
模型試驗 | Python 實現(xiàn)注意力機(jī)制

作者 | 李秋鍵
來源 | AI科技大本營
編輯 | 極市平臺
極市導(dǎo)讀
是否能夠從新的方向去獲取特征圖更豐富的注意力信息,或者以新的方式或手段去獲取更精準(zhǔn)的注意力信息也是未來需要關(guān)注的一個重點(diǎn)。 >>加入極市CV技術(shù)交流群,走在計算機(jī)視覺的最前沿
引言
隨著信息技術(shù)的發(fā)展,海量繁雜的信息向人們不斷襲來,信息無時無刻充斥在四周。然而人類所能接收的信息則是有限的,科研人員發(fā)現(xiàn)人類視覺系統(tǒng)在有限的視野之下卻有著龐大的視覺信息處理能力。
在處理視覺數(shù)據(jù)的初期,人類視覺系統(tǒng)會迅速將注意力集中在場景中的重要區(qū)域上,這一選擇性感知機(jī)制極大地減少了人類視覺系統(tǒng)處理數(shù)據(jù)的數(shù)量,從而使人類在處理復(fù)雜的視覺信息時能夠抑制不重要的刺激,并將有限的神經(jīng)計算資源分配給場景中的關(guān)鍵部分,為更高層次的感知推理和更復(fù)雜的視覺處理任務(wù)(如物體識別、場景分類、視頻理解等)提供更易于處理且更相關(guān)的信息。
借鑒人類視覺系統(tǒng)的這一特點(diǎn),科研人員提出了注意力機(jī)制的思想。對于事物來說特征的重要性是不同的,反映在卷積網(wǎng)絡(luò)中即每張?zhí)卣鲌D的重要性是具有差異性的。
注意力機(jī)制的核心思想是通過一定手段獲取到每張?zhí)卣鲌D重要性的差異,將神經(jīng)網(wǎng)絡(luò)的計算資源更多地投入更重要的任務(wù)當(dāng)中,并利用任務(wù)結(jié)果反向指導(dǎo)特征圖的權(quán)重更新,從而高效快速地完成相應(yīng)任務(wù)。
近兩年,注意力模型被廣泛使用在自然語言處理、圖像識別、語音識別等各種不同類型的深度學(xué)習(xí)任務(wù)當(dāng)中。
如下圖所示,顏色越深的地方表示關(guān)注度越大,即注意力的權(quán)重越大。

