
多模態(tài)深度學(xué)習(xí)綜述:網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)和模態(tài)融合方法匯總
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
作者丨小奚每天都要學(xué)習(xí)@知乎 編輯丨極市平臺(tái)
來源丨h(huán)ttps://zhuanlan.zhihu.com/p/152234745
一、簡介
從2010年開始,深度學(xué)習(xí)方法為語音識(shí)別,圖像識(shí)別和自然語言處理領(lǐng)域帶來了巨大的變革。這些領(lǐng)域中的任務(wù)都只涉及單模態(tài)的輸入,但是最近更多的應(yīng)用都需要涉及到多種模態(tài)的智慧。多模態(tài)深度學(xué)習(xí)主要包含三個(gè)方面:多模態(tài)學(xué)習(xí)表征,多模態(tài)信號融合以及多模態(tài)應(yīng)用,而本文主要關(guān)注計(jì)算機(jī)視覺和自然語言處理的相關(guān)融合方法,包括網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)和模態(tài)融合方法(對于特定任務(wù)而言)。
二、多模態(tài)融合辦法
多模態(tài)融合是多模態(tài)研究中非常關(guān)鍵的研究點(diǎn),它將抽取自不同模態(tài)的信息整合成一個(gè)穩(wěn)定的多模態(tài)表征。多模態(tài)融合和表征有著明顯的聯(lián)系,如果一個(gè)過程是專注于使用某種架構(gòu)來整合不同單模態(tài)的表征,那么就被歸類于fusion類。而fusion方法又可以根據(jù)他們出現(xiàn)的不同位置而分為late和early fusion。因?yàn)樵缙诤屯砥谌诤蠒?huì)抑制模內(nèi)或者模間的交互作用,所以現(xiàn)在的研究主要集中于intermediate的融合方法,讓這些fusion操作可以放置于深度學(xué)習(xí)模型的多個(gè)層之中。而融合文本和圖像的方法主要有三種:基于簡單操作的,基于注意力的,基于張量的方法。
a) 簡單操作融合辦法
來自不同的模態(tài)的特征向量可以通過簡單地操作來實(shí)現(xiàn)整合,比如拼接和加權(quán)求和。這樣的簡單操作使得參數(shù)之間的聯(lián)系幾乎沒有,但是后續(xù)的網(wǎng)絡(luò)層會(huì)自動(dòng)對這種操作進(jìn)行自適應(yīng)。
l Concatenation拼接操作可以用來把低層的輸入特征[1][2][3]或者高層的特征(通過預(yù)訓(xùn)練模型提取出來的特征)[3][4][5]之間相互結(jié)合起來。
l Weighted sum 對于權(quán)重為標(biāo)量的加權(quán)求和方法,這種迭代的辦法要求預(yù)訓(xùn)練模型產(chǎn)生的向量要有確定的維度,并且要按一定順序排列并適合element-wise 加法[6]。為了滿足這種要求可以使用全連接層來控制維度和對每一維度進(jìn)行重新排序。
最近的一項(xiàng)研究[7]采用漸進(jìn)探索的神經(jīng)結(jié)構(gòu)搜索[8][9][10]來為fusion找到合適的設(shè)置。根據(jù)要融合的層以及是使用連接還是加權(quán)和作為融合操作來配置每個(gè)融合功能。
b) 基于注意力機(jī)制的融合辦法
