
MySQL有哪些提升性能的方法呢?
微信公眾號:歡少的成長之路
大家好,前面幾章我們介紹了關(guān)于鎖的規(guī)則優(yōu)化問題。今天我們介紹一下MySQL的那些提升性能的方法?
案例
正常的短連接模式就是連接到數(shù)據(jù)庫后,執(zhí)行很少的 SQL 語句就斷開,下次需要的時候再重連。如果使用的是短連接,在業(yè)務(wù)高峰期的時候,就可能出現(xiàn)連接數(shù)突然暴漲的情況。
MySQL 建立連接的過程,成本是很高的。除了正常的網(wǎng)絡(luò)連接三次握手外,還需要做登錄權(quán)限判斷和獲得這個連接的數(shù)據(jù)讀寫權(quán)限。
max_connections
這個參數(shù)是控制最大連接數(shù)的,一旦數(shù)據(jù)庫處理得慢一些,連接數(shù)就會暴漲。超過這個值,系統(tǒng)就會拒絕接下來的連接請求,并報錯提示“Too many connections”。對于被拒絕連接的請求來說,從業(yè)務(wù)角度看就是數(shù)據(jù)庫不可用。
在機(jī)器負(fù)載比較高的時候,處理現(xiàn)有請求的時間變長,每個連接保持的時間也更長。這時,再有新建連接的話,就可能會超過 max_connections 的限制。
解決方案
有損解決
碰到這種情況時,一個比較自然的想法,就是調(diào)高 max_connections 的值。但這樣做是有風(fēng)險的。因?yàn)樵O(shè)計 max_connections 這個參數(shù)的目的是想保護(hù) MySQL,如果我們把它改得太大,讓更多的連接都可以進(jìn)來,那么系統(tǒng)的負(fù)載可能會進(jìn)一步加大,大量的資源耗費(fèi)在權(quán)限驗(yàn)證等邏輯上,結(jié)果可能是適得其反,已經(jīng)連接的線程拿不到 CPU 資源去執(zhí)行業(yè)務(wù)的 SQL 請求。
先處理掉那些占著連接但是不工作的線程。
max_connections 的計算,不是看誰在 running,是只要連著就占用一個計數(shù)位置。對于那些不需要保持的連接,我們可以通過 kill connection 主動踢掉。這個行為跟事先設(shè)置 wait_timeout 的效果是一樣的。設(shè)置 wait_timeout 參數(shù)表示的是,一個線程空閑 wait_timeout 這么多秒之后,就會被 MySQL 直接斷開連接。
但是需要注意,在 show processlist 的結(jié)果里,踢掉顯示為 sleep 的線程,可能是有損的。我們來看下面這個例子。

sessionA
開啟一個事務(wù)并且插入一個1的記錄
sessionB
查詢id為1的數(shù)據(jù)
sessionC
查詢狀態(tài)
如果我們把sessionA關(guān)掉,那么MySQL事務(wù)就需要回滾sessionA執(zhí)行的事務(wù),
如果我們把sessionB關(guān)掉,好像對MySQL的確沒有太大的影響
結(jié)論: 應(yīng)該先關(guān)掉在事務(wù)外空閑的連接,然后再關(guān)掉事務(wù)內(nèi)的空閑連接,最終關(guān)掉那些無關(guān)緊要的查詢語句。
那么我們怎么判斷是不俗事務(wù)外的空間連接呢?
通過執(zhí)行 show processlist 根據(jù)輸出結(jié)果進(jìn)行討論分析。 圖中 id=4 和 id=5 的兩個會話都是 Sleep 狀態(tài),顯然單憑這一條方式是萬萬不夠的。那么我們就需要查詢每一個ID對應(yīng)的事務(wù)結(jié)果。看看事務(wù)內(nèi)的執(zhí)行邏輯。
圖中 id=4 和 id=5 的兩個會話都是 Sleep 狀態(tài),顯然單憑這一條方式是萬萬不夠的。那么我們就需要查詢每一個ID對應(yīng)的事務(wù)結(jié)果。看看事務(wù)內(nèi)的執(zhí)行邏輯。
看事務(wù)具體狀態(tài)的話,你可以查 information_schema 庫的 innodb_trx 表。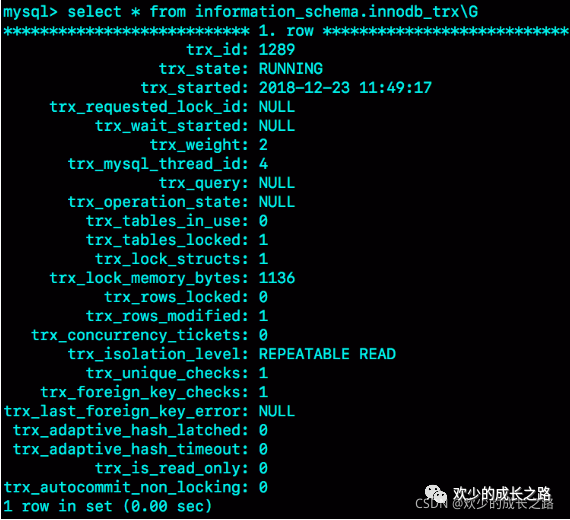
這個結(jié)果里,trx_mysql_thread_id=4,表示 id=4 的線程還處在事務(wù)中。
這個這兩種方式就可以斷定,當(dāng)前這個鏈接還在事務(wù)內(nèi)正在執(zhí)行。那么根據(jù)我們上文總結(jié)的優(yōu)先級。就可以先排除這條ID連接了。通過這種方式可以查到?jīng)]有在事務(wù)內(nèi)的正在執(zhí)行的ID
