來源:EMNLP
編輯:小咸魚
【新智元導(dǎo)讀】10月29日,EMNLP 2021會議公布了多個獎項:包括最佳長論文獎、最佳短論文獎、優(yōu)秀論文獎和最佳Demo獎。華人學(xué)者劉方宇、楊子小帆分別是最佳長論文的一作作者和最佳短論文的一作作者。
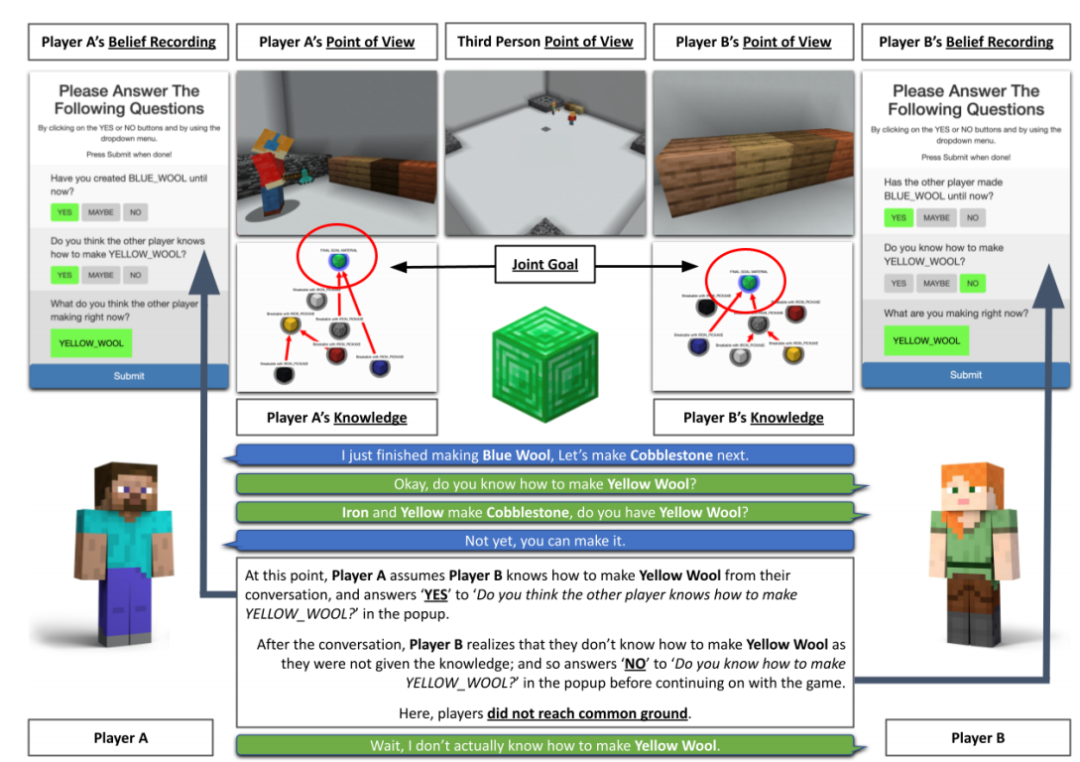
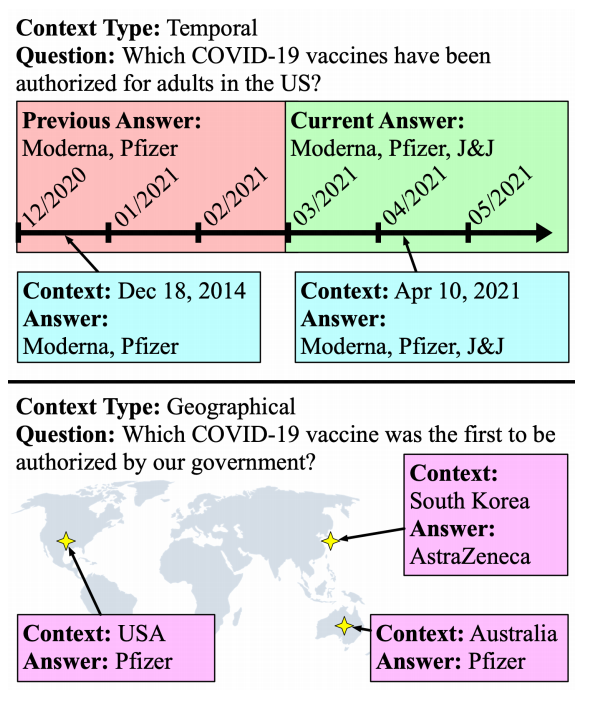
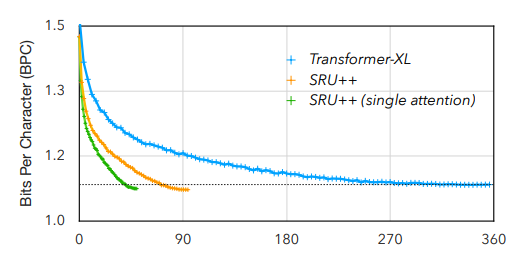
10月29日,EMNLP 2021會議公布了多個獎項:包括最佳長論文獎、最佳短論文獎、優(yōu)秀論文獎和最佳Demo獎。值得欣喜的是,中國學(xué)者收獲頗豐,最佳長論文的一作劉方宇和最佳短論文的一作楊子小帆都是華人學(xué)者。Visually Grounded Reasoning across Languages and Cultures論文地址:https://arxiv.org/ftp/arxiv/papers/2109/2109.13238.pdf劉方宇,本文的一作作者,2020年在滑鐵盧大學(xué)取得計算語言學(xué)碩士學(xué)位,目前正在劍橋大學(xué)語言技術(shù)實驗室攻讀博士,現(xiàn)在是博士二年級,師從Nigel Collier教授。個人主頁:http://fangyuliu.me/about劉方宇三個主要的研究方向是:多模態(tài)(將語言與知識和感知聯(lián)系起來)、自監(jiān)督(研究沒有人類標(biāo)簽的語言模型)、可解釋性(在預(yù)訓(xùn)練的模型權(quán)重中編碼/缺失了什么?)目前,ImageNet的概念和圖像被應(yīng)用于很多視覺和語言數(shù)據(jù)集以及預(yù)訓(xùn)練編碼器的設(shè)計,或者或多或少會從ImageNet中吸取靈感。但是,人們很難察覺,ImageNet基準(zhǔn)對計算機(jī)視覺進(jìn)步的貢獻(xiàn)其實是被高估了,因為ImageNet主要都是選自于英文數(shù)據(jù)庫和英文圖像查詢,這就會導(dǎo)致數(shù)據(jù)源材料帶有不少北美或西歐的偏見。經(jīng)驗和理論分析表明,在現(xiàn)有的視覺語言數(shù)據(jù)集中記錄的概念和圖像,在許多不同于英語的語言中以及在歐洲和北美以外的文化中,可能既不突出也不是原型。為了減輕這些偏見,他們設(shè)計了一個新的注釋協(xié)議,其中圖像和標(biāo)題的選擇完全由母語人士驅(qū)動。具體來說,他們用5種不同類型的語言(印度尼西亞語、漢語普通話、斯瓦希里語、泰米爾語和土耳其語)得出描述,比較和對比圖像對,建立了一個用于基礎(chǔ)語言推理的多元文化和多語言數(shù)據(jù)集MaRVL(Multicultural Reasoning over Vision and Language)及其注釋指南。