
差分卷積在計(jì)算機(jī)視覺(jué)中的應(yīng)用
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

編者薦語(yǔ)
文章主要介紹由Oulu大學(xué)主導(dǎo)的幾個(gè)差分卷積(Difference Convolution)工作及其在圖像、視頻領(lǐng)域中的應(yīng)用。
作者丨Fisher 魚(yú)子 @知乎
鏈接丨h(huán)ttps://zhuanlan.zhihu.com/p/392986663
1.鼻祖LBP的簡(jiǎn)單回顧
在傳統(tǒng)的手工特征中,比較經(jīng)典的有Oulu提出的 LBP(Local Binary Patterns),即局部二值模式 [1],至今引用已有16000+。最初的LBP是定義在3×3鄰域內(nèi)的,以鄰域中心像素為閾值,將相鄰的8個(gè)像素的灰度值與其進(jìn)行差分比較,若周?chē)袼刂荡笥谥行南袼刂担瑒t該像素點(diǎn)的位置被標(biāo)記為1,否則為0。這樣,鄰域內(nèi)的8個(gè)點(diǎn)經(jīng)比較可產(chǎn)生8位二進(jìn)制數(shù)(通常轉(zhuǎn)換為十進(jìn)制數(shù)即LBP碼,共256種),即得到該鄰域中心像素點(diǎn)的LBP值,并用這個(gè)值來(lái)反映該區(qū)域的紋理信息。

用公式表示為:
LBP算子運(yùn)算速度快,同時(shí)聚合了鄰域內(nèi)的差分信息,對(duì)光照變化較為魯棒;同時(shí)也能較好地描述細(xì)粒度的紋理信息,故在早期紋理識(shí)別,人臉識(shí)別等都被廣泛應(yīng)用。下圖為人臉圖像在做LBP變換后的LBP碼圖像,可以看出臉部局部紋理特征較好地被表征:

2.中心差分卷積CDC在人臉活體檢測(cè)中的應(yīng)用 [2,3]
CDC代碼鏈接: github.com/ZitongYu/CDC
Vanilla卷積通常直接聚合局部intensity-level的信息,故 1)容易受到外界光照等因素的影響;2)比較難表征細(xì)粒度的特征。在人臉活體檢測(cè)任務(wù)中,前者容易導(dǎo)致模型的泛化能力較弱,如在未知的光照環(huán)境下測(cè)試性能較低;后者會(huì)導(dǎo)致難以學(xué)到防偽本質(zhì)的細(xì)節(jié)信息,如spoof的材質(zhì)。考慮到空間差分特征具有較強(qiáng)光照不變性,同時(shí)也包含更細(xì)粒度的spoof線索(如柵格效應(yīng),屏幕反射等),借鑒傳統(tǒng)LBP的差分思想,我們提出了中心差分卷積(Central difference convolution, CDC)。

假定鄰域  為3x3區(qū)域,公式表達(dá)如下: 為了更好同時(shí)利用 intensity-level 和 gradient-level 的信息,我們通過(guò)超參 及共享卷積可學(xué)習(xí)的權(quán)重,統(tǒng)一了VanillaConv和CDC,而無(wú)需額外的可學(xué)習(xí)參數(shù)(和可忽略的計(jì)算量)。故更generalized的CDC公式為:
為3x3區(qū)域,公式表達(dá)如下: 為了更好同時(shí)利用 intensity-level 和 gradient-level 的信息,我們通過(guò)超參 及共享卷積可學(xué)習(xí)的權(quán)重,統(tǒng)一了VanillaConv和CDC,而無(wú)需額外的可學(xué)習(xí)參數(shù)(和可忽略的計(jì)算量)。故更generalized的CDC公式為:
θ控制著差分卷積及Vanilla卷積的貢獻(xiàn),值越大意味著gradient clue占比越重;當(dāng)θ=0時(shí),就成了Vanilla卷積。文章 [3]中也具體對(duì)比了CDC與前人工作Local Binary Convolution [4], Gabor Convolution [5] 和 Self-Attention layer [6],有興趣的請(qǐng)查閱原文。
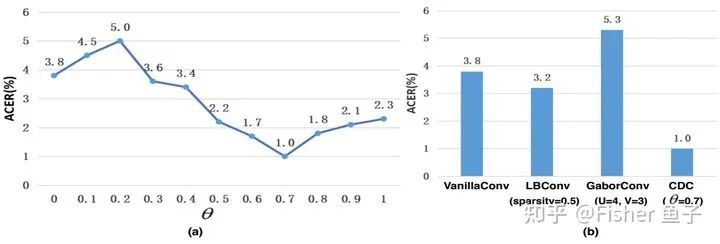
上圖可見(jiàn),當(dāng) 時(shí),使用CDC效果總比單獨(dú)Vanilla卷積要好(也就是 )。我們也觀察到,當(dāng) 時(shí),該協(xié)議下活體檢測(cè)性能處于最優(yōu),并優(yōu)于LBConv [4]和GaborConv [5]。
3.交叉中心差分卷積C-CDC在人臉活體檢測(cè)中的應(yīng)用 [7]
C-CDC代碼鏈接:
github.com/ZitongYu/CDC
考慮到CDC需要對(duì)所有鄰域特征都進(jìn)行差分操作,存在著較大的冗余,同時(shí)各方向的梯度聚合使得網(wǎng)絡(luò)優(yōu)化較為困難,我們提出了交差中心差分卷積(Cross-CDC),將CDC解耦成水平垂直和對(duì)角線兩個(gè)對(duì)稱交叉的子算子:
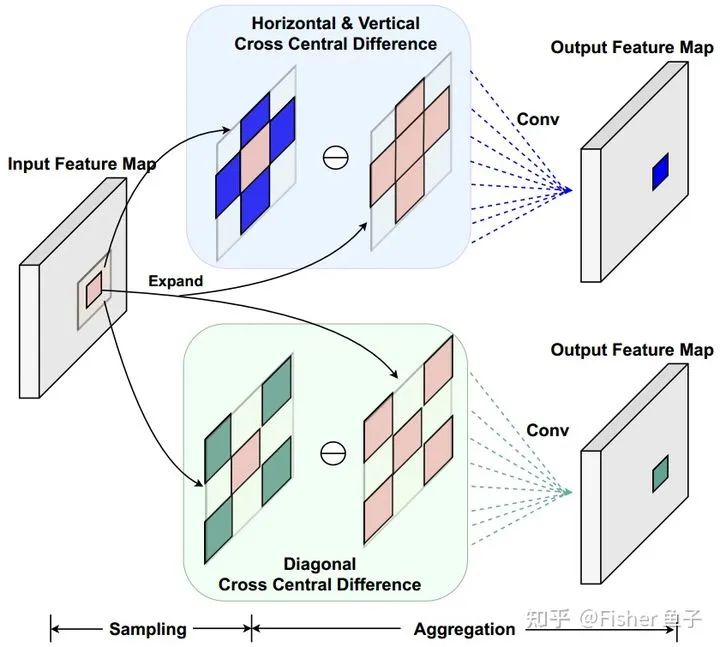
具體實(shí)現(xiàn)只需將感受野從原本的3x3鄰域 改成對(duì)應(yīng)水平垂直或者對(duì)角方向的子鄰域  即可。使用C-CDC(HV)或者C-CDC(DG)后,如下表所示,網(wǎng)絡(luò)的參數(shù)量和FLOPs都大幅度減少,并取得與原本CDC媲美的性能。
即可。使用C-CDC(HV)或者C-CDC(DG)后,如下表所示,網(wǎng)絡(luò)的參數(shù)量和FLOPs都大幅度減少,并取得與原本CDC媲美的性能。

在下圖(b)消融實(shí)驗(yàn)中可見(jiàn),相比CDC (ACER=1%),C-CDC(HV) 和 C-CDC(DG)也能取得相當(dāng)?shù)男阅堋S腥さ氖牵绻麑?duì)于VanillaConv進(jìn)行HV或者DG方向的分解,性能就會(huì)下降得比較嚴(yán)重,intensity-level信息對(duì)于充足感受野范圍需求較大。

4.像素差分卷積PDC在邊緣檢測(cè)中的應(yīng)用 [8]
PDC代碼鏈接:
GitHub - zhuoinoulu/pidinet: Code for ICCV 2021 paper "Pixel Difference Networks for Efficient Edge Detection"
在邊緣檢測(cè)中,如下圖(a)所示,經(jīng)典的傳統(tǒng)操作子(如Roberts, Sobel和LoG)都采用差分信息來(lái)表征邊緣上下文的突變及細(xì)節(jié)特征。但是這些基于手工傳統(tǒng)算子的模型往往局限于它的淺層表征能力。另外一方面, CNN通過(guò)卷積的深層堆疊,能夠有效地捕捉圖像的語(yǔ)義特征。在此過(guò)程中,卷積核扮演了捕捉局部圖像模式的作用。而如下圖(b)所示,VanillaCNN在對(duì)卷積核的初始化過(guò)程中并沒(méi)有顯式的梯度編碼限制,使其在訓(xùn)練過(guò)程中很難聚焦對(duì)圖像梯度信息的提取,從而影響了邊緣預(yù)測(cè)的精度。