故本項目將通過搭建 BiLSTM 的注意力機(jī)制模型來實現(xiàn)對時間數(shù)據(jù)的格式轉(zhuǎn)換,實現(xiàn)的最終結(jié)果如下:
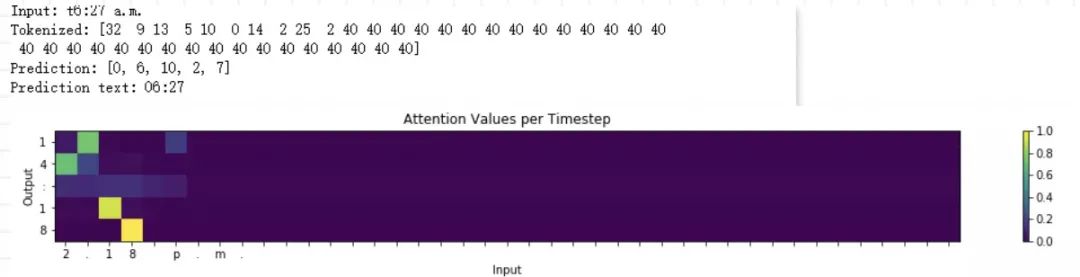
注意力機(jī)制介紹
注意力機(jī)制最初在2014年作為RNN中編碼器-解碼器框架的一部分來編碼長的輸入語句,后續(xù)被廣泛運(yùn)用在RNN中。例如在機(jī)器翻譯中通常是用一個 RNN編碼器讀入上下文,得到一個上下文向量,一個RNN解碼器以這個隱狀態(tài)為起始狀態(tài),依次生成目標(biāo)的每一個單詞。但這種做法的缺點(diǎn)是:無論之前的上下文有多長,包含多少信息量,最終都要被壓縮成一個幾百維的向量。
這意味著上下文越大,最終的狀態(tài)向量會丟失越多的信息。輸入語句長度增加后,最終解碼器翻譯的結(jié)果會顯著變差。
事實上,因為上下文在輸入時已知,一個模型完全可以在解碼的過程中利用上下文的全部信息,而不僅僅是最后一個狀態(tài)的信息,這就是注意力機(jī)制的基礎(chǔ)思想。
1.1基本方法介紹
當(dāng)前注意力機(jī)制的主流方法是將特征圖中的潛在注意力信息進(jìn)行深度挖掘,最常見的是通過各種手段獲取各個特征圖通道間的通道注意力信息與特征圖內(nèi)部像素點(diǎn)之間的空間注意力信息,獲取的方法也包括但不僅限于卷積操作,矩陣操作構(gòu)建相關(guān)性矩陣等,其共同的目的是更深層次,更全面的獲取特征圖中完善的注意力信息,于是如何更深的挖掘,從哪里去挖掘特征圖的注意力信息,將極有可能會成為未來注意力方法發(fā)展的方向之一。
目前,獲取注意力的方法基本基于通道間的注意力信息、空間像素點(diǎn)之間的注意力信息和卷積核選擇的注意力信息,是否能夠從新的方向去獲取特征圖更豐富的注意力信息,或者以新的方式或手段去獲取更精準(zhǔn)的注意力信息也是未來需要關(guān)注的一個重點(diǎn)。
模型實驗
2.1 數(shù)據(jù)處理
讀取數(shù)據(jù)集json文件,并將每一個索引轉(zhuǎn)換為對應(yīng)的one-hot編碼形式,并設(shè)置輸入數(shù)據(jù)最大長度為41。代碼如下:
with open('data/Time Dataset.json','r') as f: dataset = json.loads(f.read())with open('data/Time Vocabs.json','r') as f: human_vocab, machine_vocab = json.loads(f.read())human_vocab_size = len(human_vocab)machine_vocab_size = len(machine_vocab)m = len(dataset)def preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty): m = len(dataset) X = np.zeros([m, Tx], dtype='int32') Y = np.zeros([m, Ty], dtype='int32') for i in range(m): data = dataset[i] X[i] = np.array(tokenize(data[0], human_vocab, Tx)) Y[i] = np.array(tokenize(data[1], machine_vocab, Ty)) Xoh = oh_2d(X, len(human_vocab)) Yoh = oh_2d(Y, len(machine_vocab)) return (X, Y, Xoh, Yoh)
2.2 網(wǎng)絡(luò)模型設(shè)置
其中Tx=41為序列的最大長度,Ty=5為序列長度,layer1 size設(shè)置為32為網(wǎng)絡(luò)層,1ayer2 size=64為注意力層,human vocab size=41表述human時間會用到41個不同的字符,machine vocab size=11表述machine時間會用到11個不同的字符。這里雙向LSTM作為Encoder編碼器,全連接層作為Decoder解碼器。
代碼如下:
layer3 = Dense(machine_vocab_size, activation=softmax)def get_model(Tx, Ty, layer1_size, layer2_size, x_vocab_size, y_vocab_size): X = Input(shape=(Tx, x_vocab_size)) a1 = Bidirectional(LSTM(layer1_size, return_sequences=True), merge_mode='concat')(X) a2 = attention_layer(a1, layer2_size, Ty) a3 = [layer3(timestep) for timestep in a2] model = Model(inputs=[X], outputs=a3) return model如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標(biāo)檢測論文下載~

# CV技術(shù)社群邀請函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
