
如何快速判斷一個(gè)用戶是否訪問過我們的 APP?
牙哥好久沒更新公眾號(hào)了,后面盡量多更,不關(guān)注閱讀量,不關(guān)注新增和取關(guān),希望你還在!
背景
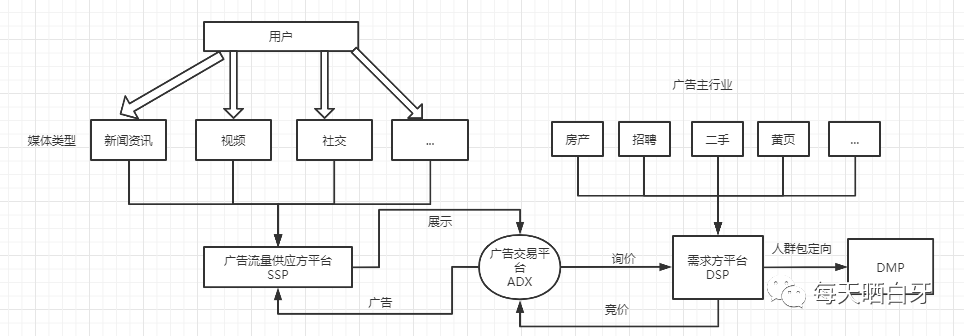
牙哥所在部門是做廣告系統(tǒng)的,所在小組主要做廣告外投,即下圖中 DSP 部分,當(dāng)用戶瀏覽媒體時(shí),媒體通過 SSP 將曝光請(qǐng)求通過 ADX 發(fā)送給 DSP,DSP 通過 DMP 進(jìn)行人群定向,對(duì)目標(biāo)人群進(jìn)行廣告競價(jià),更好地為廣告主帶來收益
如何篩選優(yōu)質(zhì)流量是個(gè)難題,我們也在不斷探索,現(xiàn)在想在程序入口讓訪問過我們 APP 的用戶的這種流量(這種流量下面稱作 RT 流量)優(yōu)先通過篩選,但我們的程序入口 QPS 約 40w,且去重后的 RT 用戶數(shù)是億級(jí)別,假設(shè) 3 億吧,用戶信息是 32 位的字符串,如何快速判斷一個(gè)用戶是否訪問過我們的 APP 呢?如果讓你來設(shè)計(jì),你打算怎么做?歡迎在留言區(qū)說出你的方案,和牙哥一起探討
分析
判斷一個(gè)對(duì)象是否存在一般可以采用哈希表的方式,檢索的平均時(shí)間復(fù)雜度是 O(1),但是哈希表比較耗內(nèi)存,3 億個(gè) 32 字節(jié)的數(shù)據(jù)占用約 9G (32 byte * 3 億/1024/1024/104)的內(nèi)存,,所以這種方案不太適合我們的場景。
節(jié)省內(nèi)存的方式有位圖 BitMap 和布隆過濾器 BloomFilter 兩種方式,其實(shí) BloomFilter 是對(duì) BitMap 的一種改進(jìn)
先簡單介紹下 BitMap
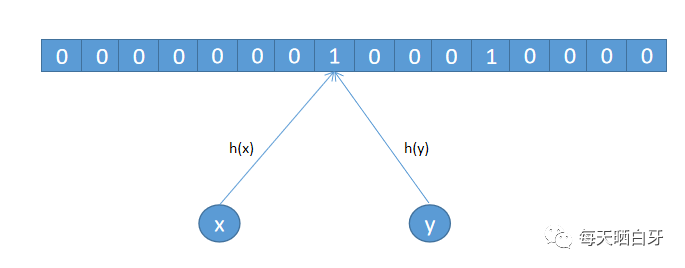
BitMap 是以 bit 為單位構(gòu)建的數(shù)組,非常節(jié)省內(nèi)存,假設(shè)用戶的 ID 是 1,那么就把索引為 1 的 bit 數(shù)組置為 1,其余位置默認(rèn)為 0,如下圖所示
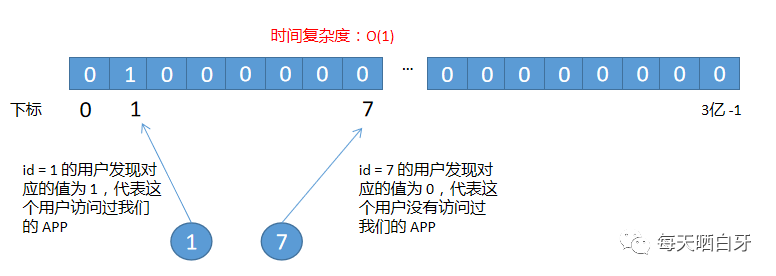