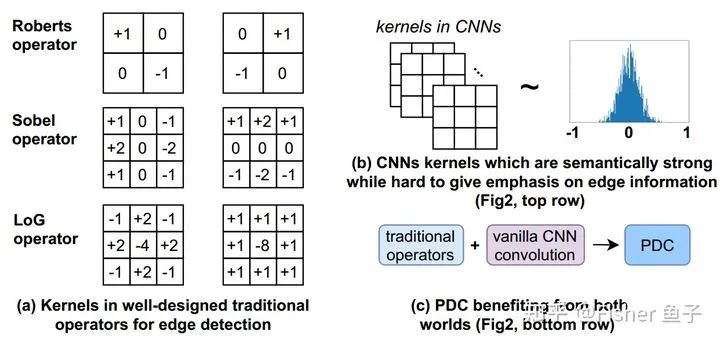
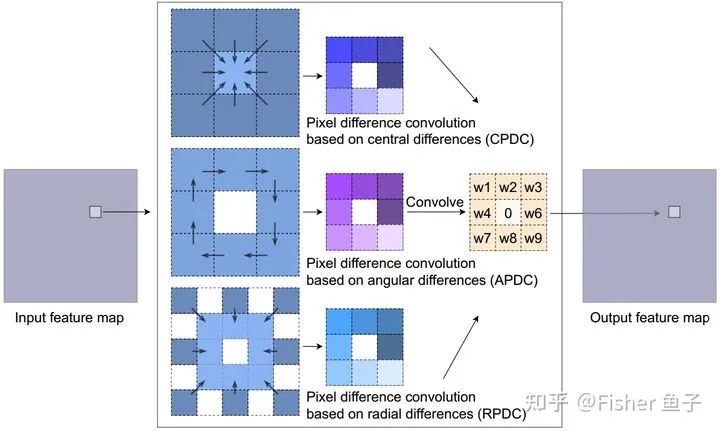
為了高效地引入差分操作到CNN中,借鑒于Extended LBP (ELBP) [9],我們提出了像素差分卷積(Pixel difference convolution, PDC)。根據(jù)候選像素對(duì)的采樣策略,PDC具體分為下圖所示三種子形式,其中CPDC類(lèi)似CDC對(duì)鄰域特征進(jìn)行中心差分;而APDC對(duì)鄰域進(jìn)行順時(shí)針?lè)较虻膬蓛刹罘郑蛔詈驲PDC對(duì)更大感受野5x5鄰域的外環(huán)與內(nèi)環(huán)進(jìn)行差分。
文中另外一個(gè)貢獻(xiàn)是提出了高效轉(zhuǎn)換PDC為VanillaConv的實(shí)現(xiàn)及推導(dǎo)證明,即先計(jì)算卷積核weights間的difference,接著直接對(duì)輸入的特征圖進(jìn)行卷積。該tweak不僅可以加速training階段,而且還可降低在inference階段的額外差分計(jì)算量。以CPDC為例,轉(zhuǎn)換公式如下: 具體的三種PDC如何組合效果最好,可閱讀文章消融實(shí)驗(yàn)及分析。最后下圖可視化了PiDiNet-Tiny網(wǎng)絡(luò)配套VanillaConv或者PDC后的特征圖及邊緣預(yù)測(cè)。明顯的是,使用PDC后,gradient信息的增強(qiáng)有利于更精確的邊緣檢測(cè)。

5.時(shí)空差分卷積3D-CDC在視頻手勢(shì)/動(dòng)作識(shí)別中的應(yīng)用 [10]
3D-CDC代碼鏈接:
github.com/ZitongYu/3DC
不同于靜態(tài)spatial圖像分析,幀間的motion信息在spatio-temporal視頻分析中往往扮演著重要角色。很多經(jīng)典motion算子,如光流optical flow和動(dòng)態(tài)圖dynamic image的計(jì)算都或多或少包含著幀內(nèi)spatial、幀間temporal、幀間spatio-temporal的差異信息。當(dāng)下主流的3DCNN一般都采用vanilla 2D、3D、偽3D的卷積操作,故較難感知細(xì)粒度的時(shí)空差異信息。與部分已有工作設(shè)計(jì)額外Modules(如OFF [11],MFNet [12])的思路不同,我們?cè)O(shè)計(jì)了時(shí)空差分卷積(3D-CDC)來(lái)高效提取時(shí)空差異特征,可取代Vanilla3DConv,直插直用于任何3DCNN,并無(wú)額外參數(shù)開(kāi)銷(xiāo)。
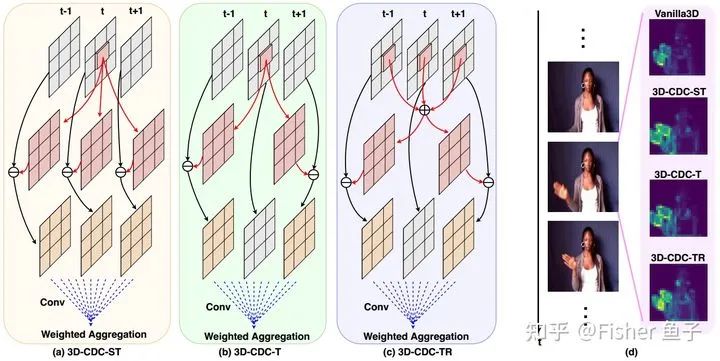
如上圖所示,3D-CDC家族有包含三種子卷積,來(lái)增強(qiáng)時(shí)域特征的同時(shí)服務(wù)于不同場(chǎng)景。如3DCDC-ST擅長(zhǎng)于動(dòng)態(tài)紋理表征;3D-CDC-T則更多捕捉精細(xì)的時(shí)域上下文信息;而3DCDC-TR則更耐抗時(shí)域間噪聲擾動(dòng) 。它們的generalized版本公式如下:( 相鄰幀)
