
Python爬蟲實(shí)戰(zhàn) | 利用多線程爬取 LOL 高清壁紙
來(lái)源:公眾號(hào)【杰哥的IT之旅】
作者:阿拉斯加
ID:Jake_Internet
如需獲取本文完整代碼及 LOL 壁紙,請(qǐng)為本文右下角點(diǎn)亮在看并添加杰哥微信:Hc220088 獲取。
一、背景介紹
隨著移動(dòng)端的普及出現(xiàn)了很多的移動(dòng) APP,應(yīng)用軟件也隨之流行起來(lái)。最近看到英雄聯(lián)盟的手游上線了,感覺還行,PC 端英雄聯(lián)盟可謂是爆火的游戲,不知道移動(dòng)端的英雄聯(lián)盟前途如何,那今天我們使用到多線程的方式爬取 LOL 官網(wǎng)英雄高清壁紙。
二、頁(yè)面分析
目標(biāo)網(wǎng)站:
https://lol.qq.com/data/info-heros.shtml#Navi
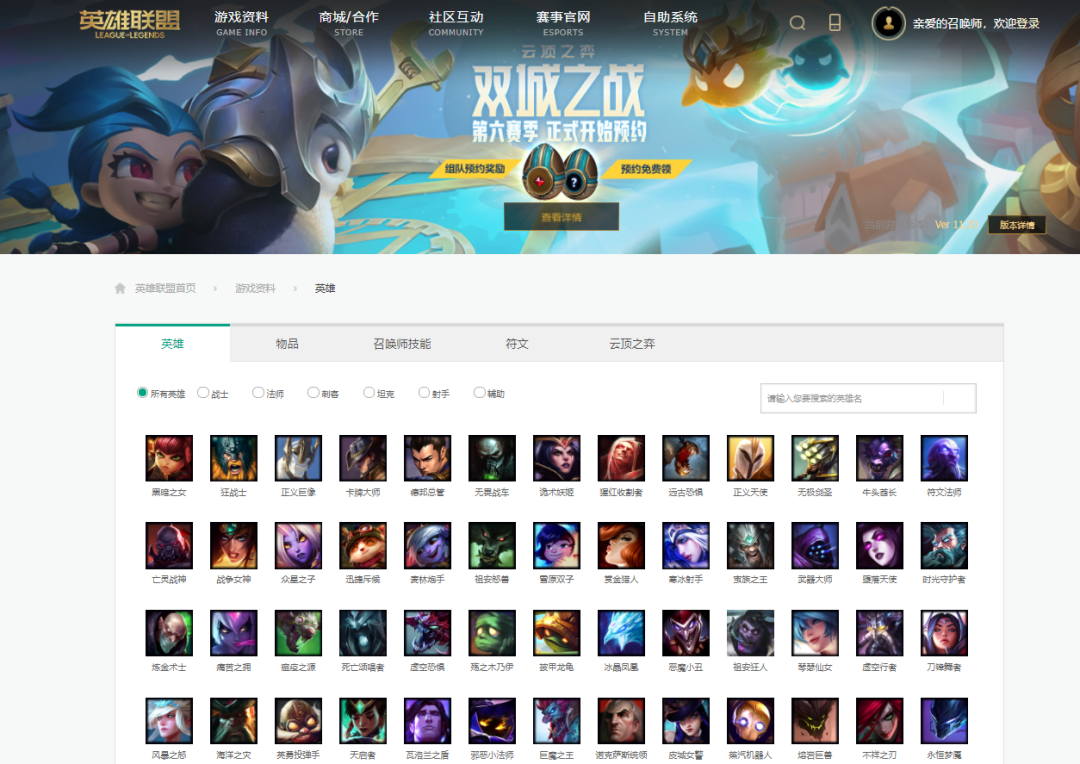
官網(wǎng)界面如圖所示,顯而易見,一個(gè)小圖表示一個(gè)英雄,我們的目的是爬取每一個(gè)英雄的所有皮膚圖片,全部下載下來(lái)并保存到本地。
次級(jí)頁(yè)面
上面的頁(yè)面我們稱為主頁(yè)面,次級(jí)頁(yè)面也就是每一個(gè)英雄對(duì)應(yīng)的頁(yè)面,就以黑暗之女為例,它的次級(jí)頁(yè)面如下所示:
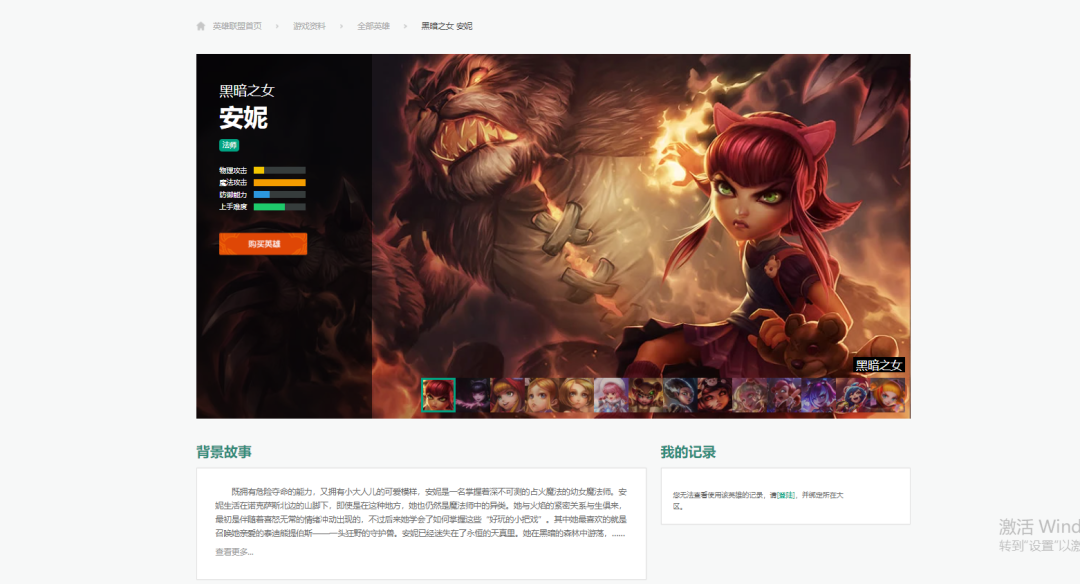
我們可以看到有很多的小圖,每一張小圖對(duì)應(yīng)一個(gè)皮膚,通過 network 查看皮膚數(shù)據(jù)接口,如下圖所示:
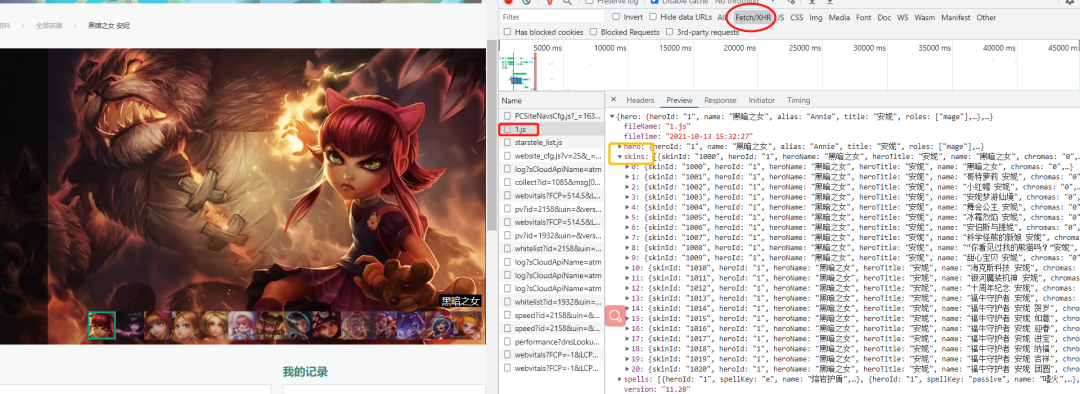
我們知道了皮膚信息是一個(gè) json 格式的字符串進(jìn)行傳輸?shù)模敲次覀冎灰业矫總€(gè)英雄對(duì)應(yīng)的 id,找到對(duì)應(yīng)的 json 文件,提取需要的數(shù)據(jù)就能得到高清皮膚壁紙。
然后這里黑暗之女的 json 的文件地址是:
hero_one?=?'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
這里其實(shí)規(guī)律也非常簡(jiǎn)單,每個(gè)英雄的皮膚數(shù)據(jù)的地址是這樣的:
url?=?'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id)
那么問題來(lái)了 id 的規(guī)律是怎么樣的呢?這里英雄的 id 需要在首頁(yè)查看,如下所示:
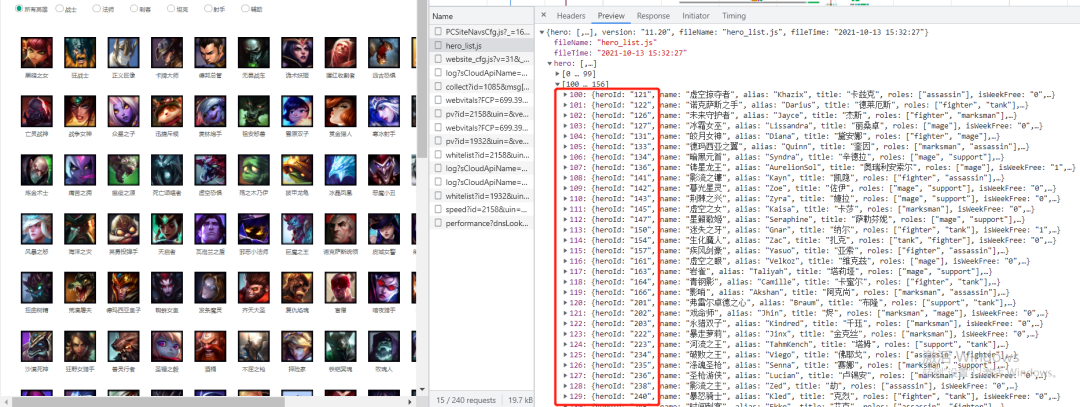
我們可以看到兩個(gè)列表[0,99],[100,156],即 156 個(gè)英雄,但是 heroId 卻一直到了 240….,由此可見,它是有一定的變化規(guī)律的,并不是依次加一,所以要爬取全部英雄皮膚圖片,需要先拿到全部的heroId。
三、抓取思路
為什么使用多線程,這里解釋一下,我們?cè)谂廊D片,視頻這種數(shù)據(jù)的時(shí)候,因?yàn)樾枰4娴奖镜兀詴?huì)使用大量的文件的讀取和寫入操作,也就是 IO 操作,試想一下如果我們進(jìn)行同步請(qǐng)求操作;
那么在第一次請(qǐng)求完成一直到文件保存到本地,才會(huì)進(jìn)行第二次請(qǐng)求,那么這樣效率非常低下,如果使用多線程進(jìn)行異步操作,效率會(huì)大大提升。
所以必然要使用多線程或者是多進(jìn)程,然后把這么多的數(shù)據(jù)隊(duì)列丟給線程池或者進(jìn)程池去處理;
在 Python 中,multiprocessing Pool 進(jìn)程池,multiprocessing.dummy 非常好用。
multiprocessing.dummy模塊:dummy模塊是多線程;multiprocessing模塊:multiprocessing是多進(jìn)程;
multiprocessing.dummy模塊與multiprocessing模塊兩者的 api 都是通用的,代碼的切換使用上比較靈活;
我們首先在一個(gè)測(cè)試的 demo.py 文件抓取英雄 id,這里的代碼我已經(jīng)寫好了,得到一個(gè)儲(chǔ)存英雄 id 的列表,直接在主文件里使用即可;
demo.py
url?=?'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
res?=?requests.get(url,headers=headers)
res?=?res.content.decode('utf-8')
res_dict?=?json.loads(res)
heros?=?res_dict["hero"]?#?156個(gè)hero信息
idList?=?[]
for?hero?in?heros:
????hero_id?=?hero["heroId"]
????idList.append(hero_id)
print(idList)
得到 idList 如下所示:
idlist = [1,2,3,….,875,876,877] # 中間的英雄 id 這里不做展示
