
Transformer在計(jì)算機(jī)視覺中的應(yīng)用-VIT、TNT模型

向AI轉(zhuǎn)型的程序員都關(guān)注了這個(gè)號(hào)??????
Transforme這一模型并不難,依舊是傳統(tǒng)機(jī)器翻譯模型中常見的seq2seq網(wǎng)絡(luò),里面加入了注意力機(jī)制,QKV矩陣的運(yùn)算使得計(jì)算并行。
當(dāng)然,最大的重點(diǎn)不是矩陣運(yùn)算,而是注意力機(jī)制的出現(xiàn)。
一、CNN最大的問題是什么
CNN依舊是十分優(yōu)秀的特征提取器,然而注意力機(jī)制的出現(xiàn)使得CNN隱含的一些問題顯露了出來
CNN中一個(gè)很重要的概念是感受野,一開始神經(jīng)網(wǎng)絡(luò)漸層的的卷積核中只能看到一些線條邊角等信息,而后才能不斷加大,看到一個(gè)小小的“面”,看到鼻子眼睛,再到后來看到整個(gè)頭部。一方面的問題是:做到這些需要網(wǎng)絡(luò)層數(shù)不斷地加深(不考慮卷積核的大小),感受野才會(huì)變大;另一方面的問題是:特征圖所表達(dá)出來的信息往往是十分抽象的,我們不清楚到底需要多少層也不清楚每層的抽象信息是否都有用(ResNet出現(xiàn))。
假設(shè)我們的臉貼在一幅畫上,我們無法看出一幅畫里都有什么;“管中窺豹”、“坐井觀天”、“一葉障目” 等都是我們此時(shí)的感受野太小了;稍微抬下頭,我們看到了畫中的人;稍微站得遠(yuǎn)一步,我們看到了整幅畫從腦中的經(jīng)驗(yàn)得知,這是《清明上河圖》。

上面這種情況是我們機(jī)械的從視野的角度去分辨看待事物,然而我們是人類,我們擁有注意力。
我們會(huì)在觀察一張圖片時(shí)會(huì)忽略背景,注意圖片中的主體(或相反)
我們會(huì)在區(qū)分獅子還是老虎時(shí),更注意看它們的毛發(fā),它們的頭上有沒有“王”。

回想注意力機(jī)制的特點(diǎn),它是從"整體"上觀察我們需要什么,要注意的地方在哪里。既然是在整體上觀察,那么其“感受野”,一定就相當(dāng)于許多層之后的CNN了。
CNN許多層才做到的事情,在Transformer中第一層就做到了。
二、VIT整體架構(gòu)解讀
2.1 圖像轉(zhuǎn)換成序列
接下來就是該怎么做了,由于Transofrmer是序列到序列模型,我們需要把圖像信息轉(zhuǎn)為序列傳給Encoder。
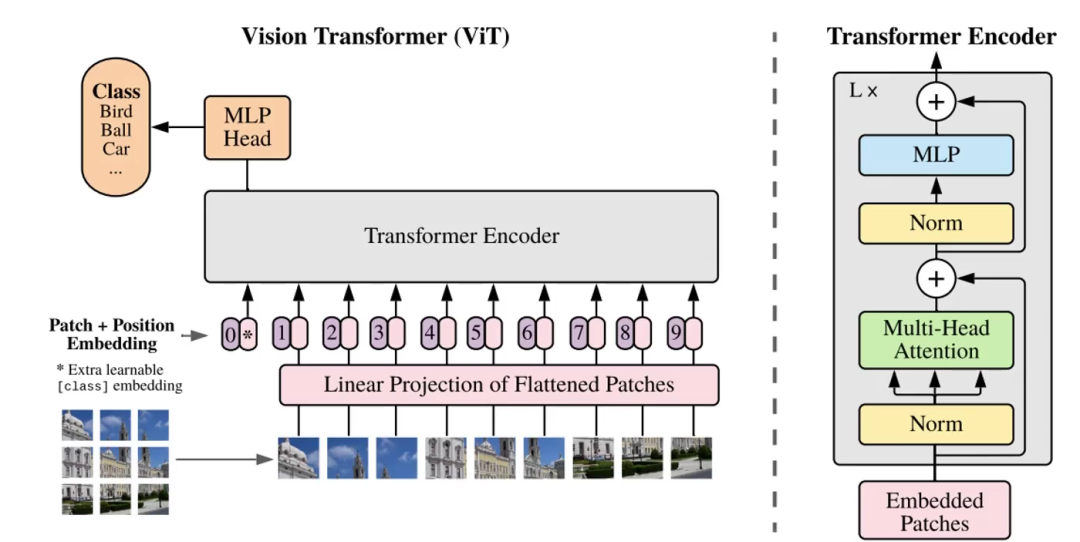
觀察上圖左下角,一個(gè)完整的圖片,我們可以把它切割成9份(舉例),9個(gè)patch,每一份比如說是10x10x3的矩陣。將每一份通過一次卷積變成1x300的矩陣,由此變成序列。
