
華為諾亞最新視覺Transformer綜述
點擊上方“視學算法”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導讀
?華為諾亞方舟實驗室聯(lián)合北大和悉大整理了業(yè)界第一篇視覺Transformer綜述。
2021 年對計算機視覺來說是非常重要的一年,各個任務的 SOTA 不斷被刷新。這么多種 Vision Transformer 模型,到底該選哪一個?新手入坑該選哪個方向?華為諾亞方舟實驗室的這一篇綜述或許能給大家?guī)韼椭?/p>
綜述論文鏈接:https://ieeexplore.ieee.org/document/9716741/
諾亞開源模型:https://github.com/huawei-noah
引言
如何將 Transformer 應用于計算機視覺(CV)任務,引起了越來越多研究人員的興趣。在過去很長一段時間內(nèi),CNN 成為視覺任務中的主要模型架構(gòu),但如今 Transformer 呈現(xiàn)出巨大的潛力,有望在視覺領域中打敗 CNN 的霸主地位。谷歌提出了 ViT 架構(gòu),首先將圖像切塊,然后用純 Transformer 架構(gòu)直接應用于圖像塊序列,就能完成對圖像的分類,并在多個圖像識別基準數(shù)據(jù)集上取得了優(yōu)越的性能。除圖像分類任務之外,Transformer 還被用于解決其他視覺問題,包括目標檢測(DETR),語義分割(SETR),圖像處理(IPT)等等。由于其出色的性能,越來越多的研究人員提出了基于 Transformer 的模型來改進各種視覺任務。為了讓大家對視覺 Transformer 在這兩年的飛速發(fā)展有一個清晰的感受,圖 1 展示了視覺 Transformer 的發(fā)展里程碑,從圖像分類到目標檢測,從圖片生成到視頻理解,視覺 Transformer 展現(xiàn)出了非常強的性能。
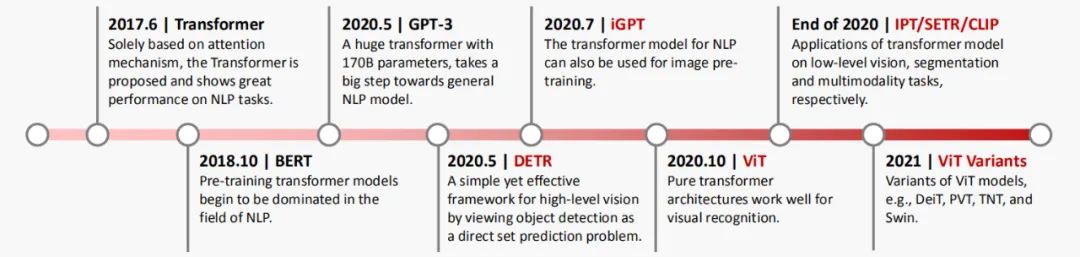
對于很多剛接觸視覺 Transformer 的研究員,看到這么多模型架構(gòu)或許一時沒有頭緒,在面對具體應用需求的時候,也不知道選哪一個視覺 Transformer 架構(gòu)。另外,想做視覺 Transformer 的同學也經(jīng)常在問還有沒有新方向可以挖掘。這些問題或多或少的都可以從這一篇涵蓋了 200 多篇前沿論文的綜述中找到答案:
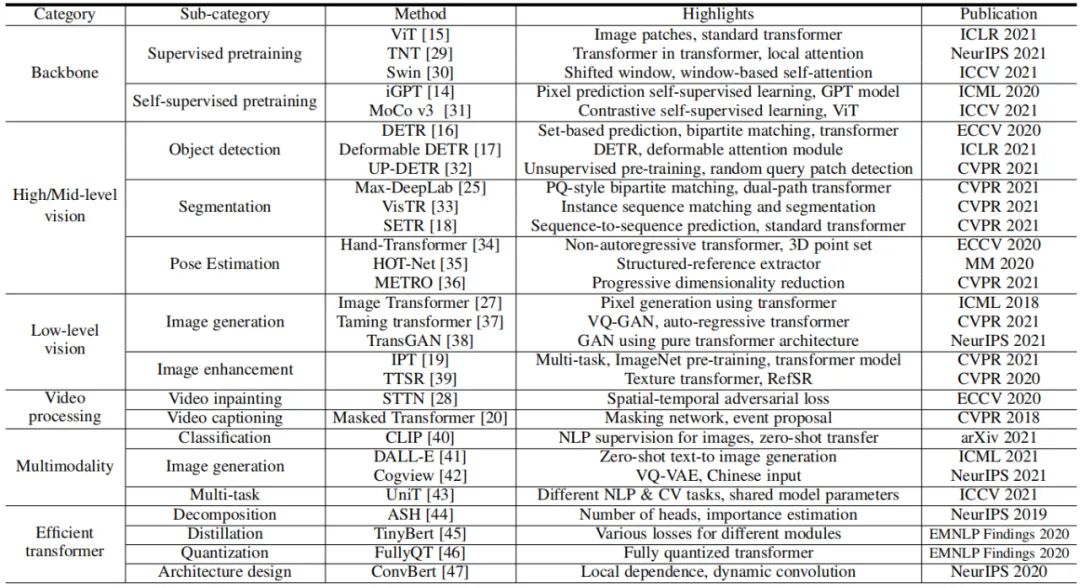
按照視覺 Transformer 的設計和應用場景,本文對視覺 Transformer 模型進行了系統(tǒng)性的歸類,如表 1 所示:骨干網(wǎng)絡、高 / 中層視覺、底層視覺、多模態(tài)等,并且在每一章中針對任務特點進行詳細分析和對比;
本文針對高效的視覺 Transformer 進行了詳細的分析,尤其是在標準數(shù)據(jù)集和硬件上進行了精度和速度的評測,并討論了一些 Transformer 模型壓縮和加速的方法;
華為是一家具有軟硬件全棧 AI 解決方案的公司,基于 A+M 生態(tài),在 Transformer 領域已經(jīng)做出了很多有影響力的工作,基于這些經(jīng)驗并且聯(lián)合了業(yè)界知名學者一起進行了深入思考和討論,給出了幾個很有潛力的未來方向,供大家參考。
附華為諾亞方舟實驗室 Transformer 系列工作:
NLP 大模型盤古 Alpha:https://arxiv.org/abs/2104.12369
中文預訓練模型哪吒:https://arxiv.org/abs/1909.00204
輕量模型 TinyBERT:https://arxiv.org/abs/1909.10351
底層視覺 IPT:https://arxiv.org/abs/2012.00364
多模態(tài) - 悟空:https://arxiv.org/abs/2111.07783
骨干網(wǎng)絡架構(gòu) TNT:https://arxiv.org/abs/2103.00112
骨干網(wǎng)絡
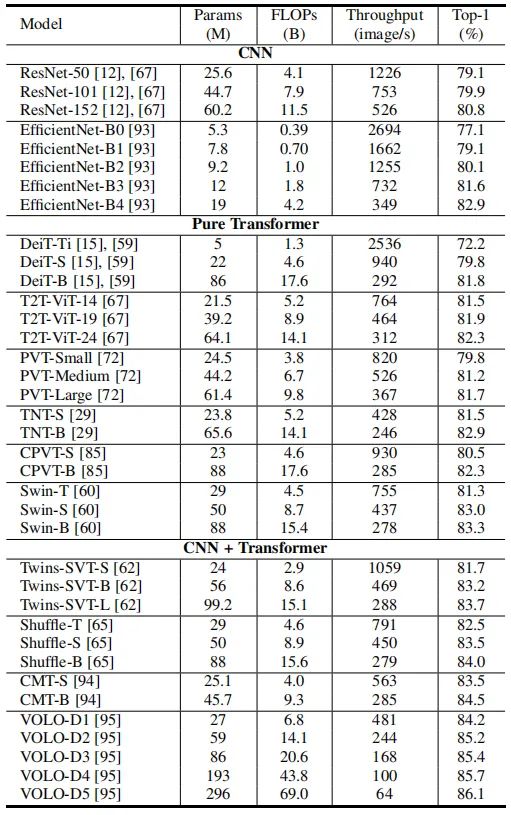
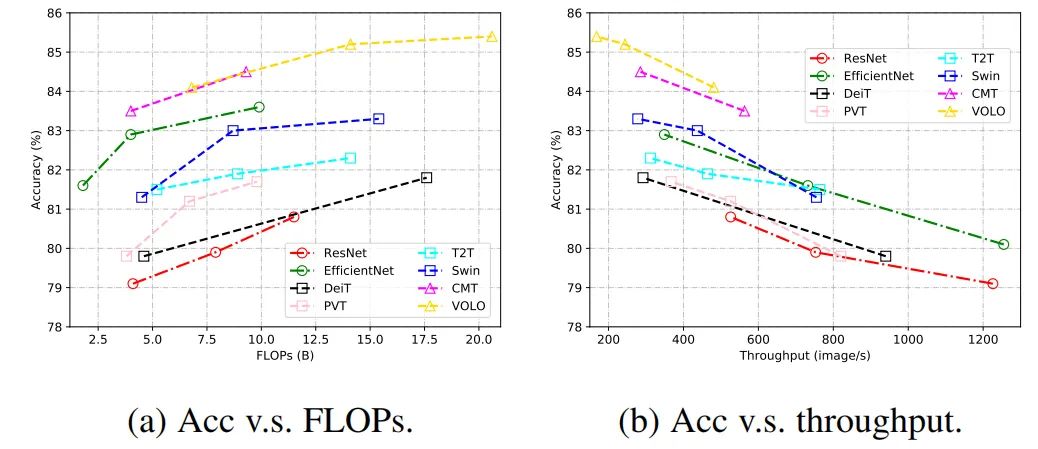
視覺 Transformer 的所有組件,包括多頭自注意力、多層感知機、殘差連接、層歸一化、位置編碼和網(wǎng)絡拓撲結(jié)構(gòu),在視覺識別中起著關鍵作用。為了提高視覺 transformer 的精度和效率,業(yè)界已經(jīng)提出了許多模型。下表總結(jié)了視覺 Transformer 骨干網(wǎng)絡的結(jié)果,可以更好分析現(xiàn)有網(wǎng)絡的發(fā)展趨勢。從圖 2 中的結(jié)果可以看出,將 CNN 和 Transformer 結(jié)合起來可以獲得更好的性能,這表明卷積的局部連接和注意力的全局連接能夠相互補充。
