
【爬蟲實(shí)戰(zhàn)】Python爬取“磁力熊”網(wǎng)站
最近跟隨螞蟻老師學(xué)習(xí)了用flask框架開發(fā)web項(xiàng)目以及爬蟲,我就打算自己開發(fā)一個(gè)電影網(wǎng)站練練手,其中很重要的一步就是獲取電影資源。
于是我就從網(wǎng)上找到了一個(gè)叫“磁力熊”的網(wǎng)站獲取資源
網(wǎng)站:https://www.cilixiong.com/movie/
第一步:我們需要獲取這個(gè)網(wǎng)站里面的每個(gè)分頁(yè)的HTML代碼
所以得找網(wǎng)站分頁(yè)的規(guī)律
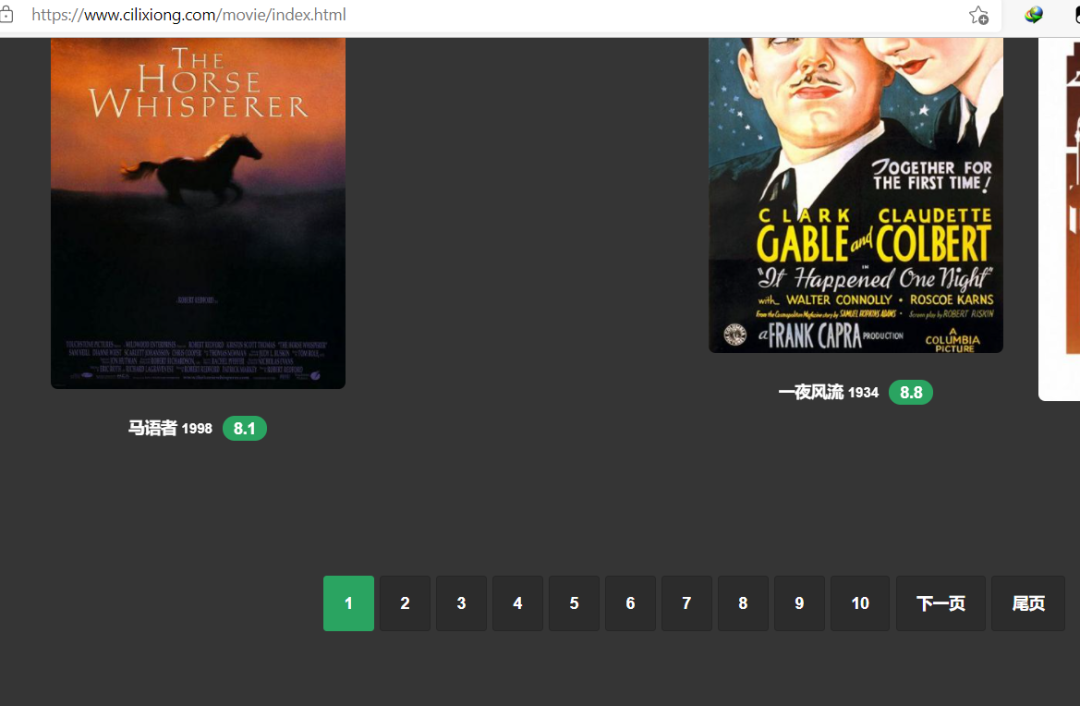
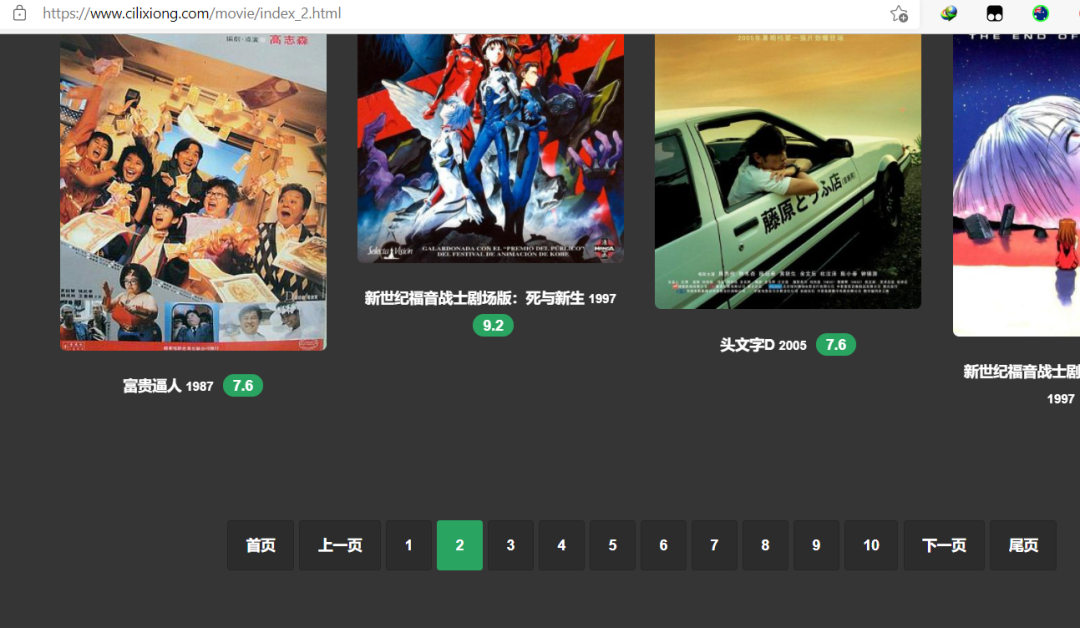
可以發(fā)現(xiàn),除了第一頁(yè)以外,都可以用https://www.cilixiong.com/movie/index_頁(yè)數(shù).html的方式得到,第一頁(yè)是https://www.cilixiong.com/movie/index.html
