
深度強(qiáng)化學(xué)習(xí)入門介紹
深度強(qiáng)化學(xué)習(xí)是一種機(jī)器學(xué)習(xí),其中智能體(Agent,也翻譯作代理)通過(guò)執(zhí)行操作(Action)和查看結(jié)果(Reward)來(lái)學(xué)習(xí)如何在環(huán)境中采取最佳的動(dòng)作或策略。
自 2013 年Deep Q-Learning 論文[1]以來(lái),強(qiáng)化學(xué)習(xí)已經(jīng)有了很多突破。從擊敗世界上最好 Dota2 玩家的[2]OpenAI到Dexterity [3],我們正處于深度強(qiáng)化學(xué)習(xí)研究的激動(dòng)人心的時(shí)刻。
此外,由于很多開源庫(kù)(TF-智能體s, Stable-Baseline 2.0…)和仿真環(huán)境的公開:Mine強(qiáng)化學(xué)習(xí) (Minecraft), Unity ML-智能體s, OpenAI retro (NES, SNES, Genesis games…)。大家現(xiàn)在可以隨時(shí)使用仿真游戲環(huán)境來(lái)測(cè)試自己的強(qiáng)化學(xué)習(xí)程序。
在本課程中,您將通過(guò)使用 Tensorflow 和 PyTorch 來(lái)訓(xùn)練能玩太空入侵者、Minecraft、星際爭(zhēng)霸、刺猬索尼克等游戲的聰明的智能體。
在第一章中,您將學(xué)習(xí)到深度強(qiáng)化學(xué)習(xí)的基礎(chǔ)知識(shí)。在訓(xùn)練深度強(qiáng)化學(xué)習(xí)智能體之前,掌握這些深度學(xué)習(xí)的基礎(chǔ)知識(shí)非常重要。讓我們開始吧!
一.什么是強(qiáng)化學(xué)習(xí)?
為了理解什么是強(qiáng)化學(xué)習(xí),讓我們從強(qiáng)化學(xué)習(xí)的核心思想開始。
強(qiáng)化學(xué)習(xí)的核心思想是,智能體(AI)將通過(guò)與環(huán)境交互(通過(guò)反復(fù)試驗(yàn))并接收獎(jiǎng)勵(lì)(負(fù)面或正面)作為執(zhí)行動(dòng)作的反饋來(lái)從環(huán)境中學(xué)習(xí)。
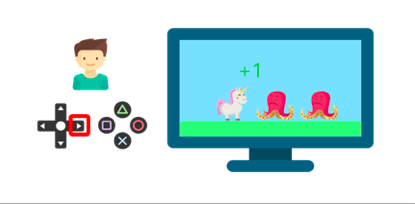
例如,想象一下你把你的弟弟放在一個(gè)他從未玩過(guò)的電子游戲面前,手里拿著一個(gè)控制器,讓他一個(gè)人呆著。

游戲場(chǎng)景
他通過(guò)按右鍵(動(dòng)作)與環(huán)境(視頻游戲)互動(dòng)。得到了一枚硬幣,這是+1的獎(jiǎng)勵(lì)。也許在這場(chǎng)比賽中,他只是知道必須得到金幣。
當(dāng)他碰到敵人時(shí),獲得-1的懲罰。
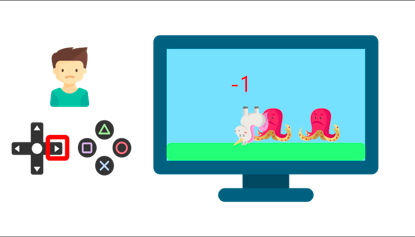
通過(guò)反復(fù)試驗(yàn)與他的環(huán)境互動(dòng),你的弟弟才明白,在這個(gè)環(huán)境中,他需要獲得金幣,但要避開敵人。
在沒(méi)有任何監(jiān)督的情況下,孩子會(huì)越來(lái)越擅長(zhǎng)玩游戲。
這就是人類和動(dòng)物通過(guò)互動(dòng)學(xué)習(xí)的方式。強(qiáng)化學(xué)習(xí)就是一種從行動(dòng)中學(xué)習(xí)的最優(yōu)解的方法。
1、正式定義
我們現(xiàn)在給出強(qiáng)化學(xué)習(xí)的一個(gè)正式的定義:
強(qiáng)化學(xué)習(xí)是一種通過(guò)構(gòu)建智能體來(lái)解決控制任務(wù)(也稱為決策問(wèn)題)的框架。智能體通過(guò)與環(huán)境互動(dòng)、反復(fù)試驗(yàn)和領(lǐng)取獎(jiǎng)勵(lì)來(lái)制定自己的策略。
但是強(qiáng)化學(xué)習(xí)是如何工作的呢?