目標檢測
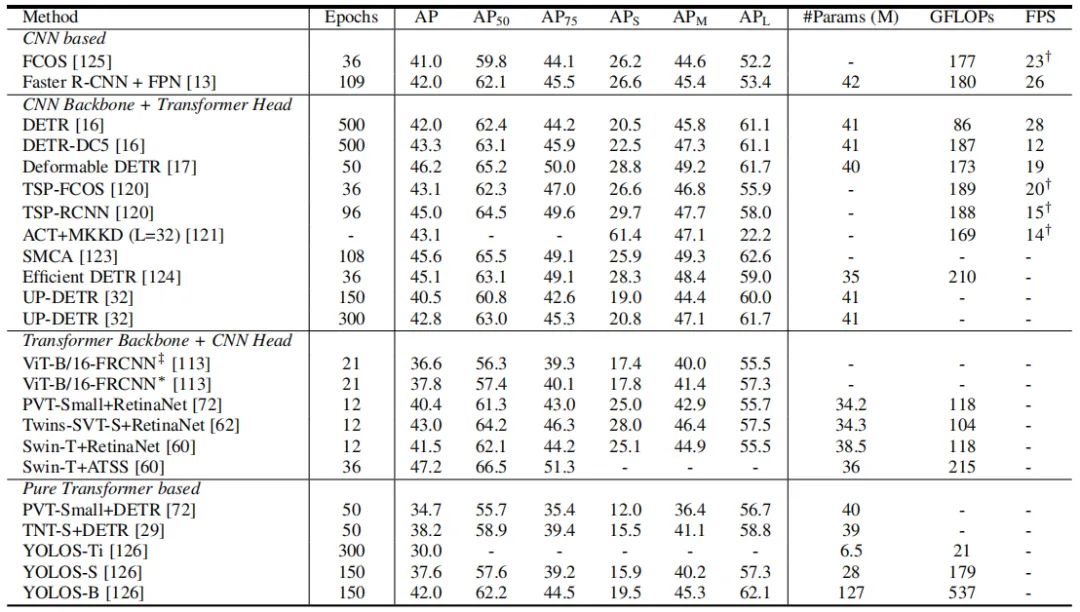
基于 Transformer 的目標檢測方法也引起了廣泛的興趣,這些方法大致可以分為兩類:基于 Transformer 的檢測集合預測方法和基于 Transformer 骨干網(wǎng)絡的檢測方法。與基于 CNN 的檢測器相比,基于 Transformer 的方法在準確性和運行速度方面都表現(xiàn)出了強大的性能。表 3 展示了在 COCO 數(shù)據(jù)集上基于 Transformer 的不同目標檢測器的性能。
將 Transformer 用于中高層視覺任務,在輸入 embedding、位置編碼、損失函數(shù)以及整體架構(gòu)設計等方面都有較多的探索空間。一些現(xiàn)有方法從不同角度改進自注意力模塊,如變形注意力機制和自適應聚類。盡管如此,利用 Transformer 來解決中高層視覺任務的探索仍處于初步階段,需要整個業(yè)界進一步的研究。例如,在 Transformer 之前是否有必要使用 CNN 或 PointNet 等特征提取模塊以獲得更好的性能?如何像 BERT 和 GPT-3 在 NLP 領域所做的那樣,使用大規(guī)模的預訓練數(shù)據(jù)充分利用 Transformer 的特性?如何通過結(jié)合特定任務的先驗知識來設計更強大的體系結(jié)構(gòu)?之前的一些工作已經(jīng)對上述問題進行了初步討論,期待有更多研究來探索更強大的視覺 Transformer。除了目標檢測,Transformer 還被應用于其他中高層視覺任務,如圖像分割、人體姿態(tài)估計、目標跟蹤等,詳細內(nèi)容可參考原論文。
底層視覺
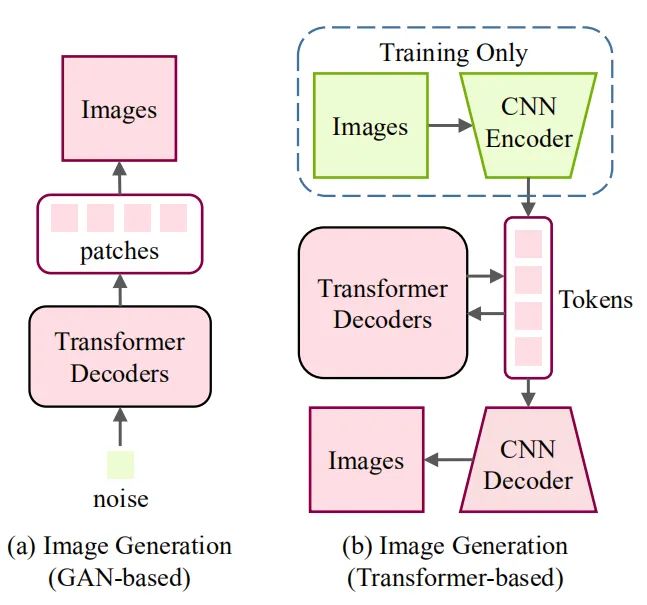
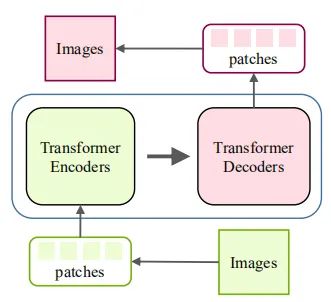
底層視覺是計算機視覺領域的一個重要問題,如圖像超分辨率和圖像生成等,而目前也有一些工作來研究如何將 Transformer 應用于底層視覺中來。這些任務通常將圖像作為輸出(高分辨率或去噪圖像),這比分類、分割和檢測等高層視覺任務(輸出是標簽或框)更具挑戰(zhàn)性。圖 3 和圖 4 展示了在底層視覺中使用 Transformer 的方式。在圖像處理任務中,首先將圖像編碼為一系列 token,Transformer 編碼器使用該序列作為輸入,進而用 Transformer 解碼器生成所需圖像。在圖像生成任務中,基于 GAN 的模型直接學習解碼器生成的 token,通過線性映射輸出圖像,而基于 Transformer 的模型訓練自編碼器學習圖像的碼本,并使用自回歸 Transformer 模型預測編碼的 token。而一個有意義的未來研究方向是為不同的圖像處理任務設計合適的網(wǎng)絡架構(gòu)。
