
阿里菜鳥實(shí)時(shí)數(shù)倉(cāng)2.0進(jìn)階之路
點(diǎn)擊上方“數(shù)據(jù)管道”,選擇“置頂星標(biāo)”公眾號(hào)
干貨福利,第一時(shí)間送達(dá)

分享嘉賓:張庭 菜鳥 數(shù)據(jù)工程師
文章整理:comn
出品平臺(tái):DataFunTalk
主要內(nèi)容包括:
相關(guān)背景介紹
進(jìn)口實(shí)時(shí)數(shù)倉(cāng)演進(jìn)過(guò)程
挑戰(zhàn)及實(shí)踐
總結(jié)與展望
1. 進(jìn)口業(yè)務(wù)簡(jiǎn)介
進(jìn)口業(yè)務(wù)的流程大致比較清晰,國(guó)內(nèi)的買家下單之后,國(guó)外的賣家發(fā)貨,經(jīng)過(guò)清關(guān),干線運(yùn)輸,到國(guó)內(nèi)的清關(guān),配送,到消費(fèi)者手里,菜鳥在整個(gè)過(guò)程中負(fù)責(zé)協(xié)調(diào)鏈路上的各個(gè)資源,完成物流履約的服務(wù)。去年考拉融入到阿里體系之后,整個(gè)進(jìn)口業(yè)務(wù)規(guī)模占國(guó)內(nèi)進(jìn)口單量的規(guī)模是非常高的。并且每年的單量都在迅速增長(zhǎng),訂單履行周期特別長(zhǎng),中間涉及的環(huán)節(jié)多,所以在數(shù)據(jù)建設(shè)時(shí),既要考慮把所有數(shù)據(jù)融合到一起,還要保證數(shù)據(jù)有效性,是非常困難的一件事情。
2. 實(shí)時(shí)數(shù)倉(cāng)加工流程
① 一般過(guò)程
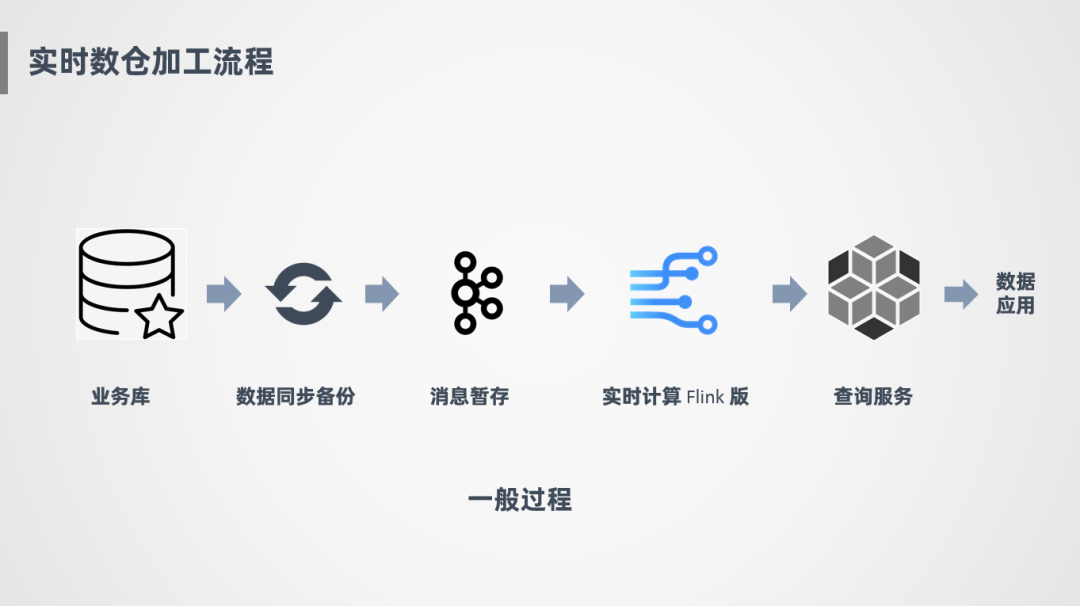
下面簡(jiǎn)單介紹一下實(shí)時(shí)數(shù)倉(cāng)的加工流程,一般會(huì)對(duì)接業(yè)務(wù)庫(kù)或者日志源,通過(guò)數(shù)據(jù)同步的方式,比如Sqoop或DataX把消息同步到消息中間件中暫存,下游會(huì)接一個(gè)實(shí)時(shí)計(jì)算引擎,對(duì)消息進(jìn)行消費(fèi),消費(fèi)之后會(huì)進(jìn)行計(jì)算、加工,產(chǎn)出一些明細(xì)表或匯總指標(biāo),放到查詢服務(wù)上供數(shù)據(jù)應(yīng)用端使用。
② 菜鳥內(nèi)部流程
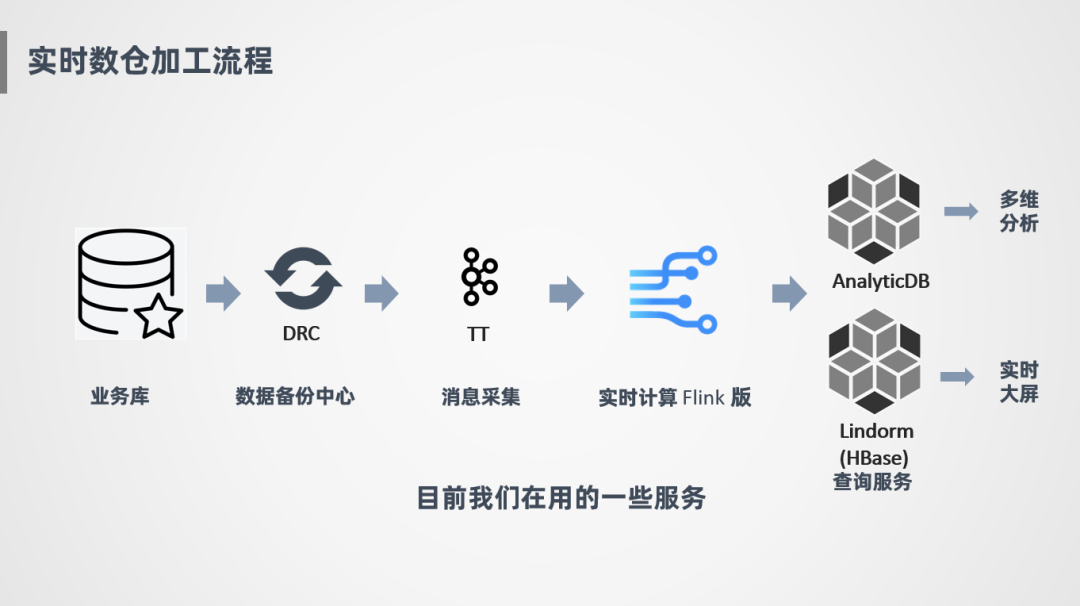
在菜鳥內(nèi)部也是同樣的流程,我們將業(yè)務(wù)庫(kù)數(shù)據(jù)通過(guò)DRC ( 數(shù)據(jù)備份中心 ) 增量采集Binlog日志的方式,同步到TT ( 類似Kafka的消息中間件 ) 做一個(gè)消息暫存,后面會(huì)接一個(gè)Flink實(shí)時(shí)計(jì)算引擎進(jìn)行消費(fèi),計(jì)算好之后寫入兩種查詢服務(wù),一種是ADB,一種是HBase ( Lindorm ),ADB是一個(gè)OLAP引擎,阿里云對(duì)外也提供服務(wù),主要是提供一些豐富的多維分析查詢,寫入的也是一些維度比較豐富的輕度匯總或明細(xì)數(shù)據(jù),對(duì)于實(shí)時(shí)大屏的場(chǎng)景,因?yàn)榫S度比較少,指標(biāo)比較固定,我們會(huì)沉淀一些高度匯總指標(biāo)寫到HBase中供實(shí)時(shí)大屏使用。
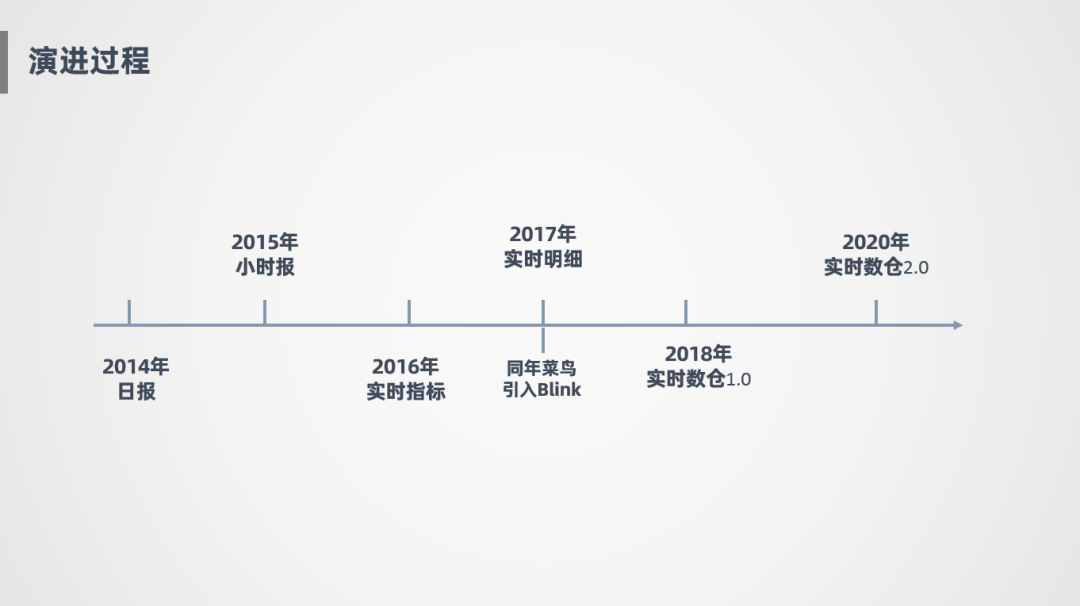
接下來(lái)講一下進(jìn)口實(shí)時(shí)數(shù)倉(cāng)的演進(jìn)過(guò)程:
2014年:進(jìn)口業(yè)務(wù)線大概在14年時(shí),建好了離線數(shù)倉(cāng),能提供日?qǐng)?bào)。
2015年:能提供小時(shí)報(bào),更新頻度從天到小時(shí)。
