
貝葉斯深度學(xué)習(xí)最新研究總結(jié)
導(dǎo)讀
?本篇文章主要概括了關(guān)于貝葉斯深度學(xué)習(xí)最新研究(2020)的survey:A Survey on Bayesian Deep Learning。內(nèi)容包括貝葉斯深度學(xué)習(xí)的基本介紹以及其在推薦系統(tǒng),話題模型,控制等領(lǐng)域的應(yīng)用。?
一個(gè)綜合的人工智能系統(tǒng)應(yīng)該不止能“感知”環(huán)境,還要能“推斷”關(guān)系及其不確定性。深度學(xué)習(xí)在各類感知的任務(wù)中表現(xiàn)很不錯(cuò),如圖像識別,語音識別。然而概率圖模型更適用于inference的工作。這篇survey提供了貝葉斯深度學(xué)習(xí)(Bayesian Deep Learning, BDL)的基本介紹以及其在推薦系統(tǒng),話題模型,控制等領(lǐng)域的應(yīng)用。
本文的目錄如下:
1 Introduction
2 Deep Learning
2.2 AutoEncoders 3 Probabilistic Graphical Models
4 Bayesian Deep Learning
4.1 A Brief History of Bayesian Neural Networks and Bayesian Deep Learning 4.2 General Framework 4.3 Perception Component 4.4 Task-Specific Component 5 Concrete BDL Models and Applications
5.1 Supervised Bayesian Deep Learning for Recommender Systems 5.2 Unsupervised Bayesian Deep Learning for Topic Models 5.3 Bayesian Deep Representation Learning for Control 5.4 Bayesian Deep Learning for Other Applications 6 Conclusions and Future Research
1 Introduction
基于深度學(xué)習(xí)的人工智能模型往往精于 “感知” 的任務(wù),然而光有感知是不夠的,“推理” 是更高階人工智能的重要組成部分。比方說醫(yī)生診斷,除了需要通過圖像和音頻等感知病人的癥狀,還應(yīng)該能夠推斷癥狀與表征的關(guān)系,推斷各種病癥的概率,也就是說,需要有“thinking”的這種能力。具體而言就是識別條件依賴關(guān)系、因果推斷、邏輯推理、處理不確定性等。
概率圖模型(PGM)能夠很好處理概率性推理問題,然而PGM的弊端在于難以應(yīng)付大規(guī)模高維數(shù)據(jù),比如圖像,文本等。因此,這篇文章嘗試將二者結(jié)合,融合到DBL的框架之中。
比如說在電影推薦系統(tǒng)中,深度學(xué)習(xí)適于處理高維數(shù)據(jù),比如影評(文本)或者海報(bào)(圖像);而概率圖模型適于對條件依賴關(guān)系建模,比如觀眾和電影之間的網(wǎng)絡(luò)關(guān)系。
從uncertainty的角度考慮,BDL適合于去處理這樣的復(fù)雜任務(wù)。復(fù)雜任務(wù)的參數(shù)不確定性一般有如下幾種:(1)神經(jīng)網(wǎng)絡(luò)的參數(shù)不確定性;(2)與任務(wù)相關(guān)的參數(shù)不確定性;(3)perception部分和task-specific部分信息傳遞的不確定性。通過將未知參數(shù)用概率分布而不是點(diǎn)估計(jì)的方式表示,能夠很方便地將這三種uncertainty統(tǒng)一起來處理(這就是BDL框架想要做的事情)。
另外BDL還有 “隱式的”正則化作用,在數(shù)據(jù)缺少的時(shí)候能夠避免過擬合。通常BDL由兩部分組成:perception模塊和task-specific模塊。前者可以通過權(quán)值衰減或者dropout正則化(這些方法擁有貝葉斯解釋),后者由于可以加入先驗(yàn),在數(shù)據(jù)缺少時(shí)也能較好地進(jìn)行建模。
當(dāng)然,BDL在實(shí)際應(yīng)用中也存在著挑戰(zhàn),比如時(shí)間復(fù)雜性的問題,以及兩個(gè)模塊間信息傳遞的有效性。
2 Deep Learning
這一章主要介紹經(jīng)典的深度學(xué)習(xí)方法,這里不用過多的篇幅去敘述,文章中提到的方法包括MLP、AutoEncoder、CNN、RNN等。
2.2 AutoEncoders
這一部分提一下自編碼器。這是一種能將輸入編碼為更緊湊表示的神經(jīng)網(wǎng)絡(luò),同時(shí)能夠?qū)⑦@種緊湊表示進(jìn)行重建。這方面的資料也很多,這里主要說明一下AE的變種——SDAE(Stacked Denoising AutoEncoders)
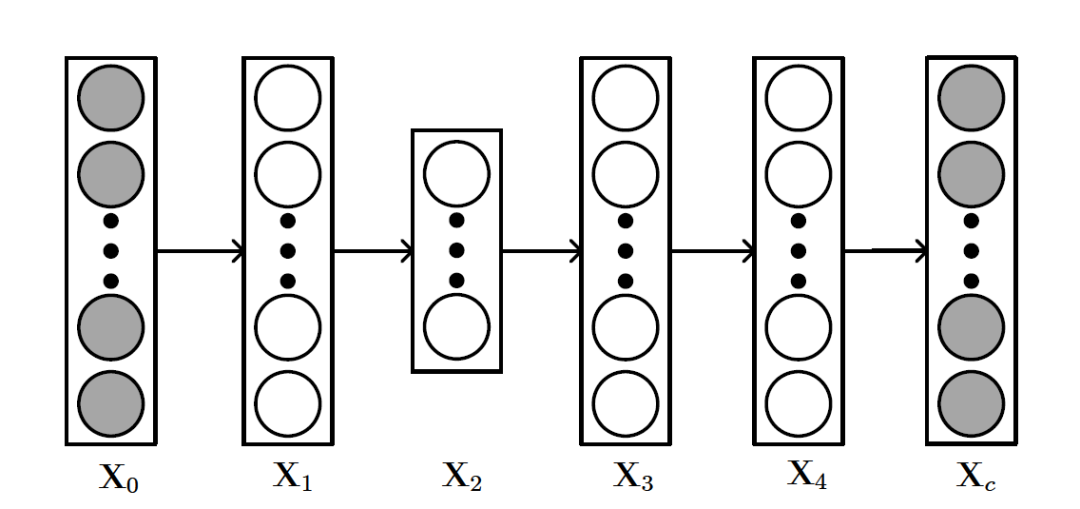
SDAE的結(jié)構(gòu)如上圖所示,和AE不同的是, 可以看做輸入數(shù)據(jù)
可以看做輸入數(shù)據(jù) 加入噪聲或者做了一些隨機(jī)處理后的結(jié)果(比如可以把中的數(shù)據(jù)隨機(jī)選30%變?yōu)榱悖K許DAE做的就是試圖把處理過的corrupted data恢復(fù)成clean data。SDAE可以轉(zhuǎn)化為如下優(yōu)化問題:
加入噪聲或者做了一些隨機(jī)處理后的結(jié)果(比如可以把中的數(shù)據(jù)隨機(jī)選30%變?yōu)榱悖K許DAE做的就是試圖把處理過的corrupted data恢復(fù)成clean data。SDAE可以轉(zhuǎn)化為如下優(yōu)化問題:
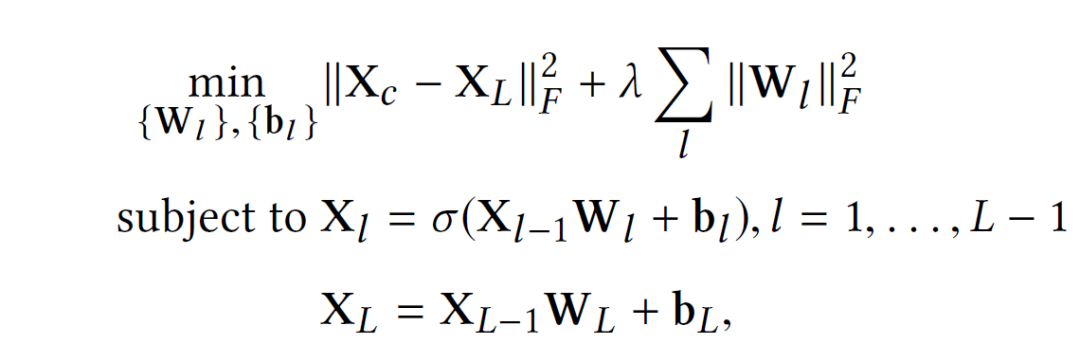
3 Probabilistic Graphical Model
這一章主要介紹概率圖模型,也是為后面的內(nèi)容做知識鋪墊的,概率圖模型的相關(guān)資料有不少,因此這里不過多敘述。文章主要介紹的是有向貝葉斯網(wǎng)(Bayesian Networks),如LDA等模型。LDA可以拓展出更多的topic model,如推薦系統(tǒng)中的協(xié)同話題回歸(CTR)。
4 Bayesian Deep Learning
在這個(gè)部分,作者列舉了一些BDL模型在推薦、控制等領(lǐng)域的應(yīng)用,我們可以看到,眾多當(dāng)前實(shí)用的模型都可以統(tǒng)一到BDL這個(gè)大框架之下:
4.1 A Brief History of Bayesian Neural Networks and Bayesian Deep Learning
和BDL很相似的是BNN(Bayesian neural networks),這是一個(gè)相當(dāng)古老的課題,然而BNN只是本文BDL框架下的一個(gè)子集——BNN相當(dāng)于只有perception部分的BDL。
4.2 General Framework
如下圖是文章提出的基本框架,紅色部分是感知模塊,藍(lán)色部分是任務(wù)模塊。紅色部分通常使用各種概率式的神經(jīng)網(wǎng)絡(luò)模型,而藍(lán)色部分可以是貝葉斯網(wǎng)絡(luò),DBN,甚至是隨機(jī)過程,這些模型會以概率圖的形式表示出來。
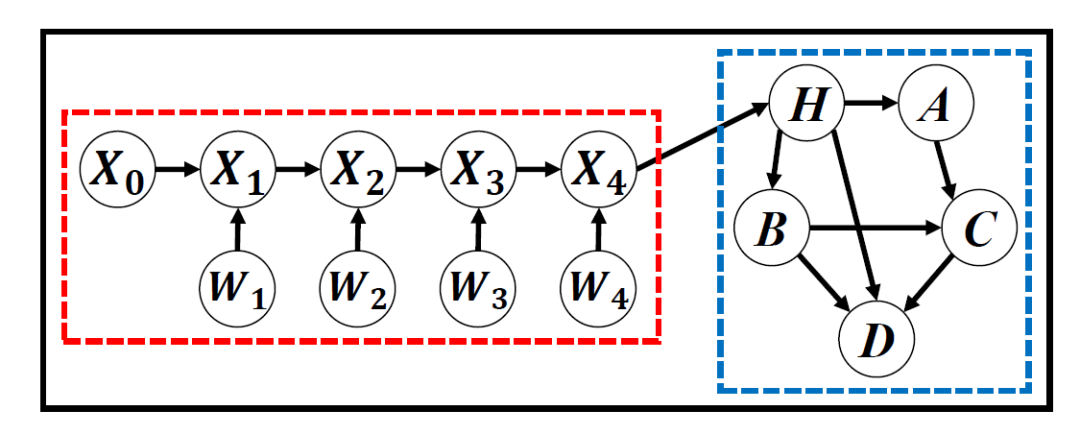
在這個(gè)基本框架中往往有三種變量:perception variables? (圖中的X,W),?hinge variables?
(圖中的X,W),?hinge variables? (圖中的H)和task variables?
(圖中的H)和task variables? (圖中的A,B,C)。通常來說,紅色模塊和hinge variables之間的連接是獨(dú)立的。因此,對于能歸納到BDL框架下的模型,我們都可以找到這樣的結(jié)構(gòu)——兩個(gè)模塊,三種變量。
(圖中的A,B,C)。通常來說,紅色模塊和hinge variables之間的連接是獨(dú)立的。因此,對于能歸納到BDL框架下的模型,我們都可以找到這樣的結(jié)構(gòu)——兩個(gè)模塊,三種變量。
BDL可以對紅藍(lán)兩個(gè)部分之間信息交換的uncertainty進(jìn)行建模,這個(gè)問題等價(jià)研究的uncertainty(在公式中的體現(xiàn)就是條件方差)。方差的不同假設(shè)有:Zero-Variance(ZV,沒有不確定性,方差為零),Hyper-Variance(HV,方差大小由超參數(shù)決定),Learnable Variance(LV,使用可學(xué)習(xí)參數(shù)表示)。顯然,靈活性上有LV>HV>ZV。
4.3 Perception Component
通常來說,這一部分應(yīng)該采用BNN等模型,當(dāng)然我們可以使用一些更加靈活的模型,比如RBM,VAE,以及近來比較火的GAN等。文章提到了以下幾個(gè)例子:
Restricted Boltzman Machine:RBM是一種特殊的BNN,主要特點(diǎn)有:(1)訓(xùn)練時(shí)不需要反向傳播的過程;(2)隱神經(jīng)元是binary的。RBM的具體結(jié)構(gòu)如下:
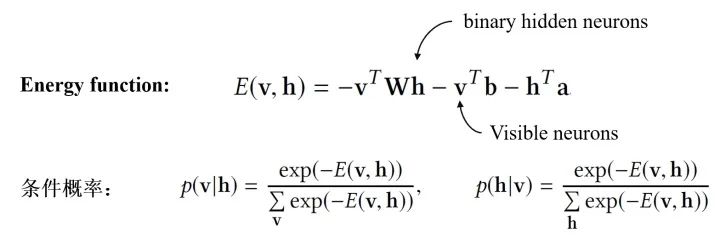
RBM通過Contrastive Divergence進(jìn)行訓(xùn)練(而不是反向傳播),訓(xùn)練結(jié)束后通過邊緣化其他neurons就能求出
 和
和 。和corrupted input?都是可以觀察的,便可以定義如下的Probabilistic SDAE:
。和corrupted input?都是可以觀察的,便可以定義如下的Probabilistic SDAE:
Variational Autoencoders:VAE的基本想法就是通過學(xué)習(xí)參數(shù)最大化ELBO,VAE也有諸多變種,比如IWAE(Importance weighted Autoencoders),Variational RNN等。
Natural-Parameter Networks:與確定性輸入的vanilla NN不同,NPN將一個(gè)分布作為輸入(和VAE只有中間層的output是分布不同)。當(dāng)然除了高斯分布,其他指數(shù)族也可也當(dāng)做NPN的輸入,如Gamma、泊松等。
4.4 Task-Specific Component
這一個(gè)模塊的主要目的是將概率先驗(yàn)融合進(jìn)BDL模型中(很自然的我們可以用PGM來表示),這個(gè)模塊可以是Bayesian Network,雙向推斷網(wǎng)絡(luò),甚至是隨機(jī)過程。
Bayesian Networks:貝葉斯網(wǎng)是最常見的task-specific component。除了LDA,另一個(gè)例子是PMF(Probabilistic Matrix Factorization),原理是使用BN去對users,items和評分的條件依賴性建模。以下是PMF假設(shè)的生成過程:

Bidirectional Inference Networks:Deep Bayesian Network不止關(guān)注“淺相關(guān)”和線性結(jié)構(gòu),還會關(guān)注隨機(jī)變量的非線性相關(guān)和模型的非線性結(jié)構(gòu)。BIN是其中的一個(gè)例子。
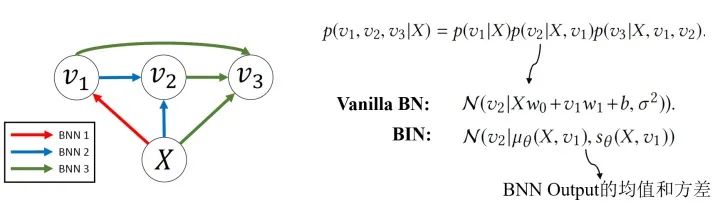
Stochastic Processes:隨機(jī)過程也可以作為Task-component,比如說用維納過程模擬離散布朗運(yùn)動(dòng),用泊松過程模擬處理語音識別的任務(wù)等。隨機(jī)過程可以被看做一種動(dòng)態(tài)貝葉斯網(wǎng)(DBN)。
5 Concerte BDL Models and Applications
上一章討論完構(gòu)成BDL的基本模型結(jié)構(gòu),我們自然希望能夠把這一套大一統(tǒng)的框架運(yùn)用在一些實(shí)際的問題上。因此,這一章主要討論了BDL的各種應(yīng)用場景,包括推薦系統(tǒng),控制問題等。在這里我們默認(rèn)任務(wù)模塊使用vanilla Bayesian networks作為這個(gè)部分的模型。
5.1 Supervised Bayesian Deep Learning for Recommender Systems
Collaborative Deep Learning。文章在這個(gè)部分提出Collaborative Deep Learning(CDL)來處理推薦系統(tǒng)的問題,這種方法連接了content information(一般使用深度學(xué)習(xí)方法處理)和rating matrix(一般使用協(xié)同過濾)。
使用4.3.2提到的Probabilistic SDAE,CDL模型的生成過程如下:

為了效率,我們可以設(shè)置趨向正無窮,這個(gè)時(shí)候,CDL的圖模型就可以用下圖來表示了:
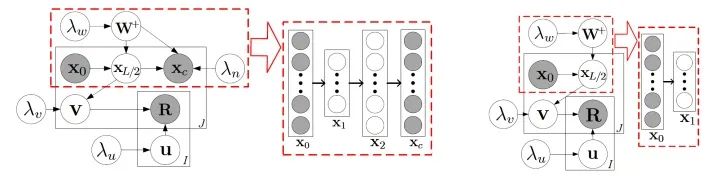
紅色虛線框中的就是SDAE(圖上是L=2的情況),右邊是degenerated CDL,我們可以看到,degenerated CDL只有SDAE的encoder部分。根據(jù)我們之前定義過的, 就是hinge variable,而
就是hinge variable,而 是task variables,其他的是perception variables。
是task variables,其他的是perception variables。
那么我們應(yīng)該如何訓(xùn)練這個(gè)模型呢?直觀來看,由于現(xiàn)在所有參數(shù)都被我們當(dāng)做隨機(jī)變量,我們可以使用純貝葉斯方法,比如VI或MCMC,然而這樣計(jì)算量往往是巨大的,因此,我們使用一個(gè)EM-style的算法去獲得MAP估計(jì)。先定義需要優(yōu)化的目標(biāo),我們希望最大化后驗(yàn)概率,可以等價(jià)為最大化給定 的joint log-likelihood。
的joint log-likelihood。
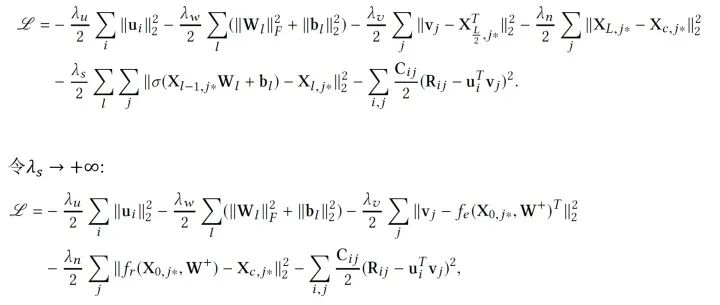
注意,當(dāng) 趨向無窮時(shí),訓(xùn)練CDL的概率圖模型就退化為了訓(xùn)練下圖的神經(jīng)網(wǎng)絡(luò)模型:兩個(gè)網(wǎng)絡(luò)有相同的加了噪音的輸入,而輸出是不同的。
趨向無窮時(shí),訓(xùn)練CDL的概率圖模型就退化為了訓(xùn)練下圖的神經(jīng)網(wǎng)絡(luò)模型:兩個(gè)網(wǎng)絡(luò)有相同的加了噪音的輸入,而輸出是不同的。
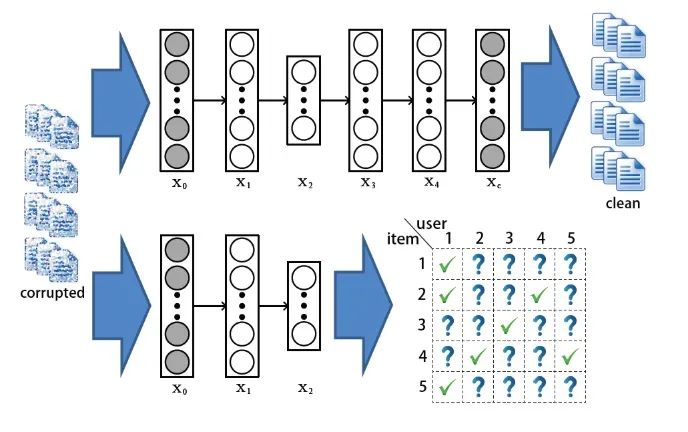
有了優(yōu)化的目標(biāo),參數(shù)該如何去更新呢?和巧妙的EM算法的思路類似,我們通過迭代的方法去逐步找到一個(gè)局部最優(yōu)解:
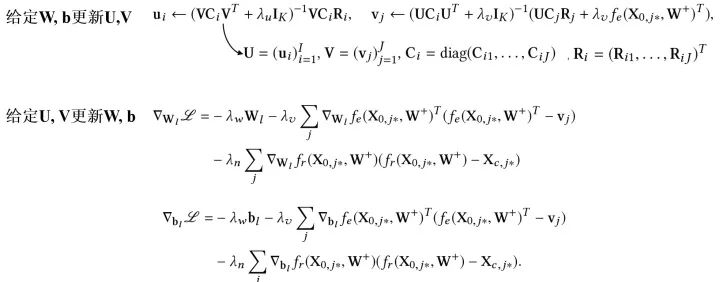
當(dāng)我們估計(jì)好參數(shù),預(yù)測新的評分就容易了,我們只需要求期望即可,也就是根據(jù)如下公式計(jì)算:
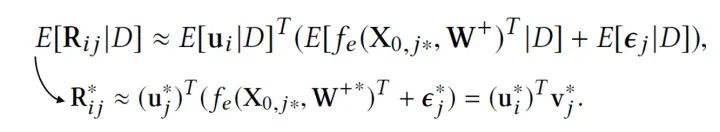
Bayesian Collaborative Deep Learning:除了這種模型,我們可以對上面提到的CDL進(jìn)行另外一種擴(kuò)展。這里我們不用MAP估計(jì),而是sampling-based算法。主要過程如下:

當(dāng)趨向正無窮并使用adaptive rejection Metropolis sampling時(shí),對 采樣就相當(dāng)于BP的貝葉斯泛化版本。
采樣就相當(dāng)于BP的貝葉斯泛化版本。
Marginalized Collaborative Deep Learning:在SDAE的訓(xùn)練中,不同訓(xùn)練的epoch使用不同的corrupted input,因此訓(xùn)練過程中需要遍歷所有的epochs,Marginalized SDAE做出了改進(jìn):通過邊緣化corrupted input直接得到閉式解。
Collaborative Deep Ranking:除了關(guān)注精確的評分,我們也可以直接關(guān)注items的排名,比如CDR算法:

這個(gè)時(shí)候我們需要優(yōu)化的log-likelihood就會成為:
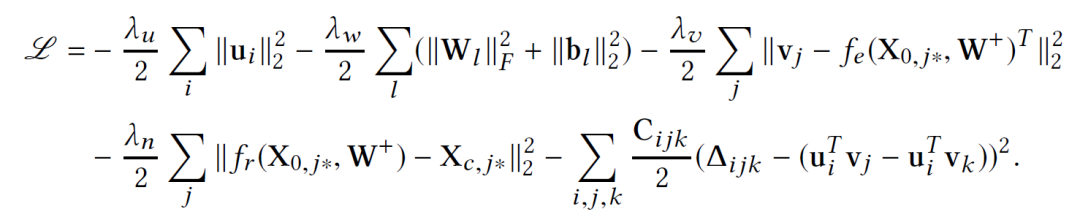
Collaborative Variational Autoencoders:另外,我們可以將感知模塊的Probabilistic SDAE換成VAE,則生成過程如下:

總之,推薦系統(tǒng)問題往往涉及高維數(shù)據(jù)(文本、圖像)處理以及條件關(guān)系推斷(用戶物品關(guān)系等),CDL這類模型使用BDL的框架,能發(fā)揮很重要的作用。當(dāng)然其他監(jiān)督學(xué)習(xí)的任務(wù)也可以參考推薦系統(tǒng)的應(yīng)用使用CDL的方法。
5.2 Unsupervised Bayesian Deep Learning for Topic Models
這一小節(jié)過渡到非監(jiān)督問題中,在這類問題中我們不再追求 “match” 我們的目標(biāo),而更多是 “describe” 我們的研究對象。
Relational Stacked Denoising Autoencoders as Topic Models (RSDAE):在RSDAE中我們希望能在關(guān)系圖的限制下學(xué)到一組topics(或者叫潛因子)。RSDAE能“原生地”集成潛在因素的層次結(jié)構(gòu)和可用的關(guān)系信息。其圖模型的形式和生成過程如下:
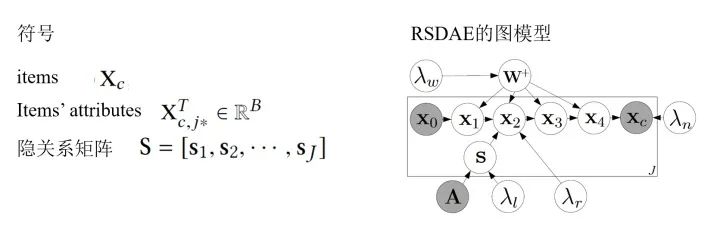

同樣的,我們最大化后驗(yàn)概率,也就是最大化各種參數(shù)的joint log-likelihood:
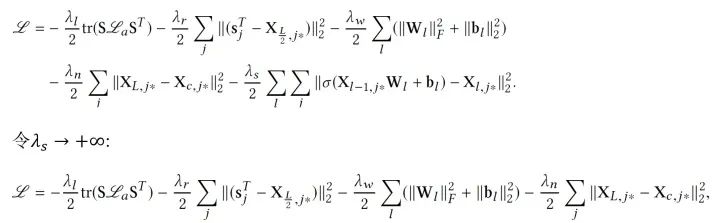
訓(xùn)練的時(shí)候我們依然使用EM-style的算法去找MAP估計(jì),并求得一個(gè)局部最優(yōu)解(當(dāng)然也可以使用一些帶skip的方法嘗試跳出局部最優(yōu)),具體如下:

Deep Poisson Factor Analysis with Sigmoid Belief Networks:泊松過程適合對于非負(fù)計(jì)數(shù)相關(guān)的過程建模,考慮到這個(gè)特性,我們可以嘗試把Poisson factor analysis(PFA)用于非負(fù)矩陣分解。這里我們以文本中的topic問題作為例子,通過取不同的先驗(yàn)我們可以有多種不同的模型。
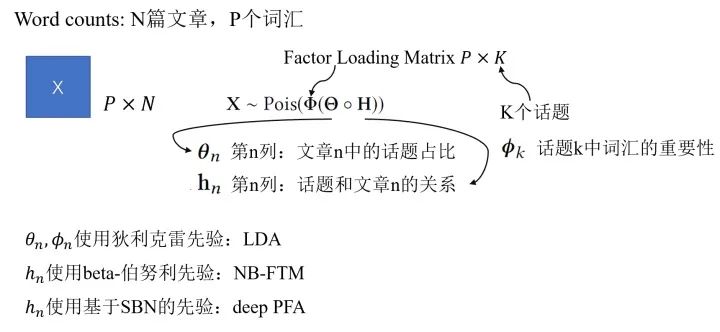
比如說,我們可以通過采用基于sigmoid belief networks(SBN)的深度先驗(yàn),構(gòu)成DeepPFA模型。DeepPFA的生成過程具體如下:

這個(gè)模型訓(xùn)練的方式是用Bayesian Conditional Density Filtering(BCDF),這是MCMC的一種online版本;也可以使用Stochastic Gradient Thermostats(SGT),屬于hybrid Monto Carlo類的采樣方法。
Deep Poisson Factor Analysis with Restricted Boltzmann Machine:我們也可以將DeepPFA中的SBN換成RBM模型達(dá)到相似的效果。
可以看到,在基于BDL的話題模型中,感知模塊用于推斷文本的topic hierarchy,而任務(wù)模塊用于對詞匯與話題的生產(chǎn)過程,詞匯-話題關(guān)系,文本內(nèi)在關(guān)系建模。
5.3 Bayesian Deep Representation Learning for Control
前面兩小節(jié)主要談?wù)揃DL在監(jiān)督學(xué)習(xí)與無監(jiān)督學(xué)習(xí)的應(yīng)用,這一節(jié)主要關(guān)注另外一個(gè)領(lǐng)域:representation learning。用控制問題為例。
Stochastic Optimal Control:在這一節(jié),我們考慮一個(gè)未知?jiǎng)討B(tài)系統(tǒng)的隨機(jī)最優(yōu)控制問題,在BDL的框架下解決的具體過程如下:

BDL-Based Representation Learning for Control:為了能夠優(yōu)化上述問題,有三個(gè)關(guān)鍵的部分,具體如下:
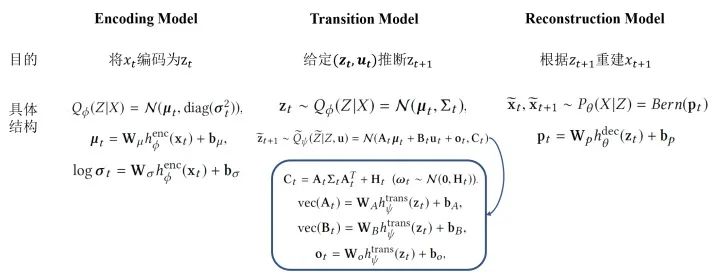
Learning Using Stochastic Gradient Variational Bayes:該模型的損失函數(shù)是如下這種形式:
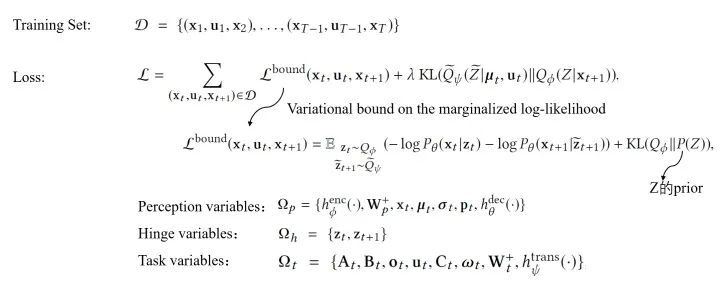
在控制的問題中,我們通常希望能夠從原始輸入中獲取語義信息,并在系統(tǒng)狀態(tài)空間中保持局部線性。而BDL的框架正好適用這一點(diǎn),兩個(gè)組件分別能完成不同的工作:感知模塊可以捕獲 live video,而任務(wù)模塊可以推斷動(dòng)態(tài)系統(tǒng)的狀態(tài)。
5.4 Bayesian Deep Learning for Other Applications
除了上面提到的,BDL還有其他諸多運(yùn)用場景:鏈路預(yù)測、自然語言處理、計(jì)算機(jī)視覺、語音、時(shí)間序列預(yù)測等。比如,在鏈路預(yù)測中,可以將GCN作為感知模塊,將stochastic blockmodel作為任務(wù)處理模塊等。
6 Conclusion and Future Research
現(xiàn)實(shí)中很多任務(wù)都會涉及兩個(gè)方面:感知高維數(shù)據(jù)(圖像、信號等)和隨機(jī)變量的概率推斷。BDL正是應(yīng)對這種問題的方案:結(jié)合了NN和PGM的長處。而廣泛的應(yīng)用使得BDL能夠成為非常有價(jià)值的研究對象,目前這類模型仍然有著眾多可以挖掘的地方。
往期精彩:
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語義分割理論與實(shí)戰(zhàn)指南.pdf