
【實(shí)戰(zhàn)】用Python進(jìn)行10w+QQ說說數(shù)據(jù)分析
Doctor?| 作者
對(duì)編程沒有興趣的朋友可以直接看后面的數(shù)據(jù)分析結(jié)果。
開發(fā)環(huán)境:win7下的python3.5、MySQL5.7
編輯器:pycharm2017.1、ipython,Navicat for mysql
需要的python第三方庫(kù):selenium、PIL、Requests、MySQLdb、csv、pandas、numpy、matplotlib、jieba、wordcloud另外還用到了無頭瀏覽器PhantomJS。
主要思路:
通過selenium+phantomjs模擬登錄qq空間取到cookies和g_qzonetoken,并算出gtk
通過Requests庫(kù)利用前面得到的url參數(shù),構(gòu)造http請(qǐng)求
分析請(qǐng)求得到的響應(yīng),是一個(gè)json,利用正則表達(dá)式提取字段
設(shè)計(jì)數(shù)據(jù)表,并將提取到的字段插入到數(shù)據(jù)庫(kù)中?
通過qq郵箱中的導(dǎo)出聯(lián)系人功能,把好友的qq號(hào)導(dǎo)出到一個(gè)csv文件,遍歷所有的qq號(hào)爬取所有的說說
通過sql查詢和ipython分析數(shù)據(jù),并將數(shù)據(jù)可視化
通過python的第三方庫(kù)jieba、wordcloud基于說說的內(nèi)容做一個(gè)詞云?
閑話不多說,直接上代碼。
通過selenium+phantomjs模擬登錄qq空間取到cookies和g_qzonetoken,并算出gtk
import?re
from?selenium import?webdriver
from?time import?sleep
from?PIL import?Image
#定義登錄函數(shù)
def?QR_login():
????def?getGTK(cookie):
????????""" 根據(jù)cookie得到GTK """
????????hashes = 5381
????????for?letter in?cookie['p_skey']:
????????????hashes += (hashes << 5) + ord(letter)
return?hashes & 0x7fffffff
????browser=webdriver.PhantomJS(executable_path="D:\phantomjs.exe")#這里要輸入你的phantomjs所在的路徑
????url="https://qzone.qq.com/"#QQ登錄網(wǎng)址
????browser.get(url)
????browser.maximize_window()#全屏
????sleep(3)#等三秒
????browser.get_screenshot_as_file('QR.png')#截屏并保存圖片
????im = Image.open('QR.png')#打開圖片
????im.show()#用手機(jī)掃二維碼登錄qq空間
????sleep(20)#等二十秒,可根據(jù)自己的網(wǎng)速和性能修改
????print(browser.title)#打印網(wǎng)頁(yè)標(biāo)題
????cookie = {}#初始化cookie字典
????for?elem in?browser.get_cookies():#取cookies
????????cookie[elem['name']] = elem['value']
print('Get the cookie of QQlogin successfully!(共%d個(gè)鍵值對(duì))'?% (len(cookie)))
????html = browser.page_source#保存網(wǎng)頁(yè)源碼
????g_qzonetoken=re.search(r'window\.g_qzonetoken = \(function\(\)\{ try\{return (.*?);\} catch\(e\)',html)#從網(wǎng)頁(yè)源碼中提取g_qzonetoken
????gtk=getGTK(cookie)#通過getGTK函數(shù)計(jì)算gtk
????browser.quit()
return?(cookie,gtk,g_qzonetoken.group(1))
if?__name__=="__main__":
????QR_login()通過Requests庫(kù)利用前面得到的url參數(shù),構(gòu)造http請(qǐng)求:
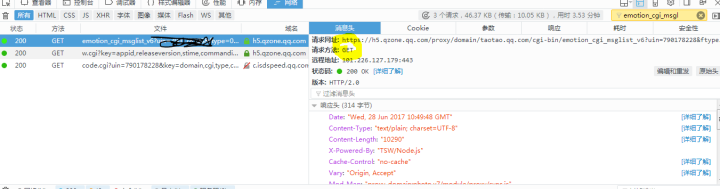

通過抓包分析可以找到上圖這個(gè)請(qǐng)求,這個(gè)請(qǐng)求響應(yīng)的是說說信息?。

通過火狐瀏覽器的一個(gè)叫json-dataview的插件可以看到這個(gè)響應(yīng)是一個(gè)json格式的,開心!
