
TPAMI 2022|華為諾亞最新視覺(jué)Transformer綜述

極市導(dǎo)讀
?華為諾亞方舟實(shí)驗(yàn)室聯(lián)合北大和悉大整理了業(yè)界第一篇視覺(jué)Transformer綜述。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
2021 年對(duì)計(jì)算機(jī)視覺(jué)來(lái)說(shuō)是非常重要的一年,各個(gè)任務(wù)的 SOTA 不斷被刷新。這么多種 Vision Transformer 模型,到底該選哪一個(gè)?新手入坑該選哪個(gè)方向?華為諾亞方舟實(shí)驗(yàn)室的這一篇綜述或許能給大家?guī)?lái)幫助。

綜述論文鏈接:https://ieeexplore.ieee.org/document/9716741/
諾亞開(kāi)源模型:https://github.com/huawei-noah
引言
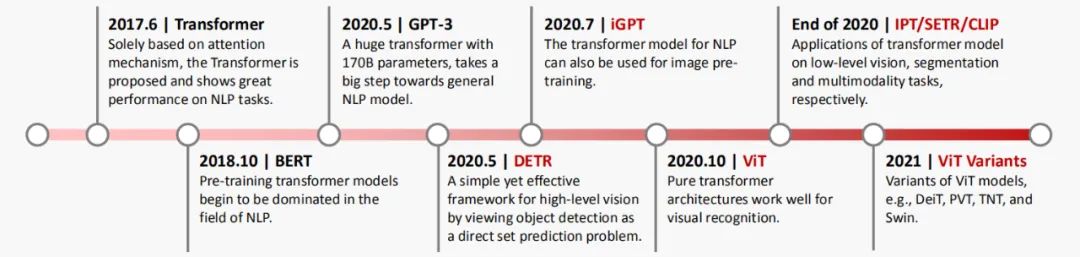
如何將 Transformer 應(yīng)用于計(jì)算機(jī)視覺(jué)(CV)任務(wù),引起了越來(lái)越多研究人員的興趣。在過(guò)去很長(zhǎng)一段時(shí)間內(nèi),CNN 成為視覺(jué)任務(wù)中的主要模型架構(gòu),但如今 Transformer 呈現(xiàn)出巨大的潛力,有望在視覺(jué)領(lǐng)域中打敗 CNN 的霸主地位。谷歌提出了 ViT 架構(gòu),首先將圖像切塊,然后用純 Transformer 架構(gòu)直接應(yīng)用于圖像塊序列,就能完成對(duì)圖像的分類(lèi),并在多個(gè)圖像識(shí)別基準(zhǔn)數(shù)據(jù)集上取得了優(yōu)越的性能。除圖像分類(lèi)任務(wù)之外,Transformer 還被用于解決其他視覺(jué)問(wèn)題,包括目標(biāo)檢測(cè)(DETR),語(yǔ)義分割(SETR),圖像處理(IPT)等等。由于其出色的性能,越來(lái)越多的研究人員提出了基于 Transformer 的模型來(lái)改進(jìn)各種視覺(jué)任務(wù)。為了讓大家對(duì)視覺(jué) Transformer 在這兩年的飛速發(fā)展有一個(gè)清晰的感受,圖 1 展示了視覺(jué) Transformer 的發(fā)展里程碑,從圖像分類(lèi)到目標(biāo)檢測(cè),從圖片生成到視頻理解,視覺(jué) Transformer 展現(xiàn)出了非常強(qiáng)的性能。