第二步,找每個(gè)電影的信息藏在何處
通過(guò)瀏覽器的“檢查元素“功能查看頁(yè)面的html代碼,可以發(fā)現(xiàn)每頁(yè)的電影信息都藏在了
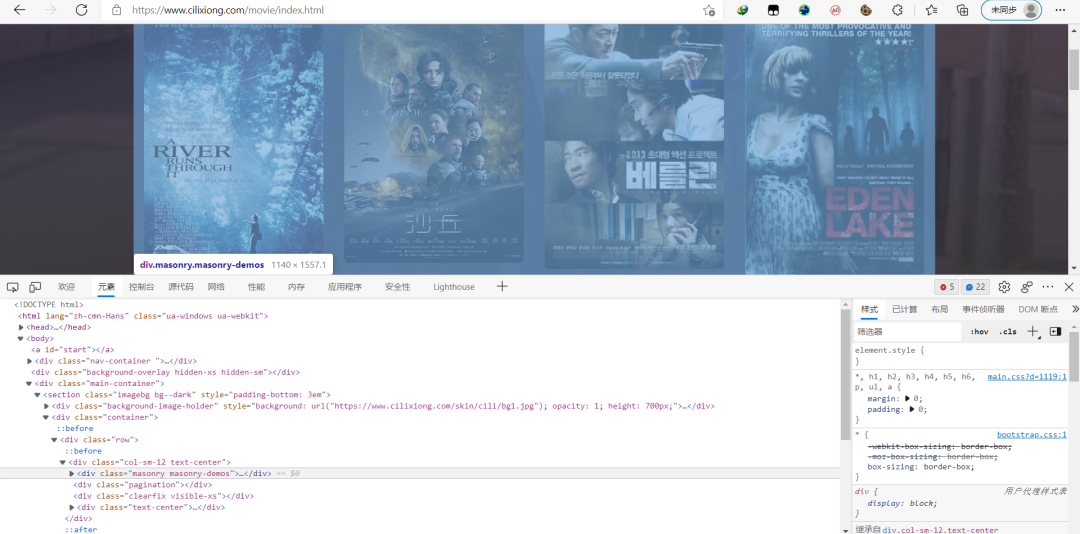
更進(jìn)一步發(fā)現(xiàn),所有電影的縮略圖都在
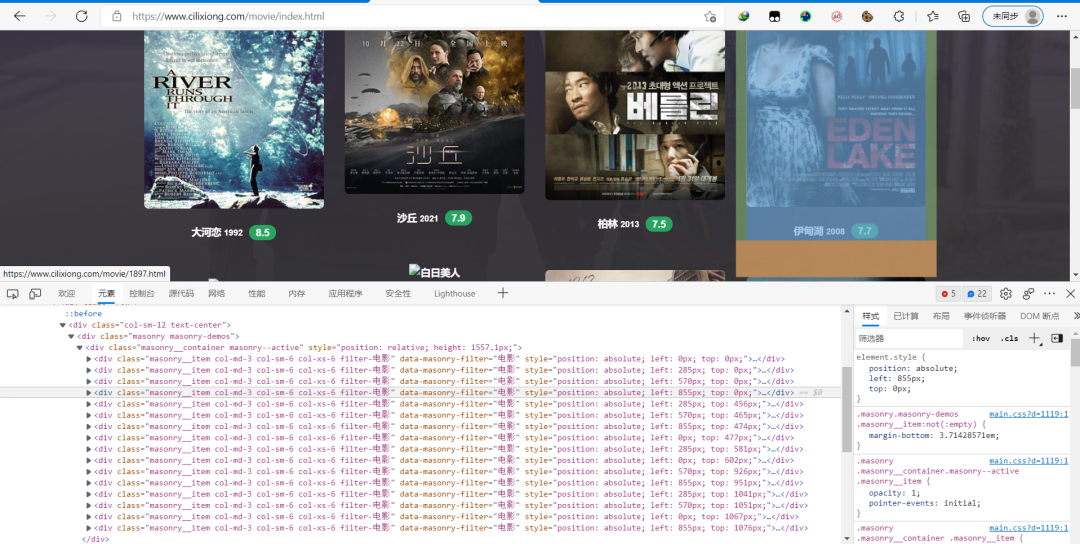
對(duì)其中一個(gè)電影縮略圖進(jìn)行分析,發(fā)現(xiàn)電影的詳情頁(yè)面就在這些div區(qū)域中的a標(biāo)簽里
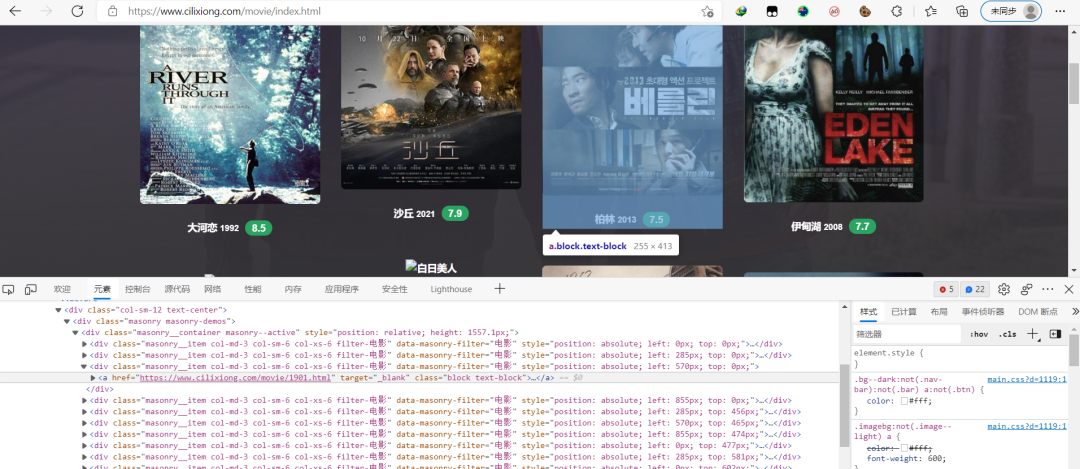
電影的名字和電影封面圖,都可以分別在img標(biāo)簽里的alt和data-original中得到

第三步,查看電影詳情信息
對(duì)html代碼進(jìn)行分析,可以發(fā)現(xiàn)電影的詳細(xì)信息都在標(biāo)簽中
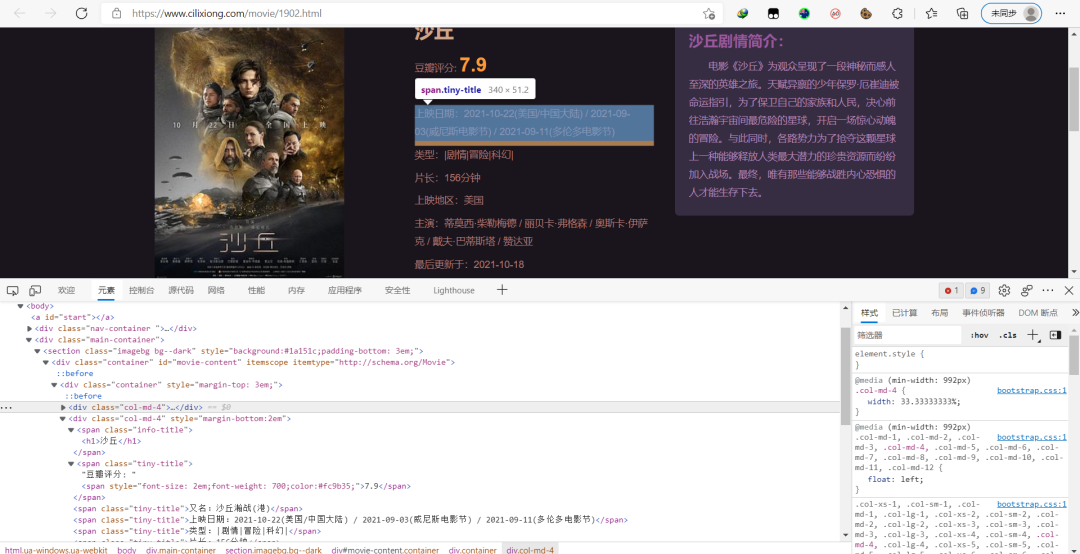
第0個(gè)span標(biāo)簽是電影名稱,第1個(gè)是豆瓣評(píng)分,第2個(gè)是上映日期...
