
SQL索引一步到位
SQL索引在數(shù)據(jù)庫(kù)優(yōu)化中占有一個(gè)非常大的比例, 一個(gè)好的索引的設(shè)計(jì),可以讓你的效率提高幾十甚至幾百倍,在這里將帶你一步步揭開他的神秘面紗。
1.1 什么是索引?
SQL索引有兩種,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系統(tǒng)的性能,加快數(shù)據(jù)的查詢速度與減少系統(tǒng)的響應(yīng)時(shí)間
下面舉兩個(gè)簡(jiǎn)單的例子:
圖書館的例子:一個(gè)圖書館那么多書,怎么管理呢?建立一個(gè)字母開頭的目錄,例如:a開頭的書,在第一排,b開頭的在第二排,這樣在找什么書就好說(shuō)了,這個(gè)就是一個(gè)聚集索引,可是很多人借書找某某作者的,不知道書名怎么辦?圖書管理員在寫一個(gè)目錄,某某作者的書分別在第幾排,第幾排,這就是一個(gè)非聚集索引
字典的例子:字典前面的目錄,可以按照拼音和部首去查詢,我們想查詢一個(gè)字,只需要根據(jù)拼音或者部首去查詢,就可以快速的定位到這個(gè)漢字了,這個(gè)就是索引的好處,拼音查詢法就是聚集索引,部首查詢就是一個(gè)非聚集索引.
看了上面的例子,下面的一句話大家就很容易理解了:聚集索引存儲(chǔ)記錄是物理上連續(xù)存在,而非聚集索引是邏輯上的連續(xù),物理存儲(chǔ)并不連續(xù)。就像字段,聚集索引是連續(xù)的,a后面肯定是b,非聚集索引就不連續(xù)了,就像圖書館的某個(gè)作者的書,有可能在第1個(gè)貨架上和第10個(gè)貨架上。還有一個(gè)小知識(shí)點(diǎn)就是:聚集索引一個(gè)表只能有一個(gè),而非聚集索引一個(gè)表可以存在多個(gè)。
1.2 索引的存儲(chǔ)機(jī)制
首先,無(wú)索引的表,查詢時(shí),是按照順序存續(xù)的方法掃描每個(gè)記錄來(lái)查找符合條件的記錄,這樣效率十分低下,舉個(gè)例子,如果我們將字典的漢字隨即打亂,沒(méi)有前面的按照拼音或者部首查詢,那么我們想找一個(gè)字,按照順序的方式去一頁(yè)頁(yè)的找,這樣效率有多底,大家可以想象。
聚集索引和非聚集索引的根本區(qū)別是表記錄的排列順序和與索引的排列順序是否一致,其實(shí)理解起來(lái)非常簡(jiǎn)單,還是舉字典的例子:如果按照拼音查詢,那么都是從a-z的,是具有連續(xù)性的,a后面就是b,b后面就是c, 聚集索引就是這樣的,他是和表的物理排列順序是一樣的,例如有id為聚集索引,那么1后面肯定是2,2后面肯定是3,所以說(shuō)這樣的搜索順序的就是聚集索引。非聚集索引就和按照部首查詢是一樣是,可能按照偏房查詢的時(shí)候,根據(jù)偏旁‘弓’字旁,索引出兩個(gè)漢字,張和弘,但是這兩個(gè)其實(shí)一個(gè)在100頁(yè),一個(gè)在1000頁(yè),(這里只是舉個(gè)例子),他們的索引順序和數(shù)據(jù)庫(kù)表的排列順序是不一樣的,這個(gè)樣的就是非聚集索引。
原理明白了,那他們是怎么存儲(chǔ)的呢?在這里簡(jiǎn)單的說(shuō)一下,聚集索引就是在數(shù)據(jù)庫(kù)被開辟一個(gè)物理空間存放他的排列的值,例如1-100,所以當(dāng)插入數(shù)據(jù)時(shí),他會(huì)重新排列整個(gè)整個(gè)物理空間,而非聚集索引其實(shí)可以看作是一個(gè)含有聚集索引的表,他只僅包含原表中非聚集索引的列和指向?qū)嶋H物理表的指針。他只記錄一個(gè)指針,其實(shí)就有點(diǎn)和堆棧差不多的感覺(jué)了
1.3 什么情況下設(shè)置索引
動(dòng)作描述 | 使用聚集索引 | 使用非聚集索引 |
外鍵列 | 應(yīng) | 應(yīng) |
主鍵列 | 應(yīng) | 應(yīng) |
列經(jīng)常被分組排序(order by) | 應(yīng) | 應(yīng) |
返回某范圍內(nèi)的數(shù)據(jù) | 應(yīng) | 不應(yīng) |
小數(shù)目的不同值 | 應(yīng) | 不應(yīng) |
大數(shù)目的不同值 | 不應(yīng) | 應(yīng) |
頻繁更新的列 | 不應(yīng) | 應(yīng) |
頻繁修改索引列 | 不應(yīng) | 應(yīng) |
一個(gè)或極少不同值 | 不應(yīng) | 不應(yīng) |
建立索引的原則:
1) 定義主鍵的數(shù)據(jù)列一定要建立索引。
2) 定義有外鍵的數(shù)據(jù)列一定要建立索引。
3) 對(duì)于經(jīng)常查詢的數(shù)據(jù)列最好建立索引。
4) 對(duì)于需要在指定范圍內(nèi)的快速或頻繁查詢的數(shù)據(jù)列;
5) 經(jīng)常用在WHERE子句中的數(shù)據(jù)列。
6) 經(jīng)常出現(xiàn)在關(guān)鍵字order by、group by、distinct后面的字段,建立索引。如果建立的是復(fù)合索引,索引的字段順序要和這些關(guān)鍵字后面的字段順序一致,否則索引不會(huì)被使用。
7) 對(duì)于那些查詢中很少涉及的列,重復(fù)值比較多的列不要建立索引。
8) 對(duì)于定義為text、image和bit的數(shù)據(jù)類型的列不要建立索引。
9) 對(duì)于經(jīng)常存取的列避免建立索引
9) 限制表上的索引數(shù)目。對(duì)一個(gè)存在大量更新操作的表,所建索引的數(shù)目一般不要超過(guò)3個(gè),最多不要超過(guò)5個(gè)。索引雖說(shuō)提高了訪問(wèn)速度,但太多索引會(huì)影響數(shù)據(jù)的更新操作。
10) 對(duì)復(fù)合索引,按照字段在查詢條件中出現(xiàn)的頻度建立索引。在復(fù)合索引中,記錄首先按照第一個(gè)字段排序。對(duì)于在第一個(gè)字段上取值相同的記錄,系統(tǒng)再按照第二個(gè)字段的取值排序,以此類推。因此只有復(fù)合索引的第一個(gè)字段出現(xiàn)在查詢條件中,該索引才可能被使用,因此將應(yīng)用頻度高的字段,放置在復(fù)合索引的前面,會(huì)使系統(tǒng)最大可能地使用此索引,發(fā)揮索引的作用。
1.4 如何創(chuàng)建索引
1.41 創(chuàng)建索引的語(yǔ)法:
CREATE [UNIQUE][CLUSTERED | NONCLUSTERED] INDEX index_name
ON {table_name | view_name} [WITH [index_property [,....n]]
說(shuō)明:
UNIQUE: 建立唯一索引。
CLUSTERED: 建立聚集索引。
NONCLUSTERED: 建立非聚集索引。
Index_property: 索引屬性。
UNIQUE索引既可以采用聚集索引結(jié)構(gòu),也可以采用非聚集索引的結(jié)構(gòu),如果不指明采用的索引結(jié)構(gòu),則SQL Server系統(tǒng)默認(rèn)為采用非聚集索引結(jié)構(gòu)。
1.42 刪除索引語(yǔ)法:
DROP INDEX table_name.index_name[,table_name.index_name]
說(shuō)明:table_name: 索引所在的表名稱。
index_name : 要?jiǎng)h除的索引名稱。
1.43 顯示索引信息:
使用系統(tǒng)存儲(chǔ)過(guò)程:sp_helpindex 查看指定表的索引信息。
執(zhí)行代碼如下:
Exec sp_helpindex book1;
1.5 索引使用次數(shù)、索引效率、占用CPU檢測(cè)、索引缺失
當(dāng)我們明白了什么是索引,什么時(shí)間創(chuàng)建索引以后,我們就會(huì)想,我們創(chuàng)建的索引到底效率執(zhí)行的怎么樣?好不好?我們創(chuàng)建的對(duì)不對(duì)?
首先我們來(lái)認(rèn)識(shí)一下DMV,DMV (dynamic management view)動(dòng)態(tài)管理視圖和函數(shù)返回特定于實(shí)現(xiàn)的內(nèi)部狀態(tài)數(shù)據(jù)。推出SQL Server 2005時(shí),微軟介紹了許多被稱為dmvs的系統(tǒng)視圖,讓您可以探測(cè)SQL Server 的健康狀況,診斷問(wèn)題,或查看SQL Server實(shí)例的運(yùn)行信息。統(tǒng)計(jì)數(shù)據(jù)是在SQL Server運(yùn)行的時(shí)候開始收集的,并且在SQL Server每次啟動(dòng)的時(shí)候,統(tǒng)計(jì)數(shù)據(jù)將會(huì)被重置。當(dāng)你刪除或者重新創(chuàng)建其組件時(shí),某些dmv的統(tǒng)計(jì)數(shù)據(jù)也可以被重置,例如存儲(chǔ)過(guò)程和表,而其它的dmv信息在運(yùn)行dbcc命令時(shí)也可以被重置。
當(dāng)你使用一個(gè)dmv時(shí),你需要緊記SQL Server收集這些信息有多長(zhǎng)時(shí)間了,以確定這些從dmv返回的數(shù)據(jù)到底有多少可用性。如果SQL Server只運(yùn)行了很短的一段時(shí)間,你可能不想去使用一些dmv統(tǒng)計(jì)數(shù)據(jù),因?yàn)樗麄儾⒉皇且粋€(gè)能夠代表SQL Server實(shí)例可能遇到的真實(shí)工作負(fù)載的樣本。另一方面,SQL Server只能維持一定量的信息,有些信息在進(jìn)行SQL Server性能管理活動(dòng)的時(shí)候可能丟失,所以如果SQL Server已經(jīng)運(yùn)行了相當(dāng)長(zhǎng)的一段時(shí)間,一些統(tǒng)計(jì)數(shù)據(jù)就有可能已被覆蓋。
因此,任何時(shí)候你使用dmv,當(dāng)你查看從SQL Server 2005的dmvs返回的相關(guān)資料時(shí),請(qǐng)務(wù)必將以上的觀點(diǎn)裝在腦海中。只有當(dāng)你確信從dmvs獲得的信息是準(zhǔn)確和完整的,你才能變更數(shù)據(jù)庫(kù)或者應(yīng)用程序代碼。
下面就看一下dmv到底能帶給我們那些好的功能呢?
1.51 :索引使用次數(shù)
我們下看一下下面兩種查詢方式返回的結(jié)果(這兩種查詢的查詢用途一致)
①----
declare @dbid int
select @dbid = db_id()
select objectname=object_name(s.object_id), s.object_id, indexname=i.name, i.index_id
, user_seeks, user_scans, user_lookups, user_updates
from sys.dm_db_index_usage_stats s,
sys.indexes i
where database_id = @dbid and objectproperty(s.object_id,'IsUserTable') = 1
and i.object_id = s.object_id
and i.index_id = s.index_id
order by (user_seeks + user_scans + user_lookups + user_updates) asc
返回查詢結(jié)果
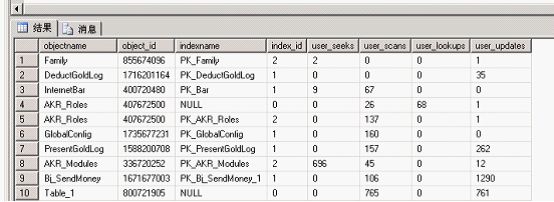
②:使用多的索引排在前面
SELECT objects.name ,
databases.name ,
indexes.name ,
user_seeks ,
user_scans ,
user_lookups ,
partition_stats.row_count
FROM sys.dm_db_index_usage_stats stats
LEFT JOIN sys.objects objects ON stats.object_id = objects.object_id
LEFT JOIN sys.databases databases ON databases.database_id = stats.database_id
LEFT JOIN sys.indexes indexes ON indexes.index_id = stats.index_id
AND stats.object_id = indexes.object_id
LEFT JOIN sys.dm_db_partition_stats partition_stats ON stats.object_id = partition_stats.object_id
AND indexes.index_id = partition_stats.index_id
WHERE 1 = 1
--AND databases.database_id = 7
AND objects.name IS NOT NULL
AND indexes.name IS NOT NULL
AND user_scans>0
ORDER BY user_scans DESC ,
stats.object_id ,
indexes.index_id
返回查詢結(jié)果
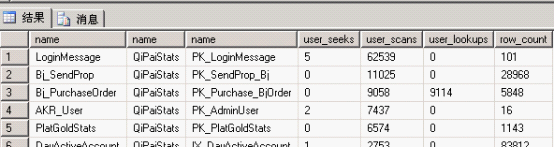
user_seeks : 通過(guò)用戶查詢執(zhí)行的搜索次數(shù)。
個(gè)人理解: 此統(tǒng)計(jì)索引搜索的次數(shù)
user_scans: 通過(guò)用戶查詢執(zhí)行的掃描次數(shù)。
個(gè)人理解:此統(tǒng)計(jì)表掃描的次數(shù),無(wú)索引配合
user_lookups: 通過(guò)用戶查詢執(zhí)行的查找次數(shù)。
個(gè)人理解:用戶通過(guò)索引查找,在使用RID或聚集索引查找數(shù)據(jù)的次數(shù),對(duì)于堆表或聚集表數(shù)據(jù)而言和索引配合使用次數(shù)
user_updates: 通過(guò)用戶查詢執(zhí)行的更新次數(shù)。
個(gè)人理解:索引或表的更新次數(shù)
我們可以清晰的看到,那些索引用的多,那些索引沒(méi)用過(guò),大家可以根據(jù)查詢出來(lái)的東西去分析自己的數(shù)據(jù)索引和表
1.52 :索引提高了多少性能
新建了索引到底增加了多少數(shù)據(jù)的效率呢?到底提高了多少性能呢?運(yùn)行如下SQL可以返回連接缺失索引動(dòng)態(tài)管理視圖,發(fā)現(xiàn)最有用的索引和創(chuàng)建索引的方法:
SELECT
avg_user_impact AS average_improvement_percentage,
avg_total_user_cost AS average_cost_of_query_without_missing_index,
'CREATE INDEX ix_' + [statement] +
ISNULL(equality_columns, '_') +
ISNULL(inequality_columns, '_') + ' ON ' + [statement] +
' (' + ISNULL(equality_columns, ' ') +
ISNULL(inequality_columns, ' ') + ')' +
ISNULL(' INCLUDE (' + included_columns + ')', '')
AS create_missing_index_command
FROM sys.dm_db_missing_index_details a INNER JOIN
sys.dm_db_missing_index_groups b ON a.index_handle = b.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats c ON
b.index_group_handle = c.group_handle
WHERE avg_user_impact > = 40
返回結(jié)果
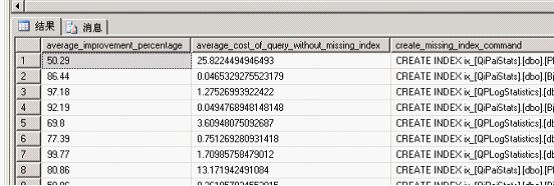
雖然用戶能夠修改性能提高的百分比,但以上查詢返回所有能夠?qū)⑿阅芴岣?span style="font-family: Verdana;">40%或更高的索引。你可以清晰的看到每個(gè)索引提高的性能和效率了
1.53 :最占用CPU、執(zhí)行時(shí)間最長(zhǎng)命令
這個(gè)和索引無(wú)關(guān),但是還是在這里提出來(lái),因?yàn)樗矊儆贒MV帶給我們的功能嗎,他可以讓你輕松查詢出,那些sql語(yǔ)句占用你的cpu最高
SELECT TOP 100 execution_count,
total_logical_reads /execution_count AS [Avg Logical Reads],
total_elapsed_time /execution_count AS [Avg Elapsed Time],
db_name(st.dbid) as [database name],
object_name(st.dbid) as [object name],
object_name(st.objectid) as [object name 1],
SUBSTRING(st.text, (qs.statement_start_offset / 2) + 1,
((CASE statement_end_offset WHEN - 1 THEN DATALENGTH(st.text) ELSE qs.statement_end_offset END - qs.statement_start_offset)
/ 2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
WHERE execution_count > 100
ORDER BY 1 DESC;
返回結(jié)果:
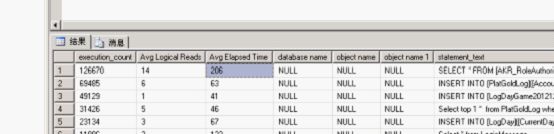
執(zhí)行時(shí)間最長(zhǎng)的命令
SELECT TOP 10 COALESCE(DB_NAME(st.dbid),
DB_NAME(CAST(pa.value as int))+'*',
'Resource') AS DBNAME,
SUBSTRING(text,
-- starting value for substring
CASE WHEN statement_start_offset = 0
OR statement_start_offset IS NULL
THEN 1
ELSE statement_start_offset/2 + 1 END,
-- ending value for substring
CASE WHEN statement_end_offset = 0
OR statement_end_offset = -1
OR statement_end_offset IS NULL
THEN LEN(text)
ELSE statement_end_offset/2 END -
CASE WHEN statement_start_offset = 0
OR statement_start_offset IS NULL
THEN 1
ELSE statement_start_offset/2 END + 1
) AS TSQL,
total_logical_reads/execution_count AS AVG_LOGICAL_READS
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
OUTER APPLY sys.dm_exec_plan_attributes(plan_handle) pa
WHERE attribute = 'dbid'
ORDER BY AVG_LOGICAL_READS DESC ;
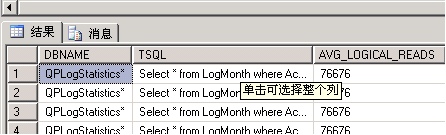
看到了嗎?直接可以定位到你的sql語(yǔ)句,優(yōu)化去吧。還等什么呢?
1.54:缺失索引
缺失索引就是幫你查找你的數(shù)據(jù)庫(kù)缺少什么索引,告訴你那些字段需要加上索引,這樣你就可以根據(jù)提示添加你數(shù)據(jù)庫(kù)缺少的索引了
SELECT TOP 10
[Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0)
, avg_user_impact
, TableName = statement
, [EqualityUsage] = equality_columns
, [InequalityUsage] = inequality_columns
, [Include Cloumns] = included_columns
FROM sys.dm_db_missing_index_groups g
INNER JOIN sys.dm_db_missing_index_group_stats s
ON s.group_handle = g.index_group_handle
INNER JOIN sys.dm_db_missing_index_details d
ON d.index_handle = g.index_handle
ORDER BY [Total Cost] DESC;
查詢結(jié)果如下:

1.6 適當(dāng)創(chuàng)建索引覆蓋
假設(shè)你在Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty)的外鍵列(ProductID)上創(chuàng)建了一個(gè)索引,假設(shè)ProductID列是一個(gè)高選中性列,那么任何在where子句中使用索引列(ProductID)的select查詢都會(huì)更快,如果在外鍵上沒(méi)有創(chuàng)建索引,將會(huì)發(fā)生全部掃描,但還有辦法可以進(jìn)一步提升查詢性能。
假設(shè)Sales表有10,000行記錄,下面的SQL語(yǔ)句選中400行(總行數(shù)的4%):
SELECT SalesDate, SalesPersonID FROM Sales WHERE ProductID = 112
我們來(lái)看看這條SQL語(yǔ)句在SQL執(zhí)行引擎中是如何執(zhí)行的:
1)Sales表在ProductID列上有一個(gè)非聚集索引,因此它查找非聚集索引樹找出ProductID=112的記錄;
2)包含ProductID = 112記錄的索引頁(yè)也包括所有的聚集索引鍵(所有的主鍵鍵值,即SalesID);
3)針對(duì)每一個(gè)主鍵(這里是400),SQL Server引擎查找聚集索引樹找出真實(shí)的行在對(duì)應(yīng)頁(yè)面中的位置;
SQL Server引擎從對(duì)應(yīng)的行查找SalesDate和SalesPersonID列的值。
在上面的步驟中,對(duì)ProductID = 112的每個(gè)主鍵記錄(這里是400),SQL Server引擎要搜索400次聚集索引樹以檢索查詢中指定的其它列(SalesDate,SalesPersonID)。
如果非聚集索引頁(yè)中包括了聚集索引鍵和其它兩列(SalesDate,,SalesPersonID)的值,SQL Server引擎可能不會(huì)執(zhí)行上面的第3和4步,直接從非聚集索引樹查找ProductID列速度還會(huì)快一些,直接從索引頁(yè)讀取這三列的數(shù)值。
幸運(yùn)的是,有一種方法實(shí)現(xiàn)了這個(gè)功能,它被稱為“覆蓋索引”,在表列上創(chuàng)建覆蓋索引時(shí),需要指定哪些額外的列值需要和聚集索引鍵值(主鍵)一起存儲(chǔ)在索引頁(yè)中。下面是在Sales 表ProductID列上創(chuàng)建覆蓋索引的例子:
CREATE INDEX NCLIX_Sales_ProductID--Index name
ON dbo.Sales(ProductID)--Column on which index is to be created
INCLUDE(SalesDate, SalesPersonID)--Additional column values to include
應(yīng)該在那些select查詢中常使用到的列上創(chuàng)建覆蓋索引,但覆蓋索引中包括過(guò)多的列也不行,因?yàn)楦采w索引列的值是存儲(chǔ)在內(nèi)存中的,這樣會(huì)消耗過(guò)多內(nèi)存,引發(fā)性能下降。
1.7 索引碎片
在數(shù)據(jù)庫(kù)性能優(yōu)化一:數(shù)據(jù)庫(kù)自身優(yōu)化一文中已經(jīng)講到了這個(gè)問(wèn)題,再次就不做過(guò)多的重復(fù)地址:http://www.cnblogs.com/AK2012/archive/2012/12/25/2012-1228.html
1.8 索引實(shí)戰(zhàn)(摘抄)
之所以這章摘抄,是因?yàn)橄旅孢@個(gè)文章已經(jīng)寫的太好了,估計(jì)我寫出來(lái)也無(wú)法比這個(gè)好了,所以就摘抄了
人們?cè)谑褂?span style="font-family: Arial;">SQL時(shí)往往會(huì)陷入一個(gè)誤區(qū),即太關(guān)注于所得的結(jié)果是否正確,而忽略了不同的實(shí)現(xiàn)方法之間可能存在的性能差異,這種性能差異在大型的或是復(fù)雜的數(shù)據(jù)庫(kù)環(huán)境中(如聯(lián)機(jī)事務(wù)處理OLTP或決策支持系統(tǒng)DSS)中表現(xiàn)得尤為明顯。
筆者在工作實(shí)踐中發(fā)現(xiàn),不良的SQL往往來(lái)自于不恰當(dāng)?shù)乃饕O(shè)計(jì)、不充份的連接條件和不可優(yōu)化的where子句。
在對(duì)它們進(jìn)行適當(dāng)?shù)膬?yōu)化后,其運(yùn)行速度有了明顯地提高!
下面我將從這三個(gè)方面分別進(jìn)行總結(jié):
為了更直觀地說(shuō)明問(wèn)題,所有實(shí)例中的SQL運(yùn)行時(shí)間均經(jīng)過(guò)測(cè)試,不超過(guò)1秒的均表示為(< 1秒)。----
測(cè)試環(huán)境: 主機(jī):HP LH II---- 主頻:330MHZ---- 內(nèi)存:128兆----
操作系統(tǒng):Operserver5.0.4----
數(shù)據(jù)庫(kù):Sybase11.0.3
一、不合理的索引設(shè)計(jì)----
例:表record有620000行,試看在不同的索引下,下面幾個(gè) SQL的運(yùn)行情況:
---- 1.在date上建有一非個(gè)群集索引
select count(*) from record where date >'19991201' and date < '19991214'and amount >2000 (25秒)
select date ,sum(amount) from record group by date(55秒)
select count(*) from record where date >'19990901' and place in ('BJ','SH') (27秒)
---- 分析:----
date上有大量的重復(fù)值,在非群集索引下,數(shù)據(jù)在物理上隨機(jī)存放在數(shù)據(jù)頁(yè)上,在范圍查找時(shí),必須執(zhí)行一次表掃描才能找到這一范圍內(nèi)的全部行。
---- 2.在date上的一個(gè)群集索引
select count(*) from record where date >'19991201' and date < '19991214' and amount >2000 (14秒)
select date,sum(amount) from record group by date(28秒)
select count(*) from record where date >'19990901' and place in ('BJ','SH')(14秒)
---- 分析:---- 在群集索引下,數(shù)據(jù)在物理上按順序在數(shù)據(jù)頁(yè)上,重復(fù)值也排列在一起,因而在范圍查找時(shí),可以先找到這個(gè)范圍的起末點(diǎn),且只在這個(gè)范圍內(nèi)掃描數(shù)據(jù)頁(yè),避免了大范圍掃描,提高了查詢速度。
---- 3.在place,date,amount上的組合索引
select count(*) from record where date >'19991201' and date < '19991214' and amount >2000 (26秒)
select date,sum(amount) from record group by date(27秒)
select count(*) from record where date >'19990901' and place in ('BJ, 'SH')(< 1秒)
---- 分析:---- 這是一個(gè)不很合理的組合索引,因?yàn)樗那皩?dǎo)列是place,第一和第二條SQL沒(méi)有引用place,因此也沒(méi)有利用上索引;第三個(gè)SQL使用了place,且引用的所有列都包含在組合索引中,形成了索引覆蓋,所以它的速度是非常快的。
---- 4.在date,place,amount上的組合索引
select count(*) from record where date >'19991201' and date < '19991214' and amount >2000(< 1秒)
select date,sum(amount) from record group by date(11秒)
select count(*) from record where date >'19990901' and place in ('BJ','SH')(< 1秒)
---- 分析:---- 這是一個(gè)合理的組合索引。它將date作為前導(dǎo)列,使每個(gè)SQL都可以利用索引,并且在第一和第三個(gè)SQL中形成了索引覆蓋,因而性能達(dá)到了最優(yōu)。
---- 5.總結(jié):----
缺省情況下建立的索引是非群集索引,但有時(shí)它并不是最佳的;合理的索引設(shè)計(jì)要建立在對(duì)各種查詢的分析和預(yù)測(cè)上。
一般來(lái)說(shuō):
①.有大量重復(fù)值、且經(jīng)常有范圍查詢(between, >,< ,>=,< =)和order by、group by發(fā)生的列,可考慮建立群集索引;
②.經(jīng)常同時(shí)存取多列,且每列都含有重復(fù)值可考慮建立組合索引;
③.組合索引要盡量使關(guān)鍵查詢形成索引覆蓋,其前導(dǎo)列一定是使用最頻繁的列。
二、不充份的連接條件:
例:表card有7896行,在card_no上有一個(gè)非聚集索引,表account有191122行,在account_no上有一個(gè)非聚集索引,試看在不同的表連接條件下,兩個(gè)SQL的執(zhí)行情況:
select sum(a.amount) from account a,card b where a.card_no = b.card_no(20秒)
select sum(a.amount) from account a,card b where a.card_no = b.card_no and a.account_no=b.account_no(< 1秒)
---- 分析:---- 在第一個(gè)連接條件下,最佳查詢方案是將account作外層表,card作內(nèi)層表,利用card上的索引,其I/O次數(shù)可由以下公式估算為:
外層表account上的22541頁(yè)+(外層表account的191122行*內(nèi)層表card上對(duì)應(yīng)外層表第一行所要查找的3頁(yè))=595907次I/O
在第二個(gè)連接條件下,最佳查詢方案是將card作外層表,account作內(nèi)層表,利用account上的索引,其I/O次數(shù)可由以下公式估算為:外層表card上的1944頁(yè)+(外層表card的7896行*內(nèi)層表account上對(duì)應(yīng)外層表每一行所要查找的4頁(yè))= 33528次I/O
可見(jiàn),只有充份的連接條件,真正的最佳方案才會(huì)被執(zhí)行。
總結(jié):
1.多表操作在被實(shí)際執(zhí)行前,查詢優(yōu)化器會(huì)根據(jù)連接條件,列出幾組可能的連接方案并從中找出系統(tǒng)開銷最小的最佳方案。連接條件要充份考慮帶有索引的表、行數(shù)多的表;內(nèi)外表的選擇可由公式:外層表中的匹配行數(shù)*內(nèi)層表中每一次查找的次數(shù)確定,乘積最小為最佳方案。
2.查看執(zhí)行方案的方法-- 用set showplanon,打開showplan選項(xiàng),就可以看到連接順序、使用何種索引的信息;想看更詳細(xì)的信息,需用sa角色執(zhí)行dbcc(3604,310,302)。
三、不可優(yōu)化的where子句
1.例:下列SQL條件語(yǔ)句中的列都建有恰當(dāng)?shù)乃饕珗?zhí)行速度卻非常慢:
select * from record wheresubstring(card_no,1,4)='5378'(13秒)
select * from record whereamount/30< 1000(11秒)
select * from record whereconvert(char(10),date,112)='19991201'(10秒)
分析:
where子句中對(duì)列的任何操作結(jié)果都是在SQL運(yùn)行時(shí)逐列計(jì)算得到的,因此它不得不進(jìn)行表搜索,而沒(méi)有使用該列上面的索引;
如果這些結(jié)果在查詢編譯時(shí)就能得到,那么就可以被SQL優(yōu)化器優(yōu)化,使用索引,避免表搜索,因此將SQL重寫成下面這樣:
select * from record where card_no like'5378%'(< 1秒)
select * from record where amount< 1000*30(< 1秒)
select * from record where date= '1999/12/01'(< 1秒)
你會(huì)發(fā)現(xiàn)SQL明顯快起來(lái)!