下圖給出了C3D模型基于3D-CDC家族的性能,可見(jiàn)針對(duì)不同模態(tài)(尤其是RGB和光流),在大部分 θ取值 下3D-CDC-T和3D-CDC-TR能帶來(lái)額外的視頻表征收益( θ=0僅為使用Vanilla3DConv)。

6.其他差分卷積及應(yīng)用
文獻(xiàn) [13] 將 CDC 思想應(yīng)用到圖卷積中,形成差分圖卷積(Central Difference Graph Convolution,CDGC)。
文獻(xiàn) [14] 將 CDC 應(yīng)用到實(shí)時(shí) Saliency detection 任務(wù)中。
文獻(xiàn) [15] 將 3D-CDC 應(yīng)用到 人臉遠(yuǎn)程生理信號(hào)rPPG測(cè)量 中。
文獻(xiàn) [18] 將 CDC 應(yīng)用到 人臉 DeepFake detection 中。
文獻(xiàn) [19] 將 PDC 拓展為random版本,應(yīng)用到人臉識(shí)別,表情識(shí)別,種族識(shí)別中。
7.總結(jié)與展望
一方面,如何將可解釋性強(qiáng)的經(jīng)典傳統(tǒng)算子(如LBP, HOG, SIFT等)融入到最新的DL框架(CNN,Vision Transformer,MLP-like等)中來(lái)增強(qiáng)性能(如準(zhǔn)確率,遷移性,魯棒性,高效性等),將是持續(xù)火熱的topic;另外一方面就是探索和應(yīng)用到更多vision tasks 來(lái)服務(wù)計(jì)算機(jī)視覺(jué)落地。
Reference:
[1] Timo Ojala, et al. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. TPAMI 2002.
[2] Zitong Yu, et al. Searching central difference convolutional networks for face anti-spoofing. CVPR 2020.
[3] Zitong Yu, et al. Nas-fas: Static-dynamic central difference network search for face anti-spoofing. TPAMI 2020.
[4] Juefei Xu, et al. Local binary convolutional neural networks. CVPR 2017.
[5] Shangzhen Luan, et al. Gabor convolutional networks. TIP 2018.
[6] Ramachandran Prajit, et al. Stand-alone self-attention in vision models. NeurIPS 2019.
[7] Zitong Yu, et al. Dual-Cross Central Difference Network for Face Anti-Spoofing. IJCAI 2021.
[8] Zhuo Su, et al. Pixel Difference Networks for Efficient Edge Detection. ICCV 2021 (Oral)
