
PyTorch常見(jiàn)的12坑

向AI轉(zhuǎn)型的程序員都關(guān)注了這個(gè)號(hào)???
機(jī)器學(xué)習(xí)AI算法工程?? 公眾號(hào):datayx
1. nn.Module.cuda() 和 Tensor.cuda() 的作用效果差異
無(wú)論是對(duì)于模型還是數(shù)據(jù),cuda()函數(shù)都能實(shí)現(xiàn)從CPU到GPU的內(nèi)存遷移,但是他們的作用效果有所不同。
對(duì)于nn.Module:

上面兩句能夠達(dá)到一樣的效果,即對(duì)model自身進(jìn)行的內(nèi)存遷移。
對(duì)于Tensor:
和nn.Module不同,調(diào)用tensor.cuda()只是返回這個(gè)tensor對(duì)象在GPU內(nèi)存上的拷貝,而不會(huì)對(duì)自身進(jìn)行改變。因此必須對(duì)tensor進(jìn)行重新賦值,即tensor=tensor.cuda().
例子:

2. PyTorch 0.4 計(jì)算累積損失的不同
以廣泛使用的模式total_loss += loss.data[0]為例。Python0.4.0之前,loss是一個(gè)封裝了(1,)張量的Variable,但Python0.4.0的loss現(xiàn)在是一個(gè)零維的標(biāo)量。對(duì)標(biāo)量進(jìn)行索引是沒(méi)有意義的(似乎會(huì)報(bào) invalid index to scalar variable 的錯(cuò)誤)。使用loss.item()可以從標(biāo)量中獲取Python數(shù)字。所以改為:

如果在累加損失時(shí)未將其轉(zhuǎn)換為Python數(shù)字,則可能出現(xiàn)程序內(nèi)存使用量增加的情況。這是因?yàn)樯厦姹磉_(dá)式的右側(cè)原本是一個(gè)Python浮點(diǎn)數(shù),而它現(xiàn)在是一個(gè)零維張量。因此,總損失累加了張量和它們的梯度歷史,這可能會(huì)產(chǎn)生很大的autograd 圖,耗費(fèi)內(nèi)存和計(jì)算資源。
?
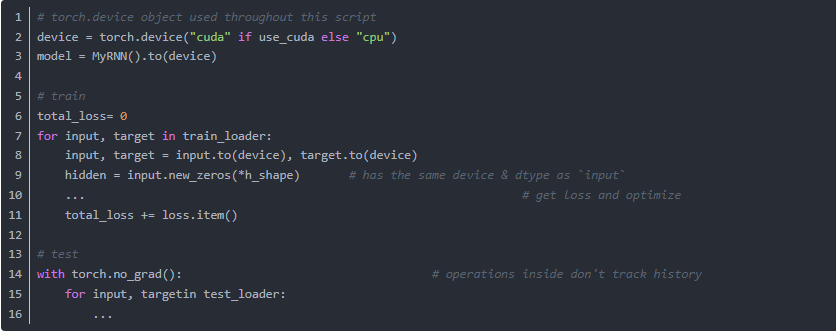
3. PyTorch 0.4 編寫(xiě)不限制設(shè)備的代碼
4.?torch.Tensor.detach()的使用
detach()的官方說(shuō)明如下:

假設(shè)有模型A和模型B,我們需要將A的輸出作為B的輸入,但訓(xùn)練時(shí)我們只訓(xùn)練模型B. 那么可以這樣做:
input_B = output_A.detach()
它可以使兩個(gè)計(jì)算圖的梯度傳遞斷開(kāi),從而實(shí)現(xiàn)我們所需的功能。
?
5. ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)
出現(xiàn)這個(gè)錯(cuò)誤的情況是,在服務(wù)器上的docker中運(yùn)行訓(xùn)練代碼時(shí),batch size設(shè)置得過(guò)大,shared memory不夠(因?yàn)閐ocker限制了shm).解決方法是,將Dataloader的num_workers設(shè)置為0.
?
6. pytorch中l(wèi)oss函數(shù)的參數(shù)設(shè)置
以CrossEntropyLoss為例:

若?reduce?= False,那么 size_average 參數(shù)失效,直接返回向量形式的 loss,即batch中每個(gè)元素對(duì)應(yīng)的loss.
若?reduce?= True,那么 loss 返回的是標(biāo)量:
如果?size_average?= True,返回 loss.mean().
如果?size_average?= False,返回 loss.sum().
weight?: 輸入一個(gè)1D的權(quán)值向量,為各個(gè)類(lèi)別的loss加權(quán),如下公式所示:
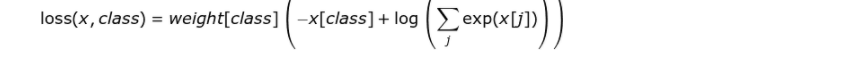
ignore_index?: 選擇要忽視的目標(biāo)值,使其對(duì)輸入梯度不作貢獻(xiàn)。如果 size_average = True,那么只計(jì)算不被忽視的目標(biāo)的loss的均值。
reduction?: 可選的參數(shù)有:‘none’ | ‘elementwise_mean’ | ‘sum’, 正如參數(shù)的字面意思,不解釋。
7. pytorch的可重復(fù)性問(wèn)題
參考這篇博文:https://blog.csdn.net/hyk_1996/article/details/84307108
?
8. 多GPU的處理機(jī)制
使用多GPU時(shí),應(yīng)該記住pytorch的處理邏輯是:
1.在各個(gè)GPU上初始化模型。
2.前向傳播時(shí),把batch分配到各個(gè)GPU上進(jìn)行計(jì)算。
3.得到的輸出在主GPU上進(jìn)行匯總,計(jì)算loss并反向傳播,更新主GPU上的權(quán)值。
4.把主GPU上的模型復(fù)制到其它GPU上。
?
9. num_batches_tracked參數(shù)
今天讀取模型參數(shù)時(shí)出現(xiàn)了錯(cuò)誤
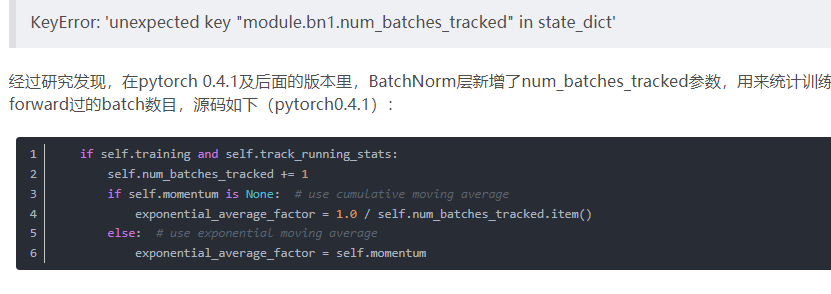
大概可以看出,這個(gè)參數(shù)和訓(xùn)練時(shí)的歸一化的計(jì)算方式有關(guān)。
因此,我們可以知道該錯(cuò)誤是由于訓(xùn)練和測(cè)試所用的pytorch版本(0.4.1版本前后的差異)不一致引起的。具體的解決方案是:如果是模型參數(shù)(Orderdict格式,很容易修改)里少了num_batches_tracked變量,就加上去,如果是多了就刪掉。偷懶的做法是將load_state_dict的strict參數(shù)置為False,如下所示:

還看到有人直接修改pytorch 0.4.1的源代碼把num_batches_tracked參數(shù)刪掉的,這就非常不建議了。
?
10. 訓(xùn)練時(shí)損失出現(xiàn)nan的問(wèn)題
最近在訓(xùn)練模型時(shí)出現(xiàn)了損失為nan的情況,發(fā)現(xiàn)是個(gè)大坑。暫時(shí)先記錄著。
可能導(dǎo)致梯度出現(xiàn)nan的三個(gè)原因:
1.梯度爆炸。也就是說(shuō)梯度數(shù)值超出范圍變成nan. 通常可以調(diào)小學(xué)習(xí)率、加BN層或者做梯度裁剪來(lái)試試看有沒(méi)有解決。
2.損失函數(shù)或者網(wǎng)絡(luò)設(shè)計(jì)。比方說(shuō),出現(xiàn)了除0,或者出現(xiàn)一些邊界情況導(dǎo)致函數(shù)不可導(dǎo),比方說(shuō)log(0)、sqrt(0).
3.臟數(shù)據(jù)。可以事先對(duì)輸入數(shù)據(jù)進(jìn)行判斷看看是否存在nan.
補(bǔ)充一下nan數(shù)據(jù)的判斷方法:
注意!像nan或者inf這樣的數(shù)值不能使用?== 或者 is 來(lái)判斷!為了安全起見(jiàn)統(tǒng)一使用 math.isnan() 或者 numpy.isnan() 吧。
例如:
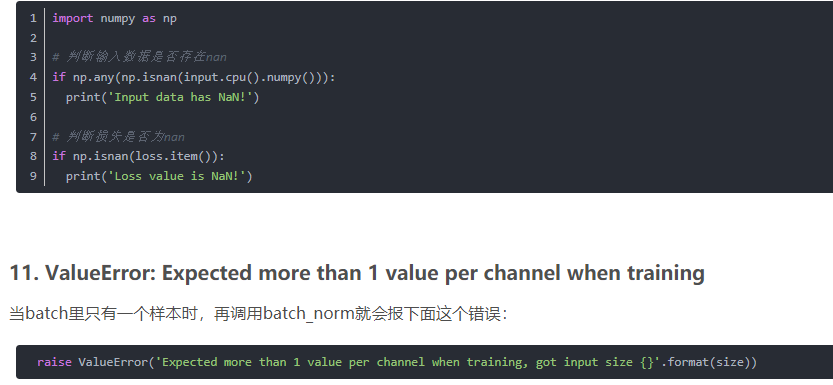
raise ValueError('Expected more than 1 value per channel when training, got input size {}'.format(size))
沒(méi)有什么特別好的解決辦法,在訓(xùn)練前用 num_of_samples % batch_size 算一下會(huì)不會(huì)正好剩下一個(gè)樣本。
可以考慮將`DataLoader`的`drop_last`選項(xiàng)設(shè)為T(mén)rue,這樣的話,當(dāng)最后一個(gè)batch湊不滿時(shí),就會(huì)舍棄掉。
?
12. 優(yōu)化器的weight_decay項(xiàng)導(dǎo)致的隱蔽bug
我們都知道weight_decay指的是權(quán)值衰減,即在原損失的基礎(chǔ)上加上一個(gè)L2懲罰項(xiàng),使得模型趨向于選擇更小的權(quán)重參數(shù),起到正則化的效果。但是我經(jīng)常會(huì)忽略掉這一項(xiàng)的存在,從而引發(fā)了意想不到的問(wèn)題。
這次的坑是這樣的,在訓(xùn)練一個(gè)ResNet50的時(shí)候,網(wǎng)絡(luò)的高層部分layer4暫時(shí)沒(méi)有用到,因此也并不會(huì)有梯度回傳,于是我就放心地將ResNet50的所有參數(shù)都傳遞給Optimizer進(jìn)行更新了,想著layer4應(yīng)該能保持原來(lái)的權(quán)重不變才對(duì)。但是實(shí)際上,盡管layer4沒(méi)有梯度回傳,但是weight_decay的作用仍然存在,它使得layer4權(quán)值越來(lái)越小,趨向于0。后面需要用到layer4的時(shí)候,發(fā)現(xiàn)輸出異常(接近于0),才注意到這個(gè)問(wèn)題的存在。
雖然這樣的情況可能不容易遇到,但是還是要謹(jǐn)慎:暫時(shí)不需要更新的權(quán)值,一定不要傳遞給Optimizer,避免不必要的麻煩。
?
13. 優(yōu)化TensorDataset的數(shù)據(jù)加載速度
`TensorDataset`提供了已經(jīng)完全加載到內(nèi)存中的矩陣的數(shù)據(jù)讀取接口。在使用`TensorDataset`的時(shí)候,如果直接用`DataLoader`,會(huì)導(dǎo)致數(shù)據(jù)加載速度非常緩慢,嚴(yán)重拖慢訓(xùn)練速度,分析和解決方案詳見(jiàn)https://huangbiubiu.github.io/2019/BEST-PRACTICE-PyTorch-TensorDataset/
