
梯度下降到底是什么?
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
我們回憶深度學習“三板斧”:
1.?選擇神經(jīng)網(wǎng)絡
2.?定義神經(jīng)網(wǎng)絡的好壞
3.?選擇最好的參數(shù)集合
其中步驟三,如何選擇神經(jīng)網(wǎng)絡的好壞呢?
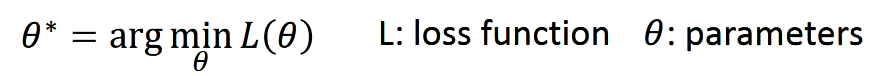
梯度下降是目前,最有效的方法之一。
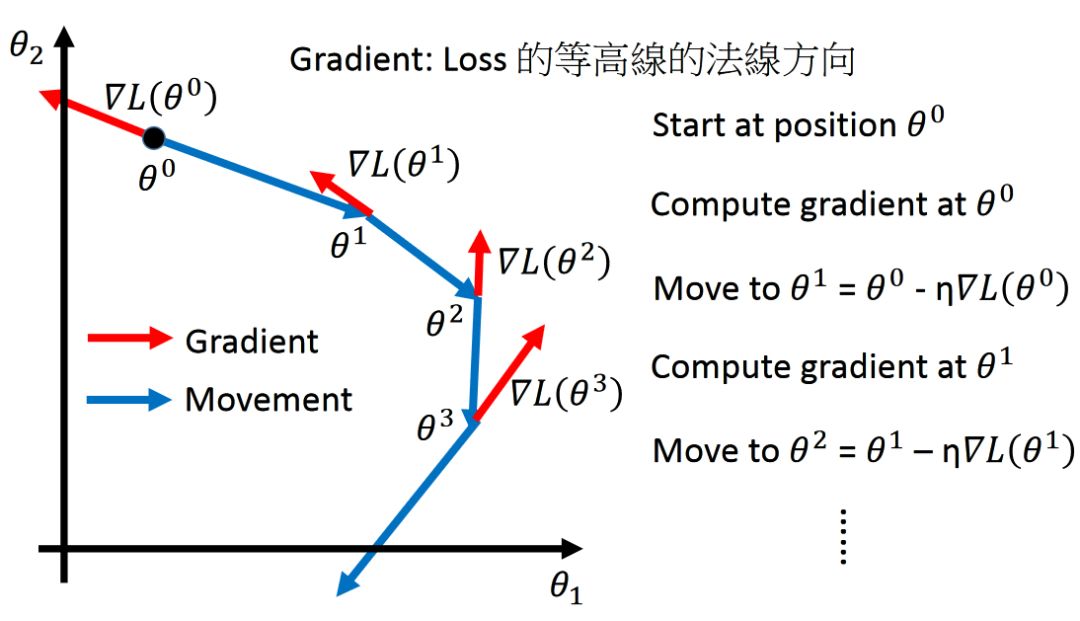
方法:我們舉兩個參數(shù)的例子?θ1、θ2,?損失函數(shù)是L。那么它的梯度是:
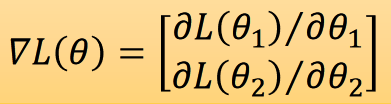
那我為了求得最小值,我們有:
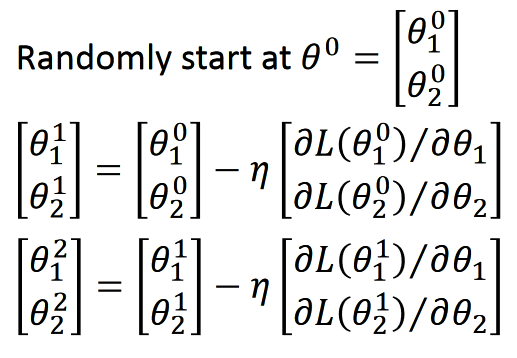
參數(shù)不斷被梯度乘以學習率η?迭代
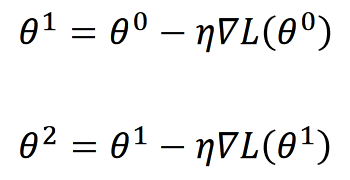
那么上述公示公為什么是減號,不是加號呢?
