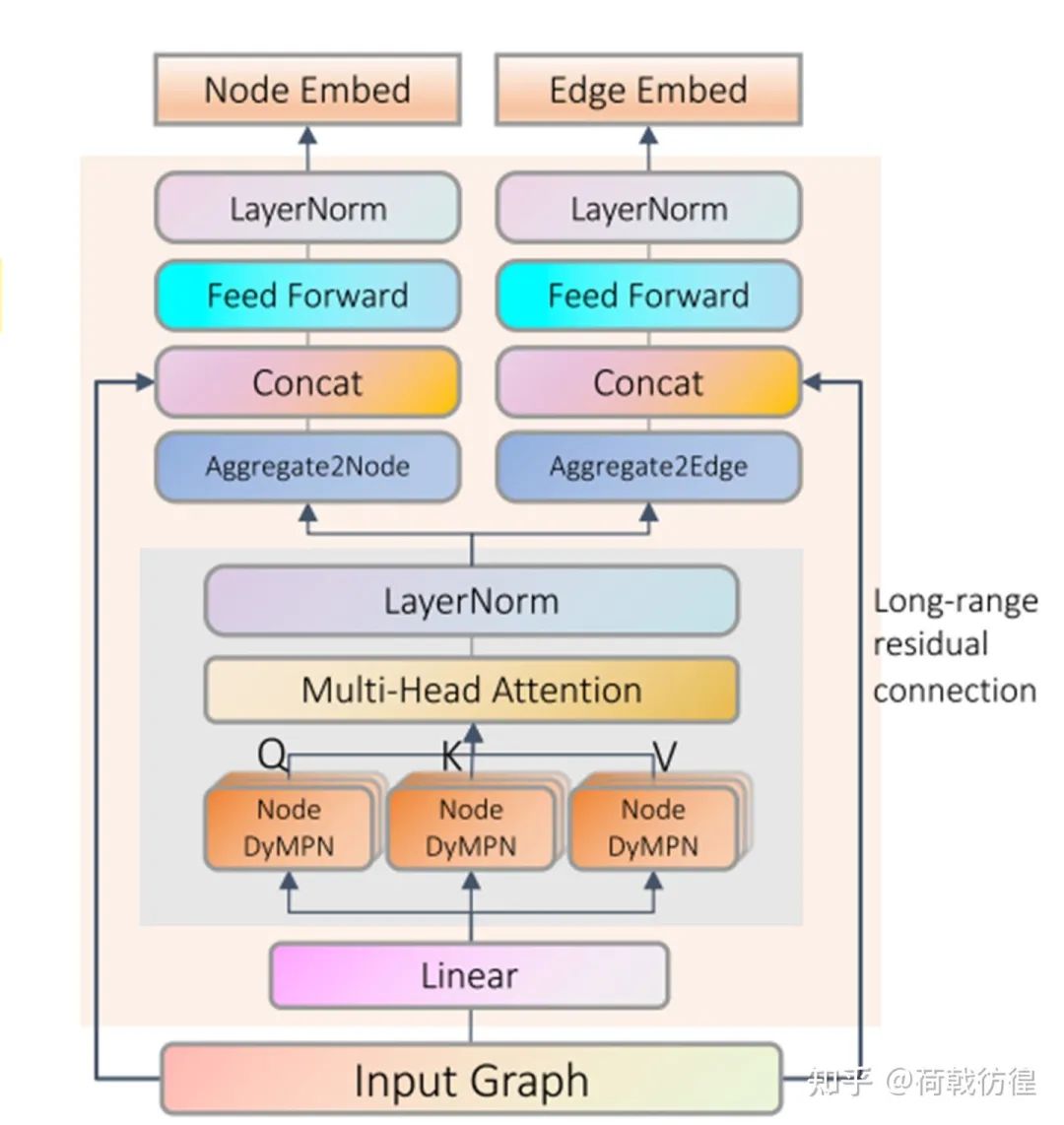
如上圖所示,把一張圖變成一個序列(具體的變動方法其實(shí)在GPT-GNN里已經(jīng)講過)之后,就可以進(jìn)行類似于transformer layer的處理了。當(dāng)然,作者還是做了一些微調(diào)。主要包括:
1. 生成QKV的方式。在transformer里,此處直接使用了一個線性映射。而在此處,則增加了一個聚合的過程:
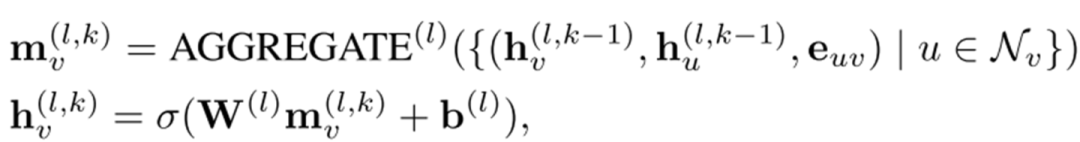
2. long-range residual connection。據(jù)說是為了解決over smoothing問題,這……
無論如何,這樣的一個模型總歸是完成了對transformer的最基本的處理了。那么,如何對之進(jìn)行任務(wù)的設(shè)計(jì)呢?