對(duì)于很多剛接觸視覺(jué) Transformer 的研究員,看到這么多模型架構(gòu)或許一時(shí)沒(méi)有頭緒,在面對(duì)具體應(yīng)用需求的時(shí)候,也不知道選哪一個(gè)視覺(jué) Transformer 架構(gòu)。另外,想做視覺(jué) Transformer 的同學(xué)也經(jīng)常在問(wèn)還有沒(méi)有新方向可以挖掘。這些問(wèn)題或多或少的都可以從這一篇涵蓋了 200 多篇前沿論文的綜述中找到答案:
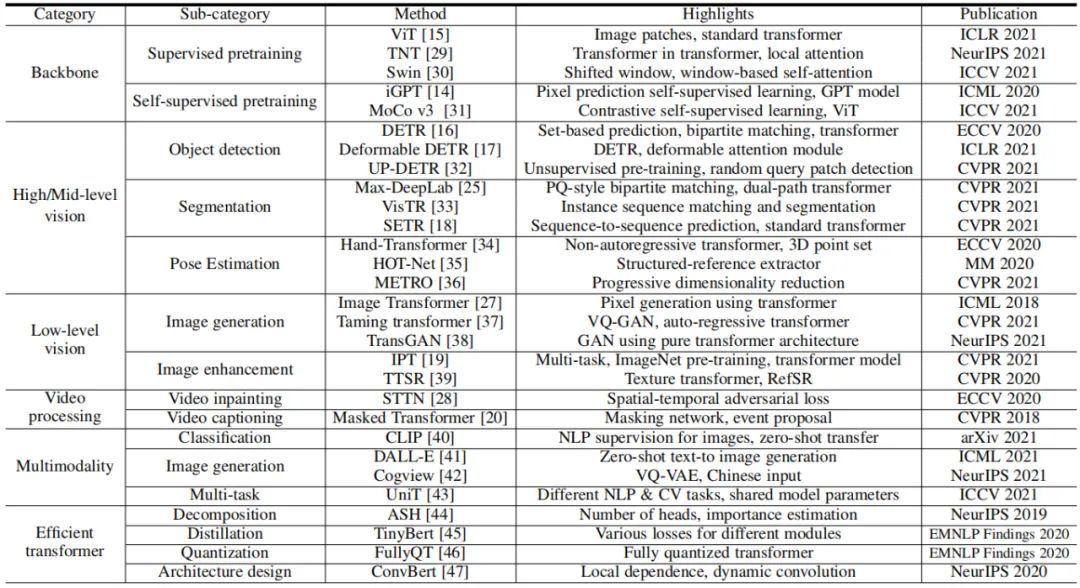
按照視覺(jué) Transformer 的設(shè)計(jì)和應(yīng)用場(chǎng)景,本文對(duì)視覺(jué) Transformer 模型進(jìn)行了系統(tǒng)性的歸類(lèi),如表 1 所示:骨干網(wǎng)絡(luò)、高 / 中層視覺(jué)、底層視覺(jué)、多模態(tài)等,并且在每一章中針對(duì)任務(wù)特點(diǎn)進(jìn)行詳細(xì)分析和對(duì)比;
本文針對(duì)高效的視覺(jué) Transformer 進(jìn)行了詳細(xì)的分析,尤其是在標(biāo)準(zhǔn)數(shù)據(jù)集和硬件上進(jìn)行了精度和速度的評(píng)測(cè),并討論了一些 Transformer 模型壓縮和加速的方法;
華為是一家具有軟硬件全棧 AI 解決方案的公司,基于 A+M 生態(tài),在 Transformer 領(lǐng)域已經(jīng)做出了很多有影響力的工作,基于這些經(jīng)驗(yàn)并且聯(lián)合了業(yè)界知名學(xué)者一起進(jìn)行了深入思考和討論,給出了幾個(gè)很有潛力的未來(lái)方向,供大家參考。
附華為諾亞方舟實(shí)驗(yàn)室 Transformer 系列工作:
NLP 大模型盤(pán)古 Alpha:https://arxiv.org/abs/2104.12369
中文預(yù)訓(xùn)練模型哪吒:https://arxiv.org/abs/1909.00204
輕量模型 TinyBERT:https://arxiv.org/abs/1909.10351
底層視覺(jué) IPT:https://arxiv.org/abs/2012.00364
多模態(tài) - 悟空:https://arxiv.org/abs/2111.07783
骨干網(wǎng)絡(luò)架構(gòu) TNT:https://arxiv.org/abs/2103.00112
骨干網(wǎng)絡(luò)
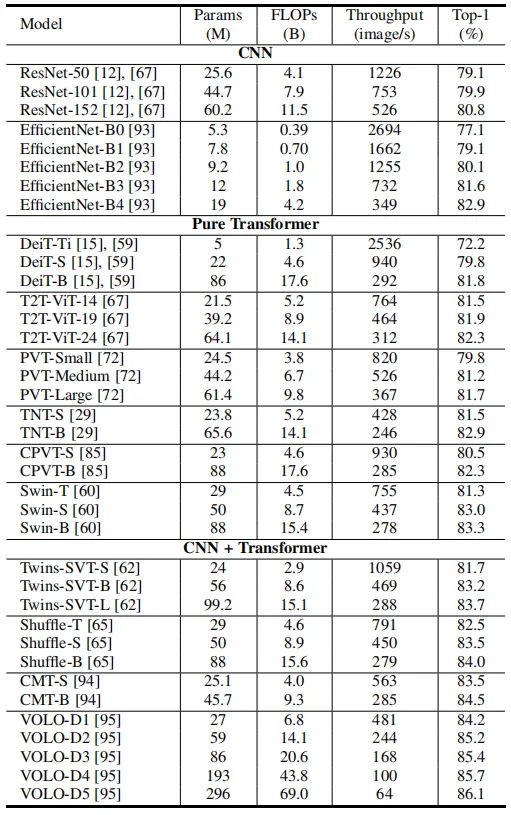
