
綜述:PyTorch顯存機(jī)制分析

極市導(dǎo)讀
?作者最近兩年在研究分布式并行,經(jīng)常使用PyTorch框架。一開始用的時(shí)候?qū)τ赑yTorch的顯存機(jī)制也是一知半解,連蒙帶猜的,經(jīng)常來知乎上來找答案,那么我就吸收大家的看法,為PyTorch的顯存機(jī)制做個(gè)小的總結(jié)吧。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
實(shí)驗(yàn)環(huán)境
OS:Ubuntu18.04
python:3.7.4
PyTorch:1.9.1
GPU:V100
目錄
1 理論知識
1.1 深度學(xué)習(xí)訓(xùn)練過程
1.2 前向傳播
1.3 后向傳播(反向傳播)
1.4 梯度更新
2 顯存分析方法與Torch機(jī)制
2.1 分析方法
2.2 Torch顯存分配機(jī)制
2.3 Torch顯存釋放機(jī)制
3 訓(xùn)練過程顯存分析
3.1 模型的定義
3.2 前向傳播過程
3.3 后向傳播過程
3.4 參數(shù)更新
1 理論知識
1.1 深度學(xué)習(xí)訓(xùn)練過程
開門見山的說,PyTorch在進(jìn)行深度學(xué)習(xí)訓(xùn)練的時(shí)候,有4大部分的顯存開銷,分別是模型參數(shù)(parameters),模型參數(shù)的梯度(gradients),優(yōu)化器狀態(tài)(optimizer states)以及中間激活值(intermediate activations) 或者叫中間結(jié)果(intermediate results)。
為了后面顯存分析闡述的方便,我將深度學(xué)習(xí)的訓(xùn)練定義4個(gè)步驟:
模型定義:定義了模型的網(wǎng)絡(luò)結(jié)構(gòu),產(chǎn)生模型參數(shù);
while(你想訓(xùn)練):
前向傳播:執(zhí)行模型的前向傳播,產(chǎn)生中間激活值; 后向傳播:執(zhí)行模型的后向傳播,產(chǎn)生梯度; 梯度更新:執(zhí)行模型參數(shù)的更新,第一次執(zhí)行的時(shí)候產(chǎn)生優(yōu)化器狀態(tài)。
在模型定義完之后,2~4循環(huán)執(zhí)行。
1.2 前向傳播
拿Linear層(或者叫Dense層,前饋神經(jīng)網(wǎng)絡(luò),全連接層等等...)舉例:假設(shè)他的權(quán)重矩陣為W,偏置向量為b,那么他的前向計(jì)算過程就是:
,
這里的X為該層的輸入向量,Y為輸出向量(中間激活值)
1.3 后向傳播(反向傳播)
參考了這篇文章《神經(jīng)網(wǎng)絡(luò)反向傳播的數(shù)學(xué)原理》https://zhuanlan.zhihu.com/p/22473137
后向傳播回來了一個(gè)第l+1層的輸出誤差矩陣 ,用以計(jì)算該層的梯度和輸入誤差
1.4 梯度更新
接下來就是利用 W_diff 和 b_diff 進(jìn)行更新了:
當(dāng)然使用 Adam 優(yōu)化器的時(shí)候,實(shí)際的更新過程并沒有上面的這么簡單。目前用的最多的是 AdamW ,可以看看這篇文章《當(dāng)前訓(xùn)練神經(jīng)網(wǎng)絡(luò)最快的方式:AdamW優(yōu)化算法+超級收斂》https://zhuanlan.zhihu.com/p/38945390)
但是使用這一類優(yōu)化器,也會帶來額外的顯存開銷。對于每一個(gè)參數(shù),Adam都會為它準(zhǔn)備對應(yīng)的2個(gè)優(yōu)化器狀態(tài),分別是動量(momentum)和方差(variance),用以加速模型的訓(xùn)練。
2 顯存分析方法與Torch機(jī)制
2.1 分析方法
(1) No Nvidia-smi
我看很多人現(xiàn)在還在用 nvidia-smi 來看 pytorch 的顯存占用,盯著跳來跳去的torch緩存區(qū)分析真的不累嗎。(貼一個(gè)Torch為什么不用Nvidia-smi看的圖)。
而且PyTorch是有緩存區(qū)的設(shè)置的,意思就是一個(gè)Tensor就算被釋放了,進(jìn)程也不會把空閑出來的顯存還給GPU,而是等待下一個(gè)Tensor來填入這一片被釋放的空間。
有什么好處?進(jìn)程不需要重新向GPU申請顯存了,運(yùn)行速度會快很多,有什么壞處?他不能準(zhǔn)確地給出某一個(gè)時(shí)間點(diǎn)具體的Tensor占用的顯存,而是顯示的已經(jīng)分配到的顯存和顯存緩沖區(qū)之和。
這也是令很多人在使用PyTorch時(shí)對顯存占用感到困惑的罪魁禍?zhǔn)住?/p>
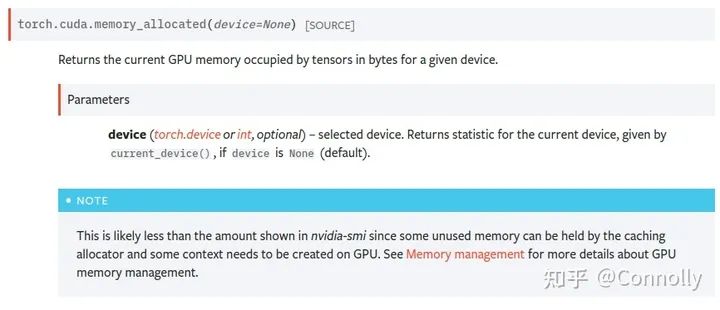