二.強(qiáng)化學(xué)習(xí)框架
強(qiáng)化學(xué)習(xí)過(guò)程
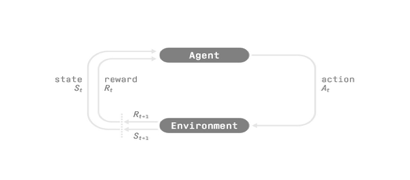
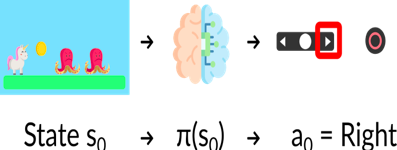
為了理解 強(qiáng)化學(xué)習(xí) 過(guò)程,讓我們想象一個(gè)智能體學(xué)習(xí)玩平臺(tái)游戲:
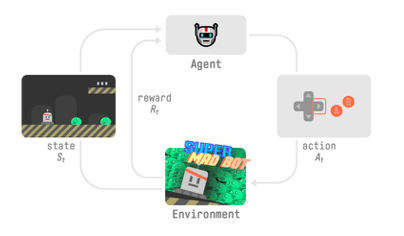
我們的智能體從環(huán)境接收狀態(tài) S0——我們接收游戲的第一幀(環(huán)境)。 基于狀態(tài) S0,智能體采取行動(dòng) A0——我們的智能體將向右移動(dòng)。 環(huán)境轉(zhuǎn)換到新狀態(tài) S1 — 新框架。 環(huán)境給了智能體一些獎(jiǎng)勵(lì) R1——我們沒(méi)有死*(Positive Reward +1)*。
這個(gè)強(qiáng)化學(xué)習(xí)循環(huán)輸出狀態(tài)、動(dòng)作和獎(jiǎng)勵(lì)以及下一個(gè)狀態(tài)的序列。
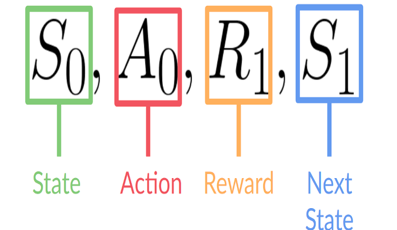
狀態(tài)、動(dòng)作、獎(jiǎng)勵(lì)、下一個(gè)狀態(tài)
2、預(yù)期回報(bào)
智能體的目標(biāo)是最大化累積獎(jiǎng)勵(lì),稱為預(yù)期回報(bào),為什么智能體的目標(biāo)是最大化預(yù)期回報(bào)?
因?yàn)閺?qiáng)化學(xué)習(xí)是基于獎(jiǎng)勵(lì)假設(shè),即所有目標(biāo)都可以描述為預(yù)期回報(bào)(預(yù)期累積獎(jiǎng)勵(lì))的最大化。這就是為什么在強(qiáng)化學(xué)習(xí)中,為了獲得最佳行為,我們需要最大化預(yù)期累積獎(jiǎng)勵(lì)。
3、觀察/狀態(tài)空間
觀察/狀態(tài)是我們的智能體從環(huán)境中獲得的信息。在視頻游戲的情況下,它可以是一張截圖,在交易智能體的情況下,它可以是某只股票的價(jià)值等。
觀察和狀態(tài)之間有一個(gè)區(qū)別:
State s:是對(duì)環(huán)境狀態(tài)的完整描述(沒(méi)有隱藏信息)。在完全觀察的環(huán)境中。

對(duì)于國(guó)際象棋游戲,我們處于完全觀察的環(huán)境中,因?yàn)槲覀兛梢栽L問(wèn)整個(gè)棋盤信息。
觀察 o:是狀態(tài)的部分描述。在部分觀察的環(huán)境中。

在《超級(jí)馬里奧兄弟》中,我們只能看到靠近玩家的關(guān)卡的一部分,因此我們收到了觀察結(jié)果。
在《超級(jí)馬里奧兄弟》中,我們只是處于一個(gè)部分觀察的環(huán)境中,我們收到了一個(gè)觀察結(jié)果,因?yàn)槲覀冎豢吹搅岁P(guān)卡的一部分。
4、行動(dòng)空間
動(dòng)作空間是環(huán)境中所有可能動(dòng)作的集合。動(dòng)作可以來(lái)自離散或連續(xù)空間:
離散空間:可能動(dòng)作的數(shù)量是有限的。