[9] Li Liu, et al. Extended local binary patterns for texture classification. Image and Vision Computing 2012.
[10] Zitong Yu, et al. Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition. TIP 2021.
[11] Shuyang Sun, et al. Optical flow guided feature: A fast and robust motion representation for video action recognition. CVPR 2018.
[12] Myunggi Lee, et al. Motion feature network: Fixed motion filter for action recognition. ECCV 2018.
[13] Klimack, Jason. A Study on Different Architectures on a 3D Garment Reconstruction Network. MS thesis. Universitat Politècnica de Catalunya, 2021.
[14] Zabihi Samad, et al. A Compact Deep Architecture for Real-time Saliency Prediction. arXiv 2020.
[15] Zhao Yu, et al. Video-Based Physiological Measurement Using 3D Central Difference Convolution Attention Network. IJCB 2021.
[16] Zitong Yu, et al. Multi-modal face anti-spoofing based on central difference networks. CVPRW 2020.
[17] Haoyu Chen, et al. 2nd place scheme on action recognition track of ECCV 2020 VIPriors challenges: An efficient optical flow stream guided framework. arXiv 2020.
[18] Yang et al. MTD-Net: Learning to Detect Deepfakes Images by Multi-Scale Texture Difference, TIFS 2021
[19] Liu et al. Beyond Vanilla Convolution: Random Pixel Difference Convolution on Face Perception. IEEE Access 2021
好消息!
小白學(xué)視覺(jué)知識(shí)星球
開(kāi)始面向外開(kāi)放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車(chē)道線檢測(cè)、車(chē)輛計(jì)數(shù)、添加眼線、車(chē)牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~