如上圖,9個(gè)300維的向量傳遞給Linear Projection of Flattened Patches層,其實(shí)就是一次全連接進(jìn)行映射,把我們這些300維的向量映射成256/512維等的向量。
之后傳遞給Transformer Encoder。
2.2 VIT位置編碼
我們上面把一張圖片切成了9份,每份都有建筑物的一部分,要讓計(jì)算機(jī)更好地識(shí)別出圖片內(nèi)容,這9份應(yīng)當(dāng)給它們加上序號(hào),即位置編碼。
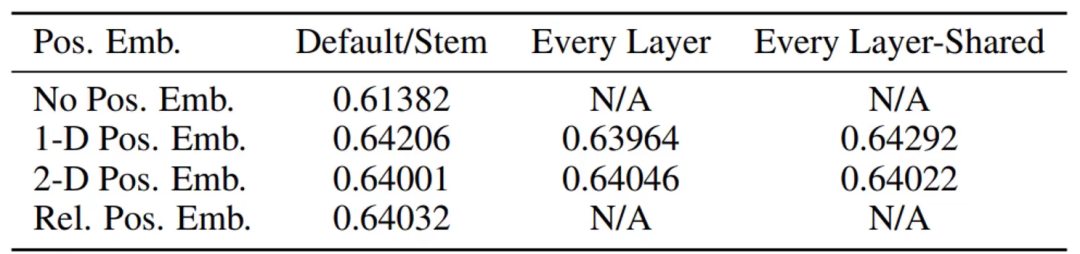
論文實(shí)驗(yàn)證明,加上序號(hào)比不加效果好;以1-9為序號(hào)和以(1,1) (1,2) (1,3) (2,1)...(3,3)為序號(hào)結(jié)果相差不大
當(dāng)然,該論文進(jìn)行的是分類任務(wù),位置編碼1D和2D確實(shí)沒有太大區(qū)別。但如果放在分割等任務(wù)就不一定了。
2.3 VIT工作原理
可以看到,上圖除了1-9以外,還存在一個(gè)序列0,我們把這個(gè)0叫做token。這個(gè)token一般只用于分類任務(wù),而檢測(cè)分割一般用不到。
以分類任務(wù)為例,無非是多了一行序列。
當(dāng)把0號(hào)token+序列1-9傳遞給Encoder后,它內(nèi)部進(jìn)行QKV計(jì)算,和權(quán)重矩陣計(jì)算轉(zhuǎn)變?yōu)镼KV矩陣?yán)^續(xù)計(jì)算。其本質(zhì)就是0號(hào)token+序列1-9這10個(gè)序列點(diǎn)積,這樣0號(hào)token中就是存儲(chǔ)著序列1-9的特征9個(gè)patch的。如此經(jīng)過L輪,經(jīng)過L輪計(jì)算,0號(hào)token中的信息就是全局信息了。
之后,就可以使用0號(hào)token這個(gè)向量去做分類了。
2.4 backbone

如上,Embedded Patches+位置編碼后經(jīng)過層歸一化,多頭注意力,層歸一化,全連接,期間還有這殘差連接。
另外這不只是一輪,而是會(huì)執(zhí)行多次
三、Transformer為什么能
就像 一 中末尾說的那樣,它是從"整體"上觀察我們需要什么,要注意的地方在哪里。既然是在整體上觀察,那么其“感受野”,一定就相當(dāng)于許多層之后的CNN了。
因?yàn)?號(hào)token是最后拿去進(jìn)行分類的,在計(jì)算時(shí),第一層第一次的計(jì)算0號(hào)就分別于1-9patch進(jìn)行了點(diǎn)積,這9個(gè)局部信息組成的整體便是這張圖片。