在《超級(jí)馬里奧兄弟》中,我們有一組有限的動(dòng)作,因?yàn)槲覀冎挥?4 個(gè)方向和跳躍。
連續(xù)空間:可能的動(dòng)作數(shù)量是無(wú)限的。
自動(dòng)駕駛汽車智能體有無(wú)數(shù)種可能的動(dòng)作,因?yàn)樗梢宰筠D(zhuǎn) 20°、21°、22°、鳴喇叭、右轉(zhuǎn) 20°、20,1°……

考慮這些信息是至關(guān)重要的,因?yàn)樗谖覀儗?lái)選擇強(qiáng)化學(xué)習(xí) 算法時(shí)很重要。
5、獎(jiǎng)勵(lì)和折扣因子
獎(jiǎng)勵(lì)是強(qiáng)化學(xué)習(xí)的基礎(chǔ),因?yàn)樗侵悄荏w和環(huán)境交互后的唯一反饋。有了它,我們的智能體才知道所采取的行動(dòng)是否足夠好。
每個(gè)時(shí)間步長(zhǎng) t 的累積獎(jiǎng)勵(lì)可以寫成:
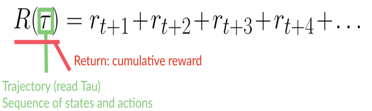
等式還可以寫成:
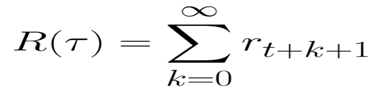
但實(shí)際上,我們不能就這樣簡(jiǎn)單累加獎(jiǎng)勵(lì)。在游戲開始時(shí)出現(xiàn)的獎(jiǎng)勵(lì)更有可能發(fā)生,因?yàn)樗鼈儽任磥?lái)的獎(jiǎng)勵(lì)更可預(yù)測(cè)。
假設(shè)您的智能體是這只小老鼠,它可以在每個(gè)時(shí)間步移動(dòng)一步,而您的對(duì)手是貓(它也可以移動(dòng))。你的目標(biāo)是在被貓吃掉之前吃掉最大量的奶酪。
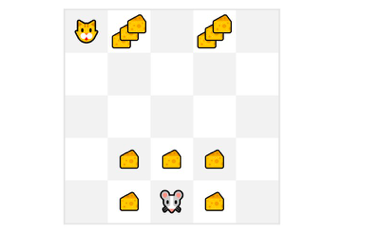
因此,靠近貓的獎(jiǎng)勵(lì),即使它更大(更多的奶酪),該獎(jiǎng)勵(lì)的風(fēng)險(xiǎn)也會(huì)更大,因?yàn)槲覀儾淮_定我們能否吃到它。為了計(jì)算這部分獎(jiǎng)勵(lì),我們定義了折扣獎(jiǎng)勵(lì)。
為了計(jì)算折扣獎(jiǎng)勵(lì),我們是這樣進(jìn)行的:
1、定義一個(gè)稱為 的γ 的折扣銀子。它必須介于 0 和 1 之間。
γ越大,折扣越小。這意味著我們的智能體更關(guān)心長(zhǎng)期獎(jiǎng)勵(lì)。另一方面,γ越小,折扣越大。這意味著我們的智能體更關(guān)心短期獎(jiǎng)勵(lì)(最近的奶酪)。
2、每個(gè)獎(jiǎng)勵(lì)將通過(guò) γ 折現(xiàn)為時(shí)間步長(zhǎng)的指數(shù)
隨著時(shí)間步長(zhǎng)的增加,貓離我們?cè)絹?lái)越近,所以未來(lái)的獎(jiǎng)勵(lì)發(fā)生的可能性越來(lái)越小。
我們的折扣累積預(yù)期獎(jiǎng)勵(lì)是:
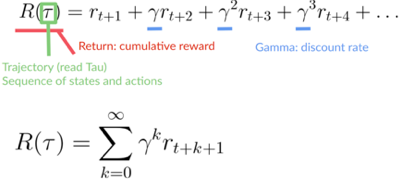
折扣累積預(yù)期獎(jiǎng)勵(lì)
6、任務(wù)類型
任務(wù)是強(qiáng)化學(xué)習(xí)問(wèn)題的一個(gè)實(shí)例。我們可以有兩種類型的任務(wù):離散的和連續(xù)的。