研究人員使用最先進(jìn)的SoTA(state-of-the-art)模型在MaRVL上測試,結(jié)果發(fā)現(xiàn),與英語數(shù)據(jù)集相比,它們的表現(xiàn)僅僅略高于隨機(jī)水平,這與MaRVL中概念、圖像和語言的分布不均勻性有很大關(guān)系。這讓他們有理由相信,在狹窄的語言和文化領(lǐng)域之外,MaRVL通常能更忠實地評估最先進(jìn)的模型在現(xiàn)實應(yīng)用中的適用性。CHoRaL: Collecting Humor Reaction Labels from Millions of Social Media Users論文解說:https://underline.io/lecture/37879-choral-collecting-humor-reaction-labels-from-millions-of-social-media-users本文一作楊子小帆是蘋果公司的研究科學(xué)家。她最近在Julia Hirschberg教授的指導(dǎo)下完成了哥倫比亞大學(xué)的博士學(xué)位。她的研究興趣集中在計算副語言學(xué)和跨語言自然語言處理。此前,她在北京大學(xué)獲得計算機(jī)科學(xué)學(xué)士學(xué)位和經(jīng)濟(jì)學(xué)學(xué)士學(xué)位。近年來,由于用戶生成的具有比喻性語言的內(nèi)容越來越多,理解幽默這一領(lǐng)域受到了越來越多的重視。然而,在幽默的感知上,個體和文化差距讓具有可靠的幽默標(biāo)簽的大規(guī)模「幽默」數(shù)據(jù)集變得非常難收集。研究人員提出了CHoRaL,這是一個使用自然用戶對帖子的反應(yīng),而不需要手動注釋,就可以在Facebook帖子上生成感知幽默標(biāo)簽的框架。他們在與新冠肺炎相關(guān)的785000篇帖子上收集到了迄今為止最大的帶有幽默標(biāo)簽的數(shù)據(jù)集。此外,要分析與COVID相關(guān)的幽默在社交媒體中的表達(dá)時,通過從Facebook帖子中提取詞匯語義和情感特征,他們構(gòu)建了與人類相仿的幽默檢測模型。CHoRaL使任何話題的大規(guī)模幽默檢測模型的開發(fā)成為可能,并開辟了社交媒體上的幽默研究這一道路。論文1:MindCraft:Theory of Mind Modeling for Situated Dialogue in Collaborative Tasks論文地址:https://arxiv.org/pdf/2109.06275.pdf在現(xiàn)實世界與物理代理的協(xié)作場景中,人類和代理將不可避免地在能力、知識和對共享世界的理解上存在差異。這項工作引入了一個新的數(shù)據(jù)集和實驗框架,支持對協(xié)作任務(wù)中情境對話的思維建模理論的深入研究。通過在協(xié)作交互過程中自我報告信念狀態(tài)的新穎實現(xiàn),他們的數(shù)據(jù)集一步一步地跟蹤合作伙伴對手頭任務(wù)的信念以及彼此的信念,并捕獲他們的精神狀態(tài)如何演變。這是情境對話環(huán)境中的第一個數(shù)據(jù)集,它為心智建模提供了細(xì)粒度的信息。他們對這個數(shù)據(jù)集的初步分析產(chǎn)生了幾個有趣的發(fā)現(xiàn),這些發(fā)現(xiàn)將為各種問題的計算模型的開發(fā)提供信息。例如,在跟蹤心理模型和管理協(xié)作代理中的對話行為方面。他們的基線結(jié)果表明,在一個共享的環(huán)境中,交互對話和視覺體驗對于預(yù)測手頭任務(wù)的相互信念狀態(tài)以及與合作伙伴確保共同點(diǎn)的重要性。論文2:SituatedQA:Incorporating Extra-Linguistic Contexts into QA論文地址:https://arxiv.org/pdf/2109.06157.pdf該工作首次研究了語言外語境(例如時間地點(diǎn))是如何影響開放檢索問答的。他們的研究表明,當(dāng)前的系統(tǒng)無法適應(yīng)時間或地理環(huán)境的變化。因此,他們創(chuàng)建了一個數(shù)據(jù)集SituatedQA,用于訓(xùn)練和評估質(zhì)量保證系統(tǒng),這就要求系統(tǒng)必須在具體的時間和地點(diǎn)等語境下,生成正確答案,以此獲得對事實在不同環(huán)境中變化的建模能力。他們的數(shù)據(jù)集將支持未來開發(fā)模型的大量工作,這些模型可以基于新的時間和地理環(huán)境優(yōu)雅地更新其預(yù)測。未來的研究可能涉及整合時間和地理相關(guān)的源文檔,如新聞文章,或考慮其他語言外的背景,如誰在提問,同時考慮個人的偏好。論文3:When Attention Meets Fast Recurrence:Training Language Models with Reduced Compute?論文地址:https://arxiv.org/pdf/2102.12459.pdf該文提出了一種結(jié)合快速循環(huán)和自注意力的高效架構(gòu)SRU++,并在各種語言建模數(shù)據(jù)集上對SRU++進(jìn)行評估,包括ENWIK8、WIKI-103和BILLION WORD數(shù)據(jù)集。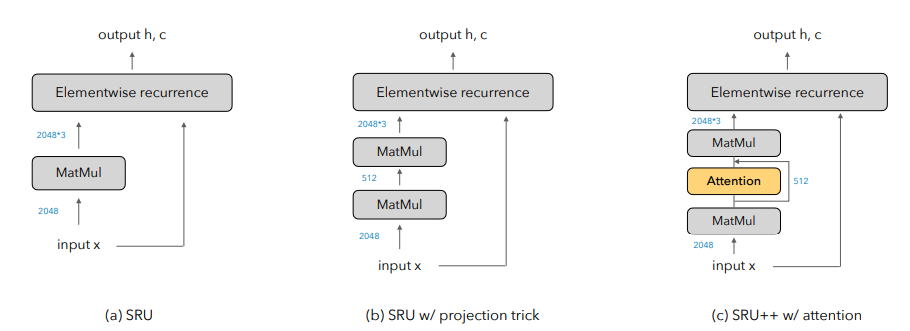 SRU和SRU++網(wǎng)絡(luò)示例
SRU和SRU++網(wǎng)絡(luò)示例