我們定義?θ?改變的方向是movement的方向,?而gradient的方向是等高線的法線方向
基礎的Gradient Decent已經(jīng)介紹完了,接下來,我們一起探討GD的使用技巧。
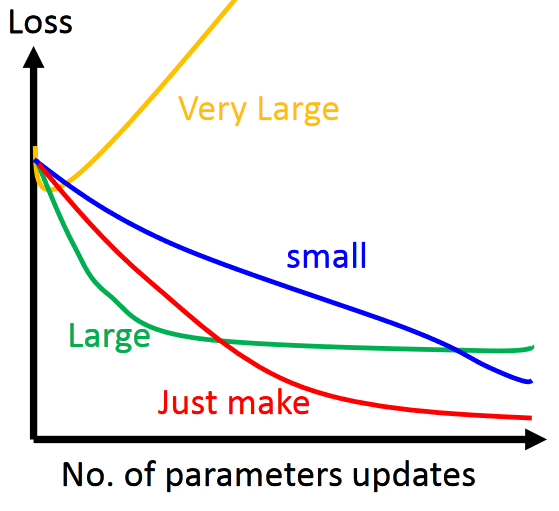
Learning?rate學習率的設定
Learning?Rate?η?如果設定不好,Loss反而增大
自適應的學習率?adaptive?learning?rate
很多小伙伴在機器學習代碼中,學習率一般都是設置為一個固定的數(shù)值(需要不斷調(diào)參)。