離散任務(wù),在這種情況下,我們有一個(gè)起點(diǎn)和一個(gè)終點(diǎn)(終止?fàn)顟B(tài))。這將創(chuàng)建一個(gè)序列:狀態(tài)、操作、獎(jiǎng)勵(lì)和新狀態(tài)。
例如,在《超級(jí)馬里奧兄弟》游戲中,這個(gè)序列從新馬里奧關(guān)卡開始,并馬里奧被殺或到達(dá)關(guān)卡終點(diǎn)時(shí)結(jié)束。

連續(xù)任務(wù),這些是永遠(yuǎn)持續(xù)的任務(wù)(沒(méi)有終止?fàn)顟B(tài))。在這種情況下,智能體必須學(xué)習(xí)如何選擇最佳動(dòng)作并隨時(shí)與環(huán)境交互。
例如,進(jìn)行自動(dòng)股票交易的智能體。對(duì)于這個(gè)任務(wù),沒(méi)有起點(diǎn)和終點(diǎn)。智能體一直運(yùn)行,直到我們決定關(guān)閉它。
7、探索/利用權(quán)衡
最后,在研究強(qiáng)化學(xué)習(xí)解決問(wèn)題的不同方法之前,我們必須討論一個(gè)非常重要的點(diǎn):探索/利用。
探索是通過(guò)嘗試隨機(jī)動(dòng)作來(lái)探索環(huán)境,以找到有關(guān)環(huán)境的更多信息。利用是根據(jù)已知的信息來(lái)最大化獎(jiǎng)勵(lì)。
我們強(qiáng)化學(xué)習(xí)智能體的目標(biāo)是最大化預(yù)期累積獎(jiǎng)勵(lì)。然而,我們可能會(huì)陷入一個(gè)陷阱。

在這個(gè)游戲中,我們的老鼠可以擁有無(wú)限量的小奶酪(每個(gè)+1)。但是在迷宮的頂部,有一堆大奶酪(+1000)。
如果我們只專注于利用,我們的智能體永遠(yuǎn)到不了大奶酪那里(探索)。它只會(huì)獲取最近的獎(jiǎng)勵(lì),即使這個(gè)獎(jiǎng)勵(lì)很小(利用)。
但是如果我們的智能體做一點(diǎn)探索,它可以發(fā)現(xiàn)更大的獎(jiǎng)勵(lì)(一堆大奶酪)。
這就是我們所說(shuō)的探索/利用的權(quán)衡。我們需要平衡對(duì)環(huán)境的探索程度和對(duì)環(huán)境的了解程度。
因此,我們必須定義一個(gè)規(guī)則來(lái)處理這種情況。我們將在以后的章節(jié)中看到不同的處理方式。如果這個(gè)問(wèn)題令人困惑,請(qǐng)考慮一個(gè)真正的問(wèn)題:餐廳的選擇。
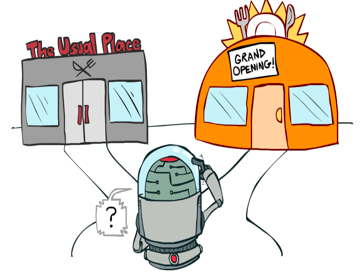
利用:每天都去同一家您認(rèn)為不錯(cuò)的餐廳,并冒著錯(cuò)過(guò)另一家更好餐廳的風(fēng)險(xiǎn)。
探索:嘗試以前從未去過(guò)的餐廳,冒著體驗(yàn)不好的風(fēng)險(xiǎn),但可能有機(jī)會(huì)獲得美妙的體驗(yàn)。
三、解決強(qiáng)化學(xué)習(xí)問(wèn)題的兩種主要方法
既然我們學(xué)習(xí)了強(qiáng)化學(xué)習(xí)框架,那么我們?nèi)绾谓鉀Q強(qiáng)化學(xué)習(xí)問(wèn)題呢?換句話說(shuō),如何構(gòu)建一個(gè)可以選擇最大化其預(yù)期累積獎(jiǎng)勵(lì)的動(dòng)作的強(qiáng)化學(xué)習(xí)智能體?