(2) torch.cuda is all you need
在分析PyTorch的顯存時(shí)候,一定要使用torch.cuda里的顯存分析函數(shù),我用的最多的是torch.cuda.memory_allocated()和torch.cuda.max_memory_allocated(),前者可以精準(zhǔn)地反饋當(dāng)前進(jìn)程中Torch.Tensor所占用的GPU顯存,后者則可以告訴我們到調(diào)用函數(shù)為止所達(dá)到的最大的顯存占用字節(jié)數(shù)。
還有像torch.cuda.memory_reserved()這樣的函數(shù)則是查看當(dāng)前進(jìn)程所分配的顯存緩沖區(qū)是多少的。
memory_allocated+memory_reserved就等于nvidia-smi中的值啦。
非~常~好~用
-----之前沒有提到PyTorch context的開銷,做個(gè)補(bǔ)充...
我注意到有很多同學(xué)在做顯存分析的時(shí)候是為了在訓(xùn)練的時(shí)候可以把卡的顯存用滿,這個(gè)之前沒有考慮到呢。其實(shí)PyTorch context是我們在使用torch的時(shí)候的一個(gè)大頭開銷。
主要參考的是論壇里的這篇討論:
How do I create Torch Tensor without any wasted storage space/baggage?
https://discuss.pytorch.org/t/how-do-i-create-torch-tensor-without-any-wasted-storage-space-baggage/131134
什么是PyTorch context? 其實(shí)官方給他的稱呼是CUDA context,就是在第一次執(zhí)行CUDA操作,也就是使用GPU的時(shí)候所需要創(chuàng)建的維護(hù)設(shè)備間工作的一些相關(guān)信息。如下圖所示
這個(gè)值跟CUDA的版本,pytorch的版本以及所使用的設(shè)備都是有關(guān)系的。目前我在ubuntu的torch1.9上測過RTX 3090和V100的context 開銷。其中3090用的CUDA 11.4,開銷為1639MB;V100用的CUDA 10.2,開銷為1351MB。
感興趣的同學(xué)可以在shell中執(zhí)行下面這兩行代碼,然后用nvidia-smi去看看自己的環(huán)境里context的大小。然后用總大小減去context的大小再做顯存分析。
import?torch
temp?=?torch.tensor([1.0]).cuda()
我估計(jì)會有人問怎么去減小這個(gè)開銷...官方也給了一個(gè)辦法,看看自己有哪些cuda依賴是不需要的,比如cuDNN,然后自己重新編譯一遍PyTorch。編譯的時(shí)候把對應(yīng)的包的flag給設(shè)為false就好了。我是還沒有試過,要搭編譯的環(huán)境太難受了,而且還要經(jīng)常和庫做更新。
2.3?Torch顯存分配機(jī)制
在PyTorch中,顯存是按頁為單位進(jìn)行分配的,這可能是CUDA設(shè)備的限制。就算我們只想申請4字節(jié)的顯存,CUDA也會為我們分配512字節(jié)或者1024字節(jié)的空間。
2.4?Torch顯存釋放機(jī)制
在PyTorch中,只要一個(gè)Tensor對象在后續(xù)不會再被使用,那么PyTorch就會自動回收該Tensor所占用的顯存,并以緩沖區(qū)的形式繼續(xù)占用顯存。
要是實(shí)在看緩沖區(qū)不爽的話,也可以用torch.cuda.empty_cache()把它歸零,但是程序速度會變慢哦
3 訓(xùn)練過程顯存分析
為了讓大家方便理解,我這里用torch.nn.Linear(1024, 1024, bias=False) 來做例子。為了省事,loss函數(shù)則直接對輸出的樣本進(jìn)行求和得到。沒辦法,想直接執(zhí)行l(wèi)oss.backward()的話,loss得是標(biāo)量才行呢。
示例代碼:
import torch
model = torch.nn.Linear(1024,1024, bias=False).cuda()
optimizer = torch.optim.AdamW(model.parameters())
inputs = torch.tensor([1.0]*1024).cuda() # shape = (1024)
outputs = model(inputs) # shape = (1024)
loss = sum(outputs) # shape = (1)
loss.backward()
optimizer.step()
3.1 模型的定義
結(jié)論:顯存占用量約為參數(shù)量乘以4
import torch
