
超詳細(xì)圖解Self-Attention的那些事兒
點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
導(dǎo)讀
?Self-Attention作為Transformer最為核心的思想,其相關(guān)內(nèi)部機(jī)理以及高維繁復(fù)的矩陣運(yùn)算公式等卻阻礙我們對(duì)其理解,本文作者首先總結(jié)了一些Transformer的基礎(chǔ)知識(shí),后詳細(xì)的介紹了最讓人頭禿的QKV三個(gè)矩陣,幫助大家真正的理解矩陣運(yùn)算的核心意義。
一年之前,初次接觸Transformer。當(dāng)時(shí)只覺得模型復(fù)雜,步驟繁復(fù),苦讀論文多日也沒有完全理解其中道理,只是泛泛地記住了一些名詞,于其內(nèi)部機(jī)理完全不通,相關(guān)公式更是過目便忘。
Self-Attention 是 Transformer最核心的思想,最近幾日重讀論文,有了一些新的感想。由此寫下本文與讀者共勉。
筆者剛開始接觸Self-Attention時(shí),最大的不理解的地方就是Q K V三個(gè)矩陣以及我們常提起的Query查詢向量等等,現(xiàn)在究其原因,應(yīng)當(dāng)是被高維繁復(fù)的矩陣運(yùn)算難住了,沒有真正理解矩陣運(yùn)算的核心意義。因此,在本文開始之前,筆者首先總結(jié)一些基礎(chǔ)知識(shí),文中會(huì)重新提及這些知識(shí)蘊(yùn)含的思想是怎樣體現(xiàn)在模型中的。
一些基礎(chǔ)知識(shí)
向量的內(nèi)積是什么,如何計(jì)算,最重要的,其幾何意義是什么? 一個(gè)矩陣 與其自身的轉(zhuǎn)置相乘,得到的結(jié)果有什么意義?
1. 鍵值對(duì)注意力
這一節(jié)我們首先分析Transformer中最核心的部分,我們從公式開始,將每一步都繪制成圖,方便讀者理解。
鍵值對(duì)Attention最核心的公式如下圖。其實(shí)這一個(gè)公式中蘊(yùn)含了很多個(gè)點(diǎn),我們一個(gè)一個(gè)來講。請(qǐng)讀者跟隨我的思路,從最核心的部分入手,細(xì)枝末節(jié)的部分會(huì)豁然開朗。
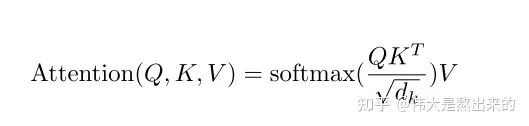
假如上面的公式很難理解,那么下面的公式讀者能否知道其意義是什么呢?
我們先拋開Q K V三個(gè)矩陣不談,self-Attention最原始的形態(tài)其實(shí)長(zhǎng)上面這樣。那么這個(gè)公式到底是什么意思呢?
我們一步一步講
代表什么?
一個(gè)矩陣乘以它自己的轉(zhuǎn)置,會(huì)得到什么結(jié)果,有什么意義?
我們知道,矩陣可以看作由一些向量組成,一個(gè)矩陣乘以它自己轉(zhuǎn)置的運(yùn)算,其實(shí)可以看成這些向量分別與其他向量計(jì)算內(nèi)積。(此時(shí)腦海里想起矩陣乘法的口訣,第一行乘以第一列、第一行乘以第二列......嗯哼,矩陣轉(zhuǎn)置以后第一行不就是第一列嗎?這是在計(jì)算第一個(gè)行向量與自己的內(nèi)積,第一行乘以第二列是計(jì)算第一個(gè)行向量與第二個(gè)行向量的內(nèi)積第一行乘以第三列是計(jì)算第一個(gè)行向量與第三個(gè)行向量的內(nèi)積.....)
回想我們文章開頭提出的問題,向量的內(nèi)積,其幾何意義是什么?