1、策略π:智能體的大腦
策略π是我們智能體的大腦,它是告訴我們?cè)诮o定狀態(tài)下要采取什么行動(dòng)的函數(shù)。所以它定義了在給定一段時(shí)間內(nèi)的智能體行為。
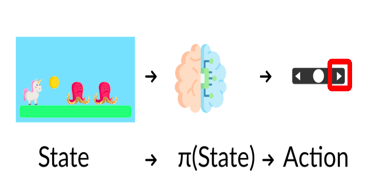
狀態(tài)、策略、動(dòng)作
將策略視為我們智能體的大腦,該功能將告訴我們?cè)诮o定狀態(tài)下采取的行動(dòng),這個(gè)策略π就是我們要學(xué)習(xí)的函數(shù),我們的目標(biāo)是找到最優(yōu)策略π*,當(dāng)智能體按照它行動(dòng)時(shí),是期望收益最大化的策略。我們通過(guò)訓(xùn)練找到了這個(gè)π*。
有兩種方法可以訓(xùn)練我們的智能體來(lái)找到這個(gè)最優(yōu)策略π*:
直接地,基于策略的方法:通過(guò)教智能體學(xué)習(xí)在給定狀態(tài)下要采取的行動(dòng)。 間接地,基于價(jià)值的方法:教智能體了解哪個(gè)狀態(tài)更有價(jià)值,然后采取會(huì)出現(xiàn)更有價(jià)值狀態(tài)的行動(dòng)。
2、基于策略的方法
在基于策略的方法中,我們直接學(xué)習(xí)策略函數(shù)。該函數(shù)將從每個(gè)狀態(tài)映射到該狀態(tài)的最佳對(duì)應(yīng)動(dòng)作,或者該狀態(tài)下一組可能動(dòng)作的概率分布。
正如我們?cè)谶@里看到的,策略(確定性的)直接指示每一步要采取的行動(dòng)。
我們有兩種類型的策略:
確定地:在給定狀態(tài)下該策略將始終返回相同的操作。
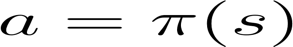
給定狀態(tài)下輸出動(dòng)作
隨機(jī)地:在給定狀態(tài)下該該策略輸出動(dòng)作的概率分布。

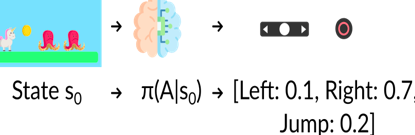
給定一個(gè)初始狀態(tài),隨機(jī)策略將輸出該狀態(tài)下可能動(dòng)作的概率分布
3、基于價(jià)值的方法
在基于價(jià)值的方法中,我們不是訓(xùn)練策略函數(shù),而是訓(xùn)練一個(gè)將狀態(tài)映射到處于該狀態(tài)的預(yù)期值的值函數(shù)。
一個(gè)狀態(tài)的價(jià)值是如果智能體從該狀態(tài)開始,根據(jù)我們的策略采取行動(dòng),它可以獲得的最大的折扣累積預(yù)期獎(jiǎng)勵(lì)。
“按照我們的策略行事”意味著我們的策略是“走向價(jià)值最高的”。
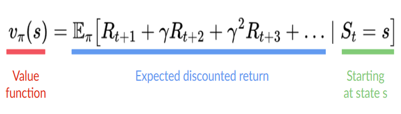
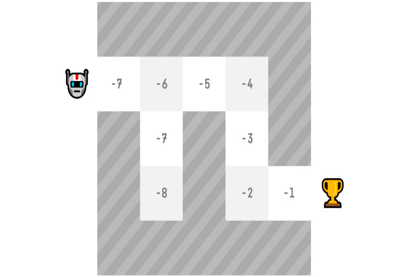
有了我們的價(jià)值函數(shù),在每一步,我們的策略都會(huì)選擇價(jià)值函數(shù)定義的具有最大價(jià)值的狀態(tài):-7,然后是-6,然后是-5(等等)來(lái)實(shí)現(xiàn)目標(biāo)。
四、強(qiáng)化學(xué)習(xí)的“深度”
談到了強(qiáng)化學(xué)習(xí),但我們?yōu)槭裁匆務(wù)撋疃葟?qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)引入了深度神經(jīng)網(wǎng)絡(luò)來(lái)解決強(qiáng)化學(xué)習(xí)問(wèn)題——因此得名“深度”。
例如,在下一篇文章中,我們將研究 Q-Learning(經(jīng)典強(qiáng)化學(xué)習(xí))和 Deep Q-Learning,兩者都是基于價(jià)值的強(qiáng)化學(xué)習(xí)算法。
