
【目標(biāo)檢測(cè)算法50篇速覽】1、檢測(cè)網(wǎng)絡(luò)的出現(xiàn)
【GiantPandaCV導(dǎo)讀】用深度學(xué)習(xí)網(wǎng)絡(luò)來(lái)完成實(shí)際場(chǎng)景的檢測(cè)任務(wù)已經(jīng)是現(xiàn)在很多公司的常規(guī)做法了,但是檢測(cè)網(wǎng)絡(luò)是怎么來(lái)的,又是怎么一步步發(fā)展的呢?在檢測(cè)網(wǎng)絡(luò)不斷迭代的過(guò)程中,學(xué)者們的改進(jìn)都是基于什么思路提出并最終被證實(shí)其優(yōu)越性的呢?
這個(gè)系列將從2013年RCNN開(kāi)始,對(duì)檢測(cè)網(wǎng)絡(luò)發(fā)展過(guò)程中的50篇論文進(jìn)行閱讀,并嘗試梳理檢測(cè)網(wǎng)絡(luò)的發(fā)展脈絡(luò)。這個(gè)系列將按照以下安排梳理:
1、檢測(cè)網(wǎng)絡(luò)從出現(xiàn)到成為一個(gè)完整的端到端模型。
2、one stage 模型出現(xiàn)及two stage 的優(yōu)化。
3、當(dāng)前 anchor base檢測(cè)算法的完整優(yōu)化思路。
4、anchor free算法及檢測(cè)的最新進(jìn)展。
第一篇 RCNN
《Rich feature hierarchies for accurate object detection and semantic segmentation》
提出時(shí)間:2014年
針對(duì)問(wèn)題:
從Alexnet提出后,作者等人思考如何利用卷積網(wǎng)絡(luò)來(lái)完成檢測(cè)任務(wù),即輸入一張圖,實(shí)現(xiàn)圖上目標(biāo)的定位(目標(biāo)在哪)和分類(lèi)(目標(biāo)是什么)兩個(gè)目標(biāo),并最終完成了RCNN網(wǎng)絡(luò)模型。
創(chuàng)新點(diǎn):
RCNN提出時(shí),檢測(cè)網(wǎng)絡(luò)的執(zhí)行思路還是脫胎于分類(lèi)網(wǎng)絡(luò)。也就是深度學(xué)習(xí)部分僅完成輸入圖像塊的分類(lèi)工作。那么對(duì)檢測(cè)任務(wù)來(lái)說(shuō)如何完成目標(biāo)的定位呢,作者采用的是Selective Search候選區(qū)域提取算法,來(lái)獲得當(dāng)前輸入圖上可能包含目標(biāo)的不同圖像塊,再將圖像塊裁剪到固定的尺寸輸入CNN網(wǎng)絡(luò)來(lái)進(jìn)行當(dāng)前圖像塊類(lèi)別的判斷。下圖為RCNN論文中的網(wǎng)絡(luò)完整檢測(cè)流程圖。
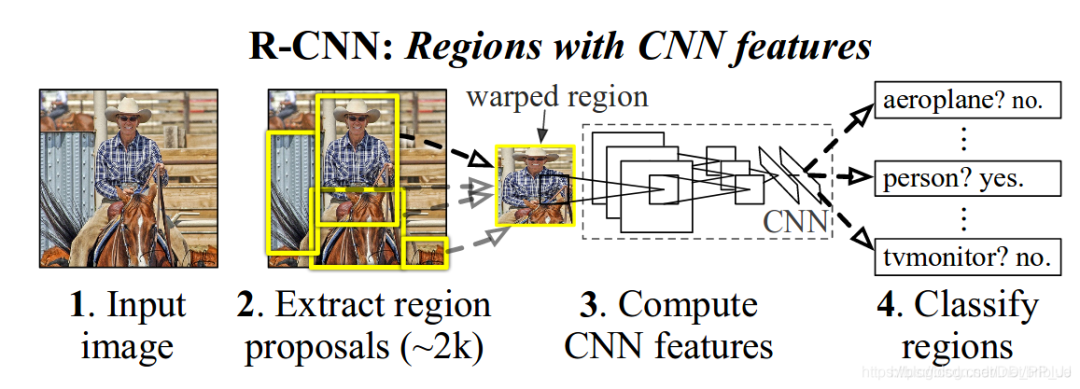
詳解博客:https://blog.csdn.net/briblue/article/details/82012575。