答:表征兩個(gè)向量的夾角,表征一個(gè)向量在另一個(gè)向量上的投影
記住這個(gè)知識(shí)點(diǎn),我們進(jìn)入一個(gè)超級(jí)詳細(xì)的實(shí)例:
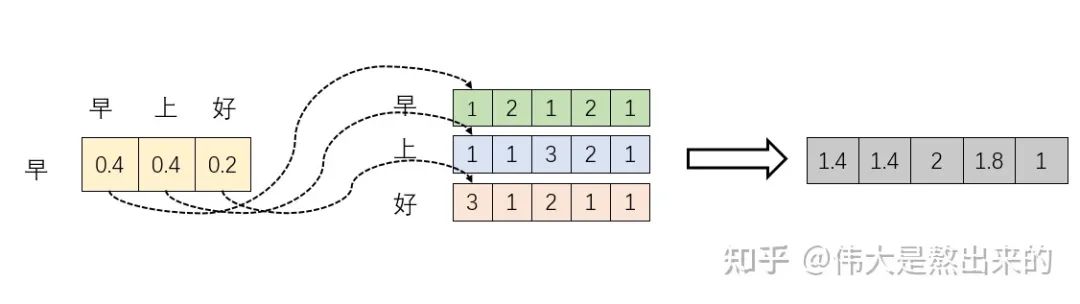
我們假設(shè) ,其中 為一個(gè)二維矩陣, 為一個(gè)行向量(其實(shí)很多教材都默認(rèn)向量是列向量,為了方便舉例請(qǐng)讀者理解筆者使用行向量)。對(duì)應(yīng)下面的圖, 對(duì)應(yīng)"早"字embedding之后的結(jié)果,以此類推。
下面的運(yùn)算模擬了一個(gè)過程,即 。我們來看看其結(jié)果究竟有什么意義
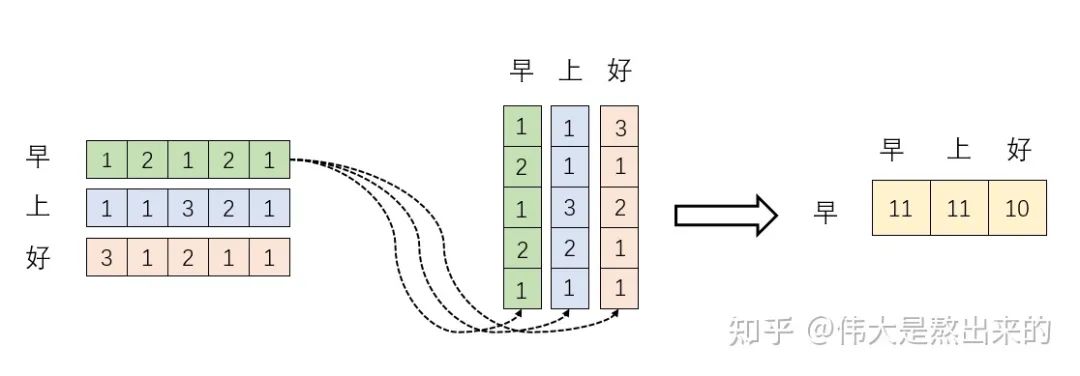
首先,行向量 分別與自己和其他兩個(gè)行向量做內(nèi)積("早"分別與"上""好"計(jì)算內(nèi)積),得到了一個(gè)新的向量。我們回想前文提到的向量的內(nèi)積表征兩個(gè)向量的夾角,表征一個(gè)向量在另一個(gè)向量上的投影。那么新的向量向量有什么意義的?是行向量 在自己和其他兩個(gè)行向量上的投影。我們思考,投影的值大有什么意思?投影的值小又如何?
投影的值大,說明兩個(gè)向量相關(guān)度高。
我們考慮,如果兩個(gè)向量夾角是九十度,那么這兩個(gè)向量線性無關(guān),完全沒有相關(guān)性!