2016年:基于JStorm探索了一些實(shí)時(shí)指標(biāo)的計(jì)算服務(wù),越來(lái)越趨向于實(shí)時(shí)化。由于16年剛開始嘗試實(shí)時(shí)指標(biāo),指標(biāo)還不是特別豐富。
2017年:菜鳥引進(jìn)了Blink,也就是Flink在阿里的內(nèi)部版本,作為我們的流計(jì)算引擎,并且進(jìn)口業(yè)務(wù)線在同一年打通了實(shí)時(shí)明細(xì),通過(guò)實(shí)時(shí)明細(xì)大寬表對(duì)外提供數(shù)據(jù)服務(wù)。
2018年:完成了菜鳥進(jìn)口實(shí)時(shí)數(shù)倉(cāng)1.0的建設(shè)。
2020年:開始了實(shí)時(shí)數(shù)倉(cāng)2.0的建設(shè),為什么開始2.0?因?yàn)?.0在設(shè)計(jì)過(guò)程中存在了很多問(wèn)題,整個(gè)模型架構(gòu)不夠靈活,擴(kuò)展性不高,還有一些是因?yàn)闆]有了解Blink的特性,導(dǎo)致誤用帶來(lái)的一些運(yùn)維成本的增加,所以后面進(jìn)行了大的升級(jí)改造。
1. 實(shí)時(shí)數(shù)倉(cāng)1.0
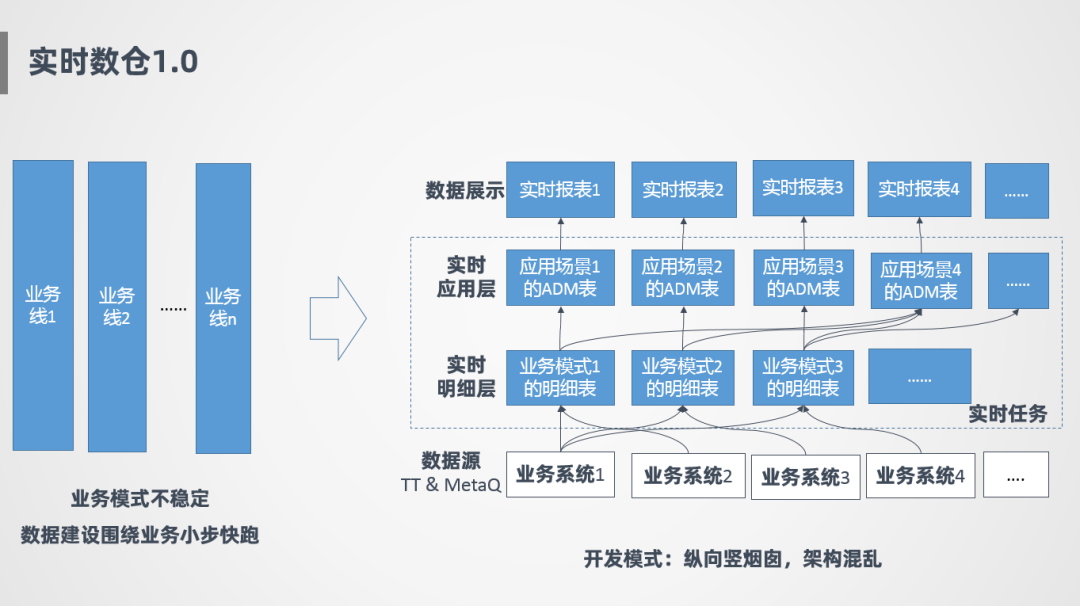
接下來(lái)講一下實(shí)時(shí)數(shù)倉(cāng)1.0的情況,一開始因?yàn)樵诎l(fā)展初期,業(yè)務(wù)模式不太穩(wěn)定,所以一開始的策略就是圍繞業(yè)務(wù)小步快跑,比如針對(duì)業(yè)務(wù)1會(huì)開發(fā)一套實(shí)時(shí)明細(xì)層,針對(duì)業(yè)務(wù)2也會(huì)開發(fā)一套實(shí)時(shí)任務(wù),好處是可以隨著業(yè)務(wù)發(fā)展快速迭代,互相之間不影響,早期會(huì)更靈活。
如上圖右側(cè)所示,最底層是各個(gè)業(yè)務(wù)系統(tǒng)的消息源,實(shí)時(shí)任務(wù)主要有兩層,一層是實(shí)時(shí)明細(xì)層,針對(duì)業(yè)務(wù)線會(huì)開發(fā)不同的明細(xì)表,明細(xì)表就是針對(duì)該條業(yè)務(wù)線需要的數(shù)據(jù)把它抽取過(guò)來(lái),在這之上是ADM層,也就是實(shí)時(shí)應(yīng)用層,應(yīng)用層主要針對(duì)具體的場(chǎng)景定制,比如有個(gè)場(chǎng)景要看整體匯總指標(biāo),則從各個(gè)明細(xì)表抽取數(shù)據(jù),產(chǎn)生一張實(shí)時(shí)匯總層表,整個(gè)過(guò)程是豎向煙囪式開發(fā),模型比較混亂,難擴(kuò)展,并且存在很多重復(fù)計(jì)算。
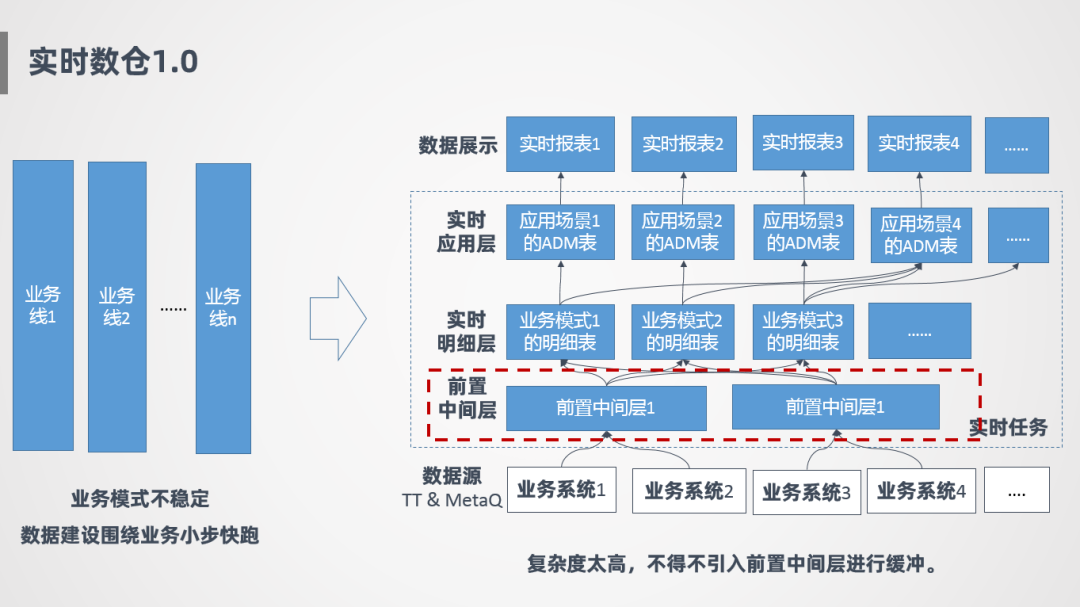
后面也是由于重復(fù)計(jì)算的問(wèn)題,進(jìn)行了一層抽象,加了一個(gè)前置中間層,對(duì)公共的部分進(jìn)行提取,但是治標(biāo)不治本,整個(gè)模型還是比較混亂的,數(shù)據(jù)建設(shè)上也沒有進(jìn)行統(tǒng)一,模型擴(kuò)展性上也很差。
2. 實(shí)時(shí)數(shù)倉(cāng)2.0

2.0升級(jí)完之后是比較清晰的一張圖:
前置層:底層數(shù)據(jù)源會(huì)接入到前置中間層,屏蔽掉底層一些非常復(fù)雜的邏輯。
明細(xì)層:前置層會(huì)把比較干凈的數(shù)據(jù)給到明細(xì)表,明細(xì)層打通了各個(gè)業(yè)務(wù)線,進(jìn)行了模型的統(tǒng)一。
匯總層:明細(xì)層之上會(huì)有輕度匯總和高度匯總,輕度匯總表維度非常多,主要寫入到OLAP引擎中供多維查詢分析,高度匯總指標(biāo)主要針對(duì)實(shí)時(shí)大屏場(chǎng)景進(jìn)行沉淀。