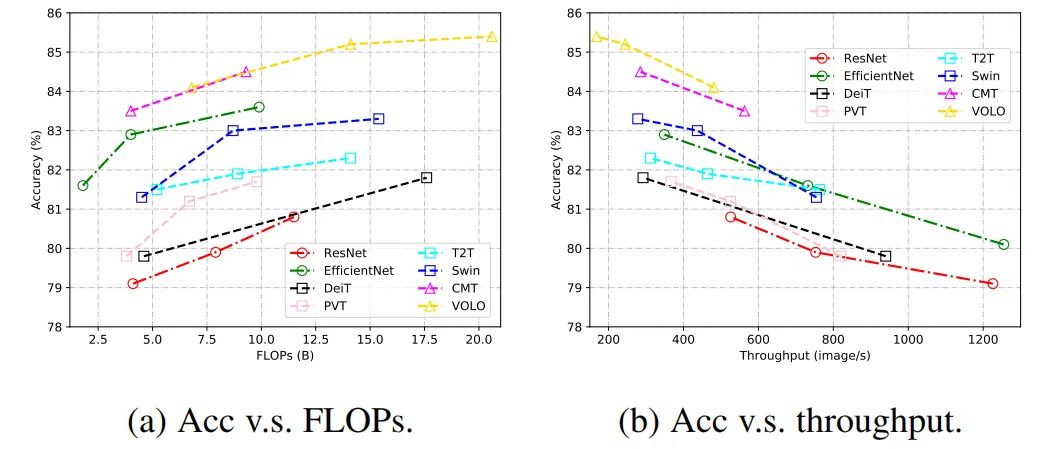
視覺(jué) Transformer 的所有組件,包括多頭自注意力、多層感知機(jī)、殘差連接、層歸一化、位置編碼和網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),在視覺(jué)識(shí)別中起著關(guān)鍵作用。為了提高視覺(jué) transformer 的精度和效率,業(yè)界已經(jīng)提出了許多模型。下表總結(jié)了視覺(jué) Transformer 骨干網(wǎng)絡(luò)的結(jié)果,可以更好分析現(xiàn)有網(wǎng)絡(luò)的發(fā)展趨勢(shì)。從圖 2 中的結(jié)果可以看出,將 CNN 和 Transformer 結(jié)合起來(lái)可以獲得更好的性能,這表明卷積的局部連接和注意力的全局連接能夠相互補(bǔ)充。
目標(biāo)檢測(cè)
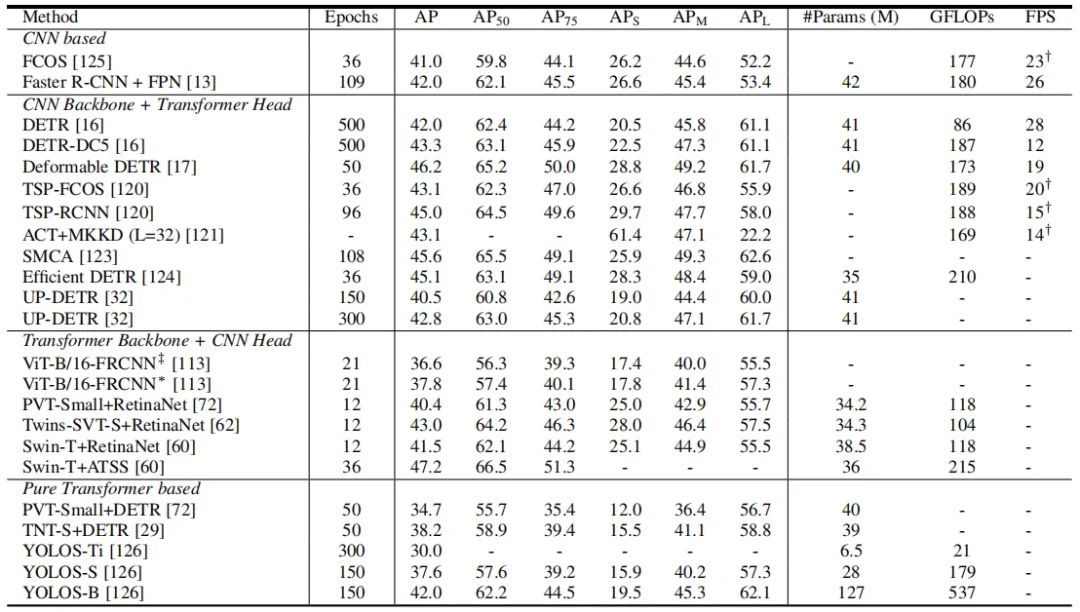
基于 Transformer 的目標(biāo)檢測(cè)方法也引起了廣泛的興趣,這些方法大致可以分為兩類(lèi):基于 Transformer 的檢測(cè)集合預(yù)測(cè)方法和基于 Transformer 骨干網(wǎng)絡(luò)的檢測(cè)方法。與基于 CNN 的檢測(cè)器相比,基于 Transformer 的方法在準(zhǔn)確性和運(yùn)行速度方面都表現(xiàn)出了強(qiáng)大的性能。表 3 展示了在 COCO 數(shù)據(jù)集上基于 Transformer 的不同目標(biāo)檢測(cè)器的性能。
將 Transformer 用于中高層視覺(jué)任務(wù),在輸入 embedding、位置編碼、損失函數(shù)以及整體架構(gòu)設(shè)計(jì)等方面都有較多的探索空間。一些現(xiàn)有方法從不同角度改進(jìn)自注意力模塊,如變形注意力機(jī)制和自適應(yīng)聚類(lèi)。盡管如此,利用 Transformer 來(lái)解決中高層視覺(jué)任務(wù)的探索仍處于初步階段,需要整個(gè)業(yè)界進(jìn)一步的研究。例如,在 Transformer 之前是否有必要使用 CNN 或 PointNet 等特征提取模塊以獲得更好的性能?如何像 BERT 和 GPT-3 在 NLP 領(lǐng)域所做的那樣,使用大規(guī)模的預(yù)訓(xùn)練數(shù)據(jù)充分利用 Transformer 的特性?如何通過(guò)結(jié)合特定任務(wù)的先驗(yàn)知識(shí)來(lái)設(shè)計(jì)更強(qiáng)大的體系結(jié)構(gòu)?