SRU++在這些數(shù)據(jù)集上始終優(yōu)于各種Transformer模型,提供了更好或不相上下的結(jié)果,同時使用的計算量減少了3-10倍,因為他們的模型不使用位置編碼、多頭注意力和其他對Transformer模型有用的技術(shù)。SRU++通過使用1/8的訓(xùn)練時長獲得了更好的BPC此外,他們證明了對于SRU++來說,幾個注意力層足以獲得接近最先進(jìn)的性能。這些結(jié)果不僅突出了循環(huán)的有效性,而且表明其能夠在訓(xùn)練和推理中大大減少計算量。論文4:Shortcutted Commonsense: Data Spuriousness in Deep Learning of Commonsense ReasoningGitHub地址:https://github.com/nlx-group/Shortcutted-Commonsense-Reasoning自人工智能誕生以來,常識,這一典型的人類基本能力,一直是人工智能的核心挑戰(zhàn)。Transformer在自然語言處理任務(wù)(包括常識推理)中取得了非常令人興奮的結(jié)果,甚至在某些基準(zhǔn)測試中匹配或超過了人類的表現(xiàn)。不過最近,Transformer的進(jìn)步受到了一些質(zhì)疑,那是因為訓(xùn)練數(shù)據(jù)中的偽影已經(jīng)明顯表現(xiàn)出來,在某些情況下,Transformer正在利用這些虛假的相關(guān)性和膚淺的捷徑達(dá)到更優(yōu)的性能。在本文中,他們進(jìn)一步分析了與常識相關(guān)的語言處理任務(wù)領(lǐng)域,對涉及常識推理的不同突出基準(zhǔn)進(jìn)行了研究,從而尋求深入了解模型是在學(xué)習(xí)問題根本的可遷移信息,還是只是利用數(shù)據(jù)項中的捷徑。而所獲得的結(jié)果表明,大多數(shù)實驗數(shù)據(jù)集都是有問題的,因為模型依賴了非魯棒特征,并且沒有學(xué)習(xí)和概括數(shù)據(jù)集想要傳達(dá)或舉例說明的東西。Datasets: A Community Library for Natural Language Processing論文地址:https://arxiv.org/pdf/2109.02846.pdfHugging Face Datasets是一個開源的、社區(qū)驅(qū)動的庫,它將自然語言處理數(shù)據(jù)集的處理、分發(fā)和文檔標(biāo)準(zhǔn)化。核心庫設(shè)計為易于使用、快速,并且對不同大小的數(shù)據(jù)集使用相同的界面。來自超過250個貢獻(xiàn)者的650個數(shù)據(jù)集,使Hugging Face Datasets易于使用標(biāo)準(zhǔn)數(shù)據(jù)集,促進(jìn)了跨數(shù)據(jù)集自然語言處理的新用例,并具有索引和流式傳輸大型數(shù)據(jù)集等任務(wù)的高級功能。
參考資料:
https://2021.emnlp.org/blog/2021-10-29-best-paper-awards/