然后就是用正則表達(dá)式提取字段了,這個(gè)沒什么意思,直接看我的代碼吧:
def?parse_mood(i):
????'''從返回的json中,提取我們想要的字段'''
????text = re.sub('"commentlist":.*?"conlist":', '', i)
if?text:
????????myMood = {}
????????myMood["isTransfered"] = False
????????tid = re.findall('"t1_termtype":.*?"tid":"(.*?)"', text)[0] # 獲取說說ID
????????tid = qq + '_'?+ tid
????????myMood['id'] = tid
????????myMood['pos_y'] = 0
????????myMood['pos_x'] = 0
????????mood_cont = re.findall('\],"content":"(.*?)"', text)
if?re.findall('},"name":"(.*?)",', text):
????????????name = re.findall('},"name":"(.*?)",', text)[0]
????????????myMood['name'] = name
if?len(mood_cont) == 2: # 如果長(zhǎng)度為2則判斷為屬于轉(zhuǎn)載
????????????myMood["Mood_cont"] = "評(píng)語:"?+ mood_cont[0] + "--------->轉(zhuǎn)載內(nèi)容:"?+ mood_cont[1] # 說說內(nèi)容
????????????myMood["isTransfered"] = True
????????elif?len(mood_cont) == 1:
????????????myMood["Mood_cont"] = mood_cont[0]
else:
????????????myMood["Mood_cont"] = ""
????????if?re.findall('"created_time":(\d+)', text):
????????????created_time = re.findall('"created_time":(\d+)', text)[0]
????????????temp_pubTime = datetime.datetime.fromtimestamp(int(created_time))
????????????temp_pubTime = temp_pubTime.strftime("%Y-%m-%d %H:%M:%S")
????????????dt = temp_pubTime.split(' ')
????????????time = dt[1]
????????????myMood['time'] = time
????????????date = dt[0]
????????????myMood['date'] = date
if?re.findall('"source_name":"(.*?)"', text):
????????????source_name = re.findall('"source_name":"(.*?)"', text)[0] # 獲取發(fā)表的工具(如某手機(jī))
????????????myMood['tool'] = source_name
if?re.findall('"pos_x":"(.*?)"', text):#獲取經(jīng)緯度坐標(biāo)
????????????pos_x = re.findall('"pos_x":"(.*?)"', text)[0]
????????????pos_y = re.findall('"pos_y":"(.*?)"', text)[0]
if?pos_x:
????????????????myMood['pos_x'] = pos_x
if?pos_y:
????????????????myMood['pos_y'] = pos_y
????????????idname = re.findall('"idname":"(.*?)"', text)[0]
????????????myMood['idneme'] = idname
????????????cmtnum = re.findall('"cmtnum":(.*?),', text)[0]
????????????myMood['cmtnum'] = cmtnum
return?myMood#返回一個(gè)字典我們想要的東西已經(jīng)提取出來了,接下來需要設(shè)計(jì)數(shù)據(jù)表,通過navicat可以很方便的建表,然后通過python連接mysql數(shù)據(jù)庫(kù),寫入數(shù)據(jù)。這是創(chuàng)建數(shù)據(jù)表的sql代碼:
CREATE?TABLE?`mood`?(
`name`?varchar(80) DEFAULT?NULL,
`date`?date?DEFAULT?NULL,
`content`?text,
`comments_num`?int(11) DEFAULT?NULL,
`time`?time?DEFAULT?NULL,
`tool`?varchar(255) DEFAULT?NULL,
`id`?varchar(255) NOT?NULL,
`sitename`?varchar(255) DEFAULT?NULL,
`pox_x`?varchar(30) DEFAULT?NULL,
`pox_y`?varchar(30) DEFAULT?NULL,
`isTransfered`?double?DEFAULT?NULL,