第二篇 OverFeat
《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》
提出時(shí)間:2014年
針對(duì)問(wèn)題:
該論文討論了,CNN提取到的特征能夠同時(shí)用于定位和分類(lèi)兩個(gè)任務(wù)。也就是在CNN提取到特征以后,在網(wǎng)絡(luò)后端組織兩組卷積或全連接層,一組用于實(shí)現(xiàn)定位,輸出當(dāng)前圖像上目標(biāo)的最小外接矩形框坐標(biāo),一組用于分類(lèi),輸出當(dāng)前圖像上目標(biāo)的類(lèi)別信息。也是以此為起點(diǎn),檢測(cè)網(wǎng)絡(luò)出現(xiàn)基礎(chǔ)主干網(wǎng)絡(luò)(backbone)+分類(lèi)頭或回歸頭(定位頭)的網(wǎng)絡(luò)設(shè)計(jì)模式雛形。
創(chuàng)新點(diǎn):
在這篇論文中還有兩個(gè)比較有意思的點(diǎn),一是作者認(rèn)為全連接層其實(shí)質(zhì)實(shí)現(xiàn)的操作和1x1的卷積是類(lèi)似的,而且用1x1的卷積核還可以避免FC對(duì)輸入特征尺寸的限制,那用1x1卷積來(lái)替換FC層,是否可行呢?作者在測(cè)試時(shí)通過(guò)將全連接層替換為1x1卷積核證明是可行的;二是提出了offset max-pooling,也就是對(duì)池化層輸入特征不能整除的情況,通過(guò)進(jìn)行滑動(dòng)池化并將不同的池化層傳遞給后續(xù)網(wǎng)絡(luò)層來(lái)提高效果。如下為論文中的offset max-pooling示意圖。
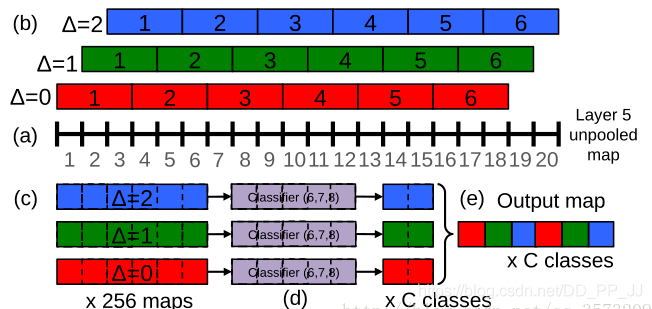
另外作者在論文里提到他的用法是先基于主干網(wǎng)絡(luò)+分類(lèi)頭訓(xùn)練,然后切換分類(lèi)頭為回歸頭,再訓(xùn)練回歸頭的參數(shù),最終完成整個(gè)網(wǎng)絡(luò)的訓(xùn)練。圖像的輸入作者采用的是直接在輸入圖上利用卷積核劃窗。然后在指定的每個(gè)網(wǎng)絡(luò)層上回歸目標(biāo)的尺度和空間位置。
詳解的博客:https://blog.csdn.net/qq_35732097/article/details/79027095
第三篇 MultiBox
《Scalable Object Detection using Deep Neural Networks》
提出時(shí)間:2014年multibox
針對(duì)問(wèn)題:
既然CNN網(wǎng)絡(luò)提取的特征可以直接用于檢測(cè)任務(wù)(定位+分類(lèi)),作者就嘗試將目標(biāo)框(可能包含目標(biāo)的最小外包矩形框)提取任務(wù)放到CNN中進(jìn)行。也就是直接通過(guò)網(wǎng)絡(luò)完成輸入圖像上目標(biāo)的定位工作。