根據(jù)學習經(jīng)驗,一般的我們有如下結論:
1.?訓練剛開始的時候,學習率較大
2.?經(jīng)過幾輪訓練后,結果慢慢接近的時候,需要調(diào)小學習率

Adagrad?的學習率是現(xiàn)有學習率?除以?導數(shù)的平方和的開根號
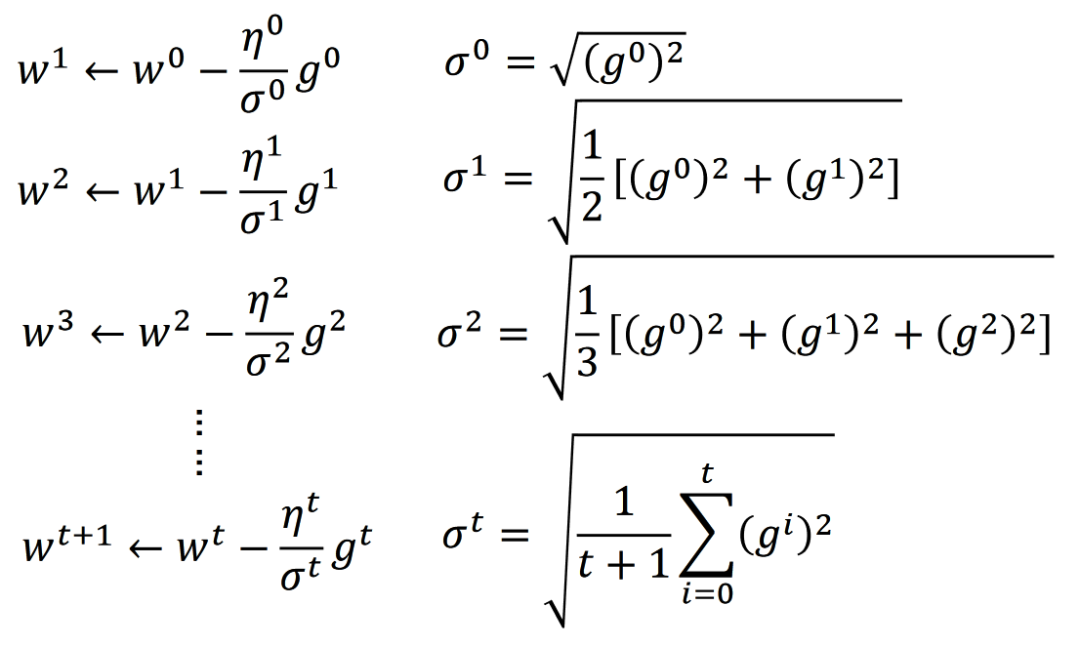
Stochastic?Gradient?Decent?(SGD)
讓訓練更加快速
一般的GD方法是所有的訓練數(shù)據(jù)后,進行一次參數(shù)更新