而電影的下載地址則是在
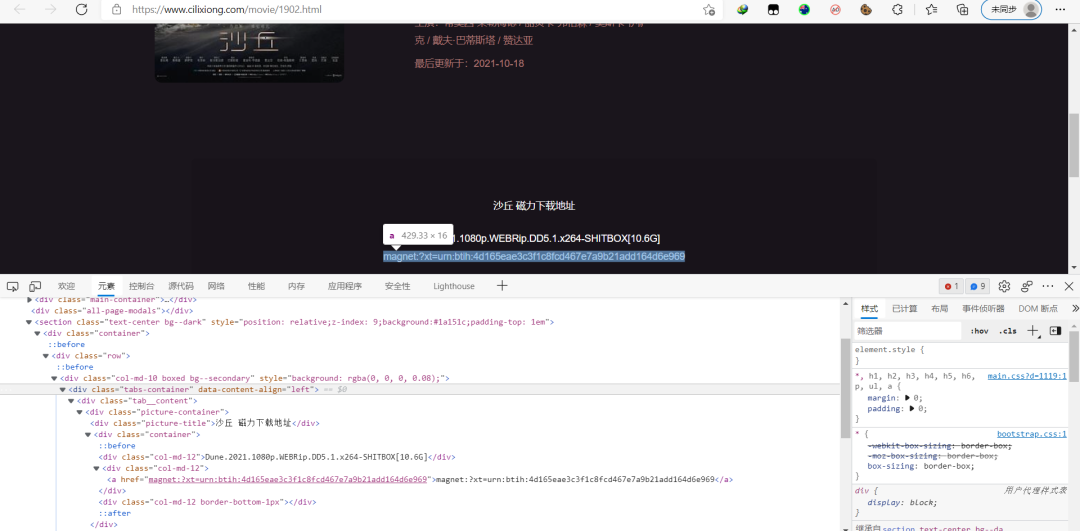
第四步,根據(jù)上面的分析過(guò)程寫代碼
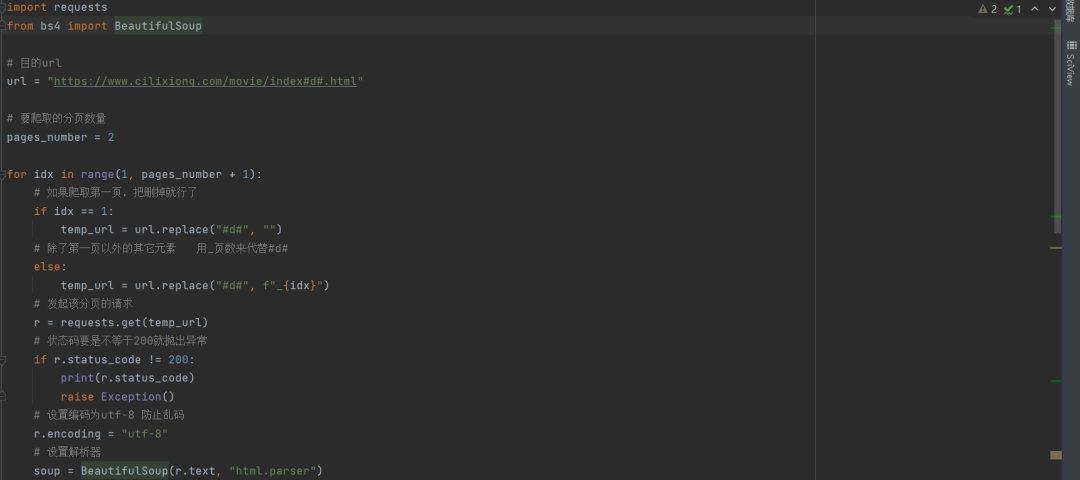

運(yùn)行結(jié)果如下

源代碼:
import requestsfrom bs4 import BeautifulSoup# 目的urlurl = "https://www.cilixiong.com/movie/index#d#.html"# 要爬取的分頁(yè)數(shù)量pages_number = 2for idx in range(1, pages_number + 1):# 如果爬取第一頁(yè),把刪掉就行了if idx == 1:temp_url = url.replace("#d#", "")# 除了第一頁(yè)以外的其它元素 用_頁(yè)數(shù)來(lái)代替#d#else:temp_url = url.replace("#d#", f"_{idx}")# 發(fā)起該分頁(yè)的請(qǐng)求r = requests.get(temp_url)# 