
圖像、視頻生成大一統(tǒng)!MSRA+北大全華班「女?huà)z」模型怒刷8項(xiàng)SOTA,完虐OpenAI DALL-E

??新智元報(bào)道??
??新智元報(bào)道??
編輯:好困 小咸魚(yú) LRS
【新智元導(dǎo)讀】微軟亞洲研究院、北京大學(xué)強(qiáng)強(qiáng)聯(lián)合提出了一個(gè)可以同時(shí)覆蓋語(yǔ)言、圖像和視頻的統(tǒng)一多模態(tài)預(yù)訓(xùn)練模型——NüWA(女?huà)z),直接包攬8項(xiàng)SOTA。其中,NüWA更是在文本到圖像生成中完虐OpenAI DALL-E。








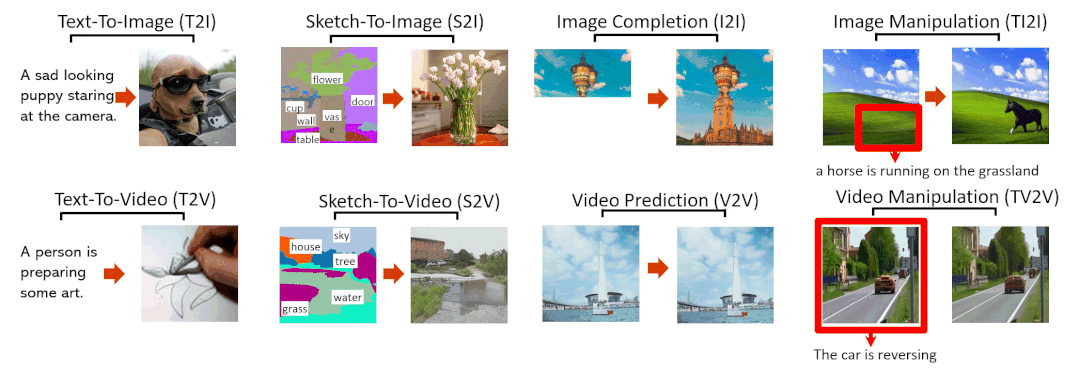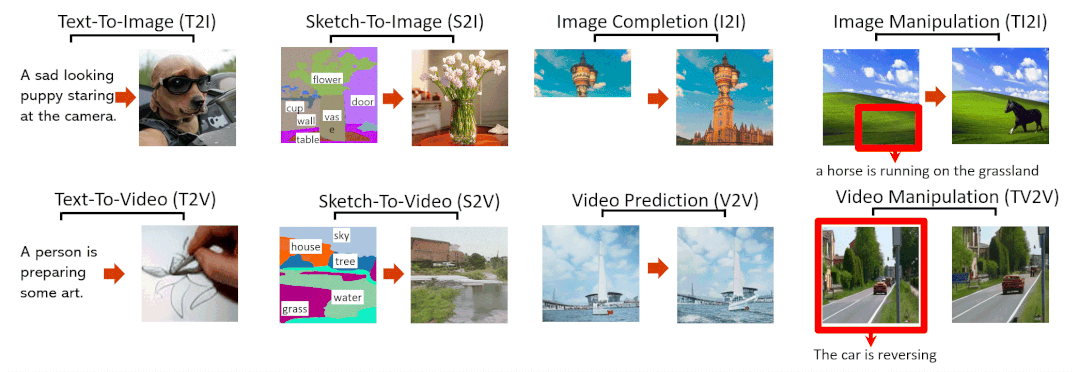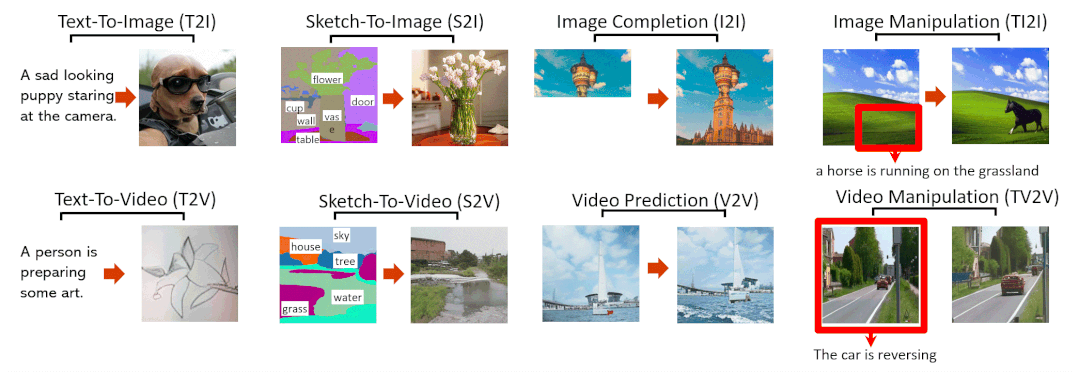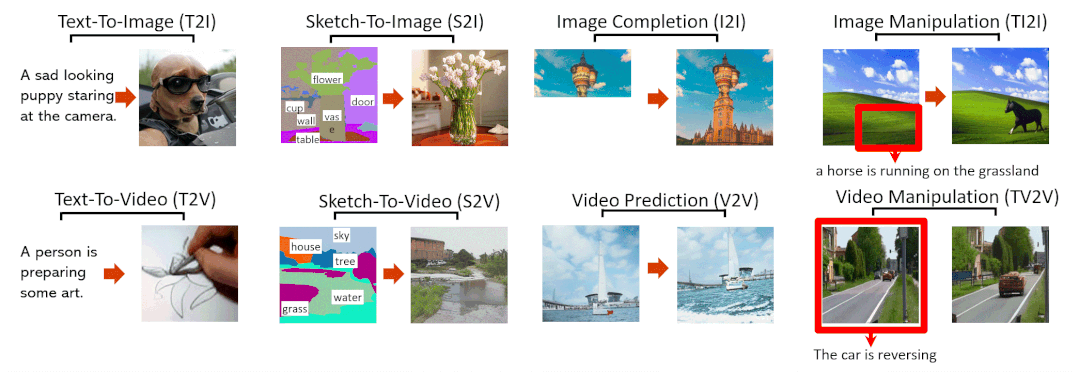
8大SOTA效果搶先看
8大SOTA效果搶先看
文字轉(zhuǎn)圖像(Text-To-Image,T2I)