BitMap 通過數(shù)組下標(biāo)來定位數(shù)據(jù),Java 沒有支持表示二進(jìn)制數(shù)據(jù)的類型,可以通過 char 類型的數(shù)組通過或運(yùn)算來達(dá)到目的,訪問效率很快,檢索的時(shí)間復(fù)雜度是 O(1)。但我們的數(shù)據(jù)不適合直接使用 BitMap ,原因如下:
BitMap 不適合數(shù)字范圍過大,因?yàn)閿?shù)組的長度必須大于 ID 的上限,如果數(shù)組范圍是 3 億,BitMap 的大小是 3 億個(gè)二進(jìn)制位,大約占用 36MB (3億/8/1024/1024)左右的內(nèi)存空間,注意這里假設(shè) ID 是連續(xù)的,所以使用場景是是受限的
我們通過設(shè)備號(hào)來識(shí)別用戶,并將設(shè)備號(hào)處理成 32 位的字符串,這顯然不符合連續(xù) ID 的假設(shè),那想要使用 BitMap 該怎么做?
這就需要一個(gè)映射表來做支持,<設(shè)備號(hào),ID>,映射表可以使用 Redis,在流量過來后,先根據(jù)設(shè)置號(hào)查詢映射表拿到 ID,然后再從 BitMap 中判斷用戶是否存在,流程如下圖所示:
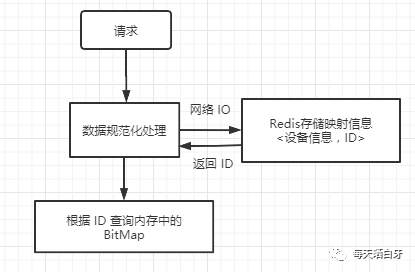
現(xiàn)在我們?cè)倏聪逻@個(gè)方案,既然已經(jīng)在 Redis 中存儲(chǔ)了映射信息了,那根據(jù) ID 通過 BitMap 來判斷是否存在貌似是多余的,因?yàn)槿绻成浔碇写嬖冢f明用戶就存在呀,不需要再多做一個(gè)判斷了,再改一版,直接把設(shè)備信息存到 Redis 中
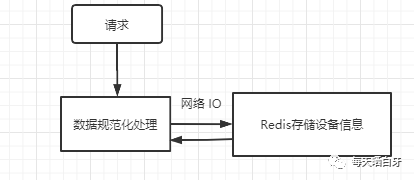
這種方案就是把占用的內(nèi)存轉(zhuǎn)移到了外部存儲(chǔ),這樣 Redis 也占用內(nèi)存呀,怎么辦?
Redis 也是支持布隆過濾器的,不直接存儲(chǔ)設(shè)備信息,改為用布隆過濾器(布隆過濾器原理后面聊)來存,可以節(jié)省內(nèi)存
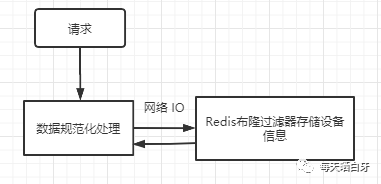
這種方案貌似可以解決我們的問題了,但是多了一次網(wǎng)絡(luò) IO,,我們的系統(tǒng)對(duì)響應(yīng)時(shí)間要求高,所以帶有網(wǎng)絡(luò)IO的方式,也不太適合。那我們直接把網(wǎng)絡(luò) IO 去掉,直接在內(nèi)存中使用布隆過濾器呢?
