
目標檢測算法21篇速覽:檢測網(wǎng)絡(luò)優(yōu)化及改進

極市導讀
?本文總結(jié)了21篇目標檢測算法方面的論文,包括對已有的兩種檢測網(wǎng)絡(luò)設(shè)計范式的調(diào)整和優(yōu)化,在檢測網(wǎng)絡(luò)中添加注意力模塊的方式和方法以及關(guān)于anchor從多個框壓縮為點的可能性等。>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿?
導讀
檢測網(wǎng)絡(luò)模型發(fā)展到16年已經(jīng)基本形成了一段式和兩段式的兩種網(wǎng)絡(luò)設(shè)計模式,兩者的共同點是均采用了anchor based的設(shè)計結(jié)構(gòu)來達到對輸入特征圖遍歷的效果。但是反映出來的現(xiàn)象是兩段式網(wǎng)絡(luò)的精度更高,一段式網(wǎng)絡(luò)速度更快,兩者都對待檢測目標的尺度適應(yīng)能力存在一定的瓶頸,那么如何繼續(xù)提高特征表達來增強網(wǎng)絡(luò)性能呢?基于anchor的思路也引入了相對較多的超參數(shù),如何繼續(xù)簡化超參數(shù)的數(shù)量呢?本章我們將沿著這個問題進行2016年到2018年論文的速覽。
第一篇 MS-CNN
《A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection》
提出時間:2016
針對問題:
多尺度目標的檢測問題仍舊是檢測任務(wù)的一個重點問題,既然已經(jīng)有學者考慮了在網(wǎng)絡(luò)的不同層上完成對不同尺度的目標檢測任務(wù),那么具體怎么運用多層的特征呢,本文作者的思路是對不同的輸出層設(shè)計不同尺度的目標檢測器。
創(chuàng)新點:
對于不同的輸出層設(shè)計不同尺度的目標檢測器,完成多尺度下的檢測問題,使用特征的上采樣代替輸入圖像的上采樣步驟。設(shè)計一個去卷積層,來增加特征圖的分辨率,使得小目標依然可以被檢測出來。這里使用了特征圖的deconvolutional layer(反卷積層)來代替input圖像的上采樣,可以大大減少內(nèi)存占用,提高速度。
詳解博客:https://blog.csdn.net/app_12062011/article/details/77945816
第二篇 R-FCN
《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
提出時間:2016
針對問題:
分類網(wǎng)絡(luò)對輸入特征圖中目標的位置信息是不敏感的,而檢測網(wǎng)絡(luò)即需要對目標的位置敏感,還需要保證足夠的分類精度。如何解決或者平衡這個矛盾?按我們的理解來說就是,對分類網(wǎng)絡(luò)來說輸入的特征圖,目標在圖上的不同位置其損失差別不大,但是對檢測網(wǎng)絡(luò)來說,就需要考慮定位的損失,定位的損失再經(jīng)過回傳,會改變網(wǎng)絡(luò)的權(quán)重參數(shù),從而可能對分類的性能產(chǎn)生影響。