之前的一些工作已經(jīng)對(duì)上述問(wèn)題進(jìn)行了初步討論,期待有更多研究來(lái)探索更強(qiáng)大的視覺(jué) Transformer。除了目標(biāo)檢測(cè),Transformer 還被應(yīng)用于其他中高層視覺(jué)任務(wù),如圖像分割、人體姿態(tài)估計(jì)、目標(biāo)跟蹤等,詳細(xì)內(nèi)容可參考原論文。
底層視覺(jué)
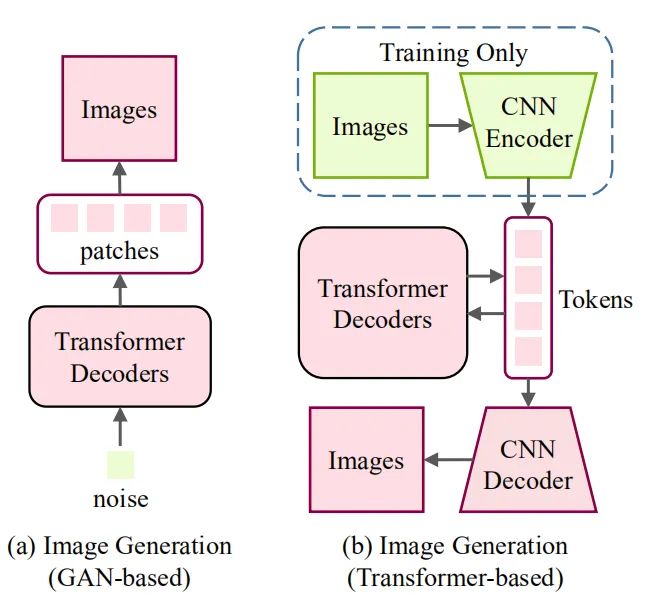
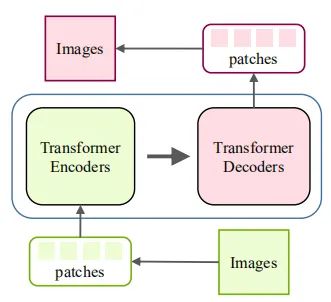
底層視覺(jué)是計(jì)算機(jī)視覺(jué)領(lǐng)域的一個(gè)重要問(wèn)題,如圖像超分辨率和圖像生成等,而目前也有一些工作來(lái)研究如何將 Transformer 應(yīng)用于底層視覺(jué)中來(lái)。這些任務(wù)通常將圖像作為輸出(高分辨率或去噪圖像),這比分類(lèi)、分割和檢測(cè)等高層視覺(jué)任務(wù)(輸出是標(biāo)簽或框)更具挑戰(zhàn)性。圖 3 和圖 4 展示了在底層視覺(jué)中使用 Transformer 的方式。在圖像處理任務(wù)中,首先將圖像編碼為一系列 token,Transformer 編碼器使用該序列作為輸入,進(jìn)而用 Transformer 解碼器生成所需圖像。在圖像生成任務(wù)中,基于 GAN 的模型直接學(xué)習(xí)解碼器生成的 token,通過(guò)線(xiàn)性映射輸出圖像,而基于 Transformer 的模型訓(xùn)練自編碼器學(xué)習(xí)圖像的碼本,并使用自回歸 Transformer 模型預(yù)測(cè)編碼的 token。而一個(gè)有意義的未來(lái)研究方向是為不同的圖像處理任務(wù)設(shè)計(jì)合適的網(wǎng)絡(luò)架構(gòu)。
多模態(tài)
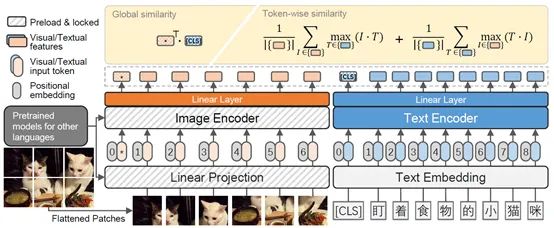
許多研究開(kāi)始熱衷于挖掘 Transformer 在處理多模態(tài)任務(wù)(如視頻 - 文本、圖像 - 文本和音頻 - 文本)的潛力。CLIP 是其中影響力較大的一個(gè)工作, 其將自然語(yǔ)言作為監(jiān)督信號(hào),來(lái)學(xué)習(xí)更有效的圖像表示。CLIP 使用大量文本圖像對(duì)來(lái)聯(lián)合訓(xùn)練文本編碼器和圖像編碼器。