更進(jìn)一步,這個(gè)向量是詞向量,是詞在高維空間的數(shù)值映射。詞向量之間相關(guān)度高表示什么?是不是在一定程度上(不是完全)表示,在關(guān)注詞A的時(shí)候,應(yīng)當(dāng)給予詞B更多的關(guān)注?
上圖展示了一個(gè)行向量運(yùn)算的結(jié)果,那么矩陣 的意義是什么呢?
矩陣 是一個(gè)方陣,我們以行向量的角度理解,里面保存了每個(gè)向量與自己和其他向量進(jìn)行內(nèi)積運(yùn)算的結(jié)果。
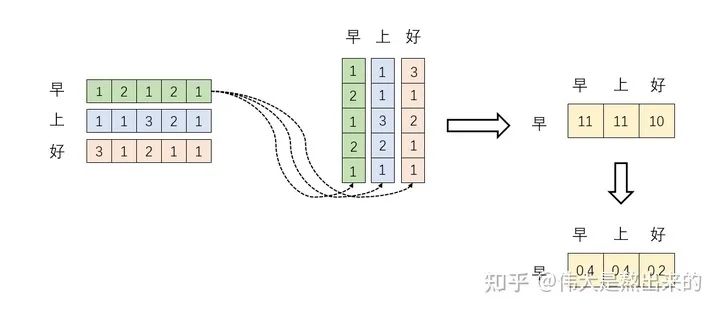
至此,我們理解了公式 中, 的意義。我們進(jìn)一步,Softmax的意義何在呢?請(qǐng)看下圖
我們回想Softmax的公式,Softmax操作的意義是什么呢?
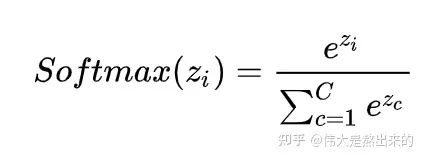
答:歸一化
我們結(jié)合上面圖理解,Softmax之后,這些數(shù)字的和為1了。我們?cè)傧耄珹ttention機(jī)制的核心是什么?
加權(quán)求和
那么權(quán)重從何而來呢?就是這些歸一化之后的數(shù)字。當(dāng)我們關(guān)注"早"這個(gè)字的時(shí)候,我們應(yīng)當(dāng)分配0.4的注意力給它本身,剩下0.4關(guān)注"上",0.2關(guān)注"好"。當(dāng)然具體到我們的Transformer,就是對(duì)應(yīng)向量的運(yùn)算了,這是后話。
行文至此,我們對(duì)這個(gè)東西是不是有點(diǎn)熟悉?Python中的熱力圖Heatmap,其中的矩陣是不是也保存了相似度的結(jié)果?
