
ResNet在計(jì)算機(jī)視覺中的應(yīng)用
點(diǎn)擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時(shí)間送達(dá)
2.數(shù)據(jù)預(yù)處理
import?tensorflow?as?tf
from?tensorflow.keras.models?import?Model
from?tensorflow.keras.layers?import?Layer,?BatchNormalization,?Conv2D,?Dense,?Flatten,?Add,?Dropout,?BatchNormalization
import?numpy?as?np
from?tensorflow.keras.datasets?import?fashion_mnist
from?tensorflow.keras.utils?import?to_categorical
import?matplotlib.pyplot?as?plt
from?sklearn.model_selection?import?train_test_split
from?tensorflow.keras.preprocessing.image?import?ImageDataGenerator
import?os
from?tensorflow.keras?import?Input,?layers
from?tensorflow.keras.layers?import?Dense,?Flatten,?Conv2D,?MaxPooling2D
import?time
directory_train?=?"./simpsons_data_split/train/"
directory_test?=?"./simpsons_data_split/test/"
def?get_ImageDataGenerator(validation_split=None):
????image_generator?=?ImageDataGenerator(rescale=(1/255.),
?????????????????????????????????????????validation_split=validation_split)
????return?image_generator
image_gen_train?=?get_ImageDataGenerator(validation_split=0.2)
def?get_generator(image_data_generator,?directory,?train_valid=None,?seed=None):
????train_generator?=?image_data_generator.flow_from_directory(directory,?
???????????????????????????????????????????????????????????????batch_size=32,?
?????????????????????????????????????????????????????????????????class_mode='categorical',?
???????????????????????????????????????????????????????????????target_size=(128,128),?
???????????????????????????????????????????????????????????????subset=train_valid,?
???????????????????????????????????????????????????????????????seed=seed)????
????return?train_generator
train_generator?=?get_generator(image_gen_train,?directory_train,?train_valid='training',?seed=1)
validation_generator?=?get_generator(image_gen_train,?directory_train,?train_valid='validation')
Found?12411?images?belonging?to?19?classes.
Found?3091?images?belonging?to?19?classes.
def?get_ImageDataGenerator_augmented(validation_split=None):
????image_generator?=?ImageDataGenerator(rescale=(1/255.),
????????????????????????????????????????rotation_range=40,
????????????????????????????????????????width_shift_range=0.2,
????????????????????????????????????????height_shift_range=0.2,
????????????????????????????????????????shear_range=0.2,
????????????????????????????????????????zoom_range=0.1,
????????????????????????????????????????brightness_range=[0.8,1.2],
????????????????????????????????????????horizontal_flip=True,
????????????????????????????????????????validation_split=validation_split)
????return?image_generator
????
image_gen_train_aug?=?get_ImageDataGenerator_augmented(validation_split=0.2)
train_generator_aug?=?get_generator(image_gen_train_aug,?directory_train,?train_valid='training',?seed=1)
validation_generator_aug?=?get_generator(image_gen_train_aug,?directory_train,?train_valid='validation')
Found?12411?images?belonging?to?19?classes.
Found?3091?images?belonging?to?19?classes.
target_labels?=?next(os.walk(directory_train))[1]
target_labels.sort()
batch?=?next(train_generator)
batch_images?=?np.array(batch[0])
batch_labels?=?np.array(batch[1])
target_labels?=?np.asarray(target_labels)
plt.figure(figsize=(15,10))
for?n,?i?in?enumerate(np.arange(10)):
????ax?=?plt.subplot(3,5,n+1)
????plt.imshow(batch_images[i])
????plt.title(target_labels[np.where(batch_labels[i]==1)[0][0]])
????plt.axis('off')

3.基準(zhǔn)模型
def?get_benchmark_model(input_shape):
????x?=?Input(shape=input_shape)
????h?=?Conv2D(32,?padding='same',?kernel_size=(3,3),?activation='relu')(x)
????h?=?Conv2D(32,?padding='same',?kernel_size=(3,3),?activation='relu')(x)
????h?=?MaxPooling2D(pool_size=(2,2))(h)
????h?=?Conv2D(64,?padding='same',?kernel_size=(3,3),?activation='relu')(h)
????h?=?Conv2D(64,?padding='same',?kernel_size=(3,3),?activation='relu')(h)
????h?=?MaxPooling2D(pool_size=(2,2))(h)
????h?=?Conv2D(128,?kernel_size=(3,3),?activation='relu')(h)
????h?=?Conv2D(128,?kernel_size=(3,3),?activation='relu')(h)
????h?=?MaxPooling2D(pool_size=(2,2))(h)
????h?=?Flatten()(h)
????h?=?Dense(128,?activation='relu')(h)
????h?=?Dropout(.5)(h)
????output?=?Dense(target_labels.shape[0],?activation='softmax')(h)
????model?=?tf.keras.Model(inputs=x,?outputs=output)
????
????model.compile(optimizer='adam',
?????????????loss='categorical_crossentropy',
?????????????metrics=['accuracy'])
????return?model
????
benchmark_model?=?get_benchmark_model((128,?128,?3))
benchmark_model.summary()
Model:?"model"
_________________________________________________________________
Layer?(type)?????????????????Output?Shape??????????????Param?#???
=================================================================
input_1?(InputLayer)?????????[(None,?128,?128,?3)]?????0?????????
_________________________________________________________________
conv2d_1?(Conv2D)????????????(None,?128,?128,?32)??????896???????
_________________________________________________________________
max_pooling2d?(MaxPooling2D)?(None,?64,?64,?32)????????0?????????
_________________________________________________________________
conv2d_2?(Conv2D)????????????(None,?64,?64,?64)????????18496?????
_________________________________________________________________
conv2d_3?(Conv2D)????????????(None,?64,?64,?64)????????36928?????
_________________________________________________________________
max_pooling2d_1?(MaxPooling2?(None,?32,?32,?64)????????0?????????
_________________________________________________________________
conv2d_4?(Conv2D)????????????(None,?30,?30,?128)???????73856?????
_________________________________________________________________
conv2d_5?(Conv2D)????????????(None,?28,?28,?128)???????147584????
_________________________________________________________________
max_pooling2d_2?(MaxPooling2?(None,?14,?14,?128)???????0?????????
_________________________________________________________________
flatten?(Flatten)????????????(None,?25088)?????????????0?????????
_________________________________________________________________
dense?(Dense)????????????????(None,?128)???????????????3211392???
_________________________________________________________________
dropout?(Dropout)????????????(None,?128)???????????????0?????????
_________________________________________________________________
dense_1?(Dense)??????????????(None,?19)????????????????2451??????
=================================================================
Total?params:?3,491,603
Trainable?params:?3,491,603
Non-trainable?params:?0
_________________________________________________________________
def?train_model(model,?train_gen,?valid_gen,?epochs):
????train_steps_per_epoch?=?train_gen.n?//?train_gen.batch_size
????val_steps?=?valid_gen.n?//?valid_gen.batch_size
????
????earlystopping?=?tf.keras.callbacks.EarlyStopping(patience=3)
????history?=?model.fit(train_gen,?
????????????????????????steps_per_epoch?=?train_steps_per_epoch,
????????????????????????epochs=epochs,
????????????????????????validation_data=valid_gen,?
????????????????????????callbacks=[earlystopping])
????
????return?history
????
train_generator?=?get_generator(image_gen_train,?directory_train,?train_valid='training')
validation_generator?=?get_generator(image_gen_train,?directory_train,?train_valid='validation')
history_benchmark?=?train_model(benchmark_model,?train_generator,?validation_generator,?50)
Found?12411?images?belonging?to?19?classes.
Found?3091?images?belonging?to?19?classes.
Epoch?1/50
387/387?[==============================]?-?139s?357ms/step?-?loss:?2.7674?-?accuracy:?0.1370?-?val_loss:?2.1717?-?val_accuracy:?0.3488
Epoch?2/50
387/387?[==============================]?-?136s?352ms/step?-?loss:?2.0837?-?accuracy:?0.3757?-?val_loss:?1.7546?-?val_accuracy:?0.4940
Epoch?3/50
387/387?[==============================]?-?130s?335ms/step?-?loss:?1.5967?-?accuracy:?0.5139?-?val_loss:?1.3483?-?val_accuracy:?0.6102
Epoch?4/50
387/387?[==============================]?-?130s?335ms/step?-?loss:?1.1952?-?accuracy:?0.6348?-?val_loss:?1.1623?-?val_accuracy:?0.6619
Epoch?5/50
387/387?[==============================]?-?130s?337ms/step?-?loss:?0.9164?-?accuracy:?0.7212?-?val_loss:?1.0813?-?val_accuracy:?0.6907
Epoch?6/50
387/387?[==============================]?-?130s?336ms/step?-?loss:?0.7270?-?accuracy:?0.7802?-?val_loss:?1.0241?-?val_accuracy:?0.7240
Epoch?7/50
387/387?[==============================]?-?130s?336ms/step?-?loss:?0.5641?-?accuracy:?0.8217?-?val_loss:?0.9674?-?val_accuracy:?0.7438
Epoch?8/50
387/387?[==============================]?-?130s?336ms/step?-?loss:?0.4496?-?accuracy:?0.8592?-?val_loss:?1.0701?-?val_accuracy:?0.7441
Epoch?9/50
387/387?[==============================]?-?130s?336ms/step?-?loss:?0.3677?-?accuracy:?0.8758?-?val_loss:?0.9796?-?val_accuracy:?0.7645
Epoch?10/50
387/387?[==============================]?-?130s?336ms/step?-?loss:?0.3041?-?accuracy:?0.8983?-?val_loss:?1.0681?-?val_accuracy:?0.7561
4.ResNet
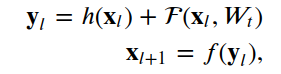
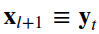
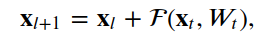
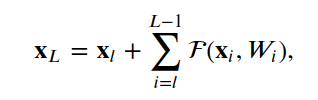
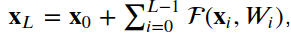
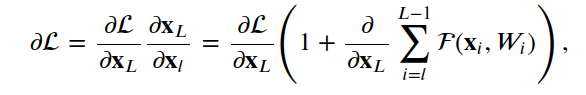

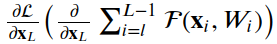
4.1殘差單位
__init__, build和call。__init__方法使用定義的關(guān)鍵字參數(shù)調(diào)用基本層類初始值設(shè)定項(xiàng)。build方法創(chuàng)建層。在我們的例子中,我們定義了兩組BatchNormalization,后面是Conv2D層,最后一組使用與層輸入相同數(shù)量的濾波器。class?ResidualUnit(Layer):
????def?__init__(self,?**kwargs):
????????super(ResidualUnit,?self).__init__(**kwargs)
????????
????def?build(self,?input_shape):
????????self.bn_1?=?tf.keras.layers.BatchNormalization(input_shape=input_shape)
????????self.conv2d_1?=?tf.keras.layers.Conv2D(input_shape[3],?(3,?3),?padding='same')
????????self.bn_2?=?tf.keras.layers.BatchNormalization()
????????self.conv2d_2?=?tf.keras.layers.Conv2D(input_shape[3],?(3,?3),?padding='same')
????????
????def?call(self,?inputs,?training=False):
????????x?=?self.bn_1(inputs,?training)
????????x?=?tf.nn.relu(x)
????????x?=?self.conv2d_1(x)
????????x?=?self.bn_2(x,?training)
????????x?=?tf.nn.relu(x)
????????x?=?self.conv2d_2(x)
????????x?=?tf.keras.layers.add([inputs,?x])
????????return?x
????????
test_model?=?tf.keras.Sequential([ResidualUnit(input_shape=(128,?128,?3),?name="residual_unit")])
test_model.summary()
Model:?"sequential"
_________________________________________________________________
Layer?(type)?????????????????Output?Shape??????????????Param?#???
=================================================================
residual_unit?(ResidualUnit)?(None,?128,?128,?3)???????192???????
=================================================================
Total?params:?192
Trainable?params:?180
Non-trainable?params:?12
_________________________________________________________________
4.2增加維度的殘差單元
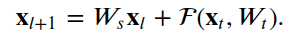
class?FiltersChangeResidualUnit(Layer):
????def?__init__(self,?out_filters,?**kwargs):
????????super(FiltersChangeResidualUnit,?self).__init__(**kwargs)
????????self.out_filters?=?out_filters
????????
????????
????def?build(self,?input_shape):
????????number_filters?=?input_shape[0]
????????self.bn_1?=?tf.keras.layers.BatchNormalization(input_shape=input_shape)
????????self.conv2d_1?=?tf.keras.layers.Conv2D(input_shape[3],?(3,?3),?padding='same')
????????self.bn_2?=?tf.keras.layers.BatchNormalization()
????????self.conv2d_2?=?tf.keras.layers.Conv2D(self.out_filters,?(3,?3),?padding='same')
????????self.conv2d_3?=?tf.keras.layers.Conv2D(self.out_filters,?(1,?1))
????????
????????
????def?call(self,?inputs,?training=False):
????????x?=?self.bn_1(inputs,?training)
????????x?=?tf.nn.relu(x)
????????x?=?self.conv2d_1(x)
????????x?=?self.bn_2(x,?training)
????????x?=?tf.nn.relu(x)
????????x?=?self.conv2d_2(x)
????????x_1?=?self.conv2d_3(inputs)
????????x?=?tf.keras.layers.add([x,?x_1])
????????return?x
????????
test_model?=?tf.keras.Sequential([FiltersChangeResidualUnit(16,?input_shape=(32,?32,?3),?name="fc_resnet_unit")])
test_model.summary()
Model:?"sequential_1"
_________________________________________________________________
Layer?(type)?????????????????Output?Shape??????????????Param?#???
=================================================================
fc_resnet_unit?(FiltersChang?(None,?32,?32,?16)????????620???????
=================================================================
Total?params:?620
Trainable?params:?608
Non-trainable?params:?12
_________________________________________________________________
4.3模型
class?ResNetModel(Model):
????def?__init__(self,?**kwargs):
????????super(ResNetModel,?self).__init__()
????????self.conv2d_1?=?tf.keras.layers.Conv2D(32,?(7,?7),?strides=(2,2))
????????self.resb?=?ResidualUnit()
????????self.conv2d_2?=?tf.keras.layers.Conv2D(32,?(3,?3),?strides=(2,2))
????????self.filtersresb?=?FiltersChangeResidualUnit(64)
????????self.flatten_1?=?tf.keras.layers.Flatten()
????????self.dense_o?=?tf.keras.layers.Dense(target_labels.shape[0],?activation='softmax')???
????????
????def?call(self,?inputs,?training=False):
????????x?=?self.conv2d_1(inputs)
????????x?=?self.resb(x,?training)
????????x?=?self.conv2d_2(x)
????????x?=?self.filtersresb(x,?training)
????????x?=?self.flatten_1(x)
????????x?=?self.dense_o(x)
????????
????????return?x
resnet_model?=?ResNetModel()
resnet_model(inputs=?tf.random.normal((32,?128,128,3)))
resnet_model.summary()
Model:?"res_net_model"
_________________________________________________________________
Layer?(type)?????????????????Output?Shape??????????????Param?#???
=================================================================
conv2d_6?(Conv2D)????????????multiple??????????????????4736??????
_________________________________________________________________
residual_unit?(ResidualUnit)?multiple??????????????????18752?????
_________________________________________________________________
conv2d_7?(Conv2D)????????????multiple??????????????????9248??????
_________________________________________________________________
filters_change_residual_unit?multiple??????????????????30112?????
_________________________________________________________________
flatten_1?(Flatten)??????????multiple??????????????????0?????????
_________________________________________________________________
dense_2?(Dense)??????????????multiple??????????????????1094419???
=================================================================
Total?params:?1,157,267
Trainable?params:?1,157,011
Non-trainable?params:?256
_________________________________________________________________
optimizer_obj?=?tf.keras.optimizers.Adam(learning_rate=0.001)
loss_obj?=?tf.keras.losses.CategoricalCrossentropy()
@tf.function
def?grad(model,?inputs,?targets,?loss):
????with?tf.GradientTape()?as?tape:
????????preds?=?model(inputs)
????????loss_value?=?loss(targets,?preds)
????return?loss_value,?tape.gradient(loss_value,?model.trainable_variables)
????
def?train_resnet(model,?num_epochs,?dataset,?valid_dataset,?optimizer,?loss,?grad_fn):
????train_steps_per_epoch?=?dataset.n?//?dataset.batch_size
????train_steps_per_epoch_valid?=?valid_dataset.n?//?valid_dataset.batch_size
????train_loss_results?=?[]
????train_accuracy_results?=?[]
????train_loss_results_valid?=?[]
????train_accuracy_results_valid?=?[]
????for?epoch?in?range(num_epochs):
????????start?=?time.time()
????????epoch_loss_avg?=?tf.keras.metrics.Mean()
????????epoch_accuracy?=?tf.keras.metrics.CategoricalAccuracy()
????????epoch_loss_avg_valid?=?tf.keras.metrics.Mean()
????????epoch_accuracy_valid?=?tf.keras.metrics.CategoricalAccuracy()
????????i=0
????????for?x,?y?in?dataset:
????????????loss_value,?grads?=?grad_fn(model,?x,?y,?loss)
????????????optimizer.apply_gradients(zip(grads,?model.trainable_variables))
????????????epoch_loss_avg(loss_value)
????????????epoch_accuracy(y,?model(x))
????????????if?i>=train_steps_per_epoch:
????????????????break
????????????i+=1
????????j?=?0
????????for?x,?y?in?valid_dataset:
????????????model_output?=?model(x)
????????????epoch_loss_avg_valid(loss_obj(y,?model_output))??
????????????epoch_accuracy_valid(y,?model_output)
????????????if?j>=train_steps_per_epoch_valid:
????????????????break
????????????j+=1
????????#?End?epoch
????????train_loss_results.append(epoch_loss_avg.result())
????????train_accuracy_results.append(epoch_accuracy.result())
????????train_loss_results_valid.append(epoch_loss_avg_valid.result())
????????train_accuracy_results_valid.append(epoch_accuracy_valid.result())
????????
????????print("Training?->?Epoch?{:03d}:?Loss:?{:.3f},?Accuracy:?{:.3%}".format(epoch,
???????????????????????????????????????????????????????????????????epoch_loss_avg.result(),
???????????????????????????????????????????????????????????????????epoch_accuracy.result()))
????????print("Validation?->?Epoch?{:03d}:?Loss:?{:.3f},?Accuracy:?{:.3%}".format(epoch,
???????????????????????????????????????????????????????????epoch_loss_avg_valid.result(),
???????????????????????????????????????????????????????????epoch_accuracy_valid.result()))
????????print(f'Time?taken?for?1?epoch?{time.time()-start:.2f}?sec\n')
????
????return?train_loss_results,?train_accuracy_results
train_loss_results,?train_accuracy_results?=?train_resnet(resnet_model,?
??????????????????????????????????????????????????????????40,?
??????????????????????????????????????????????????????????train_generator_aug,
??????????????????????????????????????????????????????????validation_generator_aug,
??????????????????????????????????????????????????????????optimizer_obj,?
??????????????????????????????????????????????????????????loss_obj,?
??????????????????????????????????????????????????????????grad)
Training?->?Epoch?000:?Loss:?2.654,?Accuracy:?27.153%
Validation?->?Epoch?000:?Loss:?2.532,?Accuracy:?23.488%
Time?taken?for?1?epoch?137.62?sec
[...]