創(chuàng)新點:
主要貢獻在于解決了“分類網(wǎng)絡(luò)的位置不敏感性(translation-invariance in image classification)”與“檢測網(wǎng)絡(luò)的位置敏感性(translation-variance in object detection)”之間的矛盾,在提升精度的同時利用“位置敏感得分圖(position-sensitive score maps)”提升了檢測速度。具體就是把每個目標輸出為k_k_(c+1)的特征向量,k*k每一層表征當前目標的上,下左右等細分位置的heatmap圖。
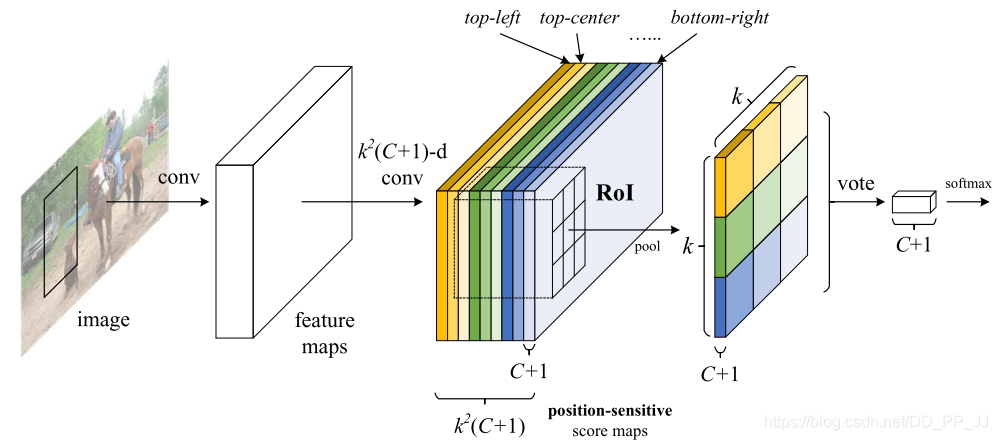
詳解博客:https://zhuanlan.zhihu.com/p/30867916
第三篇 PVANET
《PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection》
提出時間:2016年
針對問題:
本篇論文繼續(xù)在faster rcnn網(wǎng)絡(luò)上深耕,綜合之前提出的多層特征融合、淺層特征計算冗余和inception結(jié)構(gòu)來改善faster rcnn網(wǎng)絡(luò)的性能。
創(chuàng)新點:
改進了faster rcnn的基礎(chǔ)特征提取網(wǎng)絡(luò),在不影響精度的前提下加速。主要是三個點:1)C.RELU,C.ReLU(x)=[ReLU(x), ReLU(-x)],認為淺層卷積核的一半計算都是冗余的。2)Inception結(jié)構(gòu)的引入。3)多層特征的融合。以盡可能的利用細節(jié)和抽象特征。
詳解博客:https://blog.csdn.net/u014380165/article/details/79502113
第四篇 DSSD
《DSSD : Deconvolutional Single Shot Detector》
提出時間:2017
針對問題:
繼續(xù)在SSD的基礎(chǔ)上嘗試提高對小目標的檢測能力。
創(chuàng)新點:
在網(wǎng)絡(luò)中添加了反卷積的結(jié)構(gòu),并通過在backbone中使用resnet結(jié)構(gòu)來提高淺層特征的表達能力。
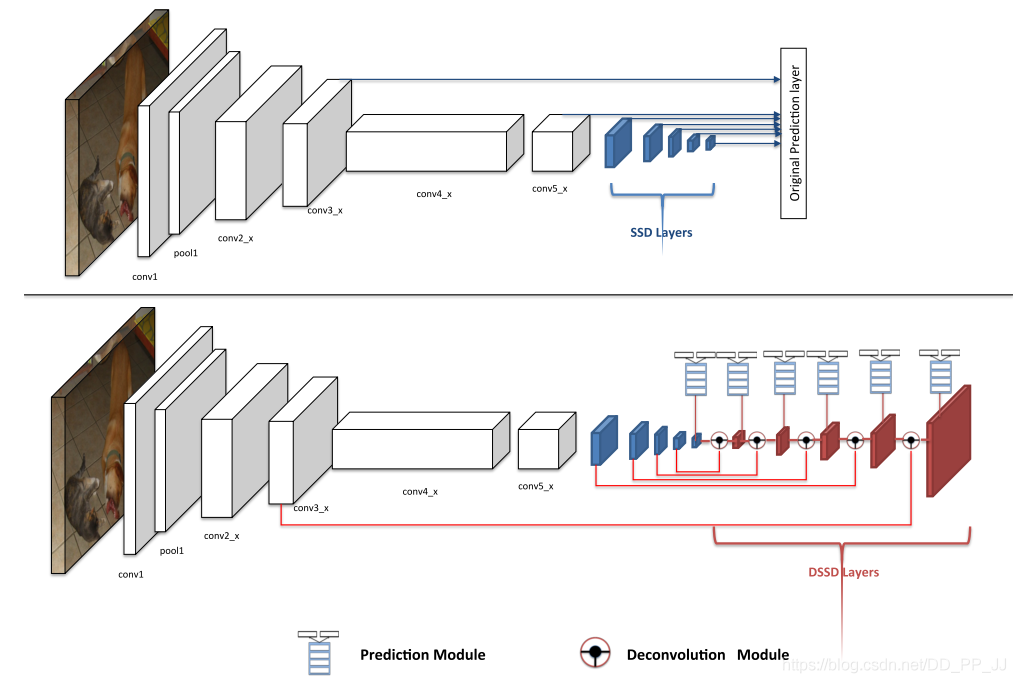
詳解博客:https://blog.csdn.net/u010725283/article/details/79115477/
第五篇 YOLOv2/YOLO9000
《YOLO9000:Better, Faster, Stronger》
提出時間:2017年
針對問題:
對yolov1進行改進,借鑒了anchor、多特征層融合檢測等網(wǎng)絡(luò)改進技巧,在保證檢測速度的前提下,提高了yolo系列的檢測精度。
創(chuàng)新點:
在v1的基礎(chǔ)上,用anchor來強化grid,提高輸入的分辨率,用BN替代dropout,約束anchor的中心點變動區(qū)間,新的backbone
詳解博客:https://blog.csdn.net/shanlepu6038/article/details/84778770
第六篇 FPN
《Feature Pyramid Networks for Object Detection》
提出時間:2017年
針對問題:
本篇論文的作者嘗試通過增強CNN主干網(wǎng)絡(luò)輸出的特征來進一步增強網(wǎng)絡(luò)的檢測精度。
創(chuàng)新點:CNN目標檢測網(wǎng)絡(luò)開始嘗試利用多層特征融合來進行大目標+小目標的檢測,本篇主要是提出新的跳層特征融合及用作分類的方式。FPN網(wǎng)絡(luò)的提出也成為后續(xù)檢測的主干網(wǎng)絡(luò)常用結(jié)構(gòu)。
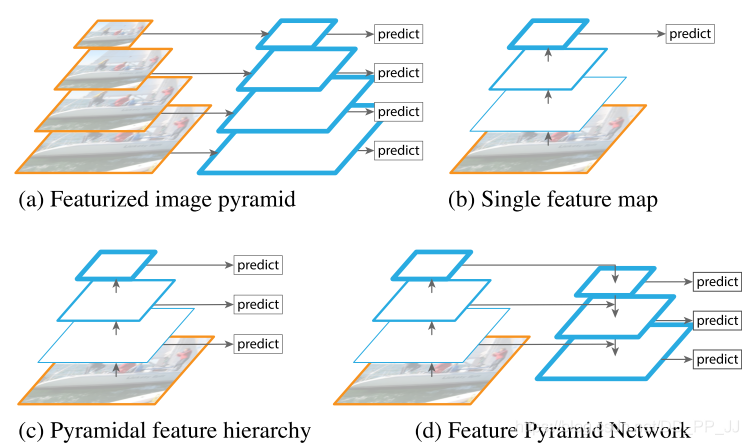
詳解博客:https://blog.csdn.net/kk123k/article/details/86566954
第七篇《RON: Reverse Connection with Objectness Prior Networks for Object Detection》
提出時間:2017年
針對問題:
對一段式網(wǎng)絡(luò)模型的訓練精度問題進行優(yōu)化,作者發(fā)現(xiàn)一段式網(wǎng)絡(luò)在訓練時相對兩段式網(wǎng)絡(luò)正負樣本不均衡程度更大且沒有有效的抑制手段。不均衡的正負樣本會不利于網(wǎng)絡(luò)模型收斂。
創(chuàng)新點:
為了優(yōu)化one-stage目標檢測算法的正負樣本不均勻的問題,添加了objectness prior層來篩選正負樣本,并采用了和FPN類似的特征融合思路,使得淺層特征的表現(xiàn)能力得到了提高。
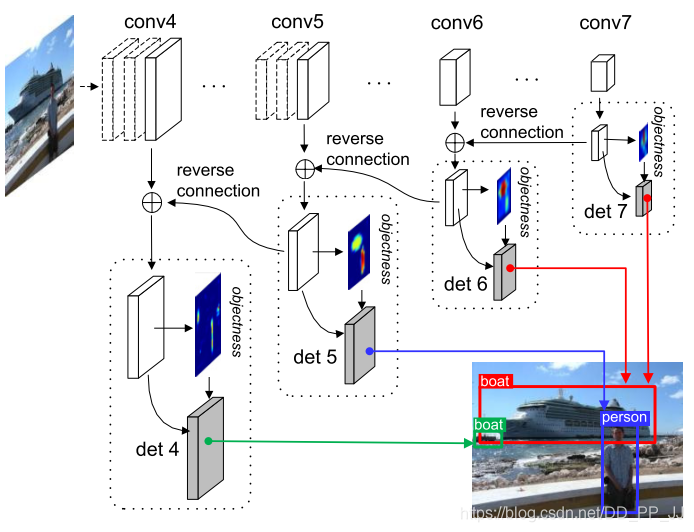
詳解博客:https://blog.csdn.net/shanlepu6038/article/details/84778770
第八篇《DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling》
提出時間:2017年
針對問題:
本文作者注意到,當前的檢測網(wǎng)絡(luò)模型都應(yīng)用了anchor來完成對特征圖的近似遍歷,其中的anchor超參數(shù)的設(shè)置也很重要。作者嘗試繼續(xù)簡化anchor的超參數(shù),即將基于一定長寬anchor組合的檢測算法,取anchor的極限,通過預(yù)測圖像中目標的角點來完成對圖像中目標的定位。
創(chuàng)新點:
之前的two stage 和 one stage都是基于anchor來實現(xiàn)目標建議框的選取,這是第一篇,嘗試在anchor盛行的時候,不手工設(shè)置anchor,而是利用目標角點檢測來實現(xiàn)目標位置檢測的方案。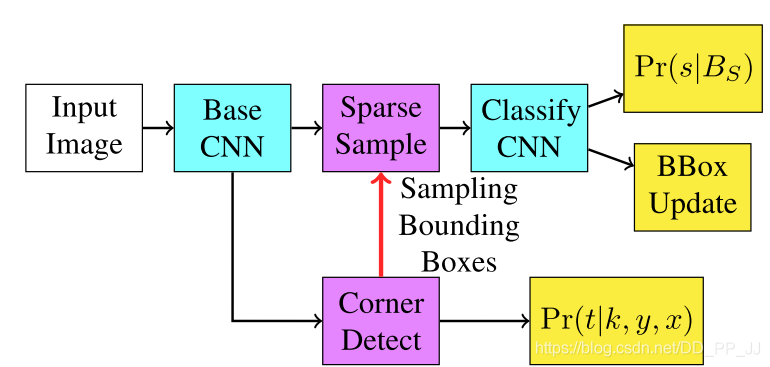 詳解博客:https://blog.csdn.net/yaoqi_isee/article/details/70184686;https://www.cnblogs.com/fourmi/p/10771589.html
詳解博客:https://blog.csdn.net/yaoqi_isee/article/details/70184686;https://www.cnblogs.com/fourmi/p/10771589.html
第九篇《CoupleNet: Coupling Global Structure with Local Parts for Object Detection》
提出時間:2017年
針對問題:
本文是對R-FCN的一個改進。作者觀察到R-FCN中,對輸入特征圖直接映射為目標的不同組件的,對紋理較少的目標,比如沙發(fā),就可能定位誤差偏大。所以作者考慮在R-FCN中加上全局信息。
創(chuàng)新點:
在R-FCN中加上了對全局信息的提取,因為R-FCN是直接將共享的Feature Map 映射為了每類目標的各個組件,而對沙發(fā)這種單獨結(jié)構(gòu)文理很少的,更需要目標的全局信息,ROI Pooling則保留了類似的信息,所以兩者合一一起用。
詳解博客:https://blog.csdn.net/qq_34564947/article/details/77462819
第十篇《Focal Loss for Dense Object Detection》
提出時間:2017年
針對問題:
如第七篇論文的工作,在網(wǎng)絡(luò)模型訓練的過程中,正負樣本的不平衡是影響模型精度的重要因素。第七篇采用的的策略和兩段式網(wǎng)絡(luò)相似,都是通過篩選生成的目標框是否包含正樣本來過濾。本文作者則從損失函數(shù)的角度,通過設(shè)計的Focal Loss降低重復的簡單樣本對模型權(quán)重的影響,強調(diào)難例對網(wǎng)絡(luò)學習的益處,以此來提高模型權(quán)重收斂的方向,使其達到更高精度。
創(chuàng)新點:
定義新的損失函數(shù)Focal loss來使得難訓練的樣本對loss貢獻大,從而一定程度優(yōu)化訓練樣本類別不均衡的問題。
詳解博客:https://www.bilibili.com/read/cv2172717
第十一篇《DSOD: Learning Deeply Supervised Object Detectors from Scratch》
提出時間:2017年
針對問題:
本文作者認為當前的檢測模型大部分都是以大數(shù)據(jù)集訓練得到的分類模型為骨干網(wǎng)絡(luò),再將其遷移到當前數(shù)據(jù)集的檢測任務(wù)上,雖然分類和檢測可以共用特征,但是檢測直接從頭訓練的模型和分類網(wǎng)絡(luò)訓練出來的模型參數(shù)還是有區(qū)別的。所以作者嘗試提供一種從頭有監(jiān)督的訓練檢測網(wǎng)絡(luò)模型的方案。
創(chuàng)新點:
擺脫預(yù)訓練模型,從頭訓練自己的模型,從而擺脫結(jié)構(gòu)依賴。
詳解博客:https://arleyzhang.github.io/articles/c0b67e9a/
第十二篇《MASK R-CNN》
提出時間:2017年
針對問題:
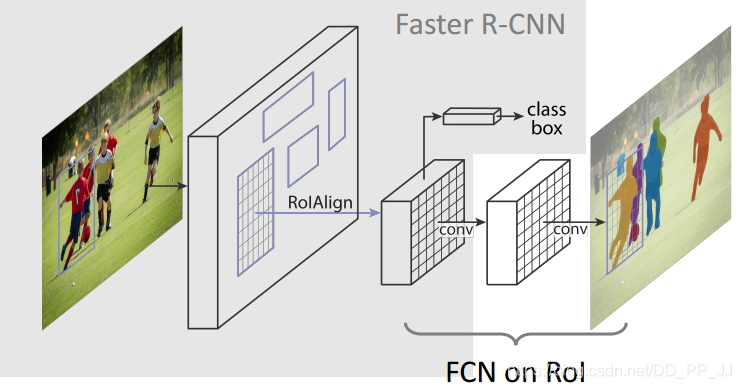
作者嘗試從采用分割網(wǎng)絡(luò)的思路來實現(xiàn)檢測的任務(wù),也就是對每個像素點判斷其類別,再通過不同實例來確定其最小外接矩形框從而達到檢測的目的。
創(chuàng)新點:
主要是ROI align技術(shù),也就是不進行截斷,而是差值方式的ROI POOLING 。
詳解博客:https://blog.csdn.net/WZZ18191171661/article/details/79453780
第十三篇《Deformable Convolutional Networks》
提出時間:2017年
針對問題:
作者認為卷積神經(jīng)網(wǎng)絡(luò)由于其構(gòu)建模塊中的固定幾何結(jié)構(gòu)而固有地僅限于模型幾何轉(zhuǎn)換,即因為卷積核是固定的形狀,無法自適應(yīng)的對輸入特征圖上的特征進行有效的提取。所以作者設(shè)計了可變形的卷積層和池化層。
創(chuàng)新點:
可變形卷積,通過借鑒空洞卷積實現(xiàn),通過單獨的層學習采樣點位置;可變形roi,roi pooling里面的每個bin都可以有一個offset來進行平移。
詳解博客:https://zhuanlan.zhihu.com/p/52476083
第十四篇《YOLOv3》
提出時間:2018年
針對問題:
主要是作者對yolov2網(wǎng)絡(luò)的持續(xù)優(yōu)化和改進。
創(chuàng)新點:
主要是借鑒FPN和resnet來提高主干網(wǎng)絡(luò)的特征層表征能力。
詳解博客:https://blog.csdn.net/dz4543/article/details/90049377
第十五篇《Scale-Transferrable Object Detection》
提出時間:2018年
針對問題:
作者認為類似原始FPN中的特征的融合并不能夠很好的增強特征的表達能力,所以設(shè)計了新的融合方式來強化這部分。
創(chuàng)新點:
提出了一種新的在幾乎不增加參數(shù)和計算量前提下得到大尺寸featuremap的方法,首先將輸入feature map在channel維度上按照r^2長度進行劃分,也就是劃分成C個,每個通道長度為r^2的feature map,然后將每個1_1_r^2區(qū)域轉(zhuǎn)換成r_r維度作為輸出feature map上r_r大小的結(jié)果,最后得到rH_rW_C的feature map。

詳解博客:https://blog.csdn.net/u014380165/article/details/80602130
第十六篇《Single-Shot Refinement Neural Network for Object Detection》
提出時間:2018年
針對問題:
作者觀察到兩段式網(wǎng)絡(luò)有較好的精度表現(xiàn),而一段式網(wǎng)絡(luò)有更優(yōu)秀的速度性能,作者嘗試結(jié)合兩者的特點來構(gòu)建新的網(wǎng)絡(luò)結(jié)構(gòu)。
創(chuàng)新點:
TCB,ARM與ODM模塊的提出。
詳解博客:https://blog.csdn.net/woduitaodong2698/article/details/85258458?utm_medium=distribute.pc_relevant_right.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant_right.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase
第十七篇《Relation Networks for Object Detection》
提出時間:2018年
針對問題:
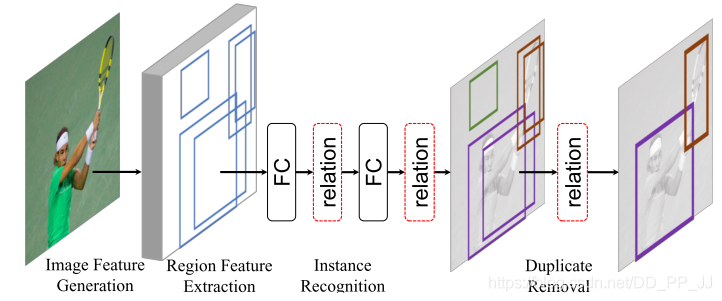
大家都有感覺,物體間或者物體內(nèi)一些區(qū)域的關(guān)聯(lián)性是有助于目標檢測任務(wù)的,但是之前沒人有實際的證明如何使用這種關(guān)聯(lián)性是一定可行的,本文作者就嘗試在檢測網(wǎng)絡(luò)中添加注意力模塊來提高網(wǎng)絡(luò)表現(xiàn)。
創(chuàng)新點:
計算object之間的relation,作為訓練參數(shù),從而提高檢測精度。
詳解博客:https://blog.csdn.net/weixin_42102248/article/details/102858695
第十八篇《Cascade R-CNN: Delving into High Quality Object Detection》
提出時間:2018年
針對問題:
本文也是對網(wǎng)絡(luò)訓練過程中的優(yōu)化技巧,作者發(fā)現(xiàn)訓練檢測網(wǎng)絡(luò)時候需要設(shè)置超參數(shù)IOU閾值來判斷當前定位框是否為正樣本,但是一個單一的IOU閾值可能并不是合用的,所以嘗試做級聯(lián)的IOU閾值來輔助訓練。
創(chuàng)新點:
為了優(yōu)化RPN中的單一IOU問題對最終檢測精度的影響問題而提出,做不同IOU閾值的級聯(lián)來提高計算最終損失的正負樣本質(zhì)量及比例,從而提高性能。
詳解博客:https://blog.csdn.net/qq_17272679/article/details/81260841
第十九篇《Receptive Field Block Net for Accurate and Fast?Object Detection》
提出時間:2018年
針對問題:
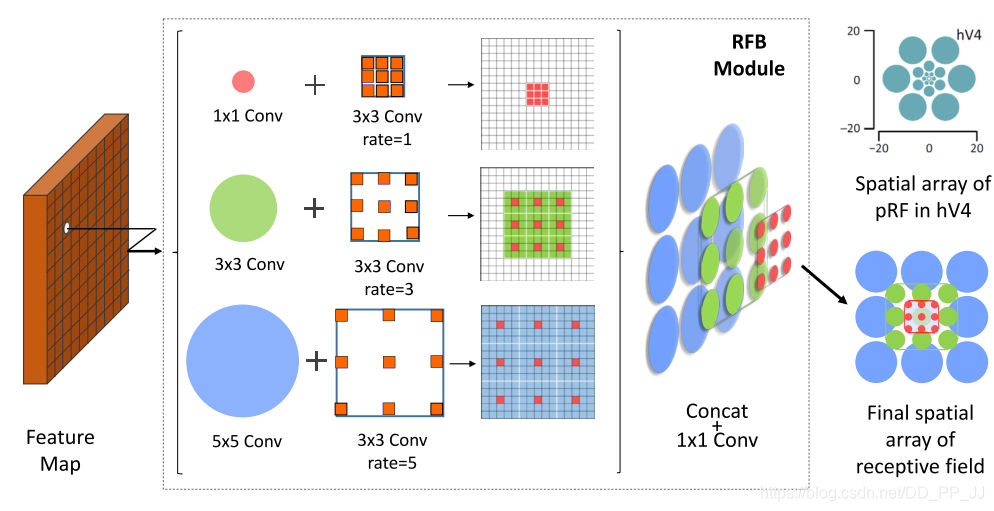
本文作者的工作也是對主干網(wǎng)絡(luò)的不同層特征融合工作的優(yōu)化進行的。主要是為了更有效且更高效的實現(xiàn)特征的融合。
創(chuàng)新點:
提出RFB結(jié)構(gòu),利用空窗卷積來進行特征的融合。
詳解博客:https://blog.csdn.net/u014380165/article/details/81556769
第二十篇《Object Detection based on Region Decomposition and Assembly》
提出時間:2019年
針對問題:
本文作者還是針對兩段式網(wǎng)絡(luò)中目標框提取部分進行優(yōu)化,來提高檢測精度。
創(chuàng)新點:
思路還是借鑒之前的論文,對正樣本圖像塊進行拆分左右上下半邊和其本身,再分別送入后續(xù)卷積,目的是讓網(wǎng)絡(luò)盡可能多的看到當前正樣本的豐富的特征。
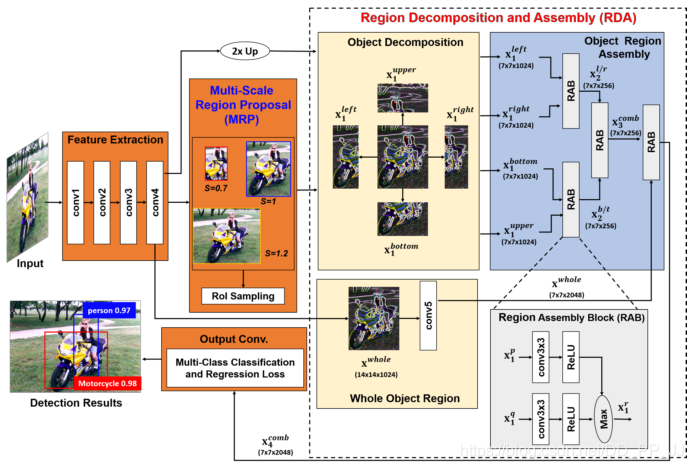
詳解博客:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/88148760
第二十一篇《M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid?Network》
提出時間:2019年
針對問題:
作者認為FPN的特征金字塔最開始就是為了分類而設(shè)計的,在檢測網(wǎng)絡(luò)中需要進行一定的適配才能達到最好的性能。
創(chuàng)新點:
原始的backbone更適合分類任務(wù),改善backbone的使用機制,使其更適應(yīng)檢測任務(wù)。兩個新模塊1)TUM 通過卷積、上采樣和相同shape相加來得到多尺度的特征2)FFMv2 特征融合模塊,通過卷積核upsample來統(tǒng)一輸入feature map的shape,再concat ?3)SFAM ?對輸入的特征先concat,再進行通道層面的attention,并轉(zhuǎn)化為權(quán)重參數(shù)相乘,再送入分類和回歸。
詳解博客:https://blog.csdn.net/hanjiangxue_wei/article/details/103311395
本章總結(jié)
到本章以后,所提到的21篇論文大部分都是對已有的兩種檢測網(wǎng)絡(luò)設(shè)計范式的調(diào)整和優(yōu)化,學者們探索了多層特征的融合并最終推出了FPN,并在FPN基礎(chǔ)上對檢測問題進行適配;學者們還探索了在檢測網(wǎng)絡(luò)中添加注意力模塊的方式和方法,并證明其有效。我們還要注意到第八篇和第十三篇論文,其中第八篇討論了anchor從多個框壓縮為點的可能性,第十三篇則探討了,可能純卷積的結(jié)構(gòu)并不是檢測問題的最優(yōu)選項,這個方向仍舊有優(yōu)化的可能。
推薦閱讀