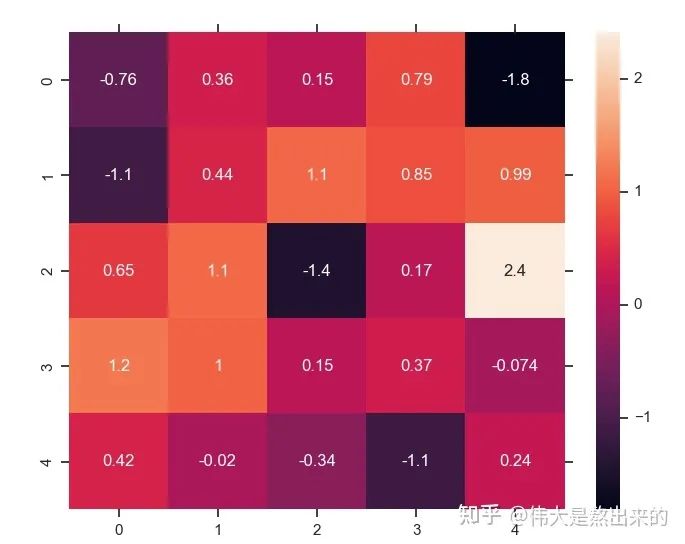
我們仿佛已經(jīng)撥開了一些迷霧,公式 已經(jīng)理解了其中的一半。最后一個(gè) X 有什么意義?完整的公式究竟表示什么?我們繼續(xù)之前的計(jì)算,請(qǐng)看下圖
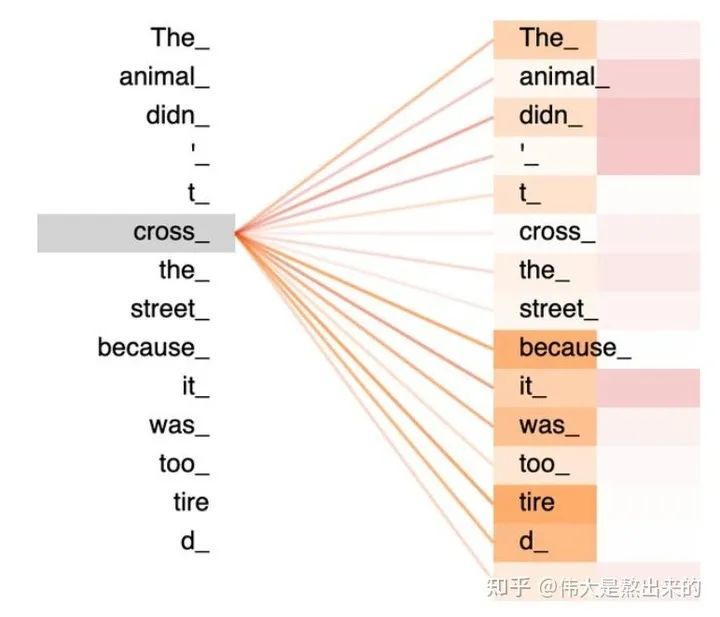
我們?nèi)? 的一個(gè)行向量舉例。這一行向量與 的一個(gè)列向量相乘,表示什么?
觀察上圖,行向量與 的第一個(gè)列向量相乘,得到了一個(gè)新的行向量,且這個(gè)行向量與 的維度相同。
在新的向量中,每一個(gè)維度的數(shù)值都是由三個(gè)詞向量在這一維度的數(shù)值加權(quán)求和得來的,這個(gè)新的行向量就是"早"字詞向量經(jīng)過注意力機(jī)制加權(quán)求和之后的表示。
一張更形象的圖是這樣的,圖中右半部分的顏色深淺,其實(shí)就是我們上圖中黃色向量中數(shù)值的大小,意義就是單詞之間的相關(guān)度(回想之前的內(nèi)容,相關(guān)度其本質(zhì)是由向量的內(nèi)積度量的)!
如果您堅(jiān)持閱讀到這里,相信對(duì)公式 已經(jīng)有了更深刻的理解。
我們接下來解釋原始公式中一些細(xì)枝末節(jié)的問題
2. Q K V矩陣
在我們之前的例子中并沒有出現(xiàn)Q K V的字眼,因?yàn)槠洳⒉皇枪街凶畋举|(zhì)的內(nèi)容。
Q K V究竟是什么?我們看下面的圖
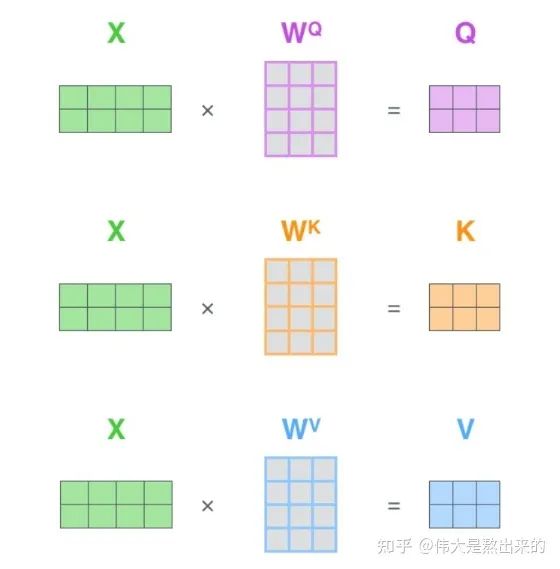
其實(shí),許多文章中所謂的Q K V矩陣、查詢向量之類的字眼,其來源是 與矩陣的乘積,本質(zhì)上都是 的線性變換。
為什么不直接使用 而要對(duì)其進(jìn)行線性變換?
