
什么是FLOPS
FLOPS,是“每秒所執(zhí)行的浮點(diǎn)運(yùn)算次數(shù)”(floating-point operations per second) 的縮寫。它常被用來估算電腦的執(zhí)行效能,尤其是在使用到大量浮點(diǎn)運(yùn)算的科學(xué)計(jì)算領(lǐng)域中。在這里所謂的“浮點(diǎn)運(yùn)算”,實(shí)際上含括了所有涉及小數(shù)的運(yùn)算。這類運(yùn)算在某類應(yīng)用軟件中常常出現(xiàn),而它們也較整數(shù)運(yùn)算花時(shí)間。現(xiàn)今大部分的處理器中,都有一個(gè)專門用來處理浮點(diǎn)運(yùn)算的“浮點(diǎn)單元”(FPU)。也因此 FLOPS 所量測的,實(shí)際上就是 FPU 的執(zhí)行速度。對(duì)于處理器處理浮點(diǎn)運(yùn)算來說,而最常用來測量 FLOPS 的基準(zhǔn)程序 (benchmark) 之一,就是 Linpack。例如:算能公司的“基于SOPHON第三代智算芯片 BM1684”芯片。該款芯片F(xiàn)P32 精度算力也達(dá)到 2.2 TFlops,INT8算力可高達(dá)17.6Tops,在Winograd卷積加速下,INT8算力更提升至35.2 Tops,是一顆低功耗、高性能的SoC芯片。
BM1684還內(nèi)置了張量計(jì)算模塊TPU,該TPU模塊包含64個(gè)NPU運(yùn)算單元,每個(gè)NPU包括16個(gè)EU單元,總共有1024個(gè)EU運(yùn)算單元。
1TFlops=1024GFlowps,即1T=1024G。各種FLOPS的含義:
- 1) 一個(gè)MFLOPS(megaFLOPS)等于每秒1百萬(=10^6)次的浮點(diǎn)運(yùn)算;
- 2) 一個(gè)GFLOPS(gigaFLOPS)等于每秒10億(=10^9)次的浮點(diǎn)運(yùn)算;
- 3) 一個(gè)TFLOPS(teraFLOPS)等于每秒1萬億(=10^12)次的浮點(diǎn)運(yùn)算;
- 4) 一個(gè)PFLOPS(petaFLOPS)等于每秒1千億(=10^15)次的浮點(diǎn)運(yùn)算。
關(guān)于?Linpack
Linpack是國際上使用最廣泛的測試高性能計(jì)算機(jī)系統(tǒng)浮點(diǎn)性能的基準(zhǔn)測試。通過對(duì)高性能計(jì)算機(jī)采用高斯消元法求解一元 N次稠密線性代數(shù)方程組的測試,評(píng)價(jià)高性能計(jì)算機(jī)的浮點(diǎn)計(jì)算性能。Linpack的結(jié)果按每秒浮點(diǎn)運(yùn)算次數(shù)(flops)表示。很多人把用 Linpack基準(zhǔn)測試出的最高性能指標(biāo)作為衡量機(jī)器性能的標(biāo)準(zhǔn)之一。這個(gè)數(shù)字可以作為對(duì)系統(tǒng)峰值性能的一個(gè)修正。通過測試求解不同問題規(guī)模的實(shí)際得分,我們可以得到達(dá)到最佳性能的問題規(guī)模,而這些數(shù)字與理論峰值性能一起列在 TOP500列表中。
Linpack 測試包括三類,Linpack100、Linpack1000和HPL。Linpack100求解規(guī)模為100階的稠密線性代數(shù)方程組,它只允許采用編譯 優(yōu)化選項(xiàng)進(jìn)行優(yōu)化,不得更改代碼,甚至代碼中的注釋也不得修改。Linpack1000要求求解1000階的線性代數(shù)方程組,達(dá)到指定的精度要求,可以在 不改變計(jì)算量的前提下做算法和代碼上做優(yōu)化。HPL即High Performance Linpack,也叫高度并行計(jì)算基準(zhǔn)測試,它對(duì)數(shù)組大小N沒有限制,求解問題的規(guī)模可以改變,除基本算法(計(jì)算量)不可改變外,可以采用其它任何優(yōu)化方 法。前兩種測試運(yùn)行規(guī)模較小,已不是很適合現(xiàn)代計(jì)算機(jī)的發(fā)展。HPL是針對(duì)現(xiàn)代并行計(jì)算機(jī)提出的測試方式。用戶在不修改任意測試程序的基礎(chǔ)上,可 以調(diào)節(jié)問題規(guī)模大小(矩陣大小)、使用CPU數(shù)目、使用各種優(yōu)化方法等等來執(zhí)行該測試程序,以獲取最佳的性能。HPL采用高斯消元法求解線性方程組。求解 問題規(guī)模為N時(shí),浮點(diǎn)運(yùn)算次數(shù)為(2/3 * N^3-2*N^2)。因此,只要給出問題規(guī)模N,測得系統(tǒng)計(jì)算時(shí)間T,峰值=計(jì)算量(2/3 * N^3-2*N^2)/計(jì)算時(shí)間T,測試結(jié)果以浮點(diǎn)運(yùn)算每秒(Flops)給出。HPL測試結(jié)果是TOP500排名的重要依據(jù)。計(jì)算機(jī)計(jì)算峰值簡介:衡量計(jì)算機(jī)性能的一個(gè)重要指標(biāo)就是計(jì)算峰值或者浮點(diǎn)計(jì)算峰值,它是指計(jì)算機(jī)每秒鐘能完成的浮點(diǎn)計(jì)算最大次數(shù)。包括理論浮點(diǎn)峰值和實(shí)測浮點(diǎn)峰值。理論浮點(diǎn)峰值是該計(jì)算機(jī)理論上能達(dá)到的每秒鐘能完成浮點(diǎn) 計(jì)算最大次數(shù),它主要是由 CPU的主頻決定的。計(jì)算公式如下:?、理論浮點(diǎn)峰值=CPU主頻×CPU每個(gè)時(shí)鐘周期執(zhí)行浮點(diǎn)運(yùn)算次數(shù)×CPU數(shù)量。
AI算力評(píng)估為什么不用?Linpack
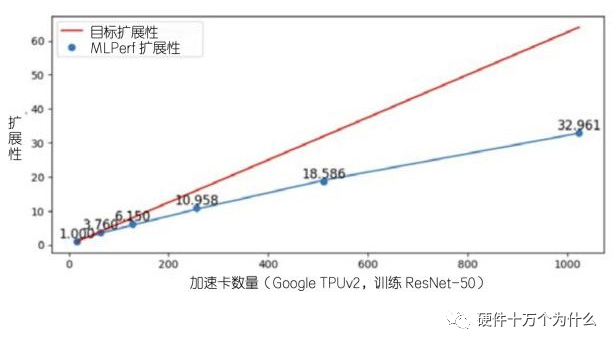
傳統(tǒng)的高性能計(jì)算機(jī)評(píng)測方法和體系與當(dāng)前人工智能需求的性能并不完全一致。例如,LINPACK是一個(gè)目前被廣泛采用的高性能計(jì)算機(jī)雙精度浮點(diǎn)運(yùn)算性能基準(zhǔn)評(píng)測程序,國際超算Top 500榜單依據(jù)LINPACK值來進(jìn)行排名,而典型的人工智能 應(yīng)用并不需要雙精度浮點(diǎn)數(shù)運(yùn)算。大部分人工智能訓(xùn)練任務(wù)以單精度浮點(diǎn)數(shù)或半精度浮點(diǎn)數(shù)為主,推理以Int8為主。對(duì)大規(guī)模人工智能算力來說,制定一個(gè)簡單有效的指標(biāo)和測試方法并不是一件容易的事情。首先,大部分單個(gè)人工智能訓(xùn)練任務(wù)(例如訓(xùn)練一個(gè)推薦系統(tǒng)或者圖像分類的神經(jīng)網(wǎng)絡(luò)模型)達(dá)不到全機(jī)上百張加速器卡規(guī)模的計(jì)算需求。很多人工智能應(yīng)用,即使使用全機(jī)規(guī)模,其訓(xùn)練時(shí)間和準(zhǔn)確率也可能沒有改進(jìn)。其次,如果要測試規(guī)模變化的人工智能集群計(jì)算機(jī),測試程序必須能夠規(guī)模可變。首先必須明確,什么樣的主流人工智能應(yīng)用是規(guī)模可以任意調(diào)整的。最后,準(zhǔn)確率的判定和計(jì)算是大規(guī)模人工智能算力評(píng)測與傳統(tǒng)高性能計(jì)算基準(zhǔn)評(píng)測之間的一個(gè)顯著區(qū)別。是否需要使殘差小于給定標(biāo)準(zhǔn),是否要將準(zhǔn)確度計(jì)入分?jǐn)?shù)統(tǒng)計(jì),同樣是需要明確的問題。目前,各大企業(yè)、高校和相關(guān)組織在人工智能性能基準(zhǔn)測試領(lǐng)域已經(jīng)有了很多探索,相繼開發(fā)了各類基準(zhǔn)評(píng)測程序,比如谷歌等公司主導(dǎo)的MLPerf,小米公司的MobileAI bench,百度公司的DeepBench,中國人工智能產(chǎn)業(yè)發(fā)展聯(lián)盟的AIIA DNN Benchmark,以及在雙精度的LINPACK基礎(chǔ)上改成混合精度的HPL-AI等。但是這些基準(zhǔn)測試方案都不能很好地解決上述問題。根據(jù)MLPerf公開發(fā)表的數(shù)據(jù),MLPerf程序在百張TPU加速卡以上規(guī)模測試下擴(kuò)展性就會(huì)出現(xiàn)下滑,在千張TPU加速卡級(jí)別到達(dá)評(píng)測體系的擴(kuò)展性瓶頸,該評(píng)測程序很難評(píng)價(jià)不同系統(tǒng)在該規(guī)模下人工智能算力的差異。
MLPerf是一套衡量機(jī)器學(xué)習(xí)系統(tǒng)性能的權(quán)威標(biāo)準(zhǔn),于2018年由谷歌、哈佛、斯坦福、百度等機(jī)構(gòu)聯(lián)合發(fā)起成立,每年定期公布榜單成績,它將在標(biāo)準(zhǔn)目標(biāo)下訓(xùn)練或推理機(jī)器學(xué)習(xí)模型的時(shí)間,作為一套系統(tǒng)性能的測量標(biāo)準(zhǔn)。MLPerf訓(xùn)練任務(wù)包括圖像分類(ResNet50)、目標(biāo)物體檢測(SSD)、目標(biāo)物體檢測(Mask R-CNN)、智能推薦(DLRM)、自然語言處理(BERT)以及強(qiáng)化機(jī)器學(xué)習(xí)(Minigo)等。最新的1.0版本增加了兩項(xiàng)新的測試項(xiàng)目:語音識(shí)別(RNN-T)和醫(yī)學(xué)影像分割(U-Net3D)。在Resnet50訓(xùn)練中,硬件及設(shè)備平臺(tái)的選取至關(guān)重要。其中磁盤讀取性能、CPU運(yùn)算性能、內(nèi)存到顯存的傳輸性能以及GPU運(yùn)算性能對(duì)訓(xùn)練速度的影響都比較大:磁盤讀取性能直接決定訓(xùn)練數(shù)據(jù)供給的速度;CPU的性能、CPU到GPU的傳輸帶寬以及GPU的性能共同決定了數(shù)據(jù)前處理的速度;而訓(xùn)練中的前向推理和反向傳播由GPU的性能及GPU之間的數(shù)據(jù)傳輸帶寬決定。如同工廠流水線上的幾名工人,任何一名工人的處理速度跟不上就會(huì)導(dǎo)致堆積,成為性能瓶頸,影響最終結(jié)果。因此這幾個(gè)重要部分不能有明顯的短板。此時(shí)就會(huì)用Resnet50模型進(jìn)行圖片分揀,得出每秒處理圖片數(shù)量作為一個(gè)性能指標(biāo)。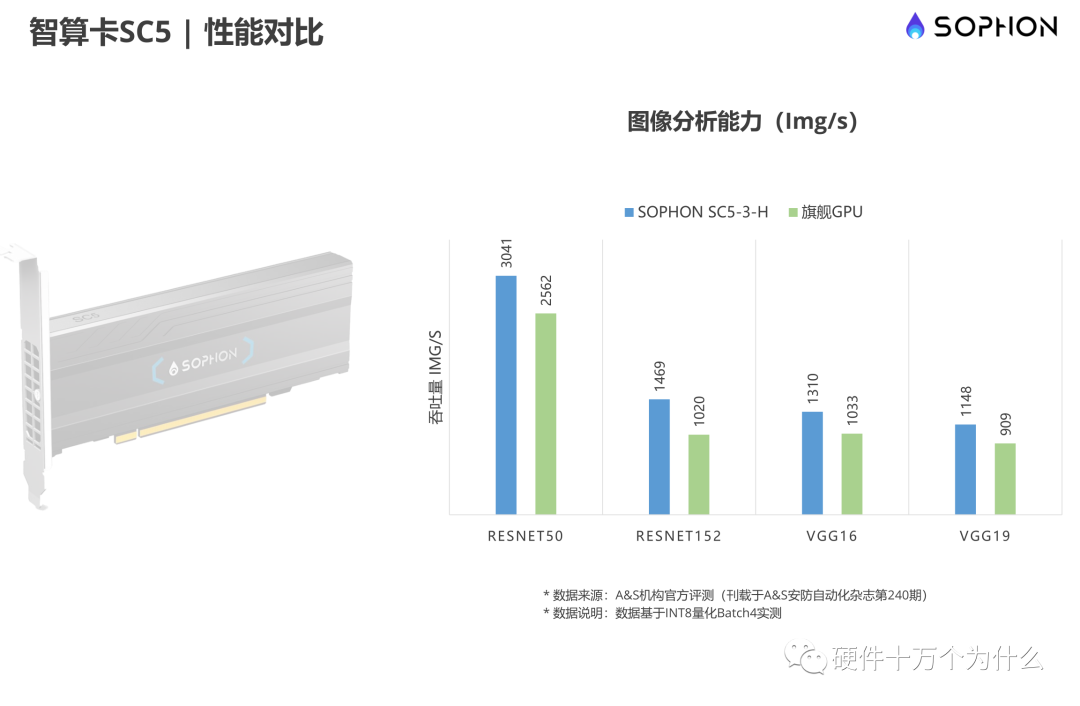
經(jīng)典芯片的算力
以下列出幾個(gè)有代表性硬件的每秒浮點(diǎn)運(yùn)算次數(shù)GFLOPS
Intel Xeon 3.6 GHz: <1.8 GFLOPS
Intel Pentium 4 HT 3.6Ghz: 7 GFLOPS
Intel Core 2 Duo E4300 14 GFLOPS
Intel Core 2 Duo E8400 24 GFLOPS
AMD Phenom 9950: 29.05 GFLOPS
Intel Core 2 Quad Q8200: 37 GFLOPS
Intel Core 2 QX9770: 39.63 GFLOPS
AMD Phenom II x4 955: 42.13 GFlopS
Intel Core i7-965: 69.23 GFLOPS
Intel Core i7-980 XE : 107.6 GFLOPS
Intel Core i5-2500K @4.5GHz: 123.35 GFLOPS (w/AVX instruction set)
IBM POWER7: 264.96GFLOPS[2]
nVIDIA Geforce 8800 Ultra(G80-450 GPU):393.6 GFLOPS
nVIDIA Geforce GTX 280(G200-300 GPU):720 GFLOPS
AMD Radeon HD 3870(RV670 GPU):497 GFLOPS
AMD Radeon HD 4870(RV770 GPU):1008 GFlops
TFLOPS
nVIDIA Geforce GTX 580(GF110-375 GPU):2.37 TFLOPS
AMD Radeon HD 6990(R900 GPU):4.98 TFLOPS
nVIDA Geforce GTX 1070: 6.5 TFLOPS
nVIDA Geforce GTX 1080: 9 TFLOPS
nVIDA Geforce GTX 1080Ti: 10.8 TFLOPS
nIVIDIA Titan Xp : 12.1 TFLOPS
ASCI White:12.3TFLOPS
AMD Vega Frontier Edition : 13.1 TFLOPS
Earth Simulator: 35.61 TFLOPS
Blue Gene/L: 135.5 TFLOPS
中國曙光Dawning 5000A: 230 TFLOPS
PFLOPS
IBM Roadrunner:1.026 PFLOPS
Jaguar:1.75 PFLOPS
天河一號(hào):2.566 PFLOPS
Folding@home運(yùn)算平臺(tái):4.769 PFLOPS
BOINC運(yùn)算平臺(tái):6.282 PFLOPS (持續(xù)增加中)
IBM Mira: 8.16 PFLOPS
京:10.51 PFLOPS
IBM Sequoia:16.32 PFLOPS
Cray Titan:17.59 PFLOPS
天河二號(hào):33.86PFLOPS
神威·太湖之光:125PFLOPS
參考“2020年HPC市場總結(jié)和預(yù)測報(bào)告(附下載)”,2020年HPC市場總結(jié)和預(yù)測報(bào)告。美國在3大超算系統(tǒng)(Aurora、Frontier和EI Capitan)近兩年投入預(yù)算均超過18億美元。
Aurora:英特爾推遲推出7納米的Ponte Vecchio GPU,計(jì)劃在Aurora與英特爾Xeon CUP集成,算力>1EF。
Focus on Frontier (CORAL-2):美國第一個(gè)Exascale System (由于Aurora延期),第二代AI系統(tǒng);
日本Fugaku超算系統(tǒng)在2020年6月TOP500榜單中位居榜首。基于Fujitsu A64 ARMv8.2處理器,無GPU加速,Linpack (HPL)?測試基準(zhǔn)達(dá) 415.5 petaflops。
中國三個(gè)超算原型機(jī)(NUDT、Sugon和Sunway)在開發(fā)中,其中一個(gè)或多個(gè)原型可能被選擇為充分生產(chǎn)。
歐洲EuroHPC項(xiàng)目于2018年啟動(dòng),歐盟32個(gè)參與國開發(fā)歐盟范圍內(nèi)高性能計(jì)算系統(tǒng),選擇芬蘭卡賈尼,西班牙巴塞羅那和意大利博洛尼亞,投資6.5億歐元實(shí)施150,200Pflops系統(tǒng),投資1.8億歐元建設(shè)中規(guī)模HPC系統(tǒng)(~4Pflops)
此外,在2022-2023將從采購3個(gè)大型系統(tǒng),至少有一個(gè)采用歐盟技術(shù)(特別是使用EPI處理器);大約在2027年部署首個(gè)混合高性能計(jì)算/量子基礎(chǔ)設(shè)施(Post Exascale System)。
更多內(nèi)容參考2021 HPC China大會(huì)因特爾方案資料(下)和2021 HPC China大會(huì)因特爾方案資料(上)
2020年HPC市場總結(jié)和預(yù)測報(bào)告
轉(zhuǎn)載申明:轉(zhuǎn)載本號(hào)文章請(qǐng)注明作者和來源,本號(hào)發(fā)布文章若存在版權(quán)等問題,請(qǐng)留言聯(lián)系處理,謝謝。
推薦閱讀
更多架構(gòu)相關(guān)技術(shù)知識(shí)總結(jié)請(qǐng)參考“架構(gòu)師全店鋪技術(shù)資料打包”相關(guān)電子書(37本技術(shù)資料打包匯總詳情可通過“閱讀原文”獲取)。
全店內(nèi)容持續(xù)更新,現(xiàn)下單“全店鋪技術(shù)資料打包(全)”,后續(xù)可享全店內(nèi)容更新“免費(fèi)”贈(zèng)閱,價(jià)格僅收198元(原總價(jià)350元)。
溫馨提示:
掃描二維碼關(guān)注公眾號(hào),點(diǎn)擊閱讀原文鏈接獲取“架構(gòu)師技術(shù)全店資料打包匯總(全)”電子書資料詳情。




