
Python爬蟲實(shí)戰(zhàn):爬取一周的天氣預(yù)報信息
作者:沐沐
來源:GOGO數(shù)據(jù)「ID: mu_science」


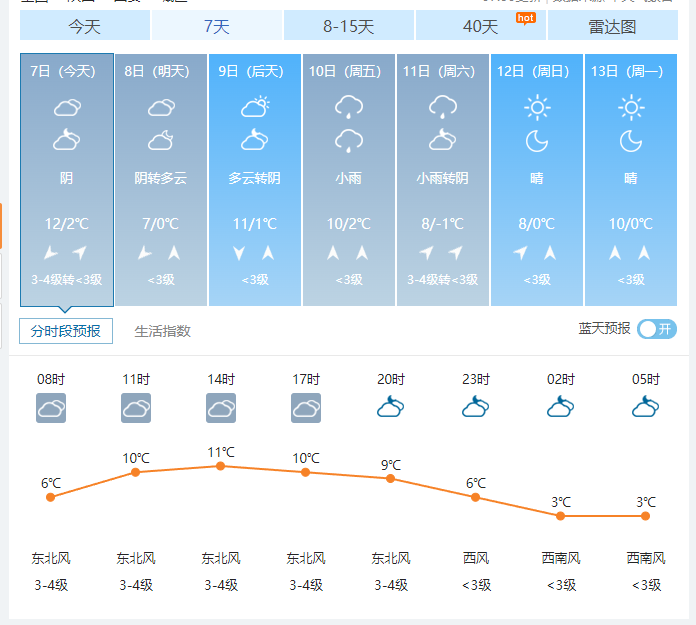
網(wǎng)頁分析
今天我們要爬取的內(nèi)容都在靜態(tài)網(wǎng)頁中,這種網(wǎng)站內(nèi)容獲取都很簡單,我們分析出各個元素所在的位置,直接使用xpath獲取即可