然后再通過kill connections id 即可。
服務(wù)端控制客戶端強(qiáng)行斷開之后,客戶端并沒有立馬提示,而是等下次執(zhí)行當(dāng)前連接查詢數(shù)據(jù)的時候才會提示 ERROR 2013 (HY000): Lost connection to MySQL server during query
從數(shù)據(jù)庫端主動斷開連接可能是有損的,尤其是有的應(yīng)用端收到這個錯誤后,不重新連接,而是直接用這個已經(jīng)不能用的句柄重試查詢。這會導(dǎo)致從應(yīng)用端看上去,“MySQL 一直沒恢復(fù)”。
減少連接過程的消耗。
下面我們介紹一下 –skip-grant-tables 這個參數(shù)的用法。
有些業(yè)務(wù)為了提升并發(fā)性能,考慮先從數(shù)據(jù)庫中提前申請連接。這樣就可以省去連接,校驗(yàn)等時間的限制。
那么想執(zhí)行當(dāng)前方法就需要重啟數(shù)據(jù)庫,并使用–skip-grant-tables 參數(shù)啟動。這樣整個MySQL就會跳過所有的權(quán)限驗(yàn)證(包括語句執(zhí)行)。
利弊
這樣的確可以解決性能問題,但是這樣做是非常危險的。如果暴露在外網(wǎng)的話,就更不能這么做了。
在 MySQL 8.0 版本里,如果你啟用–skip-grant-tables 參數(shù),MySQL 會默認(rèn)把 --skip-networking 參數(shù)打開,表示這時候數(shù)據(jù)庫只能被本地的客戶端連接。可見,MySQL 官方對 skip-grant-tables 這個參數(shù)的安全問題也很重視。
慢查詢
先說一下影響性能的幾大因素
因?yàn)樗饕龁栴},導(dǎo)致回表過多,掃描過多
SQL問題,導(dǎo)致慢
MySQL引擎選錯了索引。這里不懂的話去我MySQL學(xué)習(xí)專欄查找引導(dǎo)那一篇
下面我們一個一個分析
索引問題
如果是索引問題的話,那就必須重新設(shè)計索引了。因?yàn)槭窃谏a(chǎn)庫動數(shù)據(jù)結(jié)構(gòu),所以玩玩小心。肯定是不能隨隨便便就動的了。
單庫
MySQL 5.6 版本以后,創(chuàng)建索引都支持 Online DDL 了,對于那種高峰期數(shù)據(jù)庫已經(jīng)被這個語句打掛了的情況,最高效的做法就是直接執(zhí)行 alter table 語句。
多庫
最好的就是能夠在備庫先執(zhí)行。假設(shè)你現(xiàn)在的服務(wù)是一主一備,主庫 A、備庫 B,這個方案的大致流程是這樣的:
在備庫 B 上執(zhí)行 set sql_log_bin=off,也就是不寫 binlog,然后執(zhí)行 alter table 語句加上索引;
執(zhí)行主備切換;
這時候主庫是 B,備庫是 A。在 A 上執(zhí)行 set sql_log_bin=off,然后執(zhí)行 alter table 語句加上索引。
這是一個“古老”的 DDL 方案。平時在做變更的時候,你應(yīng)該考慮類似 gh-ost 這樣的方案,更加穩(wěn)妥。但是在需要緊急處理時,上面這個方案的效率是最高的。
SQL問題
這種情況還是比較好解決的。一般不會出現(xiàn)在生產(chǎn)庫發(fā)生。不過也有,下面我們介紹一下吧。
新手問題的SQL的話沒啥好說的,多跑跑explain吧。一些上點(diǎn)技術(shù)含量的話。那就是前幾篇介紹的索引莫名失效問題。主要從三個方面闡述了。隱式轉(zhuǎn)換,隱式編碼,函數(shù)操作等失效原因。
我們可以通過改寫 SQL 語句來處理。MySQL 5.7 提供了 query_rewrite 功能,可以把輸入的一種語句改寫成另外一種模式
比如,語句被錯誤地寫成了 select * from t where id + 1 = 10000,你可以通過下面的方式,增加一個語句改寫規(guī)則
insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");
call query_rewrite.flush_rewrite_rules();
query_rewrite.flush_rewrite_rules 這個是一個存儲過程,是為了讓上面的insert生效。先驗(yàn)證一下是否生效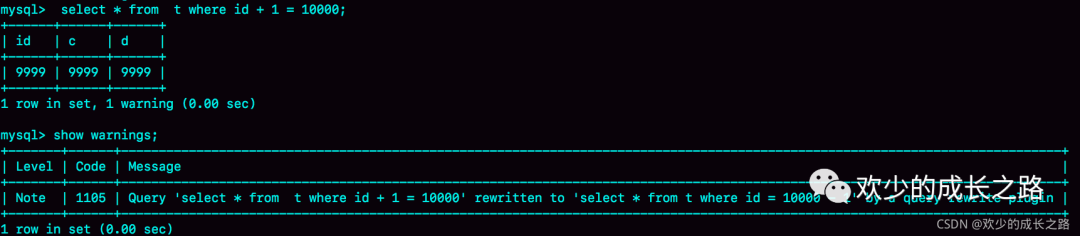
改寫成功!