草圖轉(zhuǎn)圖像(SKetch-to-Image,S2I)

圖像補(bǔ)全(Image Completion,I2I)

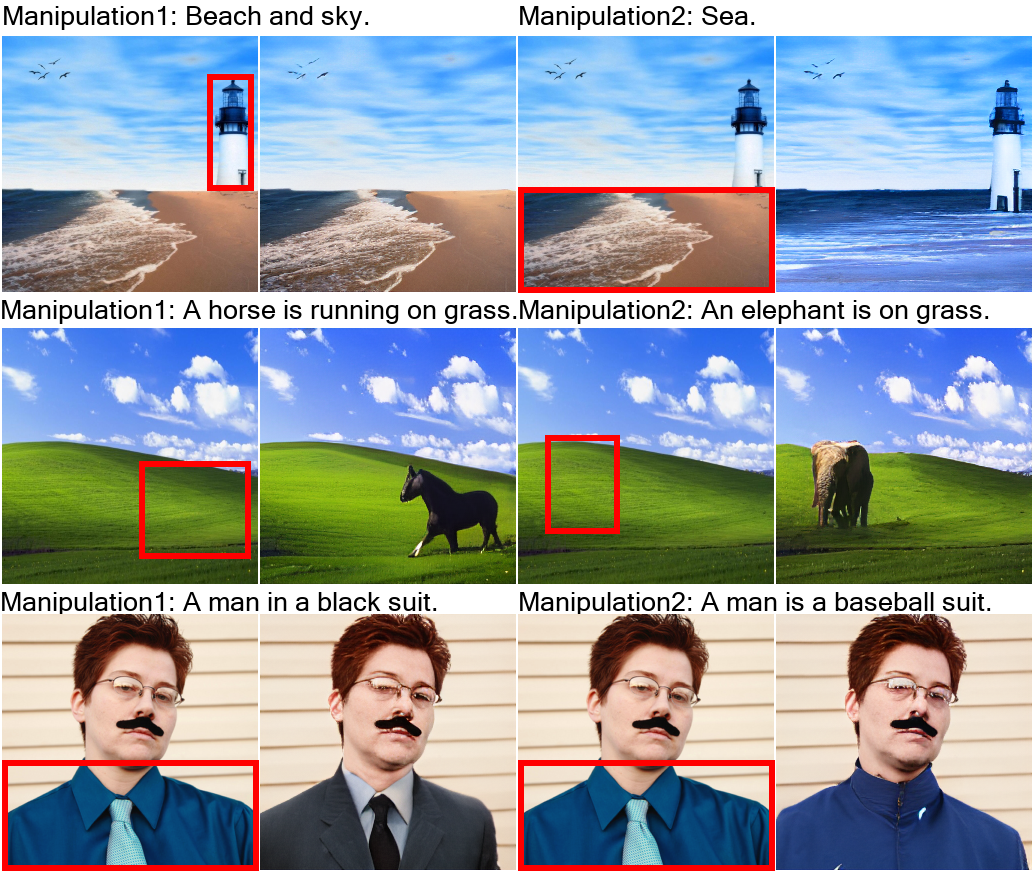
用文字指示修改圖像(Text-Guided Image Manipulation,TI2I)
文字轉(zhuǎn)視頻(Text-to-Video,T2V)
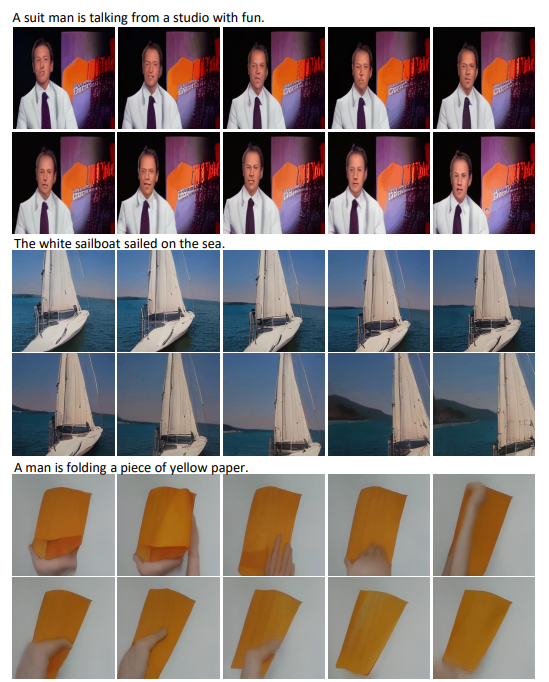
視頻預(yù)測(cè)(Video Prediction,V2V)

草圖轉(zhuǎn)視頻(Sketch-to-Video,S2V)

用文字指示修改視頻(Text-Guided Video Manipulation,TV2V)

NüWA為啥這么牛?
NüWA為啥這么牛?
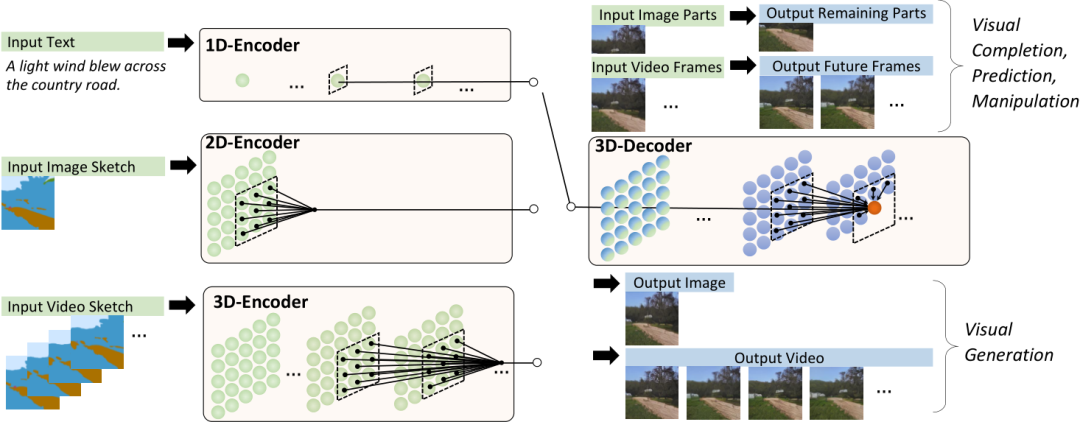
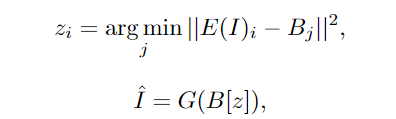

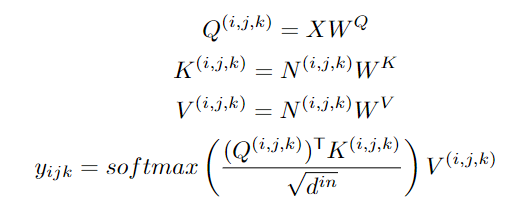
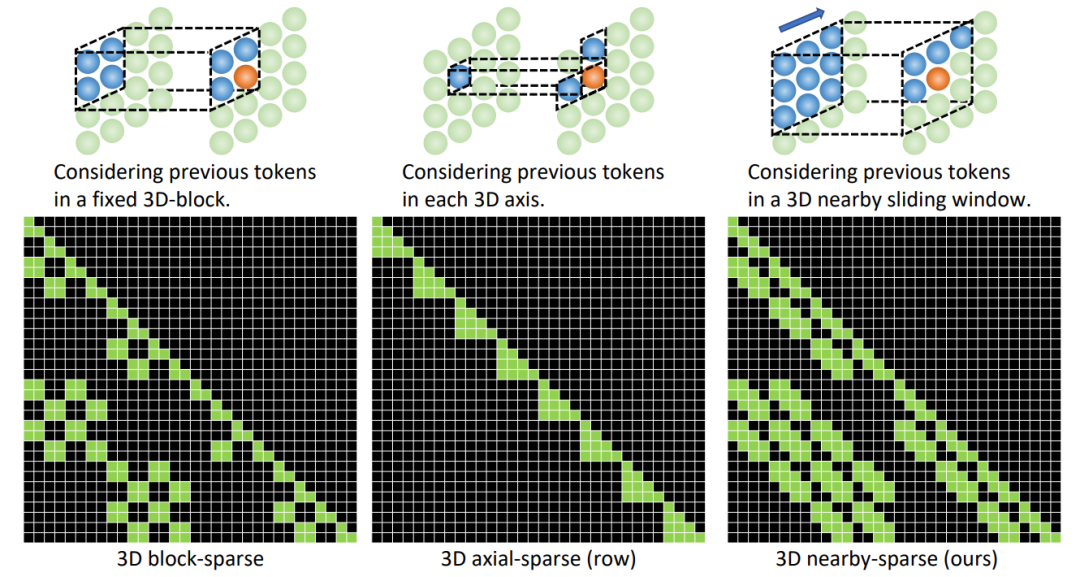
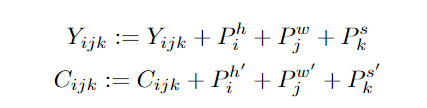
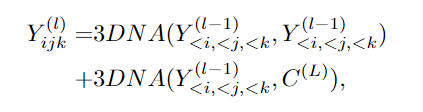
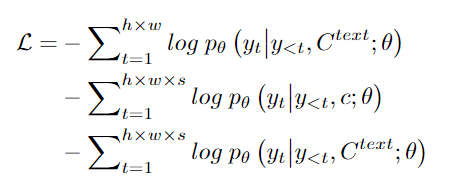
實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)結(jié)果
文本轉(zhuǎn)圖像(T2I)
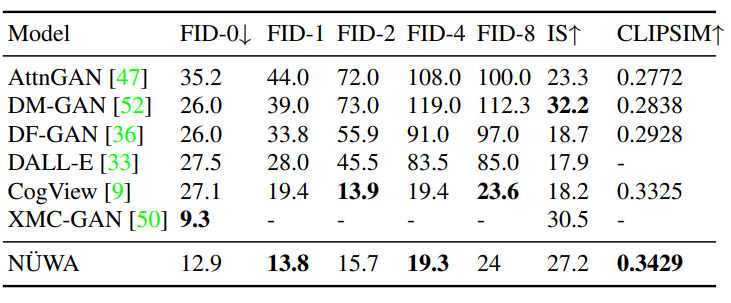