model = torch.nn.Linear(1024,1024, bias=False).cuda()
print(torch.cuda.memory_allocated())
打印出來的數(shù)值為4194304,剛好等于1024×1024×4。
3.2 前向傳播過程
結(jié)論:顯存增加等于每一層模型產(chǎn)生的結(jié)果的顯存之和,且跟batch_size成正比。
inputs = torch.tensor([1.0]*1024).cuda() # shape = (1024) memory + 4096
outputs = model(inputs) # memory + 4096
代碼中,outputs為產(chǎn)生的中間激活值,同時(shí)它也恰好是該模型的輸出結(jié)果。在執(zhí)行完這一步之后,顯存增加了4096字節(jié)。(不算inputs的顯存的話)。
3.3 后向傳播過程
后向傳播會將模型的中間激活值給消耗并釋放掉掉,并為每一個(gè)模型中的參數(shù)計(jì)算其對應(yīng)的梯度。在第一次執(zhí)行的時(shí)候,會為模型參數(shù)分配對應(yīng)的用來存儲梯度的空間。
loss = sum(outputs) # memory + 512(torch cuda分配最小單位)
temp = torch.cuda.memory_allocated()
loss.backward()
print(torch.cuda.memory_allocated() - temp) # 第一次增加4194304
第一次執(zhí)行時(shí)顯存增加:4194304字節(jié) - 激活值大小;
第二次以后執(zhí)行顯存減少:激活值大小;
Note:由于這個(gè)中間激活值被賦給了outputs,所以后面在后向傳播的時(shí)候會發(fā)現(xiàn),這個(gè)outputs的顯存沒有被釋放掉。但是當(dāng)層數(shù)變深的時(shí)候,就能明顯看到變化了。
為了讓大家看到變化,再寫一段代碼~
import torch
# 模型初始化
linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304
print(torch.cuda.memory_allocated())
linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096
print(torch.cuda.memory_allocated())
# 輸入定義
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304
print(torch.cuda.memory_allocated())
# 前向傳播
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512
print(torch.cuda.memory_allocated())
# 后向傳播
loss.backward() # memory - 4194304 + 4194304 + 4096
print(torch.cuda.memory_allocated())
# 再來一次~
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512沒了,因?yàn)閘oss的ref還在)
print(torch.cuda.memory_allocated())
loss.backward() # memory - 4194304
print(torch.cuda.memory_allocated())
3.4 參數(shù)更新
optimizer.step()?#?第一次增加8388608,第二次就不增不減了哦
第一次執(zhí)行時(shí),會為每一個(gè)參數(shù)初始化其優(yōu)化器狀態(tài),對于這里的AdamW而言,每一個(gè)參數(shù)需要4*2=8個(gè)字節(jié)。
第二次開始,不會再額外分配顯存。
顯存開銷:
第一次: 增加8388608字節(jié)
第二次及以后: 無增減
3.5 Note
由于計(jì)算機(jī)計(jì)算的特性,有一些計(jì)算操作在計(jì)算過程中是會帶來額外的顯存開銷的。但是這種開銷在torch.memory_allocated中是不能被察覺的。
比如在AdamW在進(jìn)行某一層的更新的時(shí)候,會帶來2倍該層參數(shù)量大小的臨時(shí)額外開銷。這個(gè)在max_memory_allocated中可以看到。
在本例中就是8388608字節(jié)。
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“重郵”獲取最新目標(biāo)檢測算法綜述PDF~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