接口服務(wù):匯總層之上會(huì)根據(jù)統(tǒng)一的接口服務(wù)對(duì)外提供數(shù)據(jù)輸出。
數(shù)據(jù)應(yīng)用:應(yīng)用層主要接入包括實(shí)時(shí)大屏,數(shù)據(jù)應(yīng)用,實(shí)時(shí)報(bào)表以及消息推送等。
這就是實(shí)時(shí)數(shù)倉(cāng)2.0升級(jí)之后的模型,整個(gè)模型雖然看起來(lái)比較簡(jiǎn)單,其實(shí)背后從模型設(shè)計(jì)到開發(fā)落地,遇到了很多困難,花費(fèi)了很大的精力。下面為大家分享下我們?cè)谏?jí)過(guò)程中遇到的挑戰(zhàn)及實(shí)踐。
我們?cè)趯?shí)時(shí)數(shù)倉(cāng)升級(jí)的過(guò)程中,面臨的挑戰(zhàn)如下:

1. 業(yè)務(wù)線和業(yè)務(wù)模式多

第一個(gè)就是對(duì)接的業(yè)務(wù)線比較多,不同的業(yè)務(wù)線有不同的模式,導(dǎo)致一開始小步快跑方式的模型比較割裂,模型和模型之間沒有復(fù)用性,開發(fā)和運(yùn)維成本都很高,資源消耗嚴(yán)重。
解決方案:邏輯中間層升級(jí)
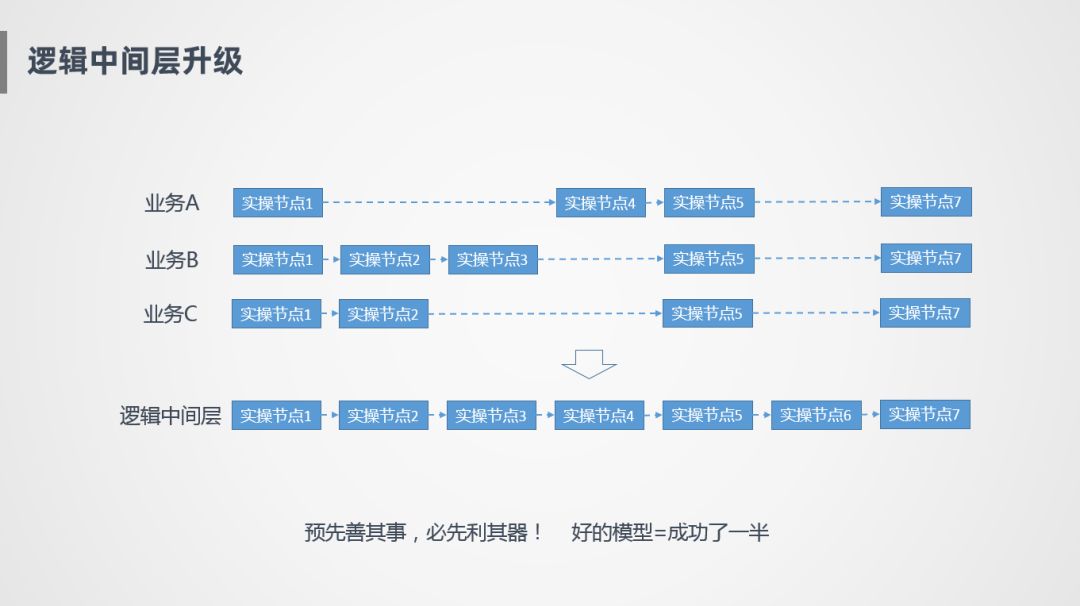
我們想到的比較簡(jiǎn)單的思路就是建設(shè)統(tǒng)一的數(shù)據(jù)中間層,比如業(yè)務(wù)A有出庫(kù)、攬收、派送等幾個(gè)業(yè)務(wù)節(jié)點(diǎn),業(yè)務(wù)B可能是另外幾個(gè)節(jié)點(diǎn),整個(gè)模型是割裂的狀態(tài),但實(shí)際上業(yè)務(wù)發(fā)展到中后期比較穩(wěn)定的時(shí)候,各個(gè)業(yè)務(wù)模式之間相對(duì)比較穩(wěn)定,這個(gè)時(shí)候可以對(duì)數(shù)據(jù)進(jìn)行一個(gè)抽象,比如業(yè)務(wù)A有節(jié)點(diǎn)1、節(jié)點(diǎn)5和其他幾個(gè)業(yè)務(wù)模式是一樣的,通過(guò)這種對(duì)齊的方式,找出哪些是公共的,哪些是非公共的,提取出來(lái)沉淀到邏輯中間層里,從而屏蔽各業(yè)務(wù)之間的差距,完成統(tǒng)一的數(shù)據(jù)建設(shè)。把邏輯中間層進(jìn)行統(tǒng)一,還有一個(gè)很大的原因,業(yè)務(wù)A,B,C雖然是不同的業(yè)務(wù)系統(tǒng),比如履行系統(tǒng),關(guān)務(wù)系統(tǒng),但是本質(zhì)上都是同一套,底層數(shù)據(jù)源也是進(jìn)行各種抽象,所以數(shù)倉(cāng)建模上也要通過(guò)統(tǒng)一的思路進(jìn)行建設(shè)。
2. 業(yè)務(wù)系統(tǒng)多,超大數(shù)據(jù)源

第二個(gè)就是對(duì)接的系統(tǒng)非常多,每個(gè)系統(tǒng)數(shù)據(jù)量很大,每天億級(jí)別的數(shù)據(jù)源就有十幾個(gè),梳理起來(lái)非常困難。帶來(lái)的問(wèn)題也比較明顯,第一個(gè)問(wèn)題就是大狀態(tài)的問(wèn)題,需要在Flink里維護(hù)特別大的狀態(tài),還有就是接入這么多數(shù)據(jù)源之后,成本怎么控制。
解決方案:善用State
State是Flink的一大特性,因?yàn)樗拍鼙WC狀態(tài)計(jì)算,需要更合理的利用。我們要認(rèn)清State是干什么的,什么時(shí)候需要State,如何優(yōu)化它,這些都是需要考慮的事情。State有兩種,一種是KeyedState,具體是跟數(shù)據(jù)的Key相關(guān)的,例如SQL中的Group By,F(xiàn)link會(huì)按照鍵值進(jìn)行相關(guān)數(shù)據(jù)的存儲(chǔ),比如存儲(chǔ)到二進(jìn)制的一個(gè)數(shù)組里。第二個(gè)是OperatorState,跟具體的算子相關(guān),比如用來(lái)記錄Source Connector里讀取的Offset,或者算子之間任務(wù)Failover之后,狀態(tài)怎么在不同算子之間進(jìn)行恢復(fù)。