上圖可以看到,這樣做在淺層就能獲得較大的范圍信息;可能5層就做得比CNN好了;全局信息豐富,更有助于理解圖像。
四、VIT公式解讀和效果圖
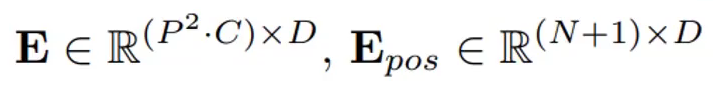
E表示的是全連接,P2·C的矩陣映射為P2·D維。后面的則是位置編碼,(N+1)·D維,N是N個(gè)patch,+1是因?yàn)榍懊嫠岬?號(hào)token。
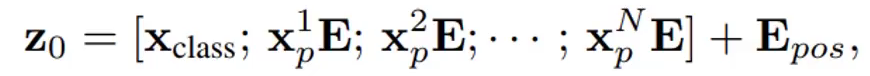
Z是每層的輸入,Z0就是第0層,記得加上位置編碼。
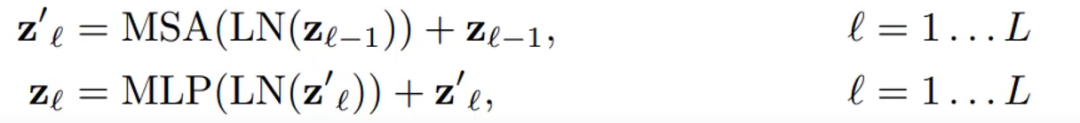
然后就是進(jìn)行多輪多頭注意力機(jī)制的運(yùn)算,MSA是多頭注意力,LN是層歸一化,MLP是全連接。后面的加法是殘差連接。
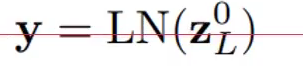
最后輸出結(jié)果。
效果圖
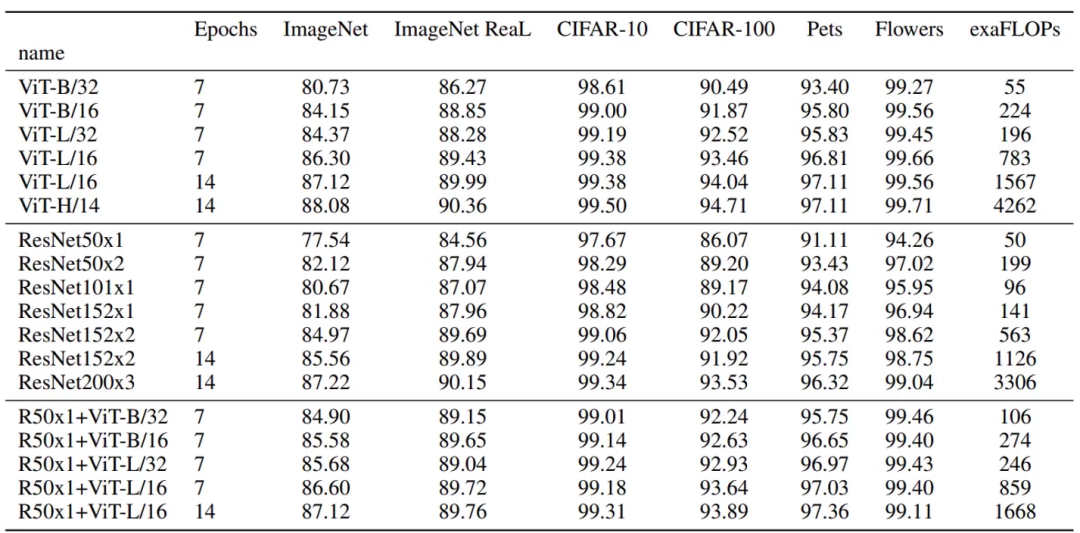
其中ViT后面的16 14 32指的是patch的大小,對(duì)于一張圖片來說,patch越大窗口數(shù)量越少,patch越小窗口數(shù)量越多。
顯然與ResNet相比,ViT更好些。
五、TNT模型
5.1 TNT介紹
TNT:Transformer in Transformer
在VIT中,只針對(duì)patch進(jìn)行了建模,比如一個(gè)patch是16*16*C (其中C是特征圖個(gè)數(shù),可能是256、512等)。每個(gè)patch可能有點(diǎn)大了,越大的patch所蘊(yùn)含的信息就越多,學(xué)習(xí)起來難度就越大。
因此,一方面可以基于patch去做,另一方面還可以把patch再分得細(xì)一點(diǎn),如16*16分成4個(gè)4*4。
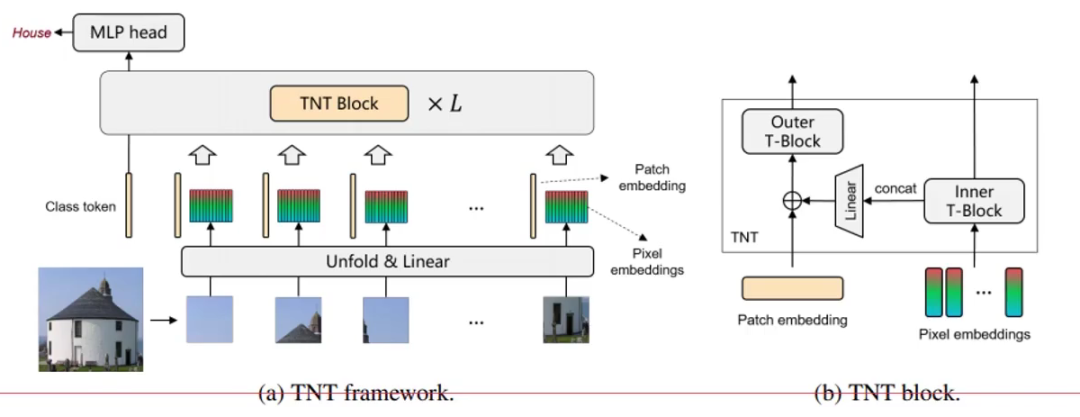
所以TNT的名字就代表了它要做什么,在Transformer里嵌套一個(gè)Transformer。
5.2 TNT模型做法分析
TNT由外部Transformer和內(nèi)部Transoformer組成,其中:
外部Transformer與VIT的做法一樣

內(nèi)部把每個(gè)patch組成多個(gè)超像素(4個(gè)像素點(diǎn)),把重組的序列繼續(xù)做Transformer。

以16*16為例,序列的長(zhǎng)度就是256了,太長(zhǎng)了太慢了效率低,且通常一個(gè)像素點(diǎn)也不能表達(dá)什么信息。至少也是4個(gè)點(diǎn)。因此內(nèi)部將每個(gè)patch拆分成很多個(gè)4*4的小塊,即分成更多個(gè)batch,然后重組。
以內(nèi)部的一個(gè)16*16*3的patch為例,拆分成4*4的超像素,結(jié)果就是每一個(gè)超像素,每一個(gè)小patch上特征的個(gè)數(shù)。
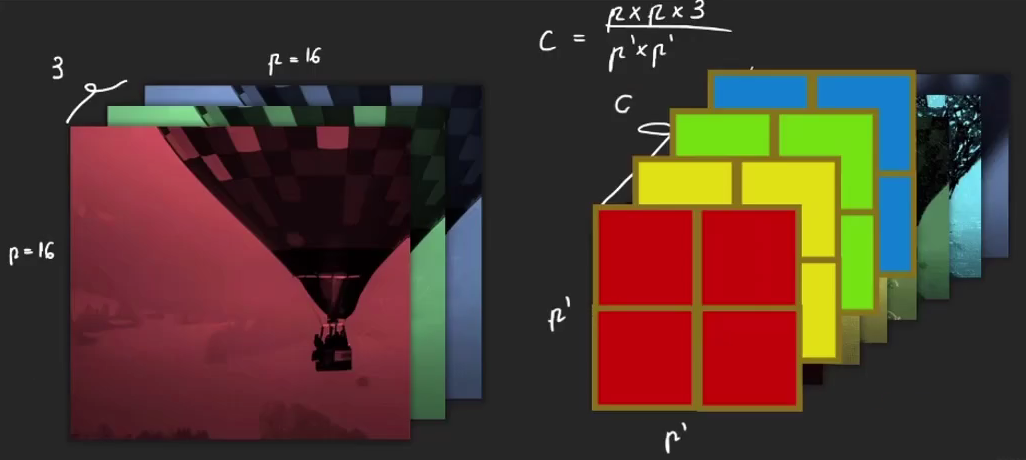
(16?16?3)/(4?4)=48
之前一個(gè)點(diǎn)上有3個(gè)channel的信息,而現(xiàn)在一個(gè)點(diǎn)上有48個(gè)。patch變小了但濃縮了。
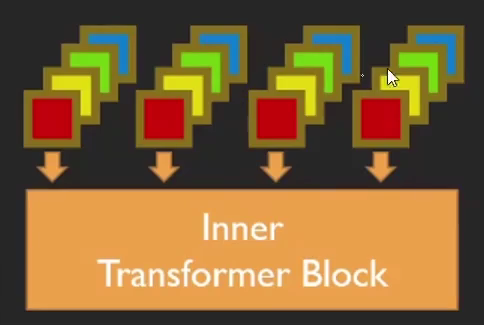
把這些小patch整合在一起,全連接,之后的Transformer與前面一樣。

如上,每個(gè)patch經(jīng)過外部Transformer計(jì)算得到向量,每個(gè)patch又拆分成小patch后全連接,經(jīng)過內(nèi)部Transformer得到同樣維度的輸出向量。兩個(gè)向量加在一起,作為最后的輸出結(jié)果。
5.4 TNT模型位置編碼
實(shí)驗(yàn)證明,內(nèi)外Transormer都進(jìn)行位置編碼效果更好。
5.5 TNT效果
上方是DeiT,就當(dāng)作是VIT把,下面是TNT。
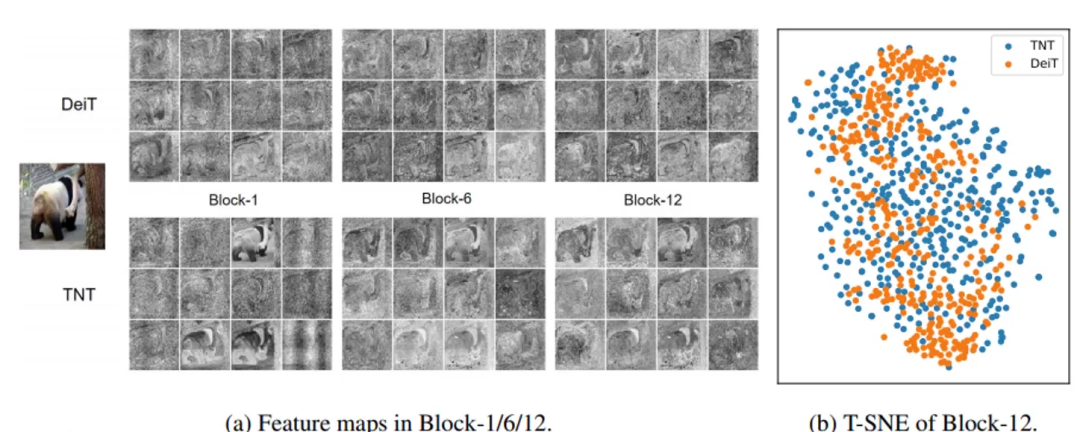
顯而易見TNT特征提取得更鮮明,效果更好,更細(xì)膩。
右圖可見TNT點(diǎn)更發(fā)散些,說明特征更發(fā)散些,更好區(qū)分。
機(jī)器學(xué)習(xí)算法AI大數(shù)據(jù)技術(shù)
搜索公眾號(hào)添加: datanlp
長(zhǎng)按圖片,識(shí)別二維碼
閱讀過本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實(shí)戰(zhàn)
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測(cè)
《基于深度學(xué)習(xí)的自然語言處理》中/英PDF
Deep Learning 中文版初版-周志華團(tuán)隊(duì)
【全套視頻課】最全的目標(biāo)檢測(cè)算法系列講解,通俗易懂!
《美團(tuán)機(jī)器學(xué)習(xí)實(shí)踐》_美團(tuán)算法團(tuán)隊(duì).pdf
《深度學(xué)習(xí)入門:基于Python的理論與實(shí)現(xiàn)》高清中文PDF+源碼
《深度學(xué)習(xí):基于Keras的Python實(shí)踐》PDF和代碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實(shí)戰(zhàn)項(xiàng)目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個(gè)項(xiàng)目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實(shí)踐詳解》完整版PDF+附書代碼
《深度學(xué)習(xí)之pytorch》pdf+附書源碼
PyTorch深度學(xué)習(xí)快速實(shí)戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評(píng)分8.1,《機(jī)器學(xué)習(xí)實(shí)戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識(shí)圖譜項(xiàng)目實(shí)戰(zhàn)視頻(全23課)
李沐大神開源《動(dòng)手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計(jì)學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
將機(jī)器學(xué)習(xí)模型部署為REST API
FashionAI服裝屬性標(biāo)簽圖像識(shí)別Top1-5方案分享
重要開源!CNN-RNN-CTC 實(shí)現(xiàn)手寫漢字識(shí)別
同樣是機(jī)器學(xué)習(xí)算法工程師,你的面試為什么過不了?
前海征信大數(shù)據(jù)算法:風(fēng)險(xiǎn)概率預(yù)測(cè)
【Keras】完整實(shí)現(xiàn)‘交通標(biāo)志’分類、‘票據(jù)’分類兩個(gè)項(xiàng)目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實(shí)現(xiàn)醫(yī)學(xué)圖像識(shí)別分類工程項(xiàng)目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級(jí)聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
全球AI挑戰(zhàn)-場(chǎng)景分類的比賽源碼(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識(shí)別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競(jìng)賽華人第1名團(tuán)隊(duì)-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析、python
搜索公眾號(hào)添加: datayx