選錯索引
選錯索引這里我們也介紹過了。來自《優(yōu)化器選錯索引,導(dǎo)致線上癱瘓》,可以先去復(fù)習(xí)一下。這里便于理解。
回到主題。
如果索引沒有按照我們的思路選擇索引的話,我們常用的寫法就是 加一個 force index。引導(dǎo)優(yōu)化器選擇索引。
同樣的,我們這個地方解決這個選錯索引的話也可以通過這種方式。
開發(fā)場景中常見的還是索引問題和SQL問題。一般MySQL不會選錯的。這兩種往往是比較好預(yù)防的。
上線前,在測試環(huán)境,把慢查詢?nèi)罩荆╯low log)打開,并且把 long_query_time 設(shè)置成 0,確保每個語句都會被記錄入慢查詢?nèi)罩荆?/p>
在測試表里插入模擬線上的數(shù)據(jù),做一遍回歸測試;
觀察慢查詢?nèi)罩纠锩款愓Z句的輸出,特別留意 Rows_examined 字段是否與預(yù)期一致。
不要吝嗇這段花在上線前的“額外”時間,因?yàn)檫@會幫你省下很多故障復(fù)盤的時間。
QPS
有時候由于業(yè)務(wù)突然出現(xiàn)高峰,或者應(yīng)用程序 bug,導(dǎo)致某個語句的 QPS 突然暴漲,也可能導(dǎo)致 MySQL 壓力過大,影響服務(wù)。
我之前碰到過一類情況,是由一個新功能的 bug 導(dǎo)致的。當(dāng)然,最理想的情況是讓業(yè)務(wù)把這個功能下掉,服務(wù)自然就會恢復(fù)。
而下掉一個功能,如果從數(shù)據(jù)庫端處理的話,對應(yīng)于不同的背景,有不同的方法可用。我這里再和你展開說明一下。
一種是由全新業(yè)務(wù)的 bug 導(dǎo)致的。假設(shè)你的 DB 運(yùn)維是比較規(guī)范的,也就是說白名單是一個個加的。這種情況下,如果你能夠確定業(yè)務(wù)方會下掉這個功能,只是時間上沒那么快,那么就可以從數(shù)據(jù)庫端直接把白名單去掉。
如果這個新功能使用的是單獨(dú)的數(shù)據(jù)庫用戶,可以用管理員賬號把這個用戶刪掉,然后斷開現(xiàn)有連接。這樣,這個新功能的連接不成功,由它引發(fā)的 QPS 就會變成 0。
如果這個新增的功能跟主體功能是部署在一起的,那么我們只能通過處理語句來限制。這時,我們可以使用上面提到的查詢重寫功能,把壓力最大的 SQL 語句直接重寫成"select 1"返回。
當(dāng)然,這個操作的風(fēng)險很高,需要你特別細(xì)致。它可能存在兩個副作用:
如果別的功能里面也用到了這個 SQL 語句模板,會有誤傷;
很多業(yè)務(wù)并不是靠這一個語句就能完成邏輯的,所以如果單獨(dú)把這一個語句以 select 1 的結(jié)果返回的話,可能會導(dǎo)致后面的業(yè)務(wù)邏輯一起失敗。
所以,方案 3 是用于止血的,跟前面提到的去掉權(quán)限驗(yàn)證一樣,應(yīng)該是你所有選項(xiàng)里優(yōu)先級最低的一個方案。
同時你會發(fā)現(xiàn),其實(shí)方案 1 和 2 都要依賴于規(guī)范的運(yùn)維體系:虛擬化、白名單機(jī)制、業(yè)務(wù)賬號分離。由此可見,更多的準(zhǔn)備,往往意味著更穩(wěn)定的系統(tǒng)。
總結(jié)
今天介紹了優(yōu)化使用MySQL的幾種方式。以及常見的問題解決訪問方案。都是線上的問題。