① 數(shù)據(jù)接入時(shí)"去重"
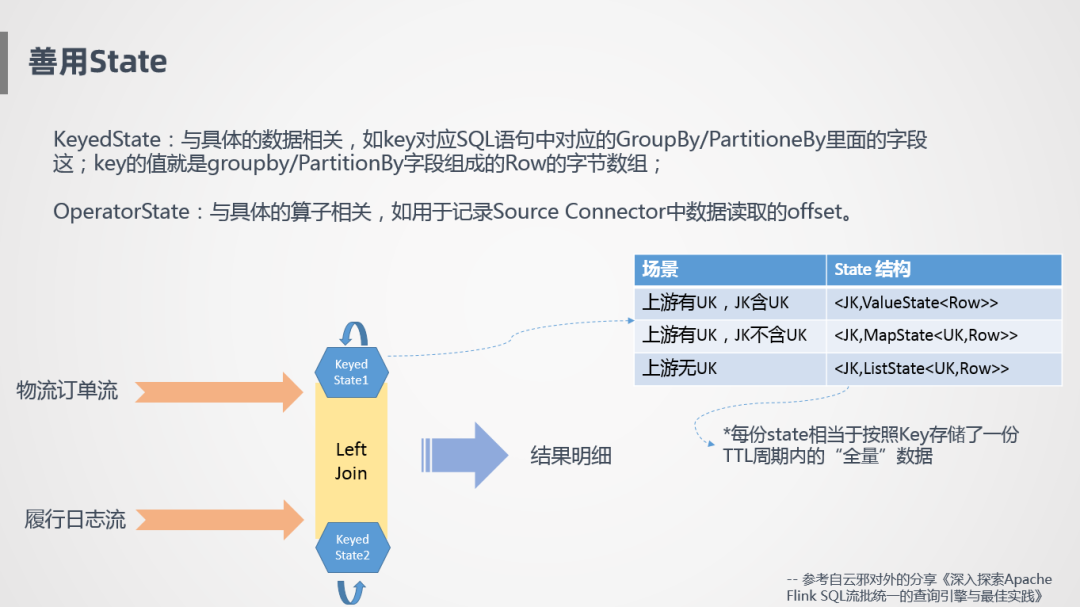
下面舉個(gè)例子,怎么用到KeyedState,比如物流訂單流和履行日志流,兩個(gè)作業(yè)關(guān)聯(lián)產(chǎn)生出最終需要的一張大表,Join是怎么存儲(chǔ)的呢?流是一直不停的過(guò)來(lái)的,消息到達(dá)的前后順序可能不一致,需要把它存在算子里面,對(duì)于Join的狀態(tài)節(jié)點(diǎn),比較簡(jiǎn)單粗暴的方式是把左流和右流同時(shí)存下來(lái),通過(guò)這樣的方式保證不管消息是先到還是后到,至少保證算子里面數(shù)據(jù)是全的,哪怕其中一個(gè)流很晚才到達(dá),也能保證匹配到之前的數(shù)據(jù),需要注意的一點(diǎn)是,State存儲(chǔ)根據(jù)上游不同而不同,比如在上游定義了一個(gè)主鍵Rowkey,并且JoinKey包含了主鍵,就不存在多筆訂單對(duì)應(yīng)同一個(gè)外鍵,這樣就告訴State只需要按照J(rèn)oinKey存儲(chǔ)唯一行就可以了。如果上游有主鍵,但是JoinKey不包含Rowkey 的話,就需要在State里將兩個(gè)Rowkey的訂單同時(shí)存下來(lái)。最差的情況是,上游沒有主鍵,比如同一筆訂單有10條消息,會(huì)有先后順序,最后一條是有效的,但是對(duì)于系統(tǒng)來(lái)說(shuō)不知道哪條是有效的,沒有指定主鍵也不好去重,它就會(huì)全部存下來(lái),特別耗資源和性能,相對(duì)來(lái)說(shuō)是特別差的一種方式。
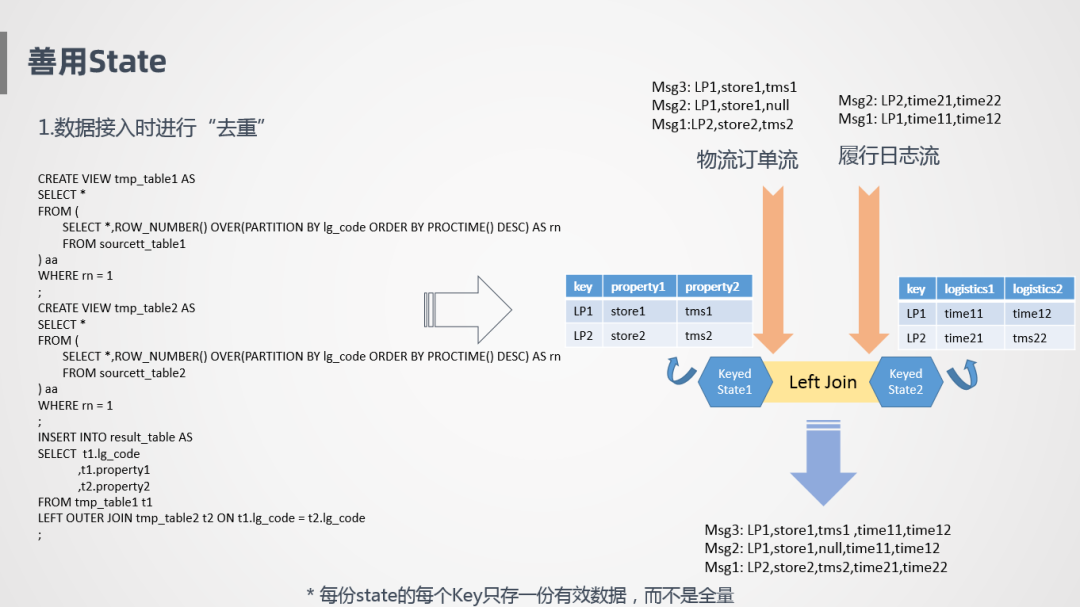
因此,我們?cè)跀?shù)據(jù)接入時(shí)進(jìn)行"去重"。數(shù)據(jù)接入時(shí),按照row_number進(jìn)行排序,告訴系統(tǒng)按照主鍵進(jìn)行數(shù)據(jù)更新就可以了,解決10條消息不知道應(yīng)該存幾條的問(wèn)題。在上面這個(gè)case里面,就是按照主鍵進(jìn)行更新,每次取最后一條消息。
按照row_number這種方式并不會(huì)減少數(shù)據(jù)處理量,但是會(huì)大大減少State存儲(chǔ)量,每一個(gè)State只存一份有效的狀態(tài),而不是把它所有的歷史數(shù)據(jù)都記錄下來(lái)。
② 多流join優(yōu)化
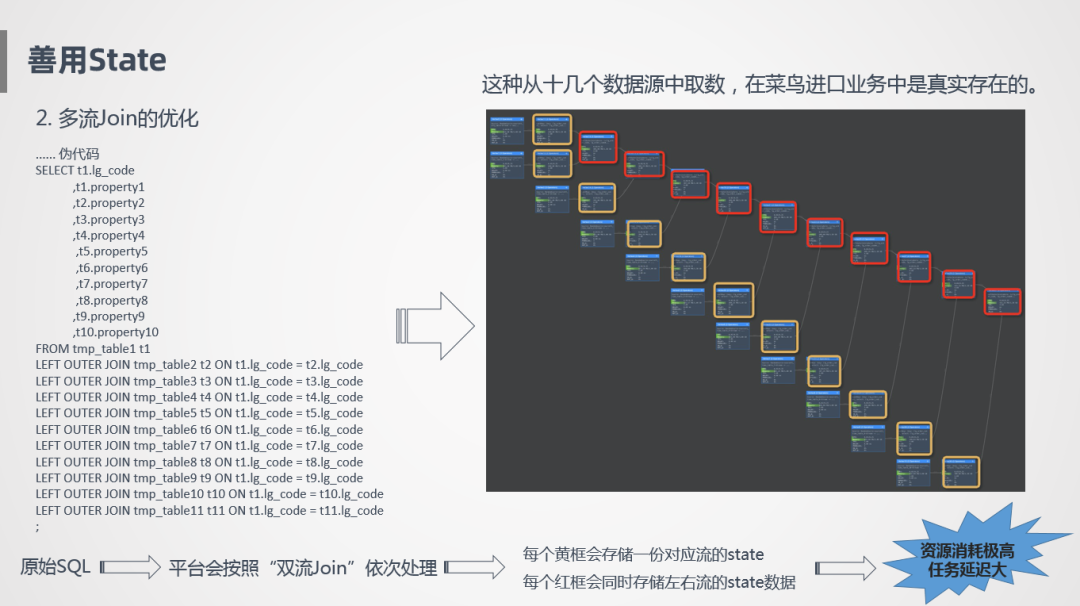
第二個(gè)是多流Join的優(yōu)化,比如像上圖左側(cè)的偽代碼,一張主表關(guān)聯(lián)很多數(shù)據(jù)源產(chǎn)生一個(gè)明細(xì)大寬表,這是我們喜歡的方式,但是這樣并不好,為什么呢?這樣一個(gè)SQL在實(shí)時(shí)計(jì)算里會(huì)按照雙流Join的方式依次處理,每次只能處理一個(gè)Join,所以像左邊這個(gè)代碼里有10個(gè)Join,在右邊就會(huì)有10個(gè)Join節(jié)點(diǎn),Join節(jié)點(diǎn)會(huì)同時(shí)將左流和右流的數(shù)據(jù)全部存下來(lái),所以會(huì)看到右邊這個(gè)圖的紅框里,每一個(gè)Join節(jié)點(diǎn)會(huì)同時(shí)存儲(chǔ)左流和右流的節(jié)點(diǎn),假設(shè)我們訂單源有1億,里面存的就是10億,這個(gè)數(shù)據(jù)量存儲(chǔ)是非常可怕的。
