點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文約2600字,建議閱讀5分鐘
Attention is all you need.
[ 導(dǎo)語(yǔ) ]在機(jī)器學(xué)習(xí)領(lǐng)域里有一句俗話:「Attention is all you need」,通過(guò)注意力機(jī)制,谷歌提出的 Transformer 模型引領(lǐng)了 NLP 領(lǐng)域的大幅度進(jìn)化,進(jìn)而影響了 CV 領(lǐng)域,甚至連論文標(biāo)題本身也變成了一個(gè)梗,被其后的研究者們不斷重新演繹。
技術(shù)潮流總有變化的時(shí)候——到了 2021 年,風(fēng)向似乎變成了多層感知機(jī)(MLP)。近日,谷歌大腦 Quoc Le 等人的一項(xiàng)研究對(duì)注意力層的必要性提出了質(zhì)疑,并提出了一種具有空間門(mén)控單元的無(wú)注意力網(wǎng)絡(luò)架構(gòu) gMLP,在圖像分類(lèi)和掩碼語(yǔ)言建模任務(wù)上均實(shí)現(xiàn)了媲美 Transformer 的性能表現(xiàn)。
最近一段時(shí)間,多層感知機(jī) MLP 成為 CV 領(lǐng)域的重點(diǎn)研究對(duì)象。谷歌原 ViT 團(tuán)隊(duì)提出了一種不使用卷積或自注意力的 MLP-Mixer 架構(gòu),并且在設(shè)計(jì)上非常簡(jiǎn)單,在 ImageNet 數(shù)據(jù)集上也實(shí)現(xiàn)了媲美 CNN 和 ViT 的性能。接著,清華大學(xué)圖形學(xué)實(shí)驗(yàn)室 Jittor 團(tuán)隊(duì)提出了一種新的注意機(jī)制「External Attention」,只用兩個(gè)級(jí)聯(lián)的線性層和歸一化層就可以取代現(xiàn)有流行的學(xué)習(xí)架構(gòu)中的「Self-attention」。同一時(shí)期,清華大學(xué)軟件學(xué)院丁貴廣團(tuán)隊(duì)提出的結(jié)合重參數(shù)化技術(shù)的 MLP 也取得了非常不錯(cuò)的效果。Facebook 也于近日提出了一種用于圖像分類(lèi)的純 MLP 架構(gòu),該架構(gòu)受 ViT 的啟發(fā),但更加簡(jiǎn)單:不采用任何形式的注意力機(jī)制,僅僅包含線性層與 GELU 非線性激活函數(shù)。MLP→CNN→Transformer→MLP 似乎已經(jīng)成為一種大勢(shì)所趨。谷歌大腦首席科學(xué)家、AutoML 鼻祖 Quoc Le 團(tuán)隊(duì)也將研究目光轉(zhuǎn)向了 MLP。在最新的一項(xiàng)研究中,該團(tuán)隊(duì)提出了一種僅基于空間門(mén)控 MLP 的無(wú)注意力網(wǎng)絡(luò)架構(gòu) gMLP,并展示了該架構(gòu)在一些重要的語(yǔ)言和視覺(jué)應(yīng)用中可以媲美 Transformer。