創(chuàng)新點(diǎn):
本文作者通過(guò)將物體檢測(cè)問(wèn)題定義為輸出多個(gè)bounding box的回歸問(wèn)題. 同時(shí)每個(gè)bounding box會(huì)輸出關(guān)于是否包含目標(biāo)物體的置信度, 使得模型更加緊湊和高效。
先通過(guò)聚類(lèi)獲得圖像中可能有目標(biāo)的位置聚類(lèi)中心,(800個(gè)anchor box)然后學(xué)習(xí)預(yù)測(cè)不考慮目標(biāo)類(lèi)別的二分類(lèi)網(wǎng)絡(luò),背景or前景。用到了多尺度下的檢測(cè)。
詳解的博客:https://blog.csdn.net/m0_45962052/article/details/104845125
第四篇 DeepBox
《DeepBox: Learning Objectness with Convolutional Networks》
提出時(shí)間:2015年ICCV
主要針對(duì)和嘗試解決問(wèn)題:
本文完成的工作與第三篇類(lèi)似,都是對(duì)目標(biāo)框提取算法的優(yōu)化方案,區(qū)別是本文首先采用自底而上的方案來(lái)提取圖像上的疑似目標(biāo)框,然后再利用CNN網(wǎng)絡(luò)提取特征對(duì)目標(biāo)框進(jìn)行是否為前景區(qū)域的排序;而第三篇為直接利用CNN網(wǎng)絡(luò)來(lái)回歸圖像上可能的目標(biāo)位置。
創(chuàng)新點(diǎn):
本文作者想通過(guò)CNN學(xué)習(xí)輸入圖像的特征,從而實(shí)現(xiàn)對(duì)輸入網(wǎng)絡(luò)目標(biāo)框是否為真實(shí)目標(biāo)的情況進(jìn)行計(jì)算,量化每個(gè)輸入框的包含目標(biāo)的可能性值。
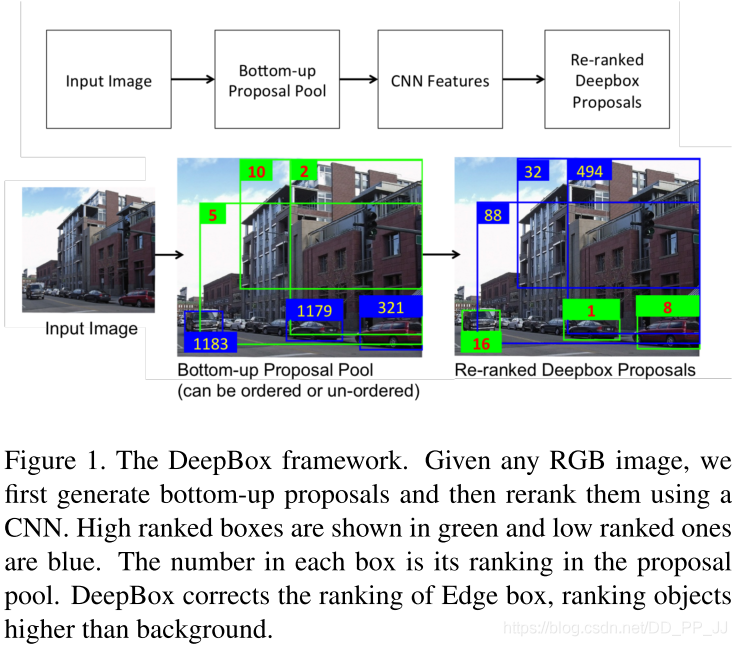
詳解博客:https://www.cnblogs.com/zjutzz/p/8232740.html
第五篇 AttentionNet
AttentionNet: AggregatingWeak Directions for Accurate Object Detection》
提出時(shí)間:2015年ICCV
主要針對(duì)和嘗試解決問(wèn)題:
對(duì)檢測(cè)網(wǎng)絡(luò)的實(shí)現(xiàn)方案進(jìn)行思考,之前的執(zhí)行策略是,先確定輸入圖像中可能包含目標(biāo)位置的矩形框,再對(duì)每個(gè)矩形框進(jìn)行分類(lèi)和回歸從而確定目標(biāo)的準(zhǔn)確位置,參考RCNN。那么能否直接利用回歸的思路從圖像的四個(gè)角點(diǎn),逐漸得到目標(biāo)的最小外接矩形框和類(lèi)別呢?