另外一個(gè)就是鏈路特別長(zhǎng),不停的要進(jìn)行網(wǎng)絡(luò)傳輸,計(jì)算,任務(wù)延遲也是很大的。像十幾個(gè)數(shù)據(jù)源取數(shù)關(guān)聯(lián)在一起,在我們的實(shí)際場(chǎng)景是真實(shí)存在的,而且我們的關(guān)聯(lián)關(guān)系比這個(gè)還要更復(fù)雜。
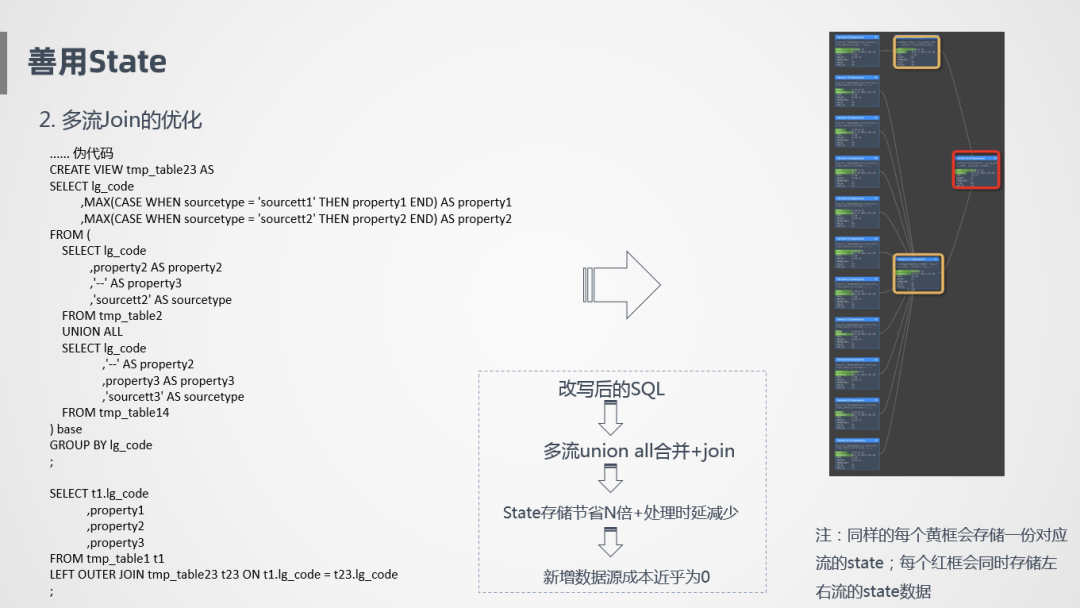
那我們?cè)趺磧?yōu)化呢?我們采用Union All的方式,把數(shù)據(jù)錯(cuò)位拼接到一起,后面加一層Group By,相當(dāng)于將Join關(guān)聯(lián)轉(zhuǎn)換成Group By,它的執(zhí)行圖就像上圖右側(cè)這樣,黃色是數(shù)據(jù)接入過(guò)程中需要進(jìn)行的存儲(chǔ),紅色是一個(gè)Join節(jié)點(diǎn),所以整個(gè)過(guò)程需要存儲(chǔ)的State是非常少的,主表會(huì)在黃色框和紅色框分別存一份,別看數(shù)據(jù)源非常多,其實(shí)只會(huì)存一份數(shù)據(jù),比如我們的物流訂單是1000萬(wàn),其他數(shù)據(jù)源也是1000萬(wàn),最終的結(jié)果有效行就是1000萬(wàn),數(shù)據(jù)存儲(chǔ)量其實(shí)是不高的,假設(shè)又新接了數(shù)據(jù)源,可能又是1000萬(wàn)的日志量,但其實(shí)有效記錄就是1000萬(wàn),只是增加了一個(gè)數(shù)據(jù)源,進(jìn)行了一個(gè)數(shù)據(jù)更新,新增數(shù)據(jù)源成本近乎為0,所以用Union All替換Join的方式在State里是一個(gè)大大的優(yōu)化。
3. 取數(shù)外鍵多,易亂序

第三個(gè)是取數(shù)外鍵多,亂序的問(wèn)題,亂序其實(shí)有很多種,采集系統(tǒng)采集過(guò)來(lái)就是亂序的,或者傳輸過(guò)程中導(dǎo)致的亂序,我們這邊要討論的是,在實(shí)際開發(fā)過(guò)程中不小心導(dǎo)致的亂序,因?yàn)槠渌麑用娴臇|西平臺(tái)已經(jīng)幫我們考慮好了,提供了很好的端到端的一致性保證。
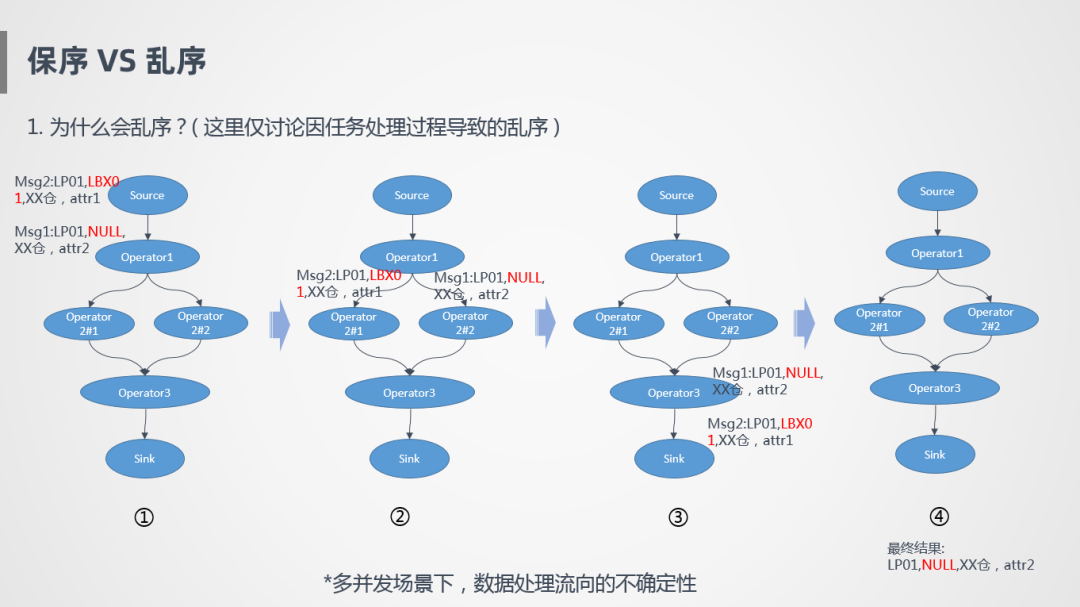
舉個(gè)例子比如說(shuō)有兩個(gè)單子都是物流單,根據(jù)單號(hào)取一些倉(cāng)內(nèi)的消息,消息1和消息2先后進(jìn)入流處理里面,關(guān)聯(lián)的時(shí)候根據(jù)JoinKey進(jìn)行Shuffle,在這種情況下,兩個(gè)消息會(huì)流到不同的算子并發(fā)上,如果這兩個(gè)并發(fā)處理速度不一致,就有可能導(dǎo)致先進(jìn)入系統(tǒng)的消息后完成處理,比如消息1先到達(dá)系統(tǒng)的,但是處理比較慢,消息2反倒先產(chǎn)出,導(dǎo)致最終的輸出結(jié)果是不對(duì)的,本質(zhì)上是多并發(fā)場(chǎng)景下,數(shù)據(jù)處理流向的不確定性,同一筆訂單的多筆消息流到不同的地方進(jìn)行計(jì)算,就可能會(huì)導(dǎo)致亂序。
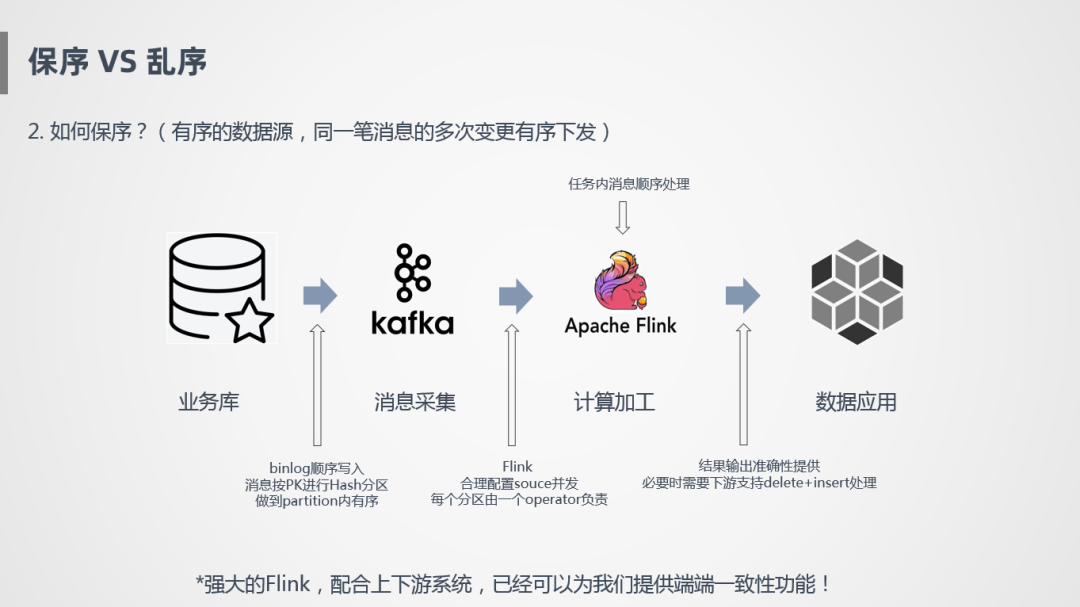
所以,同一筆訂單消息處理完之后,如何保證是有序的?
上圖是一個(gè)簡(jiǎn)化的過(guò)程,業(yè)務(wù)庫(kù)流入到Kafka,Binlog日志是順序?qū)懭氲模枰捎靡欢ǖ牟呗裕彩琼樞虿杉梢愿鶕?jù)主鍵進(jìn)行Hash分區(qū),寫到Kafka里面,保證Kafka里面每個(gè)分區(qū)存的數(shù)據(jù)是同一個(gè)Key,首先在這個(gè)層面保證有序。然后Flink消費(fèi)Kafka時(shí),需要設(shè)置合理的并發(fā),保證一個(gè)分區(qū)的數(shù)據(jù)由一個(gè)Operator負(fù)責(zé),如果一個(gè)分區(qū)由兩個(gè)Operator負(fù)責(zé),就會(huì)存在類似于剛才的情況,導(dǎo)致消息亂序。另外還要配合下游的應(yīng)用,能保證按照某些主鍵進(jìn)行更新或刪除操作,這樣才能保證端到端的一致性。