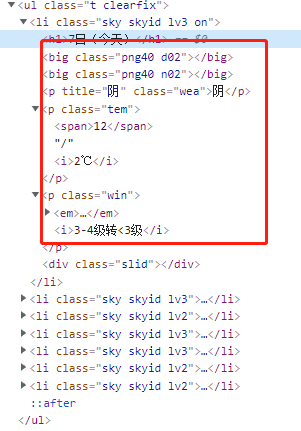
如何在瀏覽器中查找頁面元素,可以參考之前的文章:?爬蟲必備工具,掌握它就解決了一半的問題
代碼實(shí)現(xiàn)
既然知道了我們要獲取的信息所在標(biāo)簽,那么就開始爬取吧!
我們使用的是xpath提取數(shù)據(jù)。所以我們先來導(dǎo)入必要的庫:
import?requests
from?icecream?import?ic
from?lxml?import?etree注意:因?yàn)榫W(wǎng)頁中含有中文字符,所以我們在下載網(wǎng)頁源碼之前先看下它的編碼格式,輸入當(dāng)前網(wǎng)頁的編碼格式? ??
print(res.encoding)
'''
ISO-8859-1
'''打印出來的漢字就是這種'7\xe6\x97\xa5\xef\xbc\x88\xe4\xbb'的亂碼
所以就需要在此做編碼解碼處理,很煩~~
我們可以采取一種更簡單的方法,直接讓獲取到的編碼格式等于當(dāng)前的編碼格式,一行代碼即可解決
#?亂碼處理
resp.encoding?=?resp.apparent_encoding這樣就可以獲取到中文字符串了
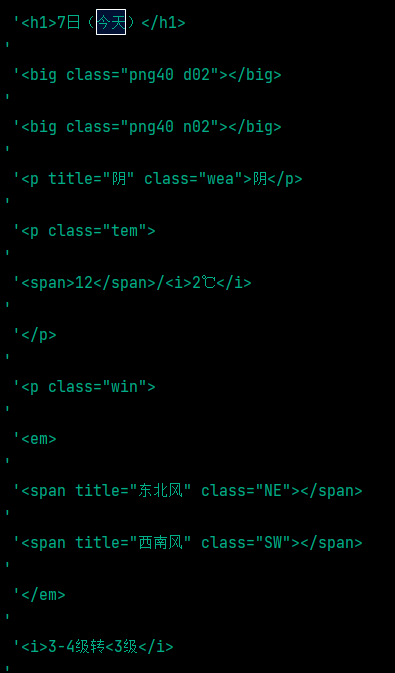
數(shù)據(jù)提取
因?yàn)槊刻斓牡奶鞖庑畔⒍嘉挥诟髯元?dú)立的li標(biāo)簽中,所以我們使用xpath先來提取到所有的li信息
html?=?etree.HTML(content)
uls?=?html.xpath("http://div[@class='left-div'][1]/div[@id='7d']/ul/li")
print(len(uls))
'''
7
'''獲取到所有的li信息,接下來我們提取內(nèi)部天氣、溫度、日期、風(fēng)力等具體信息
for?ul?in?uls:
????date?=?ul.xpath("http://div[@class='left-div'][1]/div[@id='7d']/ul[@class='t?clearfix']/li/h1/text()")
????weather?=?ul.xpath("http://li/p[@class='wea']/text()")
????low_temp?=?ul.xpath("http://li/p[@class='tem']/i/text()")
????high_temp?=?ul.xpath("http://li/p[@class='tem']/span/text()")
????wind?=?ul.xpath("http://li/p[@class='win']/i/text()")
'''
ic|?date:?['7日(今天)',?'8日(明天)',?'9日(后天)',?'10日(周五)',?'11日(周六)',?'12日(周日)',?'13日(周一)']
????weather:?['陰',?'陰轉(zhuǎn)多云',?'多云轉(zhuǎn)陰',?'小雨',?'小雨轉(zhuǎn)陰',?'晴',?'晴']
????high_temp:?['12',?'7',?'11',?'10',?'8',?'8',?'10']
????low_temp:?['2℃',?'0℃',?'1℃',?'2℃',?'-1℃',?'0℃',?'0℃']
????wind:?['3-4級轉(zhuǎn)<3級',?'<3級',?'<3級',?'<3級',?'3-4級轉(zhuǎn)<3級',?'<3級',?'<3級']
'''數(shù)據(jù)保存
數(shù)據(jù)成功打印,接下來我們嘗試將數(shù)據(jù)保存在本地csv文件中
with?open('西安天氣.csv',?'a+',?encoding='utf-8')?as?file:
????for?i?in?range(0,?7):??#?一共有七組數(shù)據(jù)
????????file.write(date[i]?+?':\t')??#?日期
????????file.write(weather[i]?+?'\t')??#?天氣情況
????????file.write("最高氣溫:"?+?high_temp[i]?+?'\t')??#?氣溫
????????file.write("最低氣溫:"?+?low_temp[i]?+?'\t')??#?氣溫
????????file.write("風(fēng)力:"?+?wind[i]?+?'\t')??#?風(fēng)力
????????file.write('\n')結(jié)果展示
結(jié)果展示如下:

以上就是通過Python爬蟲獲取一周天氣預(yù)報的全過程。整個過程沒有特別難的技術(shù)點(diǎn),也沒有很復(fù)雜的反爬處理,所以還是比較適合剛剛學(xué)習(xí)爬蟲的同學(xué)進(jìn)行練習(xí)。核心代碼都已在文中給出,不過爬蟲的代碼經(jīng)常會因?yàn)楸慌廊【W(wǎng)站的更新而失效,所以時間久了有可能需要根據(jù)實(shí)際情況做調(diào)整。但只要掌握了原理,方法都是類似的。建議大家自己動手試一試。
如果文章對你有幫助,歡迎轉(zhuǎn)發(fā)/點(diǎn)贊/收藏~
_往期文章推薦_
我在Python的艷陽里,大雪紛飛
如需了解付費(fèi)精品課程及教學(xué)答疑服務(wù) 請在Crossin的編程教室內(nèi)回復(fù): 666