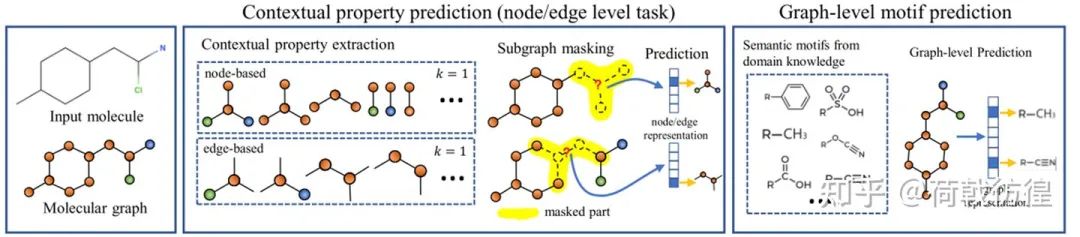
此處的任務(wù)設(shè)計(jì)主要包括兩個,都更多的體現(xiàn)在結(jié)構(gòu)性上。下面分別對之進(jìn)行簡單介紹。
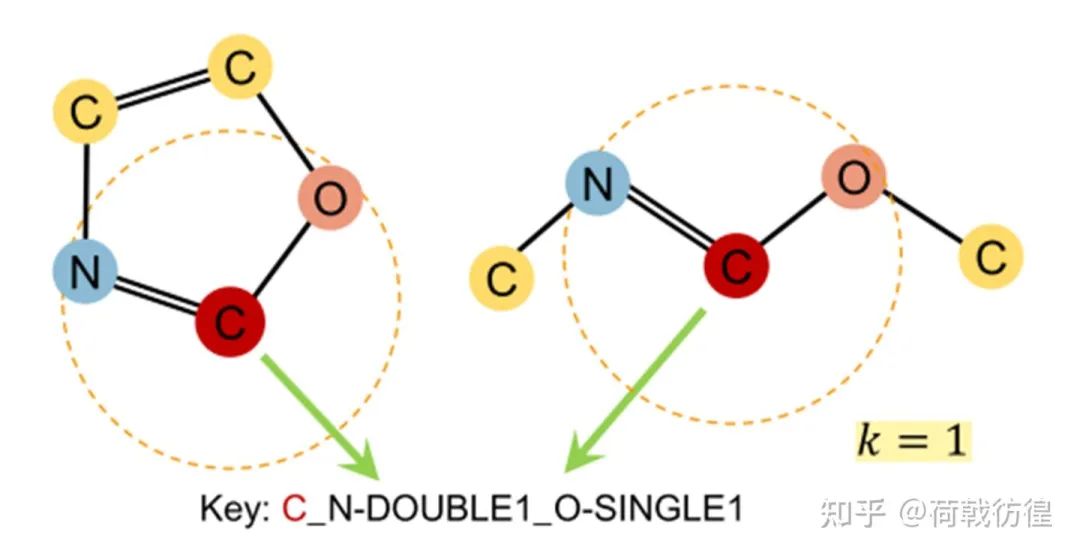
1. contextual Property Prediction。這個和上一篇論文中的結(jié)構(gòu)預(yù)測很相似,但是預(yù)測的題目從一個類似于回歸的問題變成了分類問題。如上圖所示,對于我們的目標(biāo)節(jié)點(diǎn)C,我們要預(yù)測他的contextual property,就是說,預(yù)測出來它和其它的節(jié)點(diǎn)以哪些方式連接,連接了幾個。比如圖中所示,就是1個2鍵的N和一個1鍵的O。
2. graph level motif prediction。這個是圖層次上的任務(wù),這個任務(wù)要做的事是預(yù)測一個圖里有哪些基本的化學(xué)分子式構(gòu)成單元。相當(dāng)于是一個多標(biāo)簽分類任務(wù)。可以發(fā)現(xiàn),這個任務(wù)明顯是有監(jiān)督的,但是,論文中說存在一些軟件可以自動地檢測得到所需要的表情,于是乎這個任務(wù)就變成無監(jiān)督的了。
相關(guān)實(shí)驗(yàn)就不貼了。。
03 其他的一些參考論文
Pre-training GNN, ICLR'20
Gcc, KDD'20
DeepWalk(KDD14),
LINE(KDD15),
Node2Vec(KDD16)