PRIMARY KEY?(`id`)
) ENGINE=InnoDB?DEFAULT?CHARSET=utf8;其實(shí)到這里爬蟲的主要的代碼就算完了,之后主要是通過QQ郵箱的聯(lián)系人導(dǎo)出功能,構(gòu)建url列表,最后等著它運(yùn)行完成就可以了。
這里我單線程爬200多個(gè)好友用了大約三個(gè)小時(shí),拿到了十萬條說說。下面是爬蟲的主體代碼:
#從csv文件中取qq號(hào),并保存在一個(gè)列表中
csv_reader = csv.reader(open('qq.csv'))
friend=[]
for?row in?csv_reader:
????friend.append(row[3])
friend.pop(0)
friends=[]
for?f in?friend:
????f=f[:-7]
????friends.append(f)
headers={
'Host': 'h5.qzone.qq.com',
????'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
????'Accept': '*/*',
????'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
????'Accept-Encoding': 'gzip, deflate, br',
????'Referer': 'https://user.qzone.qq.com/790178228?_t_=0.22746974226377736',
????'Connection':'keep-alive'
}#偽造瀏覽器頭
conn = MySQLdb.connect('localhost', 'root', '123456', 'qq_mood', charset="utf8", use_unicode=True)#連接mysql數(shù)據(jù)庫(kù)
cursor = conn.cursor()#定義游標(biāo)
cookie,gtk,qzonetoken=QRlogin#通過登錄函數(shù)取得cookies,gtk,qzonetoken
s=requests.session()#用requests初始化會(huì)話
for?qq in?friends:#遍歷qq號(hào)列表
????for?p in?range(0,1000):
????????pos=p*20
????????params={
'uin':qq,
????????'ftype':'0',
????????'sort':'0',
????????'pos':pos,
????????'num':'20',
????????'replynum':'100',
????????'g_tk':gtk,
????????'callback':'_preloadCallback',
????????'code_version':'1',
????????'format':'jsonp',
????????'need_private_comment':'1',
????????'qzonetoken':qzonetoken
????????}
????????response=s.request('GET','https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6',params=params,headers=headers,cookies=cookie)
print(response.status_code)#通過打印狀態(tài)碼判斷是否請(qǐng)求成功
????????text=response.text#讀取響應(yīng)內(nèi)容
????????if?not?re.search('lbs', text):#通過lbs判斷此qq的說說是否爬取完畢
????????????print('%s說說下載完成'% qq)
break
????????textlist = re.split('\{"certified"', text)[1:]
for?i in?textlist:
????????????myMood=parse_mood(i)
'''將提取的字段值插入mysql數(shù)據(jù)庫(kù),通過用異常處理防止個(gè)別的小bug中斷爬蟲,開始的時(shí)候可以先不用異常處理判斷是否能正常插入數(shù)據(jù)庫(kù)'''
????????????try:
????????????????insert_sql = '''
???????????????????????????insert into mood(id,content,time,sitename,pox_x,pox_y,tool,comments_num,date,isTransfered,name)
???????????????????????????VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
????????????????????????'''
????????????????cursor.execute(insert_sql, (myMood['id'],myMood["Mood_cont"],myMood['time'],myMood['idneme'],myMood['pos_x'],myMood['pos_y'],myMood['tool'],myMood['cmtnum'],myMood['date'],myMood["isTransfered"],myMood['name']))
????????????????conn.commit()
except:
????????????????pass
print('說說全部下載完成!')下面是爬取的數(shù)據(jù),有100878條!