文本轉(zhuǎn)視頻(T2V)
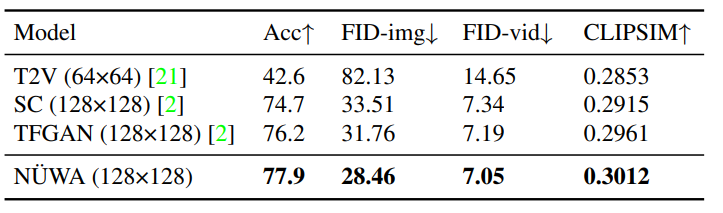

圖像補(bǔ)全(I2I)

視頻預(yù)測(cè)(V2V)
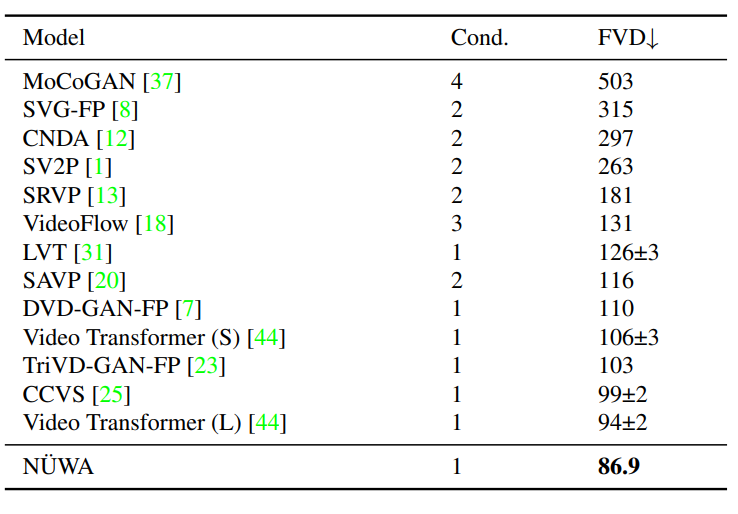
草圖轉(zhuǎn)圖像(S2I)

用文本引導(dǎo)圖像修改(TI2I)

結(jié)論
結(jié)論
P.S. 本文截圖由ReadPaper自動(dòng)截取生成(還挺好用,狗頭)。
參考資料:
https://arxiv.org/abs/2111.12417
https://github.com/microsoft/NUWA

AI能讀懂40種語(yǔ)言,15個(gè)語(yǔ)種拿下22項(xiàng)第一,背后是中國(guó)團(tuán)隊(duì)22年堅(jiān)守

評(píng)論
圖片
表情