布隆過濾器原理
BloomFilter 是對(duì) BitMap 的一種優(yōu)化,我們知道數(shù)組占用空間 = 數(shù)組元素個(gè)數(shù) * 每個(gè)元素大小,而 BitMap 已經(jīng)將每個(gè)元素的大小壓縮到最小單位 1 個(gè) bit,還想繼續(xù)優(yōu)化只能減少數(shù)組元素的個(gè)數(shù)了。在前面分析 BitMap 時(shí),我們知道它對(duì) ID 的范圍有限制,如果想減少數(shù)組元素的個(gè)數(shù),可以通過哈希函數(shù)將大于數(shù)組長度的 ID 轉(zhuǎn)換為小于數(shù)組長度的下標(biāo),這種方案還有一個(gè)優(yōu)點(diǎn)就是不再限制 ID 是正整數(shù),可以是字符串(這點(diǎn)非常重要),剛好我們的數(shù)據(jù)符合這個(gè)場景。
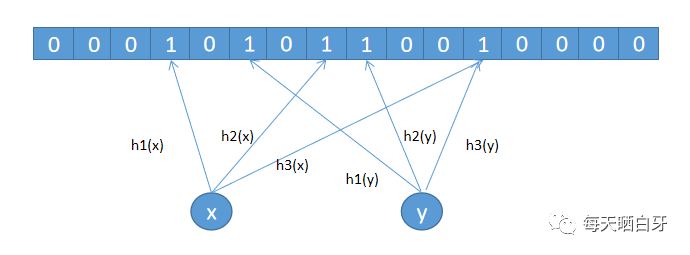
但是這樣會(huì)存在沖突,假設(shè) x 和 y 經(jīng)過哈希函數(shù)計(jì)算后定位到同一個(gè)位置,那就不能判定到底是 x 還是 y 訪問過我們的 APP 了
散列表解決哈希沖突有兩種常用方法:開放尋址法和鏈表法,鏈表法你應(yīng)該知道,HashMap 就是用的這種方案。開放尋址法中有個(gè)優(yōu)化方案叫”雙散列“,說白了就是用多個(gè)哈希函數(shù)來解決哈希沖突問題。布隆過濾器就是利用的這種多個(gè)哈希函數(shù)來解決哈希沖突的。如下圖所示,使用了 3 個(gè)哈希哈數(shù),會(huì)計(jì)算 3 個(gè)下標(biāo),會(huì)把下標(biāo)對(duì)應(yīng)的位置置為 1,這也是布隆過濾器和 BitMap 的最大區(qū)別,即在 bit 數(shù)組中用多個(gè)位來表示對(duì)象,而不是用 1 個(gè)位來表示,從而來降低沖突
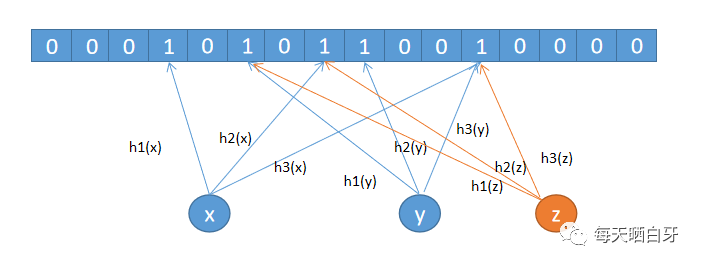
雖然用多個(gè)位來表示對(duì)象可以降低哈希沖突,但還是會(huì)存在沖突的,即布隆過濾器是存在誤判率的,如下圖所示,假設(shè)用戶 z 并未訪問過 APP,但他的設(shè)備號(hào)經(jīng)過 3 次哈希計(jì)算對(duì)應(yīng)的位置都已經(jīng)置為 1 了,所以會(huì)產(chǎn)生誤判,但因?yàn)槲覀兊臉I(yè)務(wù)場景并不要求準(zhǔn)確率是 100%,只是希望把訪問過 APP 的用戶的流量快速的放進(jìn)系統(tǒng),即使誤判也沒有影響,所以布隆過濾器的誤判率的存在,符合我們的業(yè)務(wù)場景。
實(shí)現(xiàn)方案
業(yè)務(wù)場景和布隆過濾器介紹完了,下面看看如何實(shí)現(xiàn)吧,已經(jīng)有很多開源框架實(shí)現(xiàn)了布隆過濾器,可以拿來直接使用,不需要再重復(fù)造輪子了,我采用的是 Guava 的 BloomFilter ,創(chuàng)建 BloomFilter 對(duì)象時(shí),傳入誤判率(默認(rèn)的是 0.03)和預(yù)估數(shù)據(jù)量(億級(jí)別),使用方法如下:
//?創(chuàng)建?BloomFilter
BloomFilter?bloomFilter?=?BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),?expectedNum,?fpp);
//?寫數(shù)據(jù)
bloomFilter.put("1");
//?讀數(shù)據(jù)
boolean?result?=?bloomFilter.mightContain("1");