研究者將 gMLP 用于圖像分類(lèi)任務(wù),并在 ImageNet 數(shù)據(jù)集上取得了非常不錯(cuò)的結(jié)果。在類(lèi)似的訓(xùn)練設(shè)置下,gMLP 實(shí)現(xiàn)了與 DeiT(一種改進(jìn)了正則化的 ViT 模型)相當(dāng)?shù)男阅堋2粌H如此,在參數(shù)減少 66% 的情況下,gMLP 的準(zhǔn)確率比 MLP-Mixer 高出 3%。這一系列的實(shí)驗(yàn)結(jié)果對(duì) ViT 模型中自注意力層的必要性提出了質(zhì)疑。他們還將 gMLP 應(yīng)用于 BERT 的掩碼語(yǔ)言建模(MLM)任務(wù),發(fā)現(xiàn) gMLP 在預(yù)訓(xùn)練階段最小化困惑度的效果與 Transformer 一樣好。該研究的實(shí)驗(yàn)表明,困惑度僅與模型的容量有關(guān),對(duì)注意力的存在并不敏感。隨著容量的增加,研究者觀察到,gMLP 的預(yù)訓(xùn)練和微調(diào)表現(xiàn)的提升與 Transformer 一樣快。gMLP 的有效性,視覺(jué)任務(wù)上自注意力和 NLP 中注意力機(jī)制的 case-dependent 不再具有優(yōu)勢(shì),所有這些都令研究者對(duì)多個(gè)領(lǐng)域中注意力的必要性提出了質(zhì)疑。總的來(lái)說(shuō),該研究的實(shí)驗(yàn)結(jié)果表明,自注意力并不是擴(kuò)展 ML 模型的必要因素。隨著數(shù)據(jù)和算力的增加,gMLP 等具有簡(jiǎn)單空間交互機(jī)制的模型具備媲美 Transformer 的強(qiáng)大性能,并且可以移除自注意力或大幅減弱它的作用。
論文地址:https://arxiv.org/pdf/2105.08050.pdf具有空間門(mén)控單元(Spatial Gating Unit, SGU)的 gMLP 架構(gòu)示意圖如下所示,該模型由堆疊的 L 塊(具有相同的結(jié)構(gòu)和大小)組成。
上圖公式中的關(guān)鍵組件是 s(·),這是一個(gè)用于捕獲空間交互的層。所以,研究者需要設(shè)計(jì)一個(gè)能夠捕獲 token 間復(fù)雜空間交互的強(qiáng)大 s(·)。L 塊的整體布局受到了反轉(zhuǎn)瓶頸(inverted bottleneck)的啟發(fā),將 s(·) 定義為一個(gè)空間深度卷積(spatial depthwise convolution)。值得注意的是,不同于 Transformer,gMLP 模型無(wú)需位置嵌入,因?yàn)檫@類(lèi)信息將在 s(·) 中被捕獲。并且,gMLP 模型使用與 BERT 和 ViT 完全相同的輸入和輸出格式。為了實(shí)現(xiàn)跨 token 的交互,s(·) 層必須要包含空間維度上的收縮變換。最簡(jiǎn)單的方法是線性投影:
在該論文中,研究者將空間交互單元定義為其輸入和空間轉(zhuǎn)換輸入的乘積:
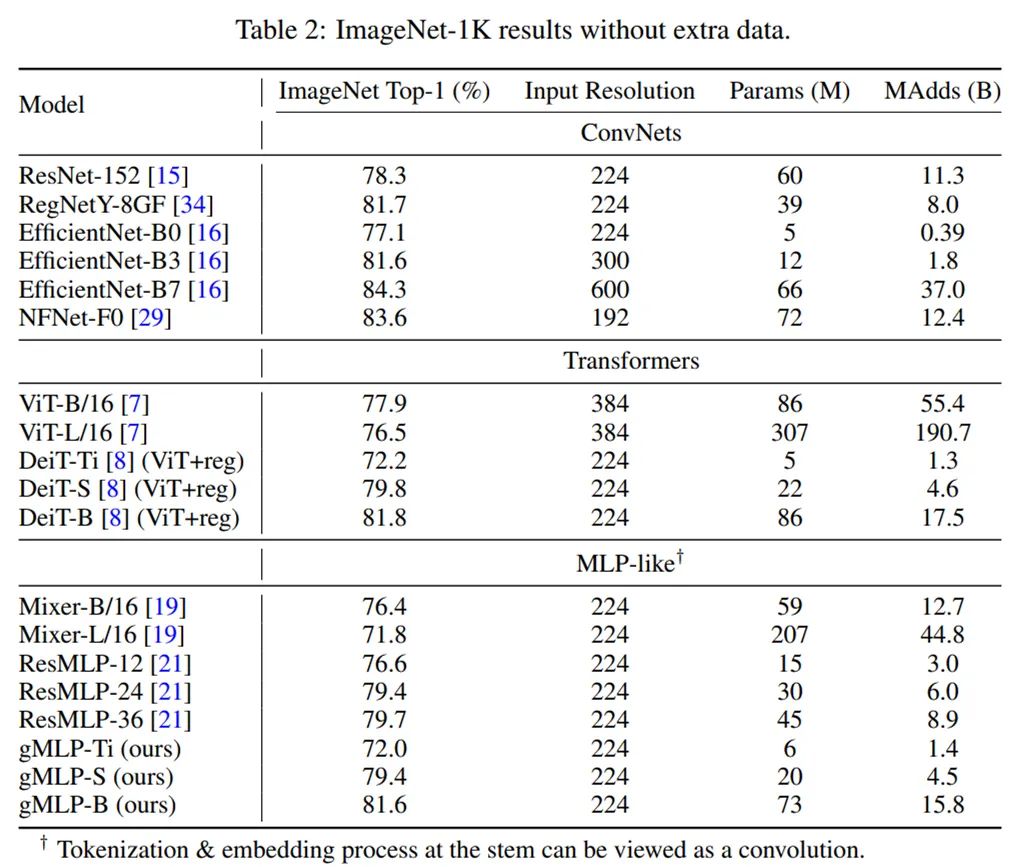
研究者在沒(méi)有額外數(shù