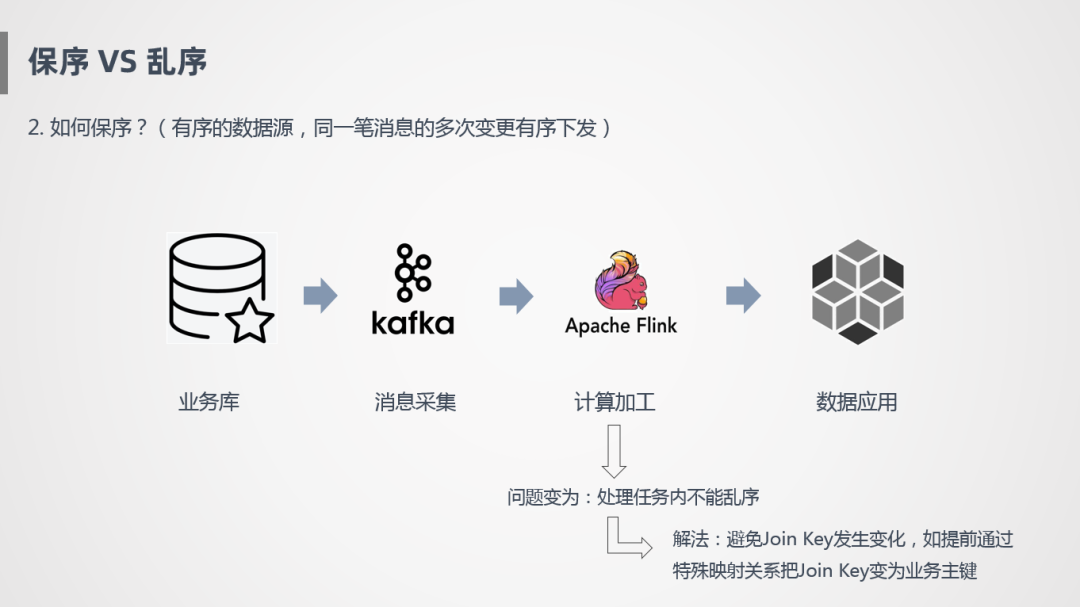
Flink已經(jīng)配合上下游系統(tǒng)已經(jīng)幫我們實(shí)現(xiàn)了端到端的一致性功能,我們只需要保證內(nèi)部處理任務(wù)不能亂序。我們的解法是避免Join Key發(fā)生變化,如提前通過(guò)特殊映射關(guān)系把Join Key變?yōu)闃I(yè)務(wù)主鍵,來(lái)保證任務(wù)處理是有序的。
4. 統(tǒng)計(jì)指標(biāo)依賴明細(xì),服務(wù)壓力大

另外一個(gè)難點(diǎn)就是我們的很多統(tǒng)計(jì)指標(biāo)都依賴明細(xì),主要是一些實(shí)時(shí)統(tǒng)計(jì),這種風(fēng)險(xiǎn)比較明顯,服務(wù)端壓力特別大,尤其是大促時(shí),極其容易把系統(tǒng)拖垮。
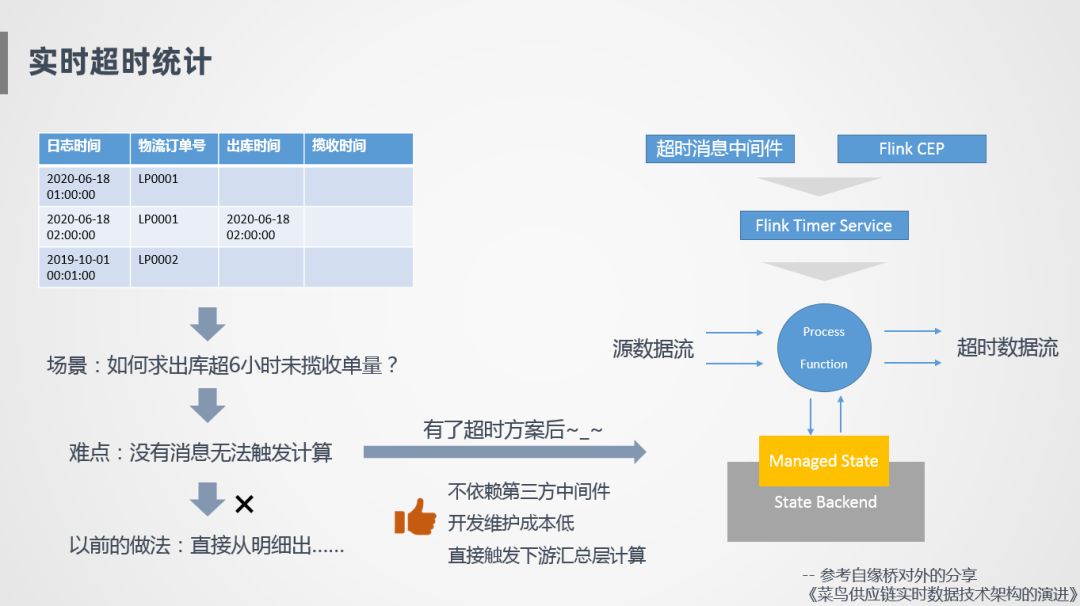
實(shí)時(shí)超時(shí)統(tǒng)計(jì)就是一個(gè)典型的場(chǎng)景,比如說(shuō)會(huì)有這樣兩筆訂單,一筆訂單1點(diǎn)鐘創(chuàng)建了物流訂單,2點(diǎn)鐘進(jìn)行出庫(kù),如何統(tǒng)計(jì)超6小時(shí)未攬收的收單量,因?yàn)闆]有消息就無(wú)法觸發(fā)計(jì)算,F(xiàn)link是基于消息觸發(fā)的,比如說(shuō)2點(diǎn)鐘出庫(kù)了,那理論上在8點(diǎn)鐘的時(shí)候超6小時(shí)未攬收的單量要加1,但是因?yàn)闆]有消息觸發(fā),下游系統(tǒng)不會(huì)觸發(fā)計(jì)算,這是比較難的事情,所以一開始沒有特別好的方案,我們直接從明細(xì)表出,比如訂單的出庫(kù)時(shí)間是2點(diǎn)鐘,生成這條明細(xì)之后,寫到數(shù)據(jù)庫(kù)的OLAP引擎里,和當(dāng)前明細(xì)進(jìn)行比較計(jì)算。
我們也探索了一些方案比如基于消息中間件,進(jìn)行一些定時(shí)超時(shí)消息下發(fā),或者也探索過(guò)基于Flink CEP的方式,第一種方式需要引入第三方的中間件,維護(hù)成本會(huì)更高,CEP這種方式采用時(shí)間窗口穩(wěn)步向前走,像我們這種物流場(chǎng)景下會(huì)存在很多這樣的情況,比如回傳一個(gè)2點(diǎn)出庫(kù)的時(shí)間,后面發(fā)現(xiàn)回傳錯(cuò)了,又會(huì)補(bǔ)一個(gè)1點(diǎn)半的時(shí)間,那么我們需要重新觸發(fā)計(jì)算,F(xiàn)link CEP是不能很好的支持的。后面我們探索了基于Flink Timer Service這種方式,基于Flink自帶的Timer Service回調(diào)方法,來(lái)制造一個(gè)消息流,首先在我們的方法里面接入數(shù)據(jù)流,根據(jù)我們定義的一些規(guī)則,比如出庫(kù)時(shí)間是2點(diǎn),會(huì)定義6小時(shí)的一個(gè)超時(shí)時(shí)間,注冊(cè)到Timer Service里面,到8點(diǎn)會(huì)觸發(fā)一次比較計(jì)算,沒有的話就會(huì)觸發(fā)一個(gè)超時(shí)消息,整個(gè)方案不依賴第三方組件,開發(fā)成本比較低。
5. 履行環(huán)節(jié)多,數(shù)據(jù)鏈路長(zhǎng)