很多的注意力機(jī)制已經(jīng)被應(yīng)用于融合操作了。注意力機(jī)制通常指的是一組“注意”模型在每個(gè)時(shí)間步動(dòng)態(tài)生成的一組標(biāo)量權(quán)重向量的加權(quán)和[11][12]。這組注意力的多個(gè)輸出頭可以動(dòng)態(tài)產(chǎn)生求和時(shí)候要用到的權(quán)重,因此最終在拼接時(shí)候可以保存額外的權(quán)重信息。在將注意機(jī)制應(yīng)用于圖像時(shí),對不同區(qū)域的圖像特征向量進(jìn)行不同的加權(quán),得到一個(gè)最終整體的圖像向量。
圖注意力機(jī)制
擴(kuò)展了用于文本問題處理的LSTM模型,加入了基于先前LSTM隱藏狀態(tài)的圖像注意模型,輸入為當(dāng)前嵌入的單詞和參與的圖像特征的拼接[13]。最終LSTM的隱藏狀態(tài)就被用于一種多模態(tài)的融合的表征,從而被應(yīng)用于VQA問題之中。這種基于RNN的encoder-decoder模型被用來給圖像特征分配權(quán)重從而做image caption任務(wù)[14]。此外,對于VQA視覺問答任務(wù),attention模型還能通過文本query來找到圖像對應(yīng)得位置[15]。同樣,堆疊注意力網(wǎng)絡(luò)(SANs)也被提出使用多層注意力模型對圖像進(jìn)行多次查詢,逐步推斷出答案,模擬了一個(gè)多步驟的推理過程[16]。通過多次迭代實(shí)現(xiàn)圖像區(qū)域的Attention。首先根據(jù)圖像特征和文本特征生成一個(gè)特征注意分布,根據(jù)這個(gè)分布得到圖像每個(gè)區(qū)域權(quán)重和Vi,根據(jù)u=Vi+Vq得到一個(gè)refine query向量。將這個(gè)過程
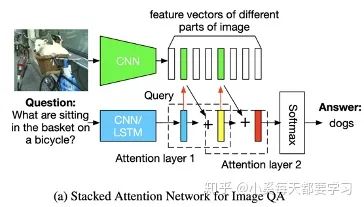
多次迭代最終注意到問題相關(guān)區(qū)域。當(dāng)然和san很像的還有[17]。
一種動(dòng)態(tài)記憶網(wǎng)絡(luò)也被升級了并用來分別編碼問題和圖像。這種網(wǎng)絡(luò)則使用了基于attention的GRUs來更新情景記憶和檢索所需信息[18]。
自底向上和自頂向下的注意方法(Up-Down),顧名思義,通過結(jié)合兩種視覺注意機(jī)制來模擬人類的視覺系統(tǒng)[19].自下而上的注意力機(jī)制是通過使用目標(biāo)檢測算法(如faster rcnn)來首先挑選出一些列的圖像候選區(qū)域,而自上而下的注意力機(jī)制則是要把視覺信息和語義特征拼接從而生成一個(gè)帶有注意力的圖像特征向量,最終服務(wù)于圖像描述和VQA任務(wù)。同時(shí),帶有注意力的圖像特征向量還可以和文本向量進(jìn)行點(diǎn)乘。來自不同模型(resnet和faster rcnn)的互補(bǔ)圖像特征也可以被用于多種圖像注意力機(jī)制[20]。更進(jìn)一步,圖像注意力機(jī)制的逆反應(yīng)用,可以從輸入的圖像+文本來生成文本特征,還可以用于文本生成圖像的任務(wù)[21]。
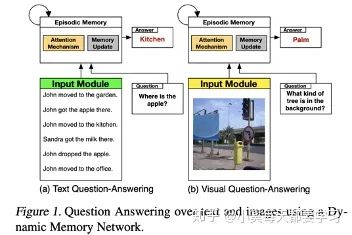
圖和文本的對稱注意力機(jī)制
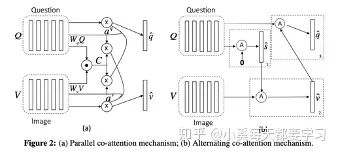
與上述圖像注意機(jī)制不同,共注意機(jī)制使用對稱注意力結(jié)構(gòu)生成attended圖像特征向量和attended語言向量[22]。平行共注意力機(jī)制采用聯(lián)合表示的方法模擬推導(dǎo)出圖像和語言的注意分布。交替共同注意力機(jī)制具有級聯(lián)結(jié)構(gòu),首先使用語言特征生成含有注意力的圖像向量,然后使用含有注意力的圖像向量生成出含注意力的語言向量。
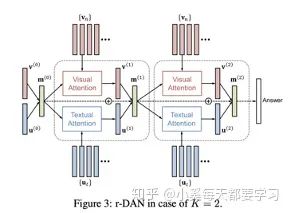