狀態(tài)碼要是不等于200就拋出異常if r.status_code != 200:print(r.status_code)raise Exception()# 設(shè)置編碼為utf-8 防止亂碼r.encoding = "utf-8"# 設(shè)置解析器soup = BeautifulSoup(r.text, "html.parser")# 根據(jù)上面所說(shuō)的內(nèi)容 設(shè)置具體解析內(nèi)容 得到該分頁(yè)下的所有電影內(nèi)容movie_list = (soup.find("div", class_="masonry masonry-demos").find("div").find_all("div"))# 對(duì)該分頁(yè)下的所有電影內(nèi)容進(jìn)行解析for movie in movie_list:a_tag = movie.find("a")# 這就是每個(gè)電影詳情的鏈接link = a_tag.get("href")img_tag = a_tag.find("figure").find("img")# 電影名稱name = img_tag.get("alt")# 電影封面圖img_url = img_tag.get("src")# 對(duì)電影的詳情信息發(fā)出請(qǐng)求r = requests.get(link)r.encoding = "utf-8"soup = BeautifulSoup(r.text, "html.parser")# 磁力鏈接cili_link = soup.find("div", class_="tabs-container").find("a").get("href")# 豆瓣得分score = soup.find("span", class_="tiny-title").find("span").get_text()print(f"電影名稱:{name} 電影封面圖:{img_url} 豆瓣得分:{score} 磁力鏈接:{cili_link}")
最后推薦下螞蟻老師的爬蟲課,干貨十足:
????????掃碼購(gòu)買:Python開發(fā)簡(jiǎn)單爬蟲實(shí)戰(zhàn)
點(diǎn)擊閱讀原文,也可以到達(dá)目的地。
<b id="afajh"><abbr id="afajh"></abbr></b>