另外一個(gè)難點(diǎn)就是我們的履行環(huán)節(jié)比較多,數(shù)據(jù)鏈路比較長(zhǎng),導(dǎo)致異常情況很難處理。比如消息要保留20多天的有效期,State也要存20多天,狀態(tài)一直存在Flink里面,如果某一天數(shù)據(jù)出現(xiàn)錯(cuò)誤或者邏輯加工錯(cuò)誤,追溯是個(gè)很大問(wèn)題,因?yàn)樯嫌蔚南⑾到y(tǒng)一般保持三天數(shù)據(jù)的有效期。

這邊說(shuō)幾個(gè)真實(shí)的案例。
案例1:
我們?cè)陔p十一期間發(fā)現(xiàn)了一個(gè)Bug,雙十一已經(jīng)過(guò)去好幾天了,因?yàn)槲覀兊穆男墟溌诽貏e長(zhǎng),要10~20天,第一時(shí)間發(fā)現(xiàn)錯(cuò)誤要改已經(jīng)改不了了,改了之后DAG執(zhí)行圖會(huì)發(fā)生變化,狀態(tài)就無(wú)法恢復(fù),而且上游只能追3天的數(shù),改了之后相當(dāng)于上游的數(shù)全沒了,這是不能接受的。
案例2:
疫情期間的一些超長(zhǎng)尾單,State的TTL設(shè)置都是60天,我們認(rèn)為60天左右肯定能夠全部完結(jié),后來(lái)發(fā)現(xiàn)超過(guò)24天數(shù)據(jù)開始失真,明明設(shè)置的有效期是60天,后來(lái)發(fā)現(xiàn)底層State存儲(chǔ)用的是int型,所以最多只能存20多天的有效期,相當(dāng)于觸發(fā)了Flink的一個(gè)邊界case,所以也證明了我們這邊的場(chǎng)景的確很復(fù)雜,很多狀態(tài)需要超長(zhǎng)的State生命周期來(lái)保證的。
案例3:
每次代碼停止升級(jí)之后,狀態(tài)就丟失了,需要重新拉取數(shù)據(jù)計(jì)算,但是一般上游的數(shù)據(jù)只保留3天有效期,這樣的話業(yè)務(wù)只能看3天的數(shù)據(jù),用戶體驗(yàn)很不好。
解決方案:批流混合
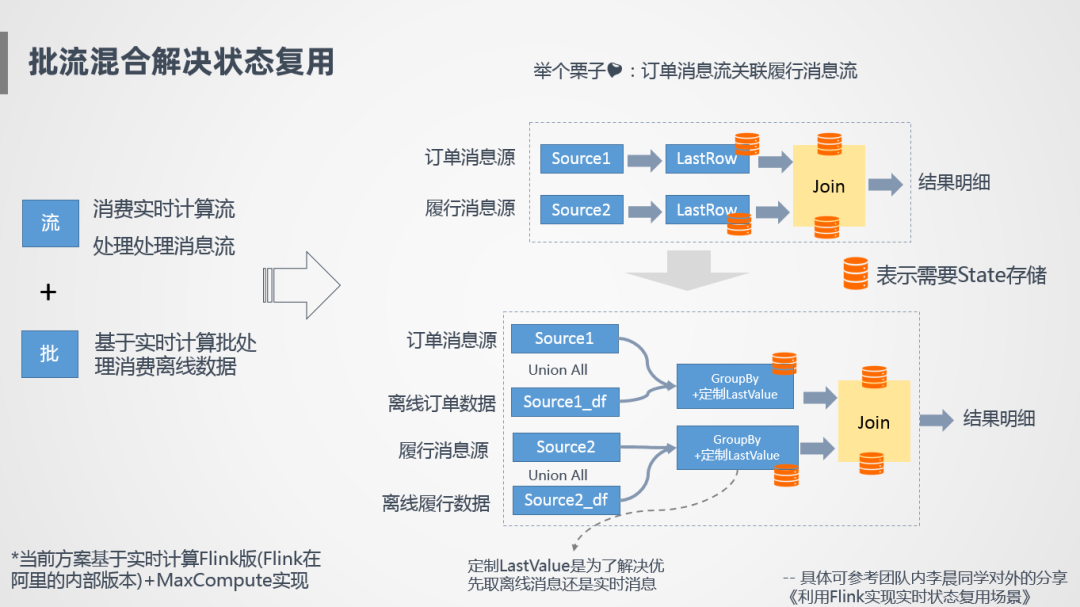
我們?cè)趺醋觯?/span>
采用批流混合的方式來(lái)完成狀態(tài)復(fù)用,基于Blink流處理來(lái)處理實(shí)時(shí)消息流,基于Blink的批處理完成離線計(jì)算,通過(guò)兩者的融合,在同一個(gè)任務(wù)里完成歷史所有數(shù)據(jù)的計(jì)算,舉個(gè)例子,訂單消息流和履行消息流進(jìn)行一個(gè)關(guān)聯(lián)計(jì)算,那么會(huì)在任務(wù)里增加一個(gè)離線訂單消息源,跟我們的實(shí)時(shí)訂單消息源Union All合并在一起,下面再增加一個(gè)Group By節(jié)點(diǎn),按照主鍵進(jìn)行去重,基于這種方式就可以實(shí)現(xiàn)狀態(tài)復(fù)用。有幾個(gè)需要注意的點(diǎn),第一個(gè)需要自定義Source Connector去開發(fā),另外一個(gè)涉及到離線消息和實(shí)時(shí)消息合并的一個(gè)問(wèn)題,GroupBy之后是優(yōu)先取離線消息還是實(shí)時(shí)消息,實(shí)時(shí)消息可能消費(fèi)的比較慢,哪個(gè)消息是真實(shí)有效的需要判斷一下,所以我們也定制了一些,比如LastValue來(lái)解決任務(wù)是優(yōu)先取離線消息還是實(shí)時(shí)消息,整個(gè)過(guò)程是基于Blink和MaxCompute來(lái)實(shí)現(xiàn)的。
6. 一些小的Tips
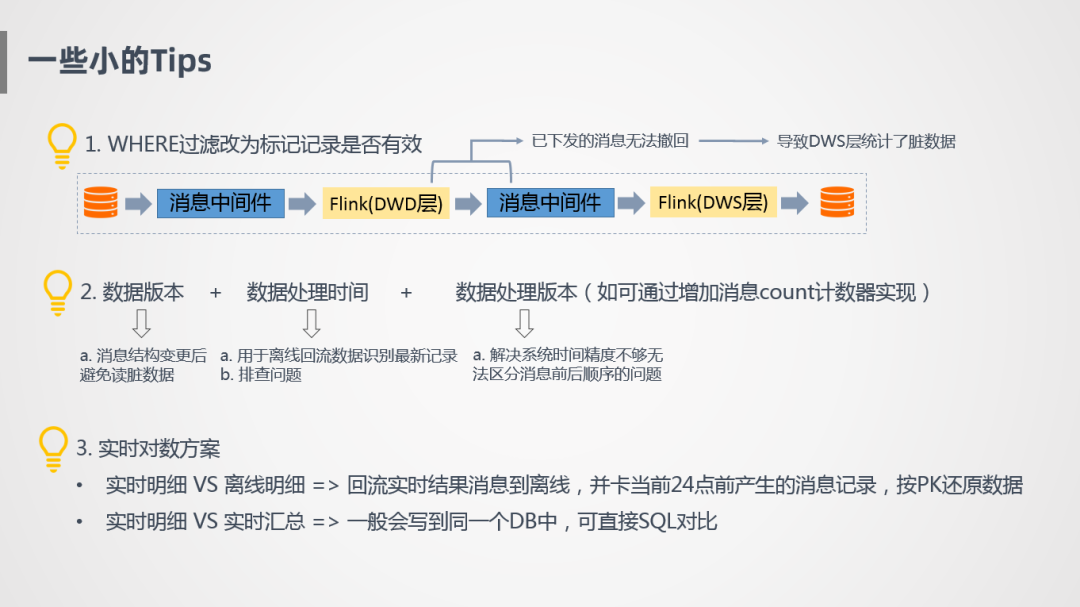
① 消息下發(fā)無(wú)法撤回問(wèn)題
第一個(gè)就是消息一旦下發(fā)無(wú)法撤回,所以有些訂單一開始有效,后面變成無(wú)效了,這種訂單不應(yīng)該在任務(wù)中過(guò)濾,而是打上標(biāo)記下傳,統(tǒng)計(jì)的時(shí)候再用。
② 增加數(shù)據(jù)版本,數(shù)據(jù)處理時(shí)間以及數(shù)據(jù)處理版本