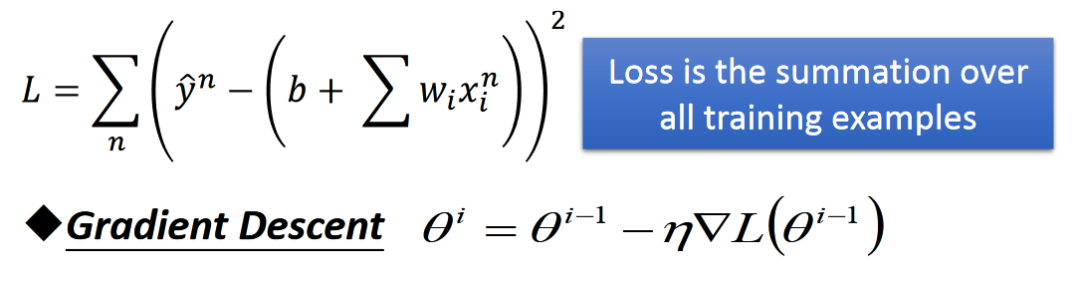
SGD是一個樣本就可以更新參數(shù)
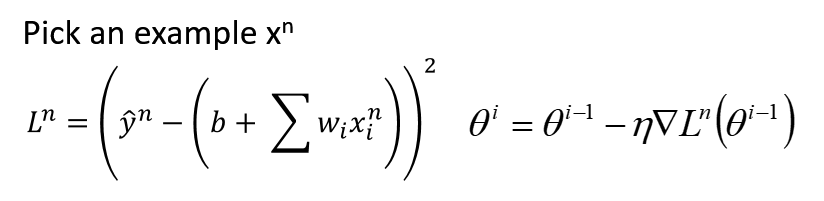
GD和SGD的對比效果:

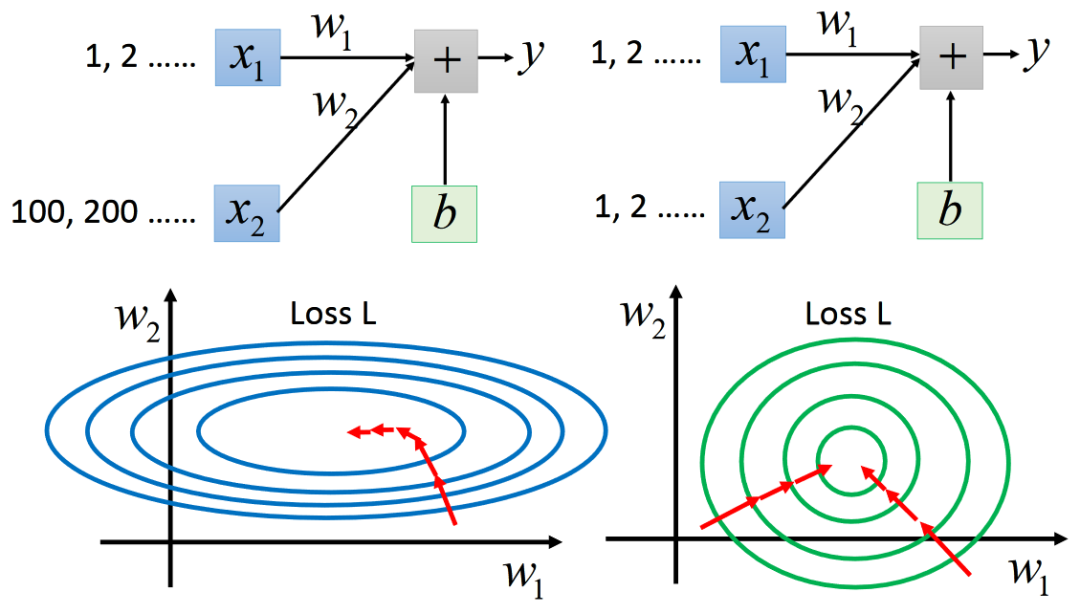
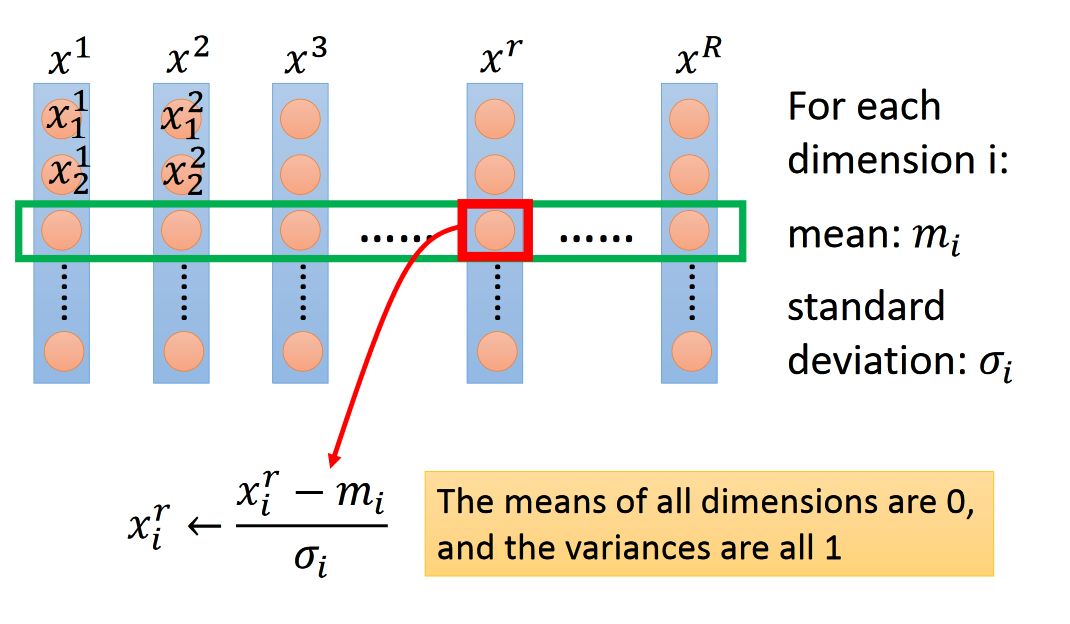
特征裁剪?Feature?Scaling
讓不同維度的數(shù)據(jù),有相同的變化幅度
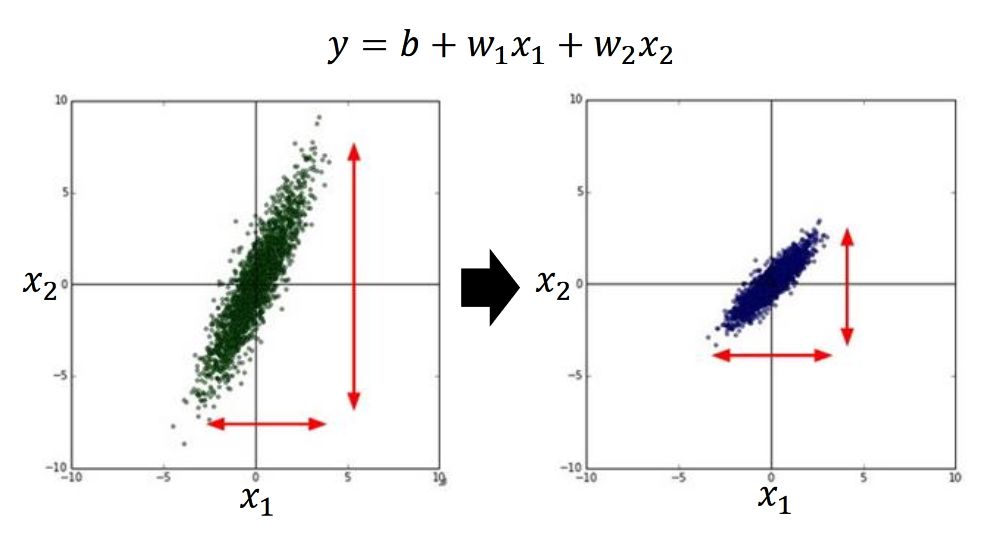
訓練的時候,哪一個好train,一目了然
歸一化方法:
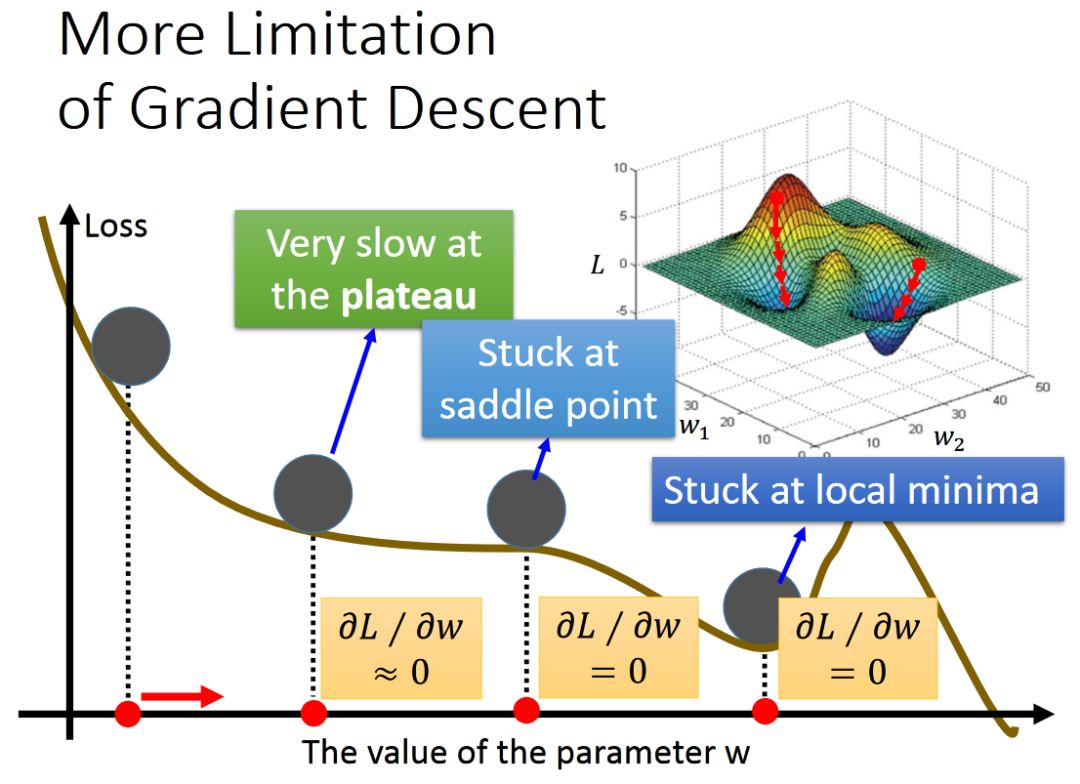
總結: Gradient Decent 是機器學習、深度學習求解Optimal問題的“普世”方法,但是也會遇到很多問題,例如local minima 和 saddle point 的問題。?我們以后會展開討論。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~