Training?->?Epoch?039:?Loss:?0.749,?Accuracy:?85.174%
Validation?->?Epoch?039:?Loss:?0.993,?Accuracy:?75.218%
Time?taken?for?1?epoch?137.56?sec
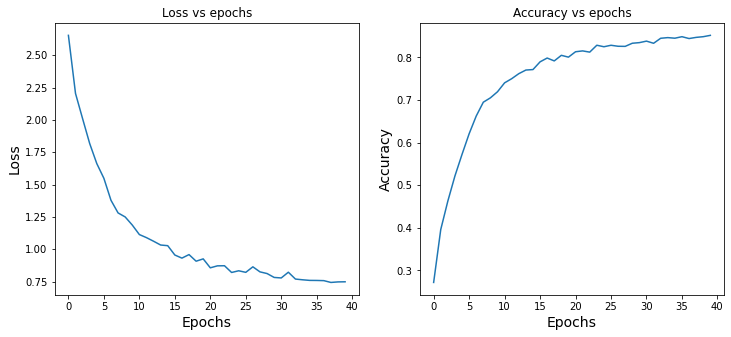
5.結(jié)果
fig,?axes?=?plt.subplots(1,?2,?sharex=True,?figsize=(12,?5))
axes[0].set_xlabel("Epochs",?fontsize=14)
axes[0].set_ylabel("Loss",?fontsize=14)
axes[0].set_title('Loss?vs?epochs')
axes[0].plot(train_loss_results)
axes[1].set_title('Accuracy?vs?epochs')
axes[1].set_ylabel("Accuracy",?fontsize=14)
axes[1].set_xlabel("Epochs",?fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
def?test_model(model,?test_generator):
????epoch_loss_avg?=?tf.keras.metrics.Mean()
????epoch_accuracy?=?tf.keras.metrics.CategoricalAccuracy()
????train_steps_per_epoch?=?test_generator.n?//?test_generator.batch_size
????i?=?0
????for?x,?y?in?test_generator:
????????model_output?=?model(x)
????????epoch_loss_avg(loss_obj(y,?model_output))??
????????epoch_accuracy(y,?model_output)
????????if?i>=train_steps_per_epoch:
????????????break
????????i+=1
????
????print("Test?loss:?{:.3f}".format(epoch_loss_avg.result().numpy()))
????print("Test?accuracy:?{:.3%}".format(epoch_accuracy.result().numpy()))
????
print('ResNet?Model')
test_model(resnet_model,?validation_generator)
print('Benchmark?Model')
test_model(benchmark_model,?validation_generator)
ResNet?Model
Test?loss:?0.787
Test?accuracy:?80.945%
Benchmark?Model
Test?loss:?1.067
Test?accuracy:?75.607%
num_test_images?=?validation_generator.n
random_test_images,?random_test_labels?=?next(validation_generator)
predictions?=?resnet_model(random_test_images)
fig,?axes?=?plt.subplots(4,?2,?figsize=(25,?12))
fig.subplots_adjust(hspace=0.5,?wspace=-0.35)
j=0
for?i,?(prediction,?image,?label)?in?enumerate(zip(predictions,?random_test_images,?target_labels[(tf.argmax(random_test_labels,?axis=1).numpy())])):
????if?j?>3:
????????break
????axes[i,?0].imshow(np.squeeze(image))
????axes[i,?0].get_xaxis().set_visible(False)
????axes[i,?0].get_yaxis().set_visible(False)
????axes[i,?0].text(5.,?-7.,?f'Class?{label}')
????axes[i,?1].bar(np.arange(len(prediction)),?prediction)
????axes[i,?1].set_xticks(np.arange(len(prediction)))
????axes[i,?1].set_xticklabels([l.split('_')[0]?for?l?in?target_labels],?rotation=0)
????pred_inx?=?np.argmax(prediction)
????axes[i,?1].set_title(f"Categorical?distribution.?Model?prediction:?{target_labels[pred_inx]}")
????j+=1
plt.show()

6.結(jié)論
7.參考引用
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群
個(gè)人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR?2020論文 和 CVPR 2021 最新論文

評論
圖片
表情