構(gòu)建的 url:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
這里的 i 表示 id,進(jìn)行 url 的動(dòng)態(tài)構(gòu)建;
那么我們定制兩個(gè)函數(shù)一個(gè)用于爬取并且解析頁(yè)面(spider),一個(gè)用于下載數(shù)據(jù) ?(download),開啟線程池,使用 for 循環(huán)構(gòu)建存儲(chǔ)英雄皮膚 json 數(shù)據(jù)的 url,儲(chǔ)存在列表中,作為 url 隊(duì)列,使用 pool.map() 方法執(zhí)行 spider (爬蟲)函數(shù);
def?map(self,?fn,?*iterables,?timeout=None,?chunksize=1):
????"""Returns?an?iterator?equivalent?to?map(fn,?iter)”“”
#?這里我們的使用是:pool.map(spider,page)?# spider:爬蟲函數(shù);page:url隊(duì)列
作用:將列表中的每個(gè)元素提取出來(lái)當(dāng)作函數(shù)的參數(shù),創(chuàng)建一個(gè)個(gè)進(jìn)程,放進(jìn)進(jìn)程池中;
參數(shù)1:要執(zhí)行的函數(shù);
參數(shù)2:迭代器,將迭代器中的數(shù)字作為參數(shù)依次傳入函數(shù)中;
json數(shù)據(jù)解析
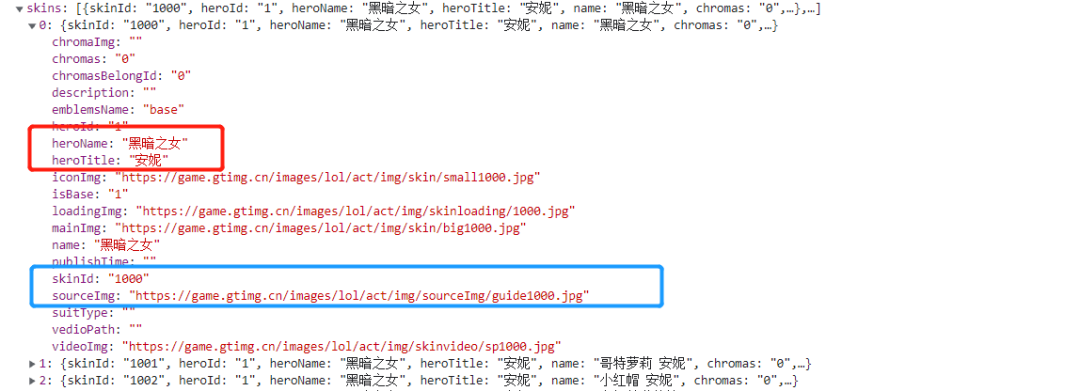
這里我們就以黑暗之女的皮膚的 json 文件做展示進(jìn)行解析,我們需要獲取的內(nèi)容有?1.name,2.skin_name,3.mainImg,因?yàn)槲覀儼l(fā)現(xiàn) heroName 是一樣的,所以把英雄名作為該英雄的皮膚文件夾名,這樣便于查看保存;
item?=?{}
item['name']?=?hero["heroName"]
item['skin_name']?=?hero["name"]
if?hero["mainImg"]?==?'':
???continue
item['imgLink']?=?hero["mainImg"]
有一個(gè)注意點(diǎn):
有的 mainImg 標(biāo)簽是空的,所以我們需要跳過,否則如果是空的鏈接,請(qǐng)求時(shí)會(huì)報(bào)錯(cuò);
四、數(shù)據(jù)采集
導(dǎo)入相關(guān)第三方庫(kù)
import?requests?#?請(qǐng)求