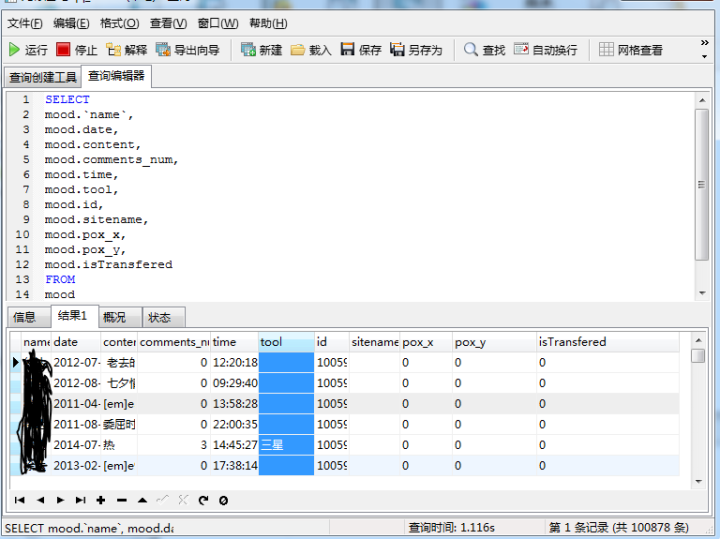
拿到數(shù)據(jù)后,我先用sql進(jìn)行聚合分析,然后通過ipython作圖,將數(shù)據(jù)可視化。
統(tǒng)計(jì)一年之中每天的說說數(shù)目,可以發(fā)現(xiàn)每年除夕這一天是大家發(fā)說說最多的一天(統(tǒng)計(jì)了2013到2017年)
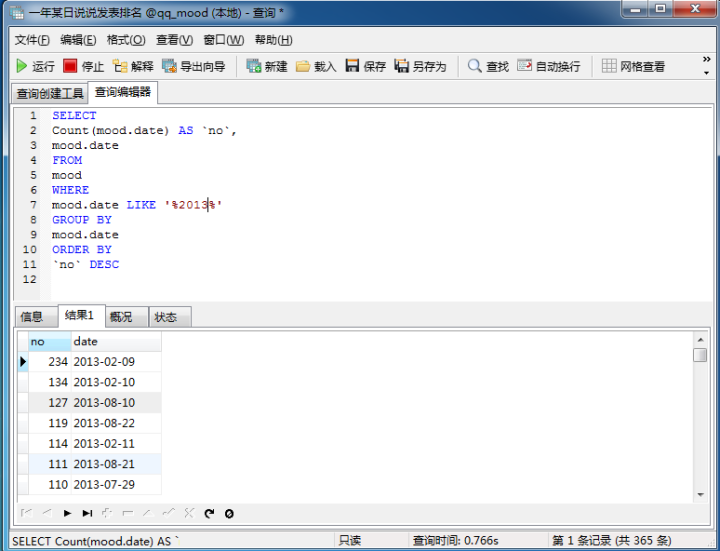
通過兩個(gè)輔助表,可以看到分年,分月,分小時(shí)段統(tǒng)計(jì)的說說數(shù)目,下面是代碼和數(shù)據(jù)圖:
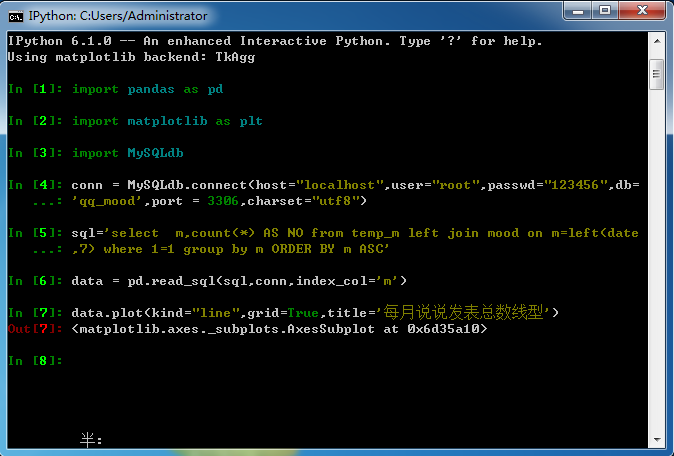
其余的幾個(gè)圖代碼都是類似的,我就不重復(fù)發(fā)了。(其實(shí)主要是cmd里面復(fù)制代碼太不方便了,建議大家用ipython notebook)
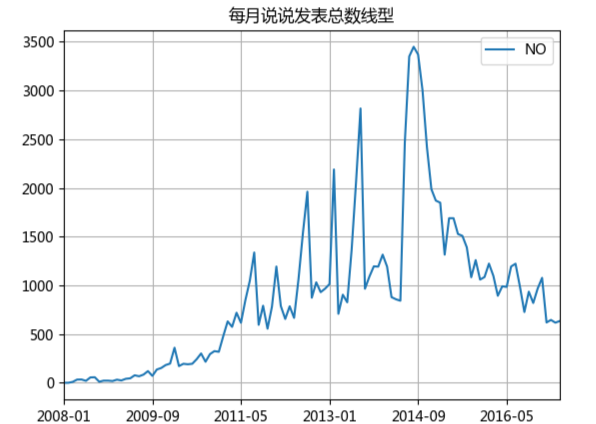
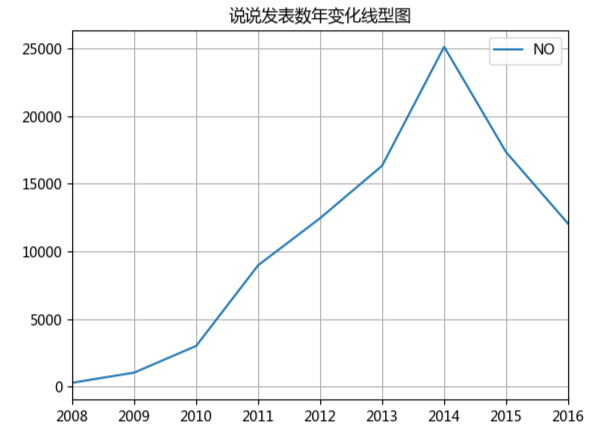
額,可以看出2014年9月達(dá)到了一個(gè)高峰,主要是因?yàn)槲业呐笥汛蠖际鞘?014年九月大學(xué)入學(xué)的,之后開始下降,這可能是好多人開始玩微信,逐漸放棄了QQ,通過下面這個(gè)年變化圖可以更直觀的看出:
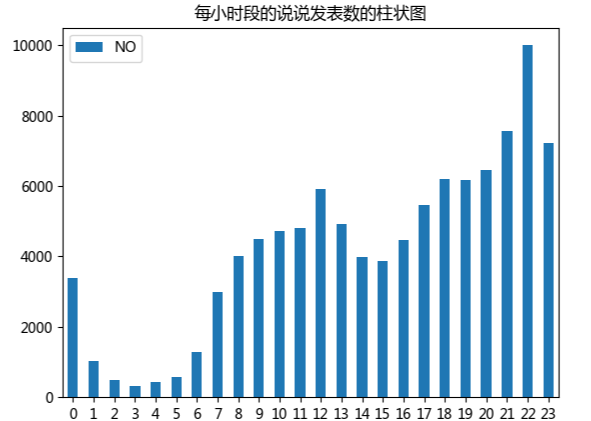
通過這個(gè)每小時(shí)段說說發(fā)表的數(shù)目柱形圖,可以發(fā)現(xiàn)大家在晚上22點(diǎn)到23點(diǎn)左右是最多的,另外中午十二點(diǎn)到一點(diǎn)也有一個(gè)小高峰
tool發(fā)表說說用的工具這個(gè)字段的數(shù)據(jù)比較臟,因?yàn)榘l(fā)表工具可以由用戶自定義。最后我用Excel的內(nèi)容篩選功能,做了一個(gè)手機(jī)類型的餅圖:
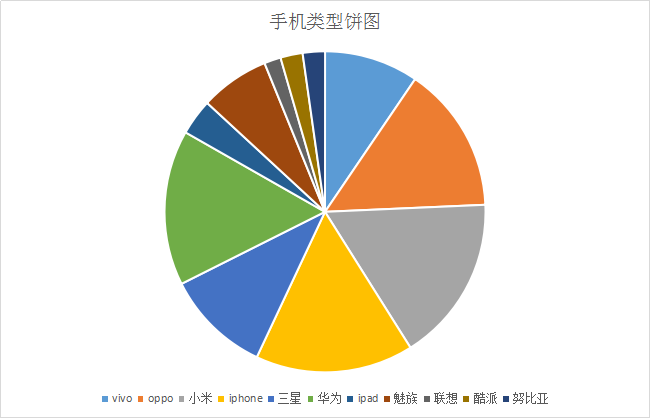
通過這個(gè)餅圖可以看出使用最多的手機(jī)是蘋果,小米,魅族,華為這四個(gè)手機(jī)品牌。(這個(gè)結(jié)果有很大的因素是因?yàn)槲业暮糜汛蠖鄶?shù)學(xué)生黨,偏向于性價(jià)比高的手機(jī))
還有一個(gè)比較好玩的就是把經(jīng)緯度信息導(dǎo)出來,通過智圖位置智能平臺(tái)可以生成一個(gè)地圖,這個(gè)地圖的效果還是非常好的(2000條數(shù)據(jù)免費(fèi),本來有位置信息的說說有3500條,剔除了國(guó)外的坐標(biāo)后我從中隨機(jī)選了2000條)?