多模態(tài)
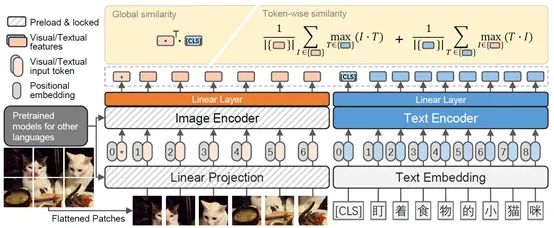
許多研究開始熱衷于挖掘 Transformer 在處理多模態(tài)任務(如視頻 - 文本、圖像 - 文本和音頻 - 文本)的潛力。CLIP 是其中影響力較大的一個工作, 其將自然語言作為監(jiān)督信號,來學習更有效的圖像表示。CLIP 使用大量文本圖像對來聯(lián)合訓練文本編碼器和圖像編碼器。CLIP 的文本編碼器是一個標準的 Transformer,具有 mask 的自注意力層;對于圖像編碼器,CLIP 考慮了兩種類型的架構(gòu):ResNet 和視覺 Transformer。CLIP 在一個新采集的數(shù)據(jù)集上進行訓練,該數(shù)據(jù)集包含從互聯(lián)網(wǎng)上收集的 4 億對圖像 - 文本對。CLIP 展示了驚人的零樣本分類性能,在 ImageNet-1K 數(shù)據(jù)集上實現(xiàn)了 76.2% top-1 精度,而無需使用任何 ImageNet 訓練標簽。華為諾亞的悟空(英文名:FILIP)模型使用雙塔架構(gòu)構(gòu)建圖文表征,取得了更好的效果,如圖 5 所示。總之,基于 transformer 的多模態(tài)模型在統(tǒng)一各種模態(tài)的數(shù)據(jù)和任務方面顯示出了其架構(gòu)優(yōu)勢,這表明了 transformer 具備構(gòu)建一個能夠處理大量應用的通用智能代理的潛力。
高效 Transformer
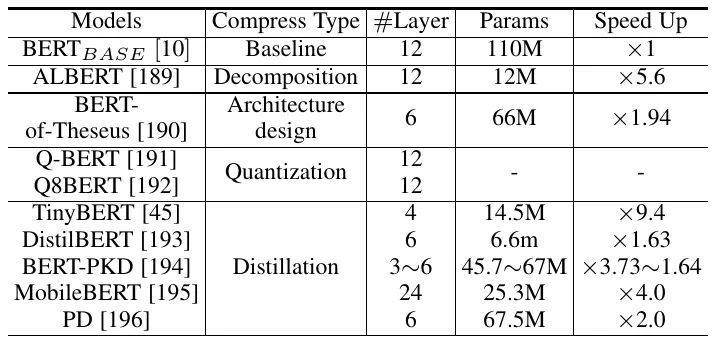
盡管 Transformer 模型在各種任務中取得了成功,但它們對內(nèi)存和計算資源的高要求阻礙了它們在端側(cè)設備(如手機)上的部署。文章還回顧了為高效部署而對 Transformer 模型進行壓縮和加速的研究,這包括網(wǎng)絡剪枝、低秩分解、知識蒸餾、網(wǎng)絡量化和緊湊結(jié)構(gòu)設計。表 4 列出了一些壓縮 Transformer 模型的代表性工作,這些工作采用不同的方法來識別 Transformer 模型中的冗余。具體來說,剪枝側(cè)重于減少 Transformer 模型中組件(例如,層、頭)的數(shù)量,而分解將原始矩陣表示為多個小矩陣。緊湊模型也可以直接手動(需要足夠的專業(yè)知識)或自動(例如通過 NAS)設計來得到。