2.例:表stuff有200000行,id_no上有非群集索引,請(qǐng)看下面這個(gè)SQL:
select count(*) from stuff where id_no in('0','1')(23秒)
分析:---- where條件中的'in'在邏輯上相當(dāng)于'or',所以語(yǔ)法分析器會(huì)將in ('0','1')轉(zhuǎn)化為id_no ='0' or id_no='1'來(lái)執(zhí)行。
我們期望它會(huì)根據(jù)每個(gè)or子句分別查找,再將結(jié)果相加,這樣可以利用id_no上的索引;
但實(shí)際上(根據(jù)showplan),它卻采用了"OR策略",即先取出滿足每個(gè)or子句的行,存入臨時(shí)數(shù)據(jù)庫(kù)的工作表中,再建立唯一索引以去掉重復(fù)行,最后從這個(gè)臨時(shí)表中計(jì)算結(jié)果。因此,實(shí)際過(guò)程沒(méi)有利用id_no上索引,并且完成時(shí)間還要受tempdb數(shù)據(jù)庫(kù)性能的影響。
實(shí)踐證明,表的行數(shù)越多,工作表的性能就越差,當(dāng)stuff有620000行時(shí),執(zhí)行時(shí)間竟達(dá)到220秒!還不如將or子句分開:
select count(*) from stuff where id_no='0'select count(*) from stuff where id_no='1'
得到兩個(gè)結(jié)果,再作一次加法合算。因?yàn)槊烤涠际褂昧怂饕瑘?zhí)行時(shí)間只有3秒,在620000行下,時(shí)間也只有4秒。
或者,用更好的方法,寫一個(gè)簡(jiǎn)單的存儲(chǔ)過(guò)程:
create proc count_stuff asdeclare @a intdeclare @b intdeclare @c intdeclare @d char(10)beginselect @a=count(*) from stuff where id_no='0'select @b=count(*) from stuff where id_no='1'endselect @c=@a+@bselect @d=convert(char(10),@c)print @d
直接算出結(jié)果,執(zhí)行時(shí)間同上面一樣快!
---- 總結(jié):---- 可見(jiàn),所謂優(yōu)化即where子句利用了索引,不可優(yōu)化即發(fā)生了表掃描或額外開銷。
1.任何對(duì)列的操作都將導(dǎo)致表掃描,它包括數(shù)據(jù)庫(kù)函數(shù)、計(jì)算表達(dá)式等等,查詢時(shí)要盡可能將操作移至等號(hào)右邊。
2.in、or子句常會(huì)使用工作表,使索引失效;如果不產(chǎn)生大量重復(fù)值,可以考慮把子句拆開;拆開的子句中應(yīng)該包含索引。
3.要善于使用存儲(chǔ)過(guò)程,它使SQL變得更加靈活和高效。
從以上這些例子可以看出,SQL優(yōu)化的實(shí)質(zhì)就是在結(jié)果正確的前提下,用優(yōu)化器可以識(shí)別的語(yǔ)句,充份利用索引,減少表掃描的I/O次數(shù),盡量避免表搜索的發(fā)生。其實(shí)SQL的性能優(yōu)化是一個(gè)復(fù)雜的過(guò)程,上述這些只是在應(yīng)用層次的一種體現(xiàn),深入研究還會(huì)涉及數(shù)據(jù)庫(kù)層的資源配置、網(wǎng)絡(luò)層的流量控制以及操作系統(tǒng)層的總體設(shè)計(jì)。
END