Guava 的 BloomFilter 使用起來還是蠻方便的,但我想介紹下 BloomFilter 涉及到的兩個(gè)比較重要的公式
//?根據(jù)預(yù)估數(shù)據(jù)量?n?和?誤判率?fpp?計(jì)算bit數(shù)組
//?m?=?-n*ln(fpp)/(log2)^2
long?m?=?(long)?(-expectedNum?*?Math.log(fpp)?/?(Math.log(2)?*?Math.log(2)));
//?根據(jù)預(yù)估數(shù)據(jù)量?n?和?bit?數(shù)組長度?m?計(jì)算哈希函數(shù)的個(gè)數(shù)?k?=?m/n?*?ln2
int?k?=?Math.max(1,?(int)?Math.round((double)m?/?expectedNum?*?Math.log(2)));
//?BloomFilter?使用?long?型數(shù)組
int?longNum?=?Ints.checkedCast(LongMath.divide(m,?64,?RoundingMode.CEILING));
根據(jù)公式對(duì)不同數(shù)據(jù)量占用的內(nèi)存做了估算,因?yàn)樽龇桨冈O(shè)計(jì)時(shí)要考慮內(nèi)存占用情況
long?expectedNum?=?500_000_000;
double?fpp?=?0.03d;
System.out.println("預(yù)估數(shù)據(jù)量?:"?+?expectedNum?+?"\n誤判率:"?+?fpp);
//?根據(jù)預(yù)估數(shù)據(jù)量?n?和?誤判率?fpp?計(jì)算bit數(shù)組
//?m?=?-n*ln(fpp)/(log2)^2
long?m?=?(long)?(-expectedNum?*?Math.log(fpp)?/?(Math.log(2)?*?Math.log(2)));
System.out.println("bit數(shù)組長度:"?+?m);
//?根據(jù)預(yù)估數(shù)據(jù)量?n?和?bit?數(shù)組長度?m?計(jì)算哈希函數(shù)的個(gè)數(shù)?k?=?m/n?*?ln2
System.out.println("哈希函數(shù)個(gè)數(shù):"?+?Math.max(1,?(int)?Math.round((double)m?/?expectedNum?*?Math.log(2))));
//?BloomFilter?使用?long?型數(shù)組
int?longNum?=?Ints.checkedCast(LongMath.divide(m,?64,?RoundingMode.CEILING));
System.out.println("long數(shù)組大小:"?+?longNum);
int?size?=?longNum?*?8?/?1024?/?1024;
System.out.println("內(nèi)存占用大小:"?+?size);
結(jié)果
誤判率采用默認(rèn)的?0.03
按?10?億的數(shù)據(jù)算,bit?數(shù)組長度是?7298440837,BloomFilter?使用long型數(shù)組,所以long型數(shù)組長度?114038139?,內(nèi)存占用約?870?MB
按?5?億的數(shù)據(jù)算,bit?數(shù)組長度是?3649220418,BloomFilter?使用long型數(shù)組,所以long型數(shù)組長度?57019070?,內(nèi)存占用約?435?MB
按?3?億的數(shù)據(jù)算,bit?數(shù)組長度是?2189532251,BloomFilter?使用long型數(shù)組,所以long型數(shù)組長度?34211442?,內(nèi)存占用約?261?MB??