您會(huì)看到不同之處在于,在第一種方法中,我們使用傳統(tǒng)算法來(lái)創(chuàng)建 Q 表,以幫助我們找到對(duì)每個(gè)狀態(tài)要采取的操作。
在第二種方法中,我們將使用神經(jīng)網(wǎng)絡(luò)(來(lái)近似 q 值)。
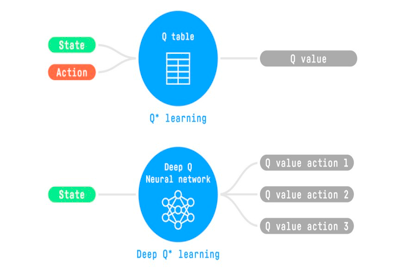
Q-Learning和 Deep Q-Learning
五、總結(jié)
我們總結(jié)一下今天學(xué)到的知識(shí):
強(qiáng)化學(xué)習(xí)是一種從行動(dòng)中學(xué)習(xí)的計(jì)算方法。我們構(gòu)建了一個(gè)智能體,它通過(guò)反復(fù)試驗(yàn)與環(huán)境交互并接收獎(jiǎng)勵(lì)(負(fù)面或正面)作為反饋,從環(huán)境中學(xué)習(xí)到動(dòng)作的好壞。
任何強(qiáng)化學(xué)習(xí)智能體的目標(biāo)都是最大化其預(yù)期累積獎(jiǎng)勵(lì)(也稱為預(yù)期回報(bào)),因?yàn)閺?qiáng)化學(xué)習(xí)基于獎(jiǎng)勵(lì)假設(shè),所有目標(biāo)都可以描述為預(yù)期累積獎(jiǎng)勵(lì)的最大化。
強(qiáng)化學(xué)習(xí)過(guò)程是一個(gè)循環(huán),可以定義為:狀態(tài)、動(dòng)作、獎(jiǎng)勵(lì)和下一個(gè)狀態(tài)的序列。
為了計(jì)算預(yù)期累積獎(jiǎng)勵(lì)(預(yù)期回報(bào)),我們對(duì)獎(jiǎng)勵(lì)打折:較早(在游戲開始時(shí))出現(xiàn)的獎(jiǎng)勵(lì)更有可能發(fā)生,因?yàn)樗鼈儽乳L(zhǎng)期未來(lái)獎(jiǎng)勵(lì)更可預(yù)測(cè)。
要解決強(qiáng)化學(xué)習(xí)問(wèn)題,需要找到最佳策略,策略是智能體的“大腦”,它會(huì)告訴我們?cè)诮o定狀態(tài)下要采取什么行動(dòng)。最佳的一種策略能提供最大化預(yù)期回報(bào)的行動(dòng)。
有兩種方法可以找到最佳策略:
通過(guò)直接訓(xùn)練的策略:基于策略的方法。
通過(guò)訓(xùn)練一個(gè)價(jià)值函數(shù),告訴我們智能體在每個(gè)狀態(tài)下將獲得的預(yù)期回報(bào),并使用這個(gè)函數(shù)來(lái)定義我們的策略:基于價(jià)值的方法。
最后,我們談?wù)撋疃葟?qiáng)化學(xué)習(xí),因?yàn)槲覀円肓松疃壬窠?jīng)網(wǎng)絡(luò)來(lái)估計(jì)要采取的動(dòng)作(基于策略)或估計(jì)狀態(tài)的值(基于值),因此稱為“深度”。
參考資料
[1]Deep Q-Learning 論文:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
[2]擊敗世界上最好 Dota2 玩家的:
https://www.twitch.tv/videos/293517383
[3]Dexterity :
https://openai.com/blog/learning-dexterity/
[4]打敗了世界上最好的 Dota2 玩家:
https://www.twitch.tv/videos/293517383
原文鏈接:
https://thomassimonini.medium.com/an-introduction-to-deep-reinforcement-learning-17a565999c0c
- EOF -
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: