
【內(nèi)含答案】AIGC-大模型產(chǎn)品經(jīng)理高頻面試32題大揭秘?(4/6)

這是求職產(chǎn)品經(jīng)理系列的第 229 篇文章
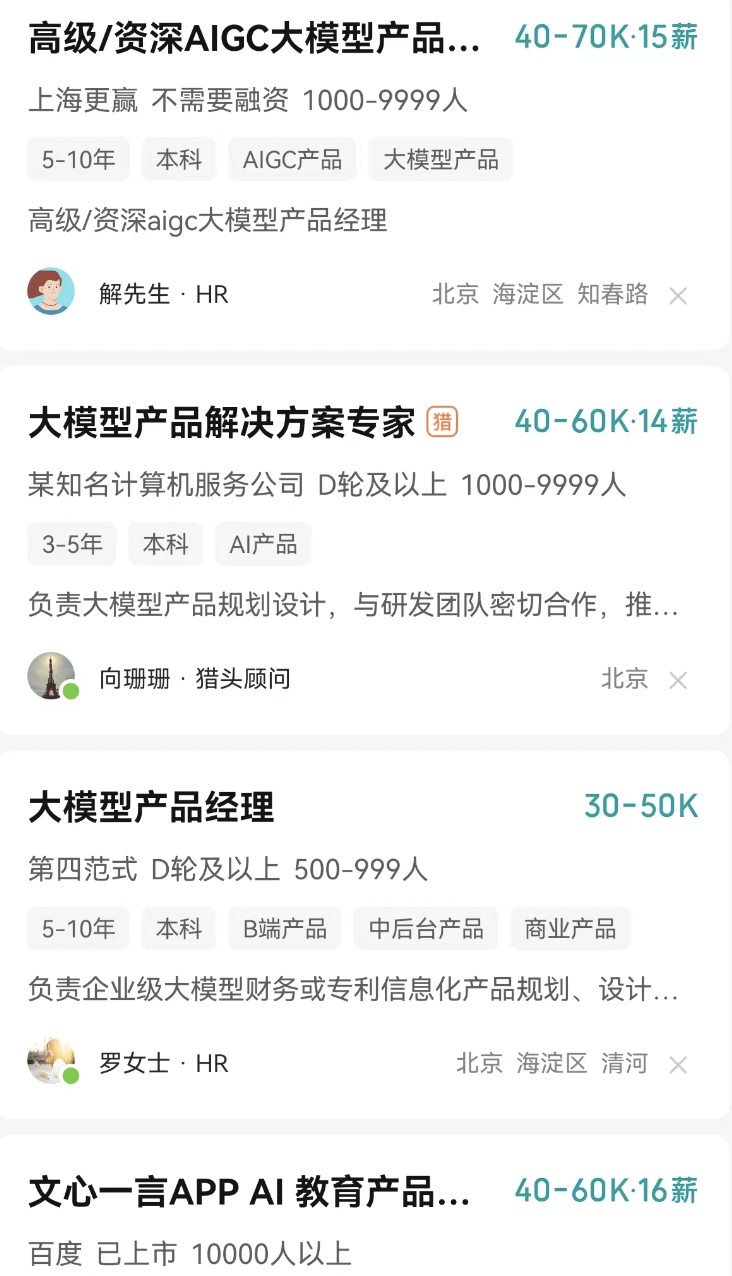
近期有十幾個學(xué)生在面試大模型產(chǎn)品經(jīng)理(薪資還可以,詳情見下圖),根據(jù)他們面試(包括1-4面)中出現(xiàn)高頻大于3次的問題匯總?cè)缦拢?strong>一共32道題目(有答案)。
20.什么是模型的推理能力?
模型的推理能力是指模型能夠根據(jù)給定的輸入或查詢,利用其內(nèi)部的知識和邏輯,生成合理和正確的輸出或回答的能力。
模型的推理能力可以反映模型的智能水平和泛化能力,也可以影響模型在不同的任務(wù)和領(lǐng)域中的表現(xiàn)。
簡單地說,模型的推理能力是指模型根據(jù)給定的信息(例如問題和答案)進(jìn)行邏輯思考和判斷的能力,以生成正確和相關(guān)的輸出。
模型的推理能力可以分為不同的類型,例如:
1)基于規(guī)則的推理 ,即模型根據(jù)一些明確的規(guī)則或公式,進(jìn)行符號操作或數(shù)學(xué)計算,得到確定的結(jié)果。 例如,模型可以根據(jù)數(shù)學(xué)公式解決一些數(shù)學(xué)應(yīng)用題。 2)基于概率的推理 ,即模型根據(jù)一些不確定的因素或假設(shè),進(jìn)行概率估計或統(tǒng)計分析,得到最可能的結(jié)果。 例如,模型可以根據(jù)貝葉斯定理進(jìn)行貝葉斯推斷。 3)基于語義的推理 ,即模型根據(jù)一些語言或文本的含義和關(guān)系,進(jìn)行語義分析或語義解釋,得到符合語境的結(jié)果。 例如,模型可以根據(jù)詞義關(guān)系進(jìn)行詞法消歧或詞法推理。 4) 基于常識的推理 ,即模型根據(jù)一些通用的知識或事實(shí),進(jìn)行常識判斷或常識解釋,得到符合常理的結(jié)果。 例如,模型可以根據(jù)物理規(guī)律進(jìn)行物理推理或物理解釋。21.LtM提示策略是如何分階段進(jìn)行的
LtM提示策略是一種利用最少到最多的提示序列,來讓大語言模型逐步增加推理難度和深度的方法。
它可以讓模型更有效地利用其通用知識和涌現(xiàn)能力,同時避免過擬合或?yàn)?zāi)難性遺忘。
LtM提示策略是由以下兩個階段組成的:
第一個階段:是自上而下的分解問題(Decompose Question into subquestion);
第二個階段:是自下而上的依次解決問題(Sequentially Solve Subquestion),整個依次回答問題的過程,其實(shí)就可以看成是CoT的過程,只不過LtM會要求模型根據(jù)每個不同的問題,單獨(dú)生成解決問題的鏈路,從而能夠更加精準(zhǔn)的解決復(fù)雜推理問題。
而整個過程問題的由少變多,則是LEAST-TO-MOST一詞的來源,具體來說:
第一階段是將問題分解為子問題,即根據(jù)問題的復(fù)雜性和模型的能力,將問題拆分成若干個更簡單或更具體的子問題,這些子問題可以建立在彼此之上,也可以相互獨(dú)立。
例如,如果要求模型解決一個數(shù) 學(xué)應(yīng)用題,可以將其分解為以下子問題:
- 識別題目中的已知條件和未知量
- 選擇合適的數(shù)學(xué)公式或方法
- 將已知條件代入公式或方法
- 計算或化簡得到結(jié)果
第二階段是逐個解決子問題,即根據(jù)第一階段得到的子問題序列,依次給模型提供相應(yīng)的提示,讓模型生成每個子問題的答案。
這些答案可以作為下一個子問題的輸入或條件,也可以直接作為最終答案。
例如,如果要求模型解決上述數(shù)學(xué)應(yīng)用題,可以給模型以下提示:
To solve this problem, we need to identify the known conditions and the unknown quantity. What are they? To solve this problem, we need to choose a suitable mathematical formula or method. What is it? To solve this problem, we need to substitute the known conditions into the formula or method. What do we get? To solve this problem, we need to calculate or simplify the result. What is the final answer?22.Few-shot-LtM策略包含哪些主要階段及其職責(zé)
Few-shot-LtM策略是一種利用最少到最多的提示序列,來讓大語言模型逐步增加推理難度和深度的方法。
它可以讓模型更有效地利用其通用知識和涌現(xiàn)能力,同時避免過擬合或?yàn)?zāi)難性遺忘。
Few-shot-LtM策略包含以下兩個主要階段及其職責(zé):
第一階段是將問題分解為子問題,即根據(jù)問題的復(fù)雜性和模型的能力,將問題拆分成若干個更簡單或更具體的子問題,這些子問題可以建立在彼此之上,也可以相互獨(dú)立。 這個階段的職責(zé)是為模型提供一個清晰和合理的思路,讓模型能夠逐步接近最終的目標(biāo)。 第二階段是逐個解決子問題,即根據(jù)第一階段得到的子問題序列,依次給模型提供相應(yīng)的提示,讓模型生成每個子問題的答案。 這些答案可以作為下一個子問題的輸入或條件,也可以直接作為最終答案。 這個階段的職責(zé)是為模型提供一個有效和靈活的引導(dǎo),讓模型能夠產(chǎn)生合理和正確的輸出。 23.相比較于llama而言,llama2有哪些改進(jìn),對于llama2是應(yīng)該如何finetune?llama和llama2都是一種大型語言模型(Large Language Model,LLM),它們可以用于多種自然語言處理的任務(wù),如文本生成、文本摘要、機(jī)器翻譯、問答等。