CLIP 的文本編碼器是一個(gè)標(biāo)準(zhǔn)的 Transformer,具有 mask 的自注意力層;對(duì)于圖像編碼器,CLIP 考慮了兩種類(lèi)型的架構(gòu):ResNet 和視覺(jué) Transformer。CLIP 在一個(gè)新采集的數(shù)據(jù)集上進(jìn)行訓(xùn)練,該數(shù)據(jù)集包含從互聯(lián)網(wǎng)上收集的 4 億對(duì)圖像 - 文本對(duì)。CLIP 展示了驚人的零樣本分類(lèi)性能,在 ImageNet-1K 數(shù)據(jù)集上實(shí)現(xiàn)了 76.2% top-1 精度,而無(wú)需使用任何 ImageNet 訓(xùn)練標(biāo)簽。華為諾亞的悟空(英文名:FILIP)模型使用雙塔架構(gòu)構(gòu)建圖文表征,取得了更好的效果,如圖 5 所示。總之,基于 transformer 的多模態(tài)模型在統(tǒng)一各種模態(tài)的數(shù)據(jù)和任務(wù)方面顯示出了其架構(gòu)優(yōu)勢(shì),這表明了 transformer 具備構(gòu)建一個(gè)能夠處理大量應(yīng)用的通用智能代理的潛力。
高效 Transformer
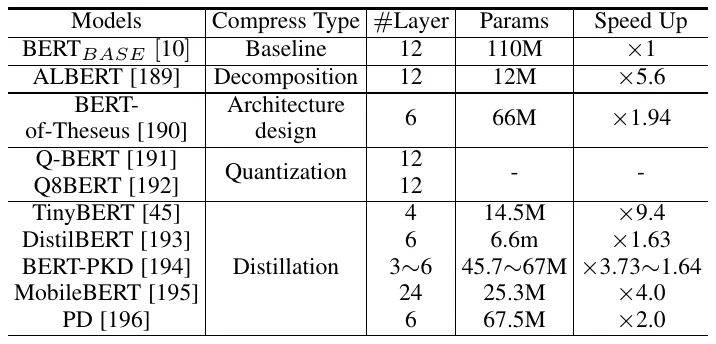
盡管 Transformer 模型在各種任務(wù)中取得了成功,但它們對(duì)內(nèi)存和計(jì)算資源的高要求阻礙了它們?cè)诙藗?cè)設(shè)備(如手機(jī))上的部署。文章還回顧了為高效部署而對(duì) Transformer 模型進(jìn)行壓縮和加速的研究,這包括網(wǎng)絡(luò)剪枝、低秩分解、知識(shí)蒸餾、網(wǎng)絡(luò)量化和緊湊結(jié)構(gòu)設(shè)計(jì)。表 4 列出了一些壓縮 Transformer 模型的代表性工作,這些工作采用不同的方法來(lái)識(shí)別 Transformer 模型中的冗余。具體來(lái)說(shuō),剪枝側(cè)重于減少 Transformer 模型中組件(例如,層、頭)的數(shù)量,而分解將原始矩陣表示為多個(gè)小矩陣。緊湊模型也可以直接手動(dòng)(需要足夠的專(zhuān)業(yè)知識(shí))或自動(dòng)(例如通過(guò) NAS)設(shè)計(jì)來(lái)得到。
未來(lái)展望
作為一篇綜述論文,對(duì)所探究的領(lǐng)域未來(lái)方向的牽引也是非常重要的。本文的最后,也為大家提供了幾個(gè)有潛力并且很重要的方向:
業(yè)界流行有各種類(lèi)型的神經(jīng)網(wǎng)絡(luò),如 CNN、RNN 和 Transformer。在 CV 領(lǐng)域,CNN 曾經(jīng)是主流選擇,但現(xiàn)在 Transformer 變得越來(lái)越流行。CNN 可以捕捉歸納偏置,如平移等變和局部性,而 ViT 使用大規(guī)模訓(xùn)練來(lái)超越歸納偏置。從現(xiàn)有的觀察來(lái)看,CNN 在小數(shù)據(jù)集上表現(xiàn)良好,而 Transformer 在大數(shù)據(jù)集上表現(xiàn)更好。而在視覺(jué)任務(wù)中,究竟是使用 CNN 還是 Transformer,或者兼二者之所長(zhǎng),是一個(gè)值得探究的問(wèn)題。
大多數(shù)現(xiàn)有的視覺(jué) Transformer 模型設(shè)計(jì)為只處理一項(xiàng)任務(wù),而許多 NLP 模型,如 GPT-3,已經(jīng)演示了 Transformer 如何在一個(gè)模型中處理多項(xiàng)任務(wù)。CV 領(lǐng)域的 IPT 能夠處理多個(gè)底層視覺(jué)任務(wù),例如超分辨率、圖像去雨和去噪。Perceiver 和 Perceiver IO 也是可以在多個(gè)領(lǐng)域工作的 Transformer 模型,包括圖像、音頻、多模態(tài)和點(diǎn)云。將所有視覺(jué)任務(wù)甚至其他任務(wù)統(tǒng)一到一個(gè) Transformer(即一個(gè)大統(tǒng)一模型)中是一個(gè)令人興奮的課題。
另一個(gè)方向是開(kāi)發(fā)高效的視覺(jué) Transformer;具體來(lái)說(shuō),如果讓 Transformer 具有更高精度和更低資源消耗。性能決定了該模型是否可以應(yīng)用于現(xiàn)實(shí)世界的應(yīng)用,而資源成本則影響其在硬件設(shè)備上的部署。而通常精度與資源消耗息息相關(guān),因此確定如何在兩者之間實(shí)現(xiàn)更好的平衡是未來(lái)研究的一個(gè)有意義的課題。
通過(guò)使用大量數(shù)據(jù)進(jìn)行訓(xùn)練,Transformer 可以在 NLP 和 CV 不同任務(wù)上得到領(lǐng)先的性能。最后,文章還留下一個(gè)問(wèn)題:Transformer 能否通過(guò)更簡(jiǎn)單的計(jì)算范式和大量數(shù)據(jù)訓(xùn)練獲得令人滿(mǎn)意的結(jié)果?
公眾號(hào)后臺(tái)回復(fù)“數(shù)據(jù)集”獲取30+深度學(xué)習(xí)數(shù)據(jù)集下載~

#?CV技術(shù)社群邀請(qǐng)函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