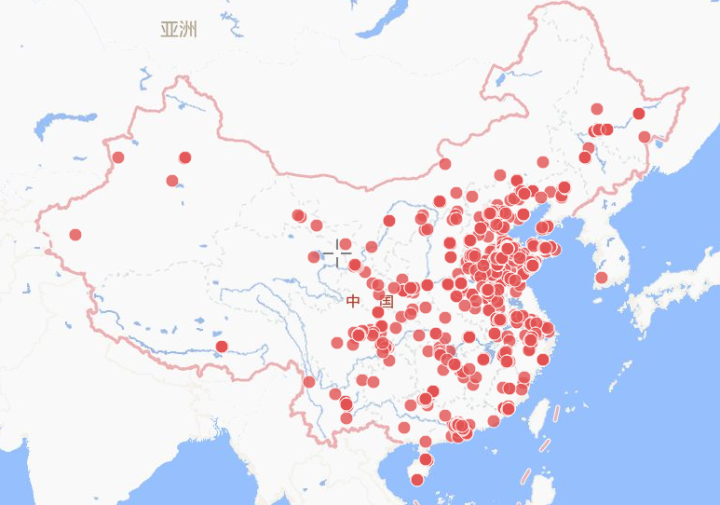
因?yàn)樯婕暗絺€(gè)人隱私問題,這個(gè)地圖的鏈接就不分享了。
最后,通過將mood表中的content字段導(dǎo)出為txt文本文件,利用python的jieba和wordcloud這兩個(gè)第三方庫(kù),可以生成基于說說內(nèi)容的詞云。下面是代碼:
#coding:utf-8
import?matplotlib.pyplot as?plt
from?wordcloud import?WordCloud,ImageColorGenerator,STOPWORDS
import?jieba
import?numpy as?np
from?PIL import?Image
#讀入背景圖片
abel_mask = np.array(Image.open("qq.jpg"))
#讀取要生成詞云的文件
text_from_file_with_apath = open('mood.txt',encoding='utf-8').read()
#通過jieba分詞進(jìn)行分詞并通過空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
stopwords = {'轉(zhuǎn)載','內(nèi)容','em','評(píng)語','uin','nick'}
seg_list = [i for?i in?wordlist_after_jieba if?i not?in?stopwords]
wl_space_split = " ".join(seg_list)
#my_wordcloud = WordCloud().generate(wl_space_split) 默認(rèn)構(gòu)造函數(shù)
my_wordcloud = WordCloud(
background_color='black', # 設(shè)置背景顏色
????????????mask = abel_mask, # 設(shè)置背景圖片
????????????max_words = 250, # 設(shè)置最大現(xiàn)實(shí)的字?jǐn)?shù)
????????????stopwords = STOPWORDS, # 設(shè)置停用詞
????????????font_path = 'C:/Windows/fonts/simkai.ttf',# 設(shè)置字體格式,如不設(shè)置顯示不了中文
????????????max_font_size = 42, # 設(shè)置字體最大值
????????????random_state = 40, # 設(shè)置有多少種隨機(jī)生成狀態(tài),即有多少種配色方案
????????????????scale=1.5,
????????????mode='RGBA',
????????????relative_scaling=0.6
????????????????).generate(wl_space_split)
# 根據(jù)圖片生成詞云顏色
#image_colors = ImageColorGenerator(abel_mask)
#my_wordcloud.recolor(color_func=image_colors)
# 以下代碼顯示圖片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
my_wordcloud.to_file("cloud.jpg")下面是效果圖:

不會(huì)ps,做的不是很美觀...
對(duì)于這個(gè)小demo,我總結(jié)了一以下的幾個(gè)問題:
爬蟲沒有采用多線程和異步IO導(dǎo)致效率太低。(主要是twisted這個(gè)庫(kù)不太懂,后面我可能會(huì)結(jié)合scapy這個(gè)框架,重寫這個(gè)爬蟲,利用他的twisted模塊加上異步IO的功能)
對(duì)于python中的關(guān)于繪圖的,和數(shù)據(jù)分析的這幾個(gè)庫(kù)了解的不好,導(dǎo)致數(shù)據(jù)可視化這塊做的不好。
-?END -
本文為轉(zhuǎn)載分享&推薦閱讀,若侵權(quán)請(qǐng)聯(lián)系后臺(tái)刪除