llama是一種基于Transformer的seq2seq模型,它使用了兩種預(yù)訓(xùn)練任務(wù),一種是無監(jiān)督的Span級別的mask,另一種是有監(jiān)督的多任務(wù)學(xué)習(xí)。
llama將所有的下游任務(wù)都視為文本到文本的轉(zhuǎn)換問題,即給定一個輸入文本,生成一個輸出文本。
llama使用了一個干凈的大規(guī)模英文預(yù)料C4,包含了約750GB的文本數(shù)據(jù)。 llama的最大規(guī)模達(dá)到了11B個參數(shù)。llama2是llama的改進(jìn)版本,它在以下幾個方面有所提升:1)數(shù)據(jù)量和質(zhì)量 :llama2使用了比llama1多40%的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,其中包括更多的高質(zhì)量和多樣性的數(shù)據(jù),例如來自Surge和Scale等數(shù)據(jù)標(biāo)注公司的數(shù)據(jù)。
2)上下文長度 :llama2的上下文長度是llama1的兩倍,達(dá)到了4k個標(biāo)記,這有助于模型理解更長的文本和更復(fù)雜的邏輯。
3)模型架構(gòu) :llama2在訓(xùn)練34B和70B參數(shù)的模型時使用了分組查詢注意力(Grouped-Query Attention,GQA)技術(shù),可以提高模型的推理速度和質(zhì)量。
4)微調(diào)方法: llama2使用了監(jiān)督微調(diào)(Supervised Fine-Tuning,SFT)和人類反饋強(qiáng)化學(xué)習(xí)(Reinforcement Learning from Human Feedback,RLHF)兩種方法來微調(diào)對話模型(llama2-chat),使模型在有用性和安全性方面都有顯著提升。
對llama2進(jìn)行微調(diào)有以下步驟:1)準(zhǔn)備訓(xùn)練腳本 :你可以使用Meta開源的llama-recipes項(xiàng)目,它提供了一些快速開始的示例和配置文件,以及一些自定義數(shù)據(jù)集和策略的方法。
2)準(zhǔn)備數(shù)據(jù)集 :你可以選擇一個符合你目標(biāo)任務(wù)和領(lǐng)域的數(shù)據(jù)集,例如GuanacoDataset,它是一個多語言的對話數(shù)據(jù)集,支持alpaca格式。你也可以使用自己的數(shù)據(jù)集,只要按照alpaca格式進(jìn)行組織即可。
3)準(zhǔn)備模型 :你可以從Hugging Face Hub下載llama2模型的權(quán)重,并轉(zhuǎn)換為Hugging Face格式。
4)啟動訓(xùn)練 :你可以使用單GPU或多GPU來進(jìn)行訓(xùn)練,并選擇是否使用參數(shù)高效微調(diào)(Parameter-Efficient Fine-Tuning,PEFT)或量化等技術(shù)來加速訓(xùn)練過程。
另外,各位對AIGC求職感興趣的小伙伴,可以多個關(guān)鍵詞同時搜索: AIGC產(chǎn)品經(jīng)理、AI產(chǎn)品經(jīng)理、ChatGpt產(chǎn)品經(jīng)理、大模型體驗(yàn)、大模型產(chǎn)品、AI數(shù)字人、AI機(jī)器人、對話機(jī)器人 等等,本質(zhì)上工作內(nèi)容都是偏AIGC的工作內(nèi)容。
好的,這篇文章先分享這些,大家關(guān)于求職有任何問題都可以在評論區(qū)留言,或者加我私人微信:xuelaoban678為了更好的幫助大家進(jìn)入AIGC領(lǐng)域,抓住未來10-20年高速發(fā)展的黃金賽道。我們推出了系統(tǒng)課程: 《AIGC產(chǎn)品實(shí)戰(zhàn)特訓(xùn)營》春節(jié)前最后一期 面向群體:0經(jīng)驗(yàn)轉(zhuǎn)行 想要求職AIGC產(chǎn)品經(jīng)理的人 項(xiàng)目優(yōu)勢: 1)小班制,每一期10個人左右。個性化好,1對1背景診斷以及項(xiàng)目方向定制。 2)課程系統(tǒng)性強(qiáng):課程會深度講解機(jī)器學(xué)習(xí)、強(qiáng)化學(xué)習(xí)、深度學(xué)習(xí)、大模型相關(guān),所以沒有算法基礎(chǔ)的同學(xué)不用擔(dān)心 3)手把手帶著做的項(xiàng)目屬于招聘量大、求職成功率高、薪資高的對話類(對話機(jī)器人)和圖片類(類妙鴨相機(jī))兩個項(xiàng)目,這兩個項(xiàng)目都是落地項(xiàng)目,不是虛擬項(xiàng)目。 4) 百度資深A(yù)I面試官1對1的簡歷修改和模擬面試服務(wù),無須額外付費(fèi)。 5)有任何疑問都可以免費(fèi)在2V1服務(wù)專屬群提問。 6)如果錯過直播,每次直播都有直播錄屏可以觀看回放。 7)額外福利:免費(fèi)復(fù)訓(xùn)。如果一期課程感覺吸收不好,目前提供免費(fèi)復(fù)訓(xùn)機(jī)會。