按?2?億的數(shù)據(jù)算,bit?數(shù)組長度是?1459688167,BloomFilter?使用long型數(shù)組,所以long型數(shù)組長度?22807628?,內(nèi)存占用約?174?MB
我們的 RT 數(shù)據(jù)預(yù)計(jì) 3 億,在默認(rèn)誤判率的情況下,占用內(nèi)存在 261MB ,服務(wù)器現(xiàn)有配置可以滿足
注意
這里發(fā)現(xiàn)使用了 BloomFilter 后占用的內(nèi)存竟然比直接使用 BitMap 耗費(fèi)內(nèi)存更多,好像和常識(shí)相反。其實(shí)使用 BitMap 時(shí)假設(shè)了是連續(xù)的 ID,緊湊的 BitMap 是最省空間的,連續(xù)的 Id 對(duì) BitMap 來說是沒有任何空間浪費(fèi)的,所以這種情況下 BloomFilter 占用的內(nèi)存高于 BitMap
首先介紹下文中涉及到的兩個(gè)項(xiàng)目,一個(gè)是 delivery 是我們的廣告檢索入口,流量非常大,對(duì)性能要求高,另一個(gè)是 dsp_jar_task,和定時(shí)任務(wù)相關(guān)
然后看下整體方案:
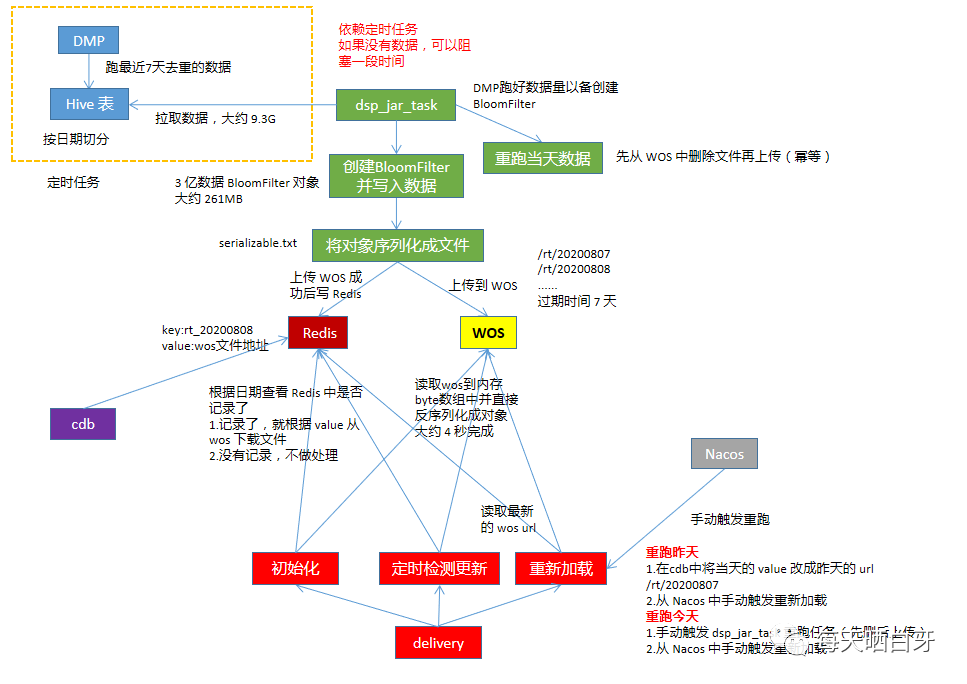
流程介紹
我們的 RT 數(shù)據(jù)每天通過定時(shí)任務(wù)跑完數(shù)后存放到 ?HDFS 上,考慮到從 HDFS 中讀取數(shù)據(jù),并創(chuàng)建對(duì)象耗時(shí)比較長,所以把這部分工作從 delivery 移到 dsp_jar_task 上,在 dsp_jar_task 讀取數(shù)據(jù)并創(chuàng)建好 BloomFilter 后,將對(duì)象序列化到文件中,先保存在本地,然后將文件上傳到 WOS (公司內(nèi)部的一個(gè)對(duì)象存儲(chǔ)組件),存儲(chǔ)到 WOS 成功后,會(huì)返回一個(gè) url 地址,根據(jù)該地址可以訪問存儲(chǔ)的對(duì)象,把記錄寫到 Redis 中,格式如:
delivery 初始化時(shí),先根據(jù)前一天日期從 Redis 中查是否有寫入 WOS,如果昨天沒有則取前天的,有就取昨天的。從 WOS 讀取數(shù)據(jù)到內(nèi)存中,存放到 byte 數(shù)組中,然后反序列化成 BloomFilter 對(duì)象,成功后,在內(nèi)存中記錄本地的模型日期,供定時(shí)檢查模型更新對(duì)比使用,delivery 啟動(dòng)后會(huì)起定時(shí)任務(wù)每隔 10 分鐘去檢查 Redis 中的模型和內(nèi)存的模型是否相同
如果相同,不做處理
如果不同,則根據(jù) Redis 中最新的模型 url 去 WOS 讀取最新的模型
回滾操作
為了應(yīng)對(duì)模型數(shù)據(jù)存在問題的 case,要支持回滾操作。回滾操作主要分為兩種,一種是回滾到昨天的模型,另一種是重跑今天的模型
回滾到昨天的模型
首先,昨天的模型一定是正常的,然后通過在 cdb 平臺(tái)手動(dòng)更新 Redis 數(shù)據(jù),將 key = rt_20200007 的 value 改成昨天的 WOS url
然后在 Nacos 中觸發(fā)重新加載模型操作
重跑今天的模型
可能當(dāng)天的任務(wù)跑的數(shù)據(jù)有問題,需要提供 RT 數(shù)據(jù)的定時(shí)任務(wù)重新跑數(shù)據(jù),跑完后,手動(dòng)觸發(fā) dsp_jar_task 執(zhí)行重跑任務(wù),需要先刪除當(dāng)天的數(shù)據(jù),然后再重新拉取數(shù)據(jù)并上傳,這里是個(gè)冪等的操作。上傳成功后,在 Nacos 中觸發(fā)重新加載模型的操作
效果和規(guī)劃
該方案上線后,業(yè)務(wù)相關(guān)的效果數(shù)據(jù)很明顯,但現(xiàn)在只有離線數(shù)據(jù),后續(xù)可能會(huì)考慮加入實(shí)時(shí)數(shù)據(jù)
—?【 THE END 】— 本公眾號(hào)全部博文已整理成一個(gè)目錄,請(qǐng)?jiān)诠娞?hào)里回復(fù)「m」獲取! 3T技術(shù)資源大放送!包括但不限于:Java、C/C++,Linux,Python,大數(shù)據(jù),人工智能等等。在公眾號(hào)內(nèi)回復(fù)「1024」,即可免費(fèi)獲取!!