創(chuàng)新點(diǎn):
通過(guò)從圖像的四個(gè)角點(diǎn),逐步迭代的方式,每次計(jì)算一個(gè)縮小的方向,并縮小指定的距離來(lái)使得逐漸逼近目標(biāo)。作者還提出了針對(duì)多目標(biāo)情況的處理方式。
詳解博客:https://blog.csdn.net/m0_45962052/article/details/104945913
第六篇 SPPNet
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
提出時(shí)間:2014年SPPnet
針對(duì)問(wèn)題:
如RCNN會(huì)將輸入的目標(biāo)圖像塊處理到同一尺寸再輸入進(jìn)CNN網(wǎng)絡(luò),在處理過(guò)程中就造成了圖像塊信息的損失。在實(shí)際的場(chǎng)景中,輸入網(wǎng)絡(luò)的目標(biāo)尺寸很難統(tǒng)一,而網(wǎng)絡(luò)最后的全連接層又要求輸入的特征信息為統(tǒng)一維度的向量。作者就嘗試進(jìn)行不同尺寸CNN網(wǎng)絡(luò)提取到的特征維度進(jìn)行統(tǒng)一。
創(chuàng)新點(diǎn):
作者提出的SPPnet中,通過(guò)使用特征金字塔池化來(lái)使得最后的卷積層輸出結(jié)果可以統(tǒng)一到全連接層需要的尺寸,在訓(xùn)練的時(shí)候,池化的操作還是通過(guò)滑動(dòng)窗口完成的,池化的核寬高及步長(zhǎng)通過(guò)當(dāng)前層的特征圖的寬高計(jì)算得到。原論文中的特征金字塔池化操作圖示如下。
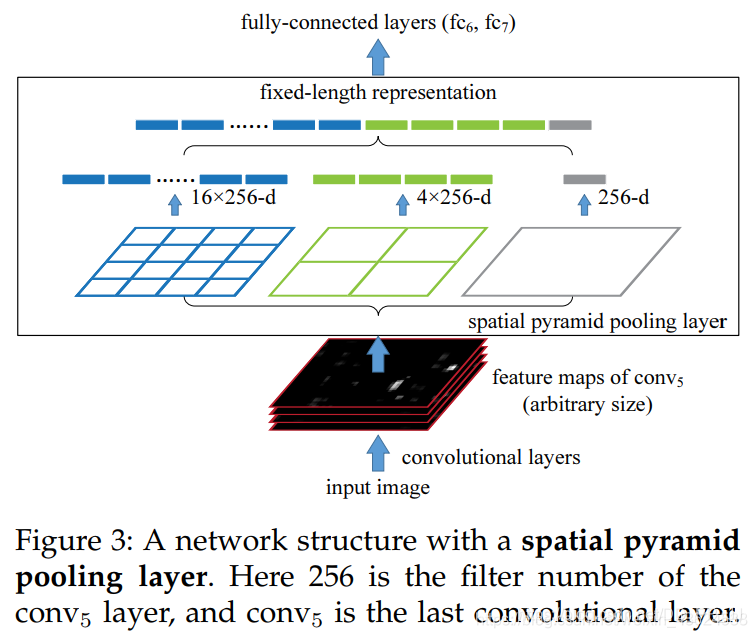
詳解的博客:https://blog.csdn.net/weixin_43624538/article/details/87966601
第七篇 Multi Region CNN
《Object detection via a multi-region & semantic segmentation-aware CNN model》
提出時(shí)間:2015年
針對(duì)問(wèn)題:
既然第三篇論文multibox算法提出了可以用CNN來(lái)實(shí)現(xiàn)輸入圖像中待檢測(cè)目標(biāo)的定位,本文作者就嘗試增加一些訓(xùn)練時(shí)的方法技巧來(lái)提高CNN網(wǎng)絡(luò)最終的定位精度。
創(chuàng)新點(diǎn):
作者通過(guò)對(duì)輸入網(wǎng)絡(luò)的region進(jìn)行一定的處理(通過(guò)數(shù)據(jù)增強(qiáng),使得網(wǎng)絡(luò)利用目標(biāo)周?chē)纳舷挛男畔⒌玫礁珳?zhǔn)的目標(biāo)框)來(lái)增加網(wǎng)絡(luò)對(duì)目標(biāo)回歸框的精度。具體的處理方式包括:擴(kuò)大輸入目標(biāo)的標(biāo)簽包圍框、取輸入目標(biāo)的標(biāo)簽中包圍框的一部分等并對(duì)不同區(qū)域分別回歸位置,使得網(wǎng)絡(luò)對(duì)目標(biāo)的邊界更加敏感。這種操作豐富了輸入目標(biāo)的多樣性,從而提高了回歸框的精度。