數(shù)據(jù)版本是消息結(jié)構(gòu)體的版本定義,避免模型升級(jí)后,任務(wù)重啟讀到臟數(shù)據(jù)。
處理時(shí)間就是消息當(dāng)前的處理時(shí)間,比如消息回流到離線,我們會(huì)按照主鍵進(jìn)行時(shí)間排序,取到最新記錄,通過(guò)這種方式還原一份準(zhǔn)實(shí)時(shí)數(shù)據(jù)。
增加數(shù)據(jù)處理版本是因?yàn)榧词沟胶撩爰?jí)也不夠精確,無(wú)法區(qū)分消息的前后順序。
③ 實(shí)時(shí)對(duì)數(shù)方案
實(shí)時(shí)對(duì)數(shù)方案有兩個(gè)層面,實(shí)時(shí)明細(xì)和離線明細(xì),剛剛也提到將實(shí)時(shí)數(shù)據(jù)回流到離線,我們可以看當(dāng)前24點(diǎn)前產(chǎn)生的消息,因?yàn)殡x線T+1只能看到昨天23點(diǎn)59分59秒的數(shù)據(jù),實(shí)時(shí)也可以模擬,我們只截取那個(gè)時(shí)刻的數(shù)據(jù)還原出來(lái),然后實(shí)時(shí)和離線進(jìn)行對(duì)比,這樣也可以很好的進(jìn)行數(shù)據(jù)比對(duì),另外可以進(jìn)行實(shí)時(shí)明細(xì)和實(shí)時(shí)匯總對(duì)比,因?yàn)槎荚谕粋€(gè)DB里,對(duì)比起來(lái)也特別方便。
1. 總結(jié)

簡(jiǎn)單做下總結(jié):
模型與架構(gòu):好的模型和架構(gòu)相當(dāng)于成功了80%。
準(zhǔn)確性要求評(píng)估:需要評(píng)估數(shù)據(jù)準(zhǔn)確性要求,是否真的需要對(duì)齊CheckPoint或者一致性的語(yǔ)義保證,有些情況下保證一般準(zhǔn)確性就ok了,那么就不需要這么多額外消耗資源的設(shè)計(jì)。
合理利用Flink特性:需要合理利用Fink的一些特性,避免一些誤用之痛,比如State和CheckPoint的使用。
代碼自查:保證數(shù)據(jù)處理是正常流轉(zhuǎn)的,合乎目標(biāo)。
SQL理解:寫SQL并不是有多高大上,更多考驗(yàn)的是在數(shù)據(jù)流轉(zhuǎn)過(guò)程中的一些思考。
2. 展望
① 實(shí)時(shí)數(shù)據(jù)質(zhì)量監(jiān)控
實(shí)時(shí)處理不像批處理,批處理跑完之后可以在跑個(gè)小腳本統(tǒng)計(jì)一下主鍵是否唯一,記錄數(shù)波動(dòng)等,實(shí)時(shí)的數(shù)據(jù)監(jiān)控是比較麻煩的事情·。
② 流批統(tǒng)一
流批統(tǒng)一有幾個(gè)層面,第一個(gè)就是存儲(chǔ)層面的統(tǒng)一,實(shí)時(shí)和離線寫到同一個(gè)地方去,應(yīng)用的時(shí)候更方便。第二個(gè)就是計(jì)算引擎的統(tǒng)一,比如像Flink可以同時(shí)支持批處理和流處理,還能夠?qū)懙紿ive里面。更高層次的就是可以做到處理結(jié)果的統(tǒng)一,同一段代碼,在批和流的語(yǔ)義可能會(huì)不一樣,如何做到同一段代碼,批和流的處理結(jié)果是完全統(tǒng)一的。
③ 自動(dòng)調(diào)優(yōu)
自動(dòng)調(diào)優(yōu)有兩種,比如在大促的時(shí)候,我們申請(qǐng)了1000個(gè)Core的資源,1000個(gè)Core怎么合理的分配,哪些地方可能是性能瓶頸,要多分配一些,這是給定資源的自動(dòng)調(diào)優(yōu)。還有一種比如像凌晨沒什么單量,也沒什么數(shù)據(jù)流量,這個(gè)時(shí)候可以把資源調(diào)到很小,根據(jù)數(shù)據(jù)流量情況自動(dòng)調(diào)整,也就是自動(dòng)伸縮能力。
以上是我們整體對(duì)未來(lái)的展望和研究方向。
張庭
菜鳥 |?數(shù)據(jù)工程師