
(圖解)為什么機器學(xué)習算法難以優(yōu)化?一文詳解算法優(yōu)化內(nèi)部機制
點擊左上方藍字關(guān)注我們

轉(zhuǎn)載自 | Datawhale
本文約3500字,建議閱讀9分鐘
本文介紹了一些關(guān)于機器學(xué)習和線性組合的部分問題以及緩解該問題的方法。
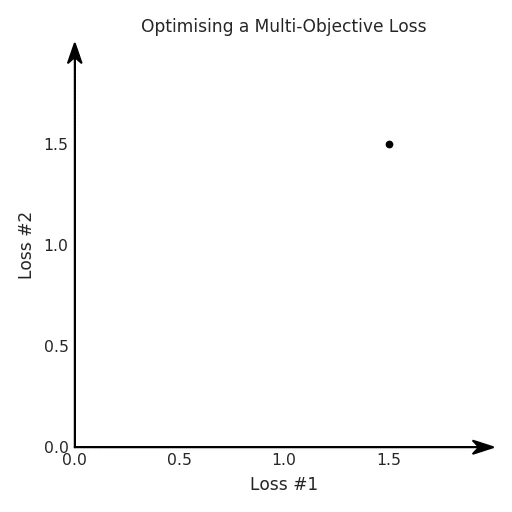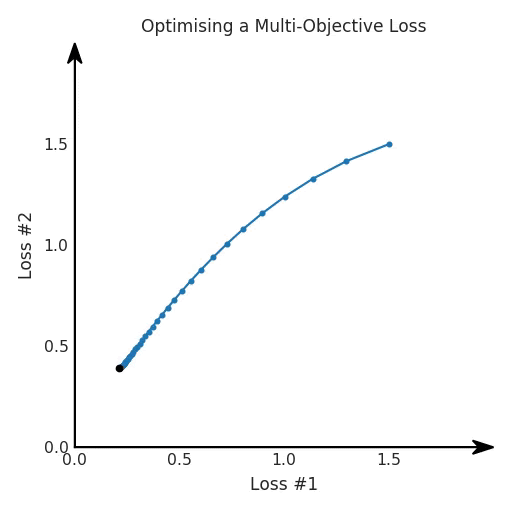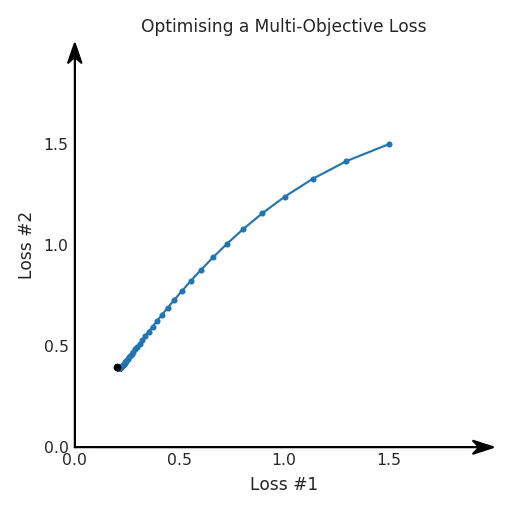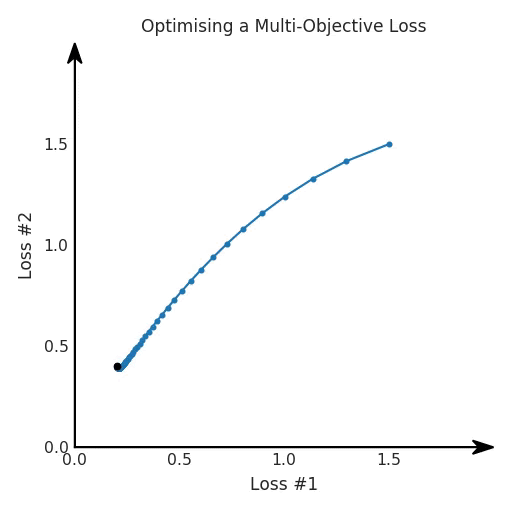
機器學(xué)習中的許多問題應(yīng)該被視為多目標問題,但目前并非如此; 「1」中的問題導(dǎo)致這些機器學(xué)習算法的超參數(shù)難以調(diào)整; 檢測這些問題何時發(fā)生幾乎是不可能的,因此很難解決這些問題。
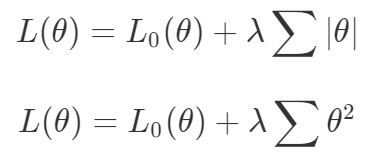
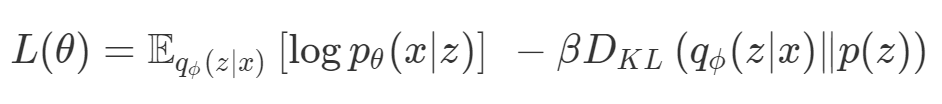
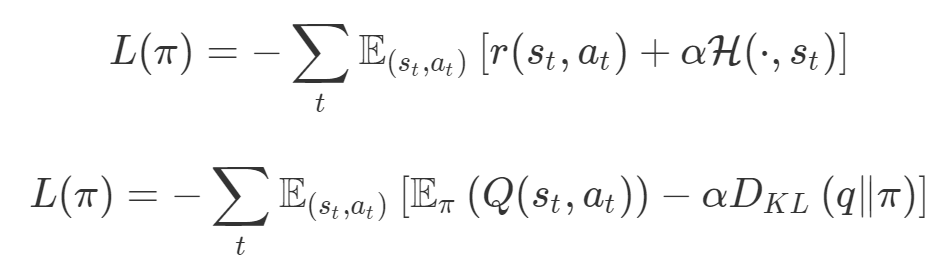
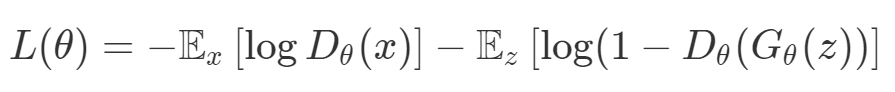
def loss(θ):return loss_1(θ) + loss_2(θ)loss_derivative = grad(loss)for gradient_step in range(200): gradient = loss_derivative(θ) θ = θ - 0.02 * gradientdef loss(θ, α):return loss_1(θ) + α*loss_2(θ)loss_derivative = grad(loss)for gradient_step in range(200): gradient = loss_derivative(θ, α=0.5) θ = θ - 0.02 * gradient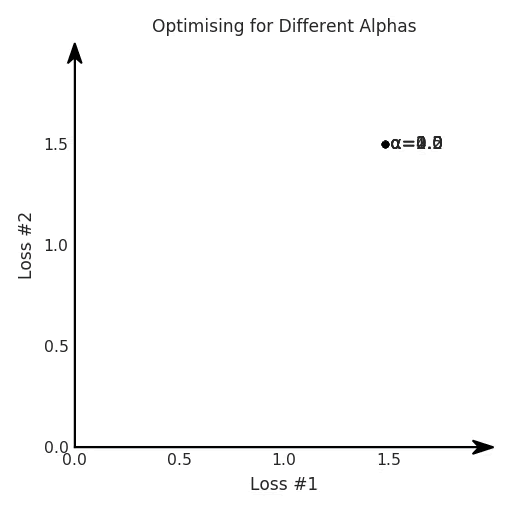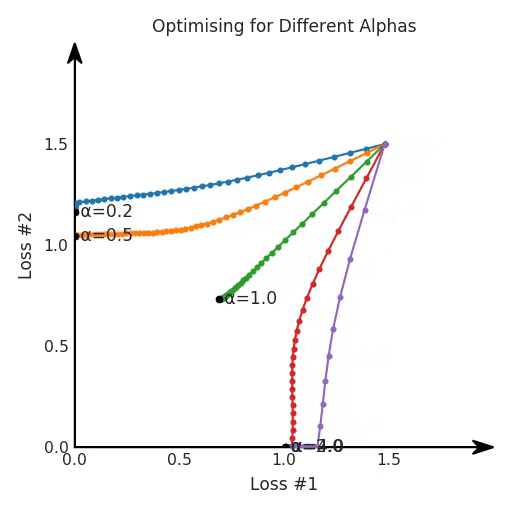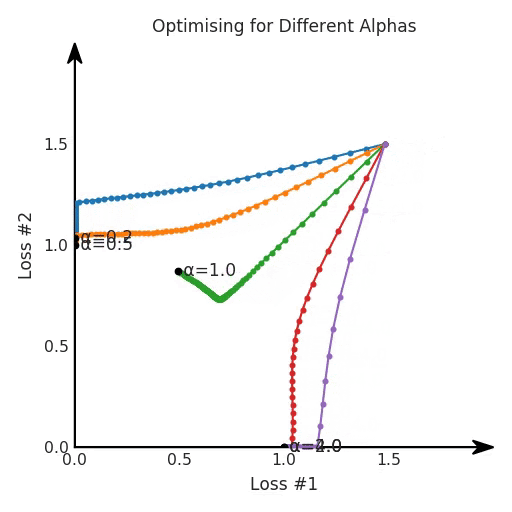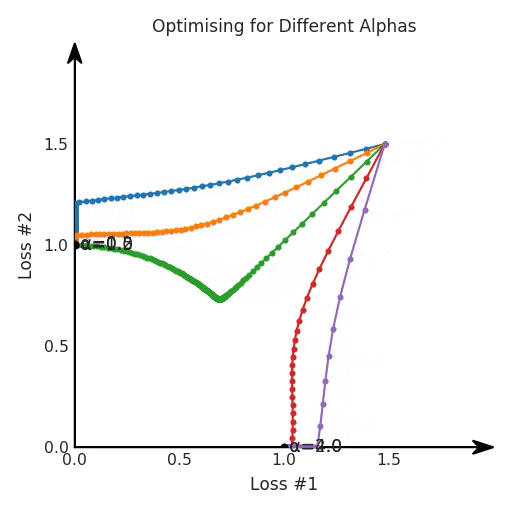
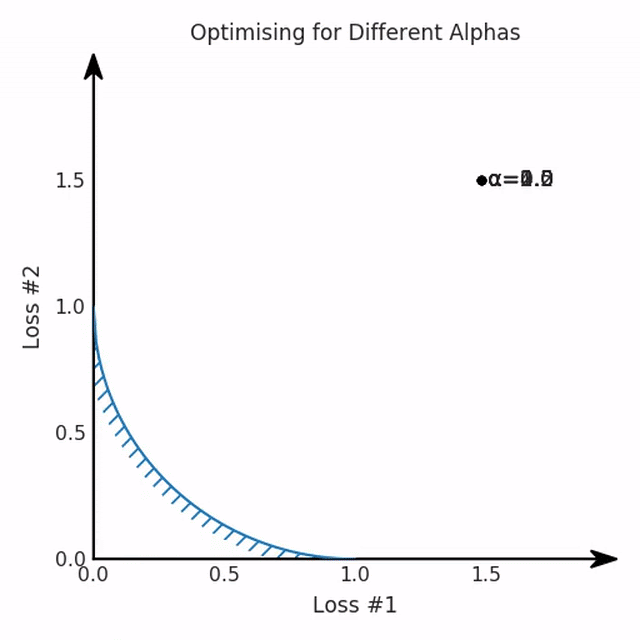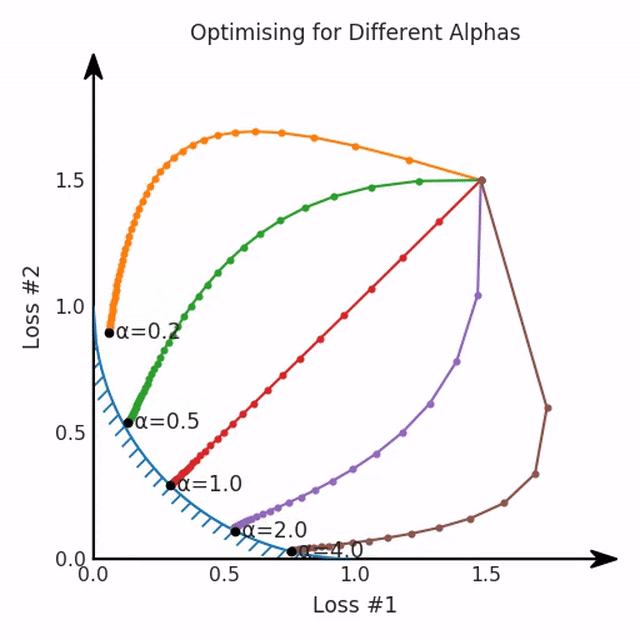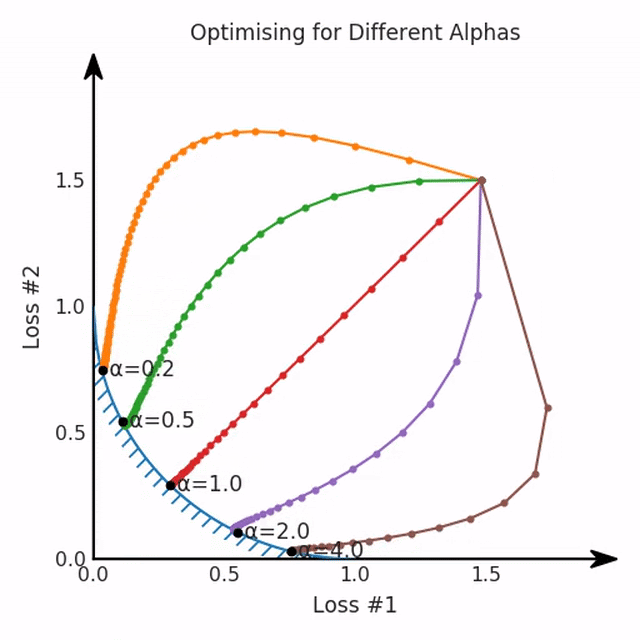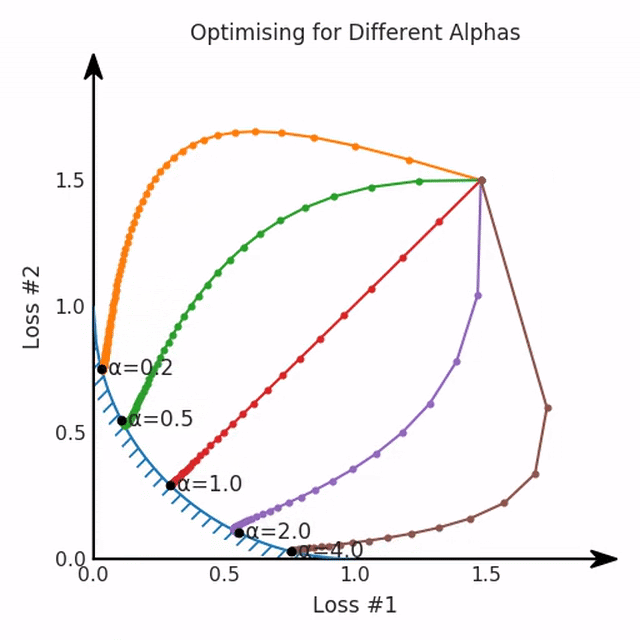
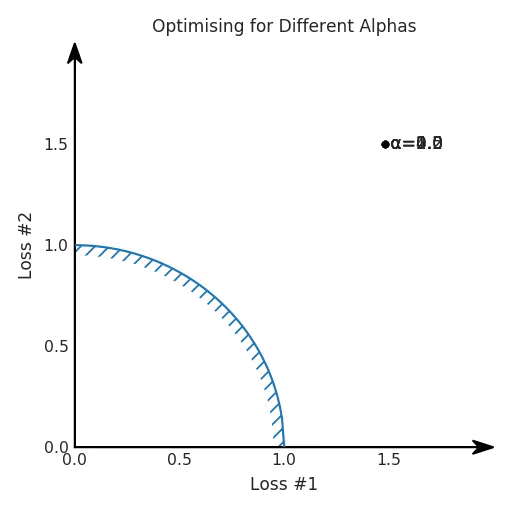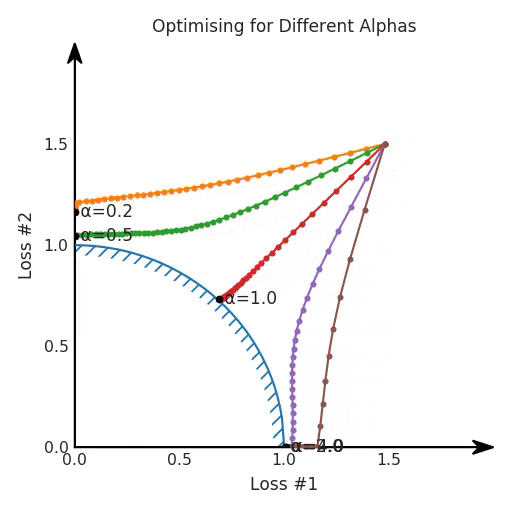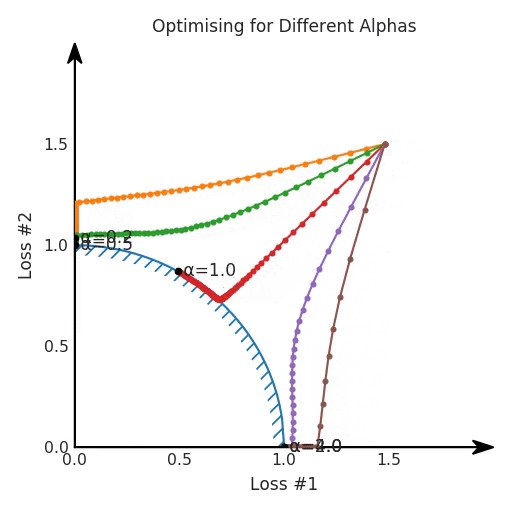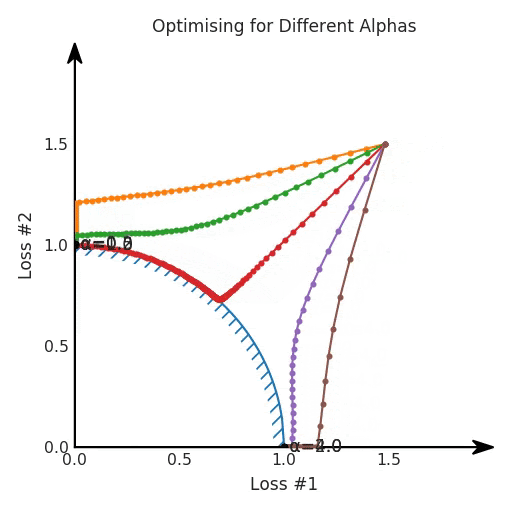
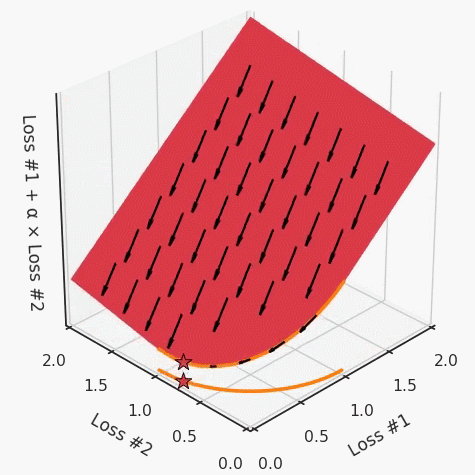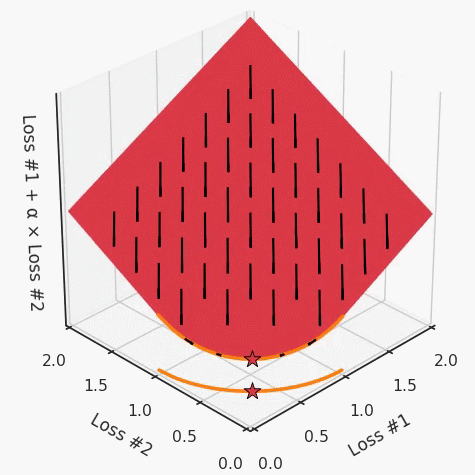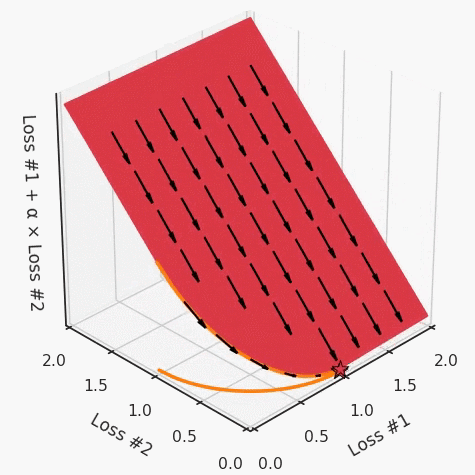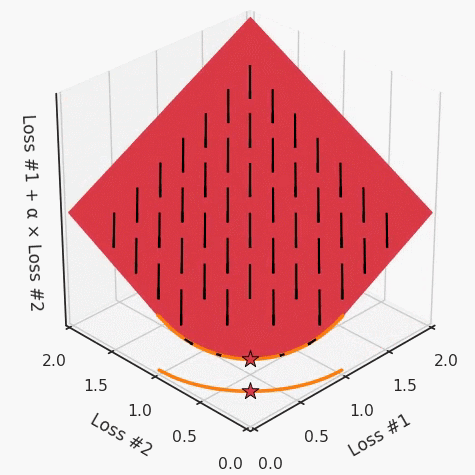
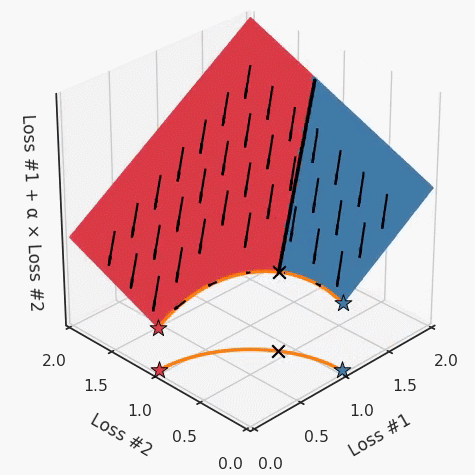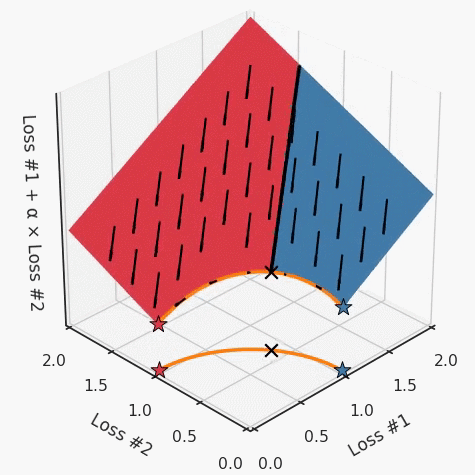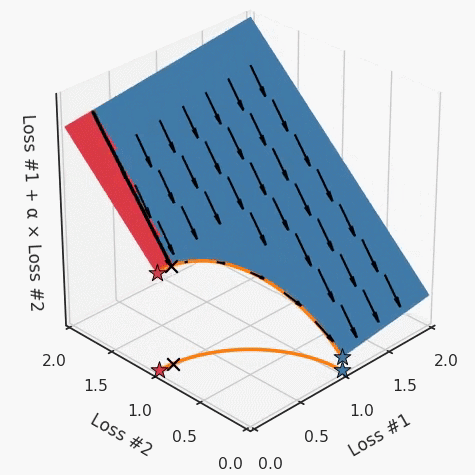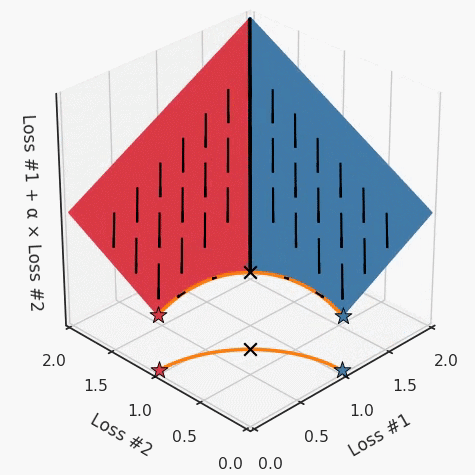
第一,即使沒有引入超參數(shù)來權(quán)衡損失,說梯度下降試圖在反作用力之間保持平衡也是不正確的。根據(jù)模型可實現(xiàn)的解,可以完全忽略其中一種損失,而將注意力放在另一種損失上,反之亦然,這取決于初始化模型的位置;
第二,即使引入了超參數(shù),也將在嘗試后的基礎(chǔ)上調(diào)整此超參數(shù)。研究中往往是運行一個完整的優(yōu)化過程,然后確定是否滿意,再對超參數(shù)進行微調(diào)。重復(fù)此優(yōu)化循環(huán),直到對性能滿意為止。這是一種費時費力的方法,通常涉及多次運行梯度下降的迭代;
第三,超參數(shù)不能針對所有的最優(yōu)情況進行調(diào)整。無論進行多少調(diào)整和微調(diào),你都不會找到可能感興趣的中間方案。這不是因為它們不存在,它們一定存在,只是因為選擇了一種糟糕的組合損失方法;
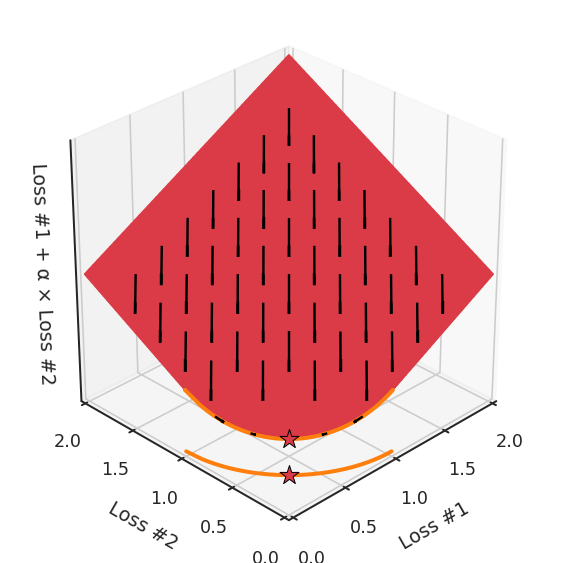
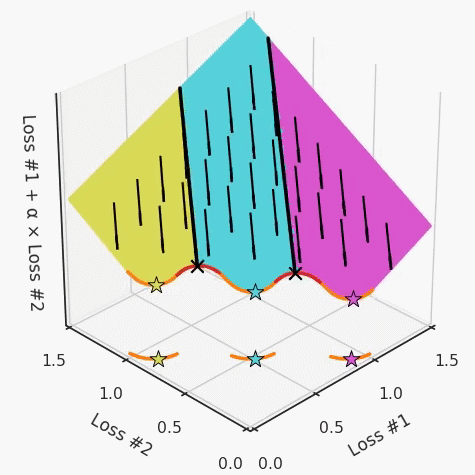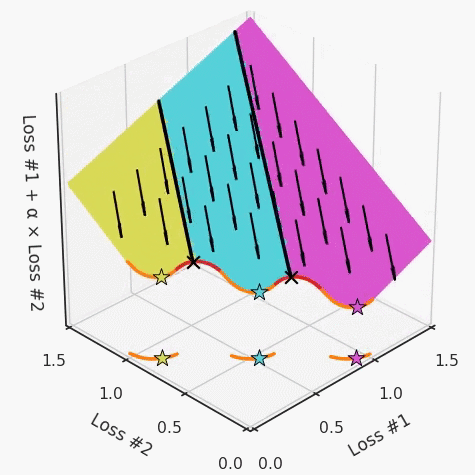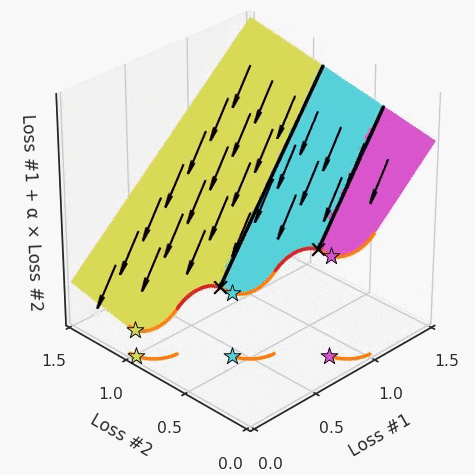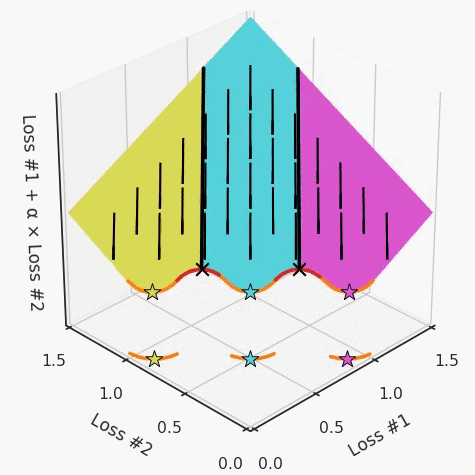
第四,必須強調(diào)的是,對于實際應(yīng)用,帕累托前沿面是否為凸面以及因此這些損失權(quán)重是否可調(diào)始終是未知的。它們是否是好的超參數(shù),取決于模型的參數(shù)化方式及其影響帕累托曲線的方式。但是,對于任何實際應(yīng)用,都無法可視化或分析帕累托曲線。可視化比原始的優(yōu)化問題要困難得多。因此出現(xiàn)問題并不會引起注意;
最后,如果你真的想使用這些線性權(quán)重來進行權(quán)衡,則需要明確證明整個帕累托曲線對于正在使用的特定模型是凸的。因此,使用相對于模型輸出而言凸的損失不足以避免問題。如果參數(shù)化空間很大(如果優(yōu)化涉及神經(jīng)網(wǎng)絡(luò)內(nèi)部的權(quán)重,則情況總是如此),你可能會忘記嘗試這種證明。需要強調(diào)的是,基于某些中間潛勢(intermediate latent),顯示這些損失的帕累托曲線的凸度不足以表明你具有可調(diào)參數(shù)。凸度實際上需要取決于參數(shù)空間以及可實現(xiàn)解決方案的帕累托前沿面。
END
整理不易,點贊三連↓