from?multiprocessing.dummy?import?Pool?as?ThreadPool?#?并發(fā)
import?time?#?效率
import?os?#?文件操作
import?json?#?解析
頁(yè)面數(shù)據(jù)解析
def?spider(url):
????res?=?requests.get(url,?headers=headers)
????result?=?res.content.decode('utf-8')
????res_dict?=?json.loads(result)
????skins?=?res_dict["skins"]??#?15個(gè)hero信息
????print(len(skins))
????for?index,hero?in?enumerate(skins):?#?這里使用到enumerate獲取下標(biāo),以便文件圖片命名;
????????item?=?{}?#?字典對(duì)象
????????item['name']?=?hero["heroName"]
????????item['skin_name']?=?hero["name"]
????????if?hero["mainImg"]?==?'':
????????????continue
????????item['imgLink']?=?hero["mainImg"]
????????print(item)
????????download(index+1,item)
download 下載圖片
def?download(index,contdict):
????name?=?contdict['name']
????path?=?"皮膚/"?+?name
????if?not?os.path.exists(path):
????????os.makedirs(path)
????content?=?requests.get(contdict['imgLink'],?headers=headers).content
????with?open('./皮膚/'?+?name?+?'/'?+?contdict['skin_name']?+?str(index)?+?'.jpg',?'wb')?as?f:
????????f.write(content)
這里我們使用 OS 模塊創(chuàng)建文件夾,前面我們有說到,每個(gè)英雄的 heroName 的值是一樣的,借此創(chuàng)建文件夾并命名,方便皮膚的保存(歸類),然后就是這里圖片文件的路徑需要仔細(xì),少一個(gè)斜杠就會(huì)報(bào)錯(cuò)。
main() 主函數(shù)
def?main():?
????pool?=?ThreadPool(6)
????page?=?[]
????for?i?in?range(1,21):
????????newpage?=?'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
????????print(newpage)
????????page.append(newpage)
????result?=?pool.map(spider,?page)
????pool.close()
????pool.join()
????end?=?time.time()
說明:
在主函數(shù)里我們首選創(chuàng)建了六個(gè)線程池;
通過 for 循環(huán)動(dòng)態(tài)構(gòu)建 20 條 url,我們小試牛刀一下,20 個(gè)英雄皮膚,如果爬取全部可以對(duì)之前的 idList 遍歷,再動(dòng)態(tài)構(gòu)建 url;
使用 map() 函數(shù)對(duì)線程池中的 url 進(jìn)行數(shù)據(jù)解析存儲(chǔ)操作;
當(dāng)線程池 close 的時(shí)候并未關(guān)閉線程池,只是會(huì)把狀態(tài)改為不可再插入元素的狀態(tài);
五、程序運(yùn)行
if?__name__?==?'__main__':
????main()
結(jié)果如下:

當(dāng)然了這里只是截取了部分圖像,總共爬取了 200+ 張圖片,總體來(lái)說還是可以。
六、總結(jié)
本次我們使用了多線程爬取了英雄聯(lián)盟官網(wǎng)英雄皮膚高清壁紙,因?yàn)閳D片涉及到 IO 操作,我們使用并發(fā)方式進(jìn)行,大大提高了程序的執(zhí)行效率。
當(dāng)然爬蟲淺嘗輒止,此次小試牛刀,爬取了 20 個(gè)英雄的皮膚圖片,感興趣的小伙伴可以把皮膚全部爬取下來(lái),只需要改變遍歷的元素為之前的 idlist 即可。
如需獲取本文完整代碼及 LOL 壁紙,請(qǐng)為本文右下角點(diǎn)亮在看并添加杰哥微信:Hc220088 獲取。
以上就是本期分享的全部?jī)?nèi)容,我是杰哥,如果你覺得這篇文章對(duì)你有點(diǎn)用的話,就請(qǐng)為本文留個(gè)言,點(diǎn)個(gè)贊?or?在看,或者轉(zhuǎn)發(fā)一下吧,我們下期不見不散!

推薦閱讀
HTTPS 協(xié)議到底比 HTTP 協(xié)議多些什么?
利用 Python 實(shí)現(xiàn)多任務(wù)進(jìn)程