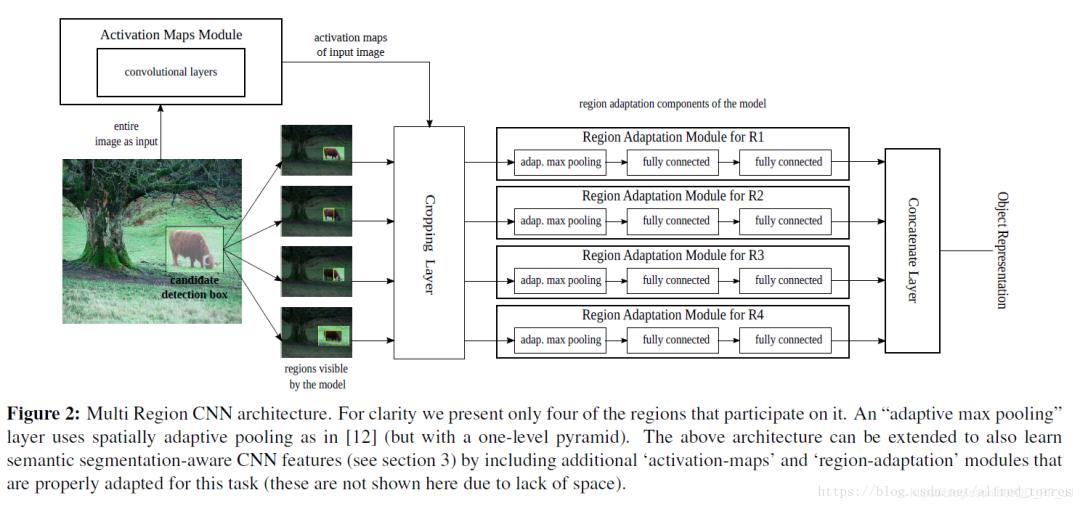
詳解博客:https://blog.csdn.net/alfred_torres/article/details/83022967
第八篇 Fast R-CNN
提出時(shí)間:2015年
針對(duì)問(wèn)題:
RCNN中的CNN每輸入一個(gè)圖像塊就要執(zhí)行一次前向計(jì)算,這顯然是非常耗時(shí)的,那么如何優(yōu)化這部分呢?
創(chuàng)新點(diǎn):
作者參考了SPPNet(第六篇論文),在網(wǎng)絡(luò)中實(shí)現(xiàn)了ROIpooling來(lái)使得輸入的圖像塊不用裁剪到統(tǒng)一尺寸,從而避免了輸入的信息丟失。其次是將整張圖輸入網(wǎng)絡(luò)得到特征圖,再將原圖上用Selective ?Search算法得到的目標(biāo)框映射到特征圖上,避免了特征的重復(fù)提取。
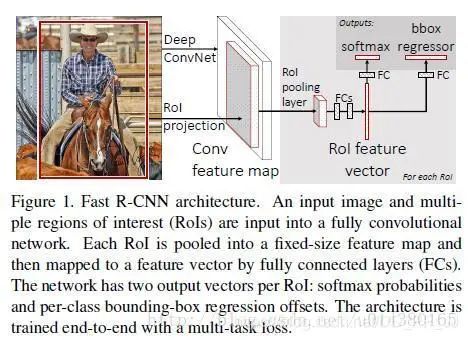
詳解博客:https://blog.csdn.net/u014380165/article/details/72851319
第九篇 DeepProposal
《DeepProposal: Hunting Objects by Cascading Deep Convolutional Layers》
提出時(shí)間:2015年
主要針對(duì)和嘗試解決問(wèn)題:
本文的作者觀察到CNN可以提取到很棒的對(duì)輸入圖像進(jìn)行表征的論文,作者嘗試通過(guò)實(shí)驗(yàn)來(lái)對(duì)CNN網(wǎng)絡(luò)不同層所產(chǎn)生的特征的作用和情況進(jìn)行討論和解析。
創(chuàng)新點(diǎn):
作者在不同的激活層上以滑動(dòng)窗口的方式生成了假設(shè),并表明最終的卷積層可以以較高的查全率找到感興趣的對(duì)象,但是由于特征圖的粗糙性,定位性很差。相反,網(wǎng)絡(luò)的第一層可以更好地定位感興趣的對(duì)象,但召回率降低。
第十篇 Faster R-CNN
提出時(shí)間:2015年NIPS
主要針對(duì)和嘗試解決問(wèn)題:
由multibox(第三篇)和DeepBox(第四篇)等論文,我們知道,用CNN可以生成目標(biāo)待檢測(cè)框,并判定當(dāng)前框?yàn)槟繕?biāo)的概率,那能否將該模型整合到目標(biāo)檢測(cè)的模型中,從而實(shí)現(xiàn)真正輸入端為圖像,輸出為最終檢測(cè)結(jié)果的,全部依賴CNN完成的檢測(cè)系統(tǒng)呢?
創(chuàng)新點(diǎn):
將當(dāng)前輸入圖目標(biāo)框提取整合到了檢測(cè)網(wǎng)絡(luò)中,依賴一個(gè)小的目標(biāo)框提取網(wǎng)絡(luò)RPN來(lái)替代Selective Search算法,從而實(shí)現(xiàn)真正的端到端檢測(cè)算法。
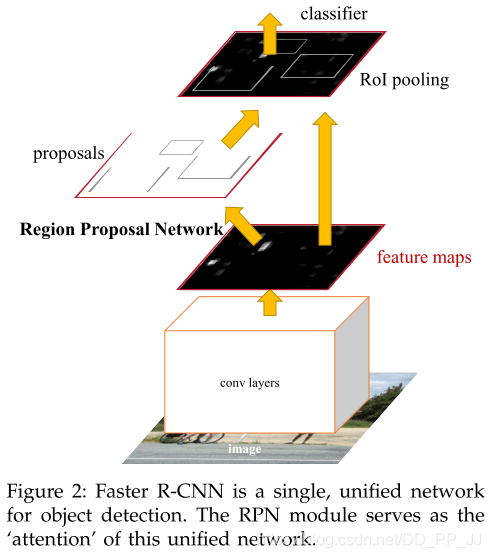
詳解博客:https://zhuanlan.zhihu.com/p/31426458
總結(jié)
第一章是檢測(cè)CNN開(kāi)始的階段,這個(gè)階段的模型最早從Alexnet的分類(lèi)模型開(kāi)始,首先提出了檢測(cè)網(wǎng)絡(luò)模型的基礎(chǔ)結(jié)構(gòu)RCNN(第一篇),接著討論了利用CNN網(wǎng)絡(luò)同時(shí)完成定位和分類(lèi)任務(wù)的可能性(第二篇)。接著就是基于以上兩篇論文的思路,對(duì)檢測(cè)網(wǎng)絡(luò)的不同部分進(jìn)行完善。首先針對(duì)候選目標(biāo)框提取部分,也就是圖像中目標(biāo)的定位,分別為基于全圖直接回歸(第三篇),基于自底向上方案候選框的篩選(第四篇)以及基于全圖的迭代回歸(第五篇)做了嘗試;接著對(duì)不同尺度的目標(biāo)如何統(tǒng)一訓(xùn)練的問(wèn)題進(jìn)行了優(yōu)化(第六篇),并通過(guò)一些訓(xùn)練技巧來(lái)強(qiáng)化網(wǎng)絡(luò)模型的精度(第七篇);然后是對(duì)CNN中不同層輸出特征情況的研究,以此奠定了CNN網(wǎng)絡(luò)不同層的特征具有不同的作用(第九篇);最終,總結(jié)并 凝練學(xué)者們提出的檢測(cè)模型結(jié)構(gòu)和改進(jìn),形成了兩階段目標(biāo)檢測(cè)框架Fast RCNN和Faster RCNN。也標(biāo)志著用CNN來(lái)實(shí)現(xiàn)端到端的目標(biāo)檢測(cè)任務(wù)的主流方向確定。

對(duì)文章有問(wèn)題,或者對(duì)公眾號(hào)的建議歡迎在評(píng)論區(qū)反饋!
希望加入交流群,可以添加BBuf微信