未來展望
作為一篇綜述論文,對所探究的領域未來方向的牽引也是非常重要的。本文的最后,也為大家提供了幾個有潛力并且很重要的方向:
業(yè)界流行有各種類型的神經(jīng)網(wǎng)絡,如 CNN、RNN 和 Transformer。在 CV 領域,CNN 曾經(jīng)是主流選擇,但現(xiàn)在 Transformer 變得越來越流行。CNN 可以捕捉歸納偏置,如平移等變和局部性,而 ViT 使用大規(guī)模訓練來超越歸納偏置。從現(xiàn)有的觀察來看,CNN 在小數(shù)據(jù)集上表現(xiàn)良好,而 Transformer 在大數(shù)據(jù)集上表現(xiàn)更好。而在視覺任務中,究竟是使用 CNN 還是 Transformer,或者兼二者之所長,是一個值得探究的問題。
大多數(shù)現(xiàn)有的視覺 Transformer 模型設計為只處理一項任務,而許多 NLP 模型,如 GPT-3,已經(jīng)演示了 Transformer 如何在一個模型中處理多項任務。CV 領域的 IPT 能夠處理多個底層視覺任務,例如超分辨率、圖像去雨和去噪。Perceiver 和 Perceiver IO 也是可以在多個領域工作的 Transformer 模型,包括圖像、音頻、多模態(tài)和點云。將所有視覺任務甚至其他任務統(tǒng)一到一個 Transformer(即一個大統(tǒng)一模型)中是一個令人興奮的課題。
另一個方向是開發(fā)高效的視覺 Transformer;具體來說,如果讓 Transformer 具有更高精度和更低資源消耗。性能決定了該模型是否可以應用于現(xiàn)實世界的應用,而資源成本則影響其在硬件設備上的部署。而通常精度與資源消耗息息相關,因此確定如何在兩者之間實現(xiàn)更好的平衡是未來研究的一個有意義的課題。
通過使用大量數(shù)據(jù)進行訓練,Transformer 可以在 NLP 和 CV 不同任務上得到領先的性能。最后,文章還留下一個問題:Transformer 能否通過更簡單的計算范式和大量數(shù)據(jù)訓練獲得令人滿意的結(jié)果?

點個在看 paper不斷!