當(dāng)然是為了提升模型的擬合能力,矩陣 都是可以訓(xùn)練的,起到一個(gè)緩沖的效果。
如果你真正讀懂了前文的內(nèi)容,讀懂了 這個(gè)矩陣的意義,相信你也理解了所謂查詢向量一類字眼的含義。
3. 的意義
假設(shè) 里的元素的均值為0,方差為1,那么 中元素的均值為0,方差為d. 當(dāng)d變得很大時(shí), 中的元素的方差也會(huì)變得很大,如果 中的元素方差很大,那么 的分布會(huì)趨于陡峭(分布的方差大,分布集中在絕對(duì)值大的區(qū)域)。總結(jié)一下就是 的分布會(huì)和d有關(guān)。因此 中每一個(gè)元素除以 后,方差又變?yōu)?。這使得 的分布“陡峭”程度與d解耦,從而使得訓(xùn)練過程中梯度值保持穩(wěn)定。
至此Self-Attention中最核心的內(nèi)容已經(jīng)講解完畢,關(guān)于Transformer的更多細(xì)節(jié)可以參考我的這篇回答:
最后再補(bǔ)充一點(diǎn),對(duì)self-attention來說,它跟每一個(gè)input vector都做attention,所以沒有考慮到input sequence的順序。更通俗來講,大家可以發(fā)現(xiàn)我們前文的計(jì)算每一個(gè)詞向量都與其他詞向量計(jì)算內(nèi)積,得到的結(jié)果丟失了我們?cè)瓉砦谋镜捻樞蛐畔ⅰ?duì)比來說,LSTM是對(duì)于文本順序信息的解釋是輸出詞向量的先后順序,而我們上文的計(jì)算對(duì)sequence的順序這一部分則完全沒有提及,你打亂詞向量的順序,得到的結(jié)果仍然是相同的。
這就牽扯到Transformer的位置編碼了,我們按住不表。
Self-Attention的代碼實(shí)現(xiàn)
# Muti-head Attention 機(jī)制的實(shí)現(xiàn)
from math import sqrt
import torch
import torch.nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_v
return output

# Muti-head Attention 機(jī)制的實(shí)現(xiàn)
from math import sqrt
import torch
import torch.nn
class Self_Attention_Muti_Head(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v,nums_head):
super(Self_Attention_Muti_Head,self).__init__()
assert dim_k % nums_head == 0
assert dim_v % nums_head == 0
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self.nums_head = nums_head
self.dim_k = dim_k
self.dim_v = dim_v
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
V = self.v(x).reshape(-1,x.shape[0],x.shape[1],self.dim_v // self.nums_head)
print(x.shape)
print(Q.size())
atten = nn.Softmax(dim=-1)(torch.matmul(Q,K.permute(0,1,3,2))) # Q * K.T() # batch_size * seq_len * seq_len
output = torch.matmul(atten,V).reshape(x.shape[0],x.shape[1],-1) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
在本文的基礎(chǔ)上,筆者從零實(shí)現(xiàn)了Transformer模型,感興趣的讀者歡迎看一看呀~
如果覺得有用,就請(qǐng)分享到朋友圈吧!

點(diǎn)個(gè)在看 paper不斷!