原文地址?https://blog.csdn.net/hyk_1996/article/details/80824747
閱讀過(guò)本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實(shí)戰(zhàn)
基于40萬(wàn)表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測(cè)
《基于深度學(xué)習(xí)的自然語(yǔ)言處理》中/英PDF
Deep Learning 中文版初版-周志華團(tuán)隊(duì)
【全套視頻課】最全的目標(biāo)檢測(cè)算法系列講解,通俗易懂!
《美團(tuán)機(jī)器學(xué)習(xí)實(shí)踐》_美團(tuán)算法團(tuán)隊(duì).pdf
《深度學(xué)習(xí)入門(mén):基于Python的理論與實(shí)現(xiàn)》高清中文PDF+源碼
python就業(yè)班學(xué)習(xí)視頻,從入門(mén)到實(shí)戰(zhàn)項(xiàng)目
2019最新《PyTorch自然語(yǔ)言處理》英、中文版PDF+源碼
《21個(gè)項(xiàng)目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實(shí)踐詳解》完整版PDF+附書(shū)代碼
《深度學(xué)習(xí)之pytorch》pdf+附書(shū)源碼
PyTorch深度學(xué)習(xí)快速實(shí)戰(zhàn)入門(mén)《pytorch-handbook》
【下載】豆瓣評(píng)分8.1,《機(jī)器學(xué)習(xí)實(shí)戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車(chē)行業(yè)完整知識(shí)圖譜項(xiàng)目實(shí)戰(zhàn)視頻(全23課)
李沐大神開(kāi)源《動(dòng)手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計(jì)學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
將機(jī)器學(xué)習(xí)模型部署為REST API
FashionAI服裝屬性標(biāo)簽圖像識(shí)別Top1-5方案分享
重要開(kāi)源!CNN-RNN-CTC 實(shí)現(xiàn)手寫(xiě)漢字識(shí)別
同樣是機(jī)器學(xué)習(xí)算法工程師,你的面試為什么過(guò)不了?
前海征信大數(shù)據(jù)算法:風(fēng)險(xiǎn)概率預(yù)測(cè)
【Keras】完整實(shí)現(xiàn)‘交通標(biāo)志’分類(lèi)、‘票據(jù)’分類(lèi)兩個(gè)項(xiàng)目,讓你掌握深度學(xué)習(xí)圖像分類(lèi)
VGG16遷移學(xué)習(xí),實(shí)現(xiàn)醫(yī)學(xué)圖像識(shí)別分類(lèi)工程項(xiàng)目
特征工程(二) :文本數(shù)據(jù)的展開(kāi)、過(guò)濾和分塊
如何利用全新的決策樹(shù)集成級(jí)聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
全球AI挑戰(zhàn)-場(chǎng)景分類(lèi)的比賽源碼(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識(shí)別手寫(xiě)中文網(wǎng)站
中科院Kaggle全球文本匹配競(jìng)賽華人第1名團(tuán)隊(duì)-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號(hào)添加:?datayx??
機(jī)大數(shù)據(jù)技術(shù)與機(jī)器學(xué)習(xí)工程
?搜索公眾號(hào)添加:?datanlp
長(zhǎng)按圖片,識(shí)別二維碼