和平行共注意力機(jī)制類似,雙注意力網(wǎng)絡(luò)(DAN)同時(shí)估計(jì)圖像和文本的注意力分布從而獲得最后的注意力特征向量[23]。這種注意模型以特征和與相關(guān)模式相關(guān)的記憶向量為條件。與共同注意相比,這是一個(gè)關(guān)鍵的區(qū)別,因?yàn)橛洃浵蛄靠梢允褂弥貜?fù)的DAN結(jié)構(gòu)在每個(gè)推理步驟中迭代更新。
堆疊的latent attention (SLA)改進(jìn)了SAN,它把圖像的原始特征和網(wǎng)絡(luò)淺層的向量連接,以保存中間推理階段的潛在信息[24]。當(dāng)然還包括一種類似雙流的并行共注意結(jié)構(gòu),用于同時(shí)注意圖像和語言特征,這便于使用多個(gè)SLA層進(jìn)行迭代推理。雙遞歸注意單元利用文本和圖像的LSTM模型實(shí)現(xiàn)了一個(gè)并行的共注意結(jié)構(gòu),在使用CNN層堆棧卷積圖像特征得到的表示中為每個(gè)輸入位置分配注意權(quán)值[25]。為了模擬兩種數(shù)據(jù)模式之間的高階交互作用,可以將兩種數(shù)據(jù)模式之間的高階相關(guān)性作為兩種特征向量的內(nèi)積來計(jì)算,從而得到兩種模式的交互的注意力特征向量[26]。
雙模的transformer的注意力機(jī)制
這部分主要是基于BERT的變體,采用雙流輸入embedding方法,然后再后續(xù)的共注意力層中進(jìn)行交互。
其他類似注意力的機(jī)制
門控多模態(tài)單元是一種基于門控的方法,可以看作是為圖像和文本分配注意權(quán)重[27]。該方法是基于門控機(jī)制動(dòng)態(tài)生成的維度特定標(biāo)量權(quán)重,計(jì)算視覺特征向量和文本特征向量的加權(quán)和。類似的,向量按位乘法可以用于融合視覺和文本表達(dá)。然后將這些融合的表示方法用于構(gòu)建基于深度殘差學(xué)習(xí)的多模態(tài)殘差網(wǎng)絡(luò)[27]。還有就是動(dòng)態(tài)參數(shù)預(yù)測網(wǎng)絡(luò),它采用動(dòng)態(tài)權(quán)值矩陣來變換視覺特征向量,其參數(shù)由文本特征向量哈希動(dòng)態(tài)生成[28]。
c) 基于雙線性池化的融合辦法
雙線性池化主要用于融合視覺特征向量和文本特征向量來獲得一個(gè)聯(lián)合表征空間,方法是計(jì)算他們倆的外積,這種辦法可以利用這倆向量元素的所有的交互作用,也被稱作second-order pooling[30]。和簡單地向量組合操作(假設(shè)每個(gè)模態(tài)的特征向量有n個(gè)元素)不一樣的是,簡單操作(如加權(quán)求和,按位操作,拼接)都會(huì)生成一個(gè)n或者2n維度的表征向量,而雙線性池化則會(huì)產(chǎn)生一個(gè)n平方維度的表征。通過將外積生成的矩陣線性化成一個(gè)向量表示,這意味著這種方法更有表現(xiàn)力。雙線性表示方法常常通過一個(gè)二維權(quán)重矩陣來轉(zhuǎn)化為相應(yīng)的輸出向量,也等價(jià)于使用一個(gè)三維的tensor來融合兩個(gè)輸入向量。在計(jì)算外積時(shí),每個(gè)特征向量可以加一個(gè)1,以在雙線性表示中保持單模態(tài)輸入特征[32]。然而,基于它的高維數(shù)(通常是幾十萬到幾百萬維的數(shù)量級),雙線性池通常需要對權(quán)值張量進(jìn)行分解,才可以適當(dāng)和有效地訓(xùn)練相關(guān)的模型。
雙線性池化的因式分解
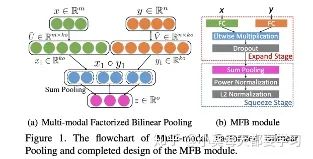
由于雙線性出來的表征與多項(xiàng)式核密切相關(guān),因此可以利用各種低維近似來獲得緊的雙線性表示[32]。Count sketch和卷積能夠用來近似多項(xiàng)式核[33][34],從而催生出了多模態(tài)緊湊雙線性池化multimodal compact bilinear pooling MCB[35]。或者,通過對權(quán)值張量施加低秩控制,多模態(tài)低秩雙線性池(MLB)將雙線性池的三維權(quán)值張量分解為三個(gè)二維權(quán)值矩陣[36]。具體的來說,視覺和文字特征向量通過兩個(gè)輸入因子矩陣線性投影到低維矩陣上。然后使用按元素的乘法將這些因子融合,然后使用第三個(gè)矩陣對輸出因子進(jìn)行線性投影。多模態(tài)因子分解雙線性池化Multimodal factorized bilinear pooling (MFB)對MLB進(jìn)行了修改,通過對每個(gè)非重疊的一維窗口內(nèi)的值求和,將元素間的乘法結(jié)果集合在一起[37]。多個(gè)MFB模型可以級聯(lián)來建模輸入特性之間的高階交互,這被稱為多模態(tài)因數(shù)化高階池(MFH)[38]。
MUTAN是一種基于多模態(tài)張量的Tucker decomposition方法,使用Tucker分解[39]將原始的三維權(quán)量張量算子分解為低維核心張量和MLB使用的三個(gè)二維權(quán)量矩陣[40]。核心張量對不同形式的相互作用進(jìn)行建模。MCB可以看作是一個(gè)具有固定對角輸入因子矩陣和稀疏固定核張量的MUTAN, MLB可以看作是一個(gè)核張量為單位張量的MUTAN。
而最新的AAAI2019提出了BLOCK,是一個(gè)基于塊的超對角陣的融合框架[41],是為了塊項(xiàng)的消解和合成[42]。BLOCK將MUTAN泛化為多個(gè)MUTAN模型的總和,為模式之間的交互提供更豐富的建模。此外,雙線性池化可以推廣到兩種以上的modality,例如使用外積來建模視頻、音頻和語言表示之間的交互[43]。
雙線性池化和注意力機(jī)制
雙線性池化和注意力機(jī)制也可以進(jìn)行結(jié)合。MCB/MLB融合的雙模態(tài)表示可以作為注意力模型的輸入特征,得到含有注意力的圖像特征向量,然后再使用MCB/MLB與文本特征向量融合,形成最終的聯(lián)合表示[44][45]。MFB/MFH可用于交替的共同注意學(xué)習(xí)聯(lián)合表示[46][47]。
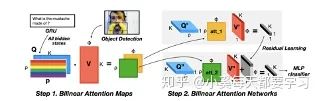
雙線性注意網(wǎng)絡(luò)(BAN)利用MLB融合圖像和文本,生成表示注意力分布的雙線性注意圖,并將其作為權(quán)重張量進(jìn)行雙線性pooling,再次融合圖像和文本特征[48]。
三、總結(jié)
近年來最主要的多模態(tài)融合辦法就是基于attention的和基于雙線性池化的方法。其中雙線性池化的數(shù)學(xué)有效性方面還可以有很大的提升空間。
Zhang, C., Yang, Z., He, X., & Deng, L. (2020). Multimodal intelligence: Representation learning, information fusion, and applications.IEEE Journal of Selected Topics in Signal Processing.
參考文獻(xiàn):
個(gè)人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2020
在「AI算法與圖像處理」公眾號后臺(tái)回復(fù):CVPR2020,即可下載1467篇CVPR 2020論文
覺得不錯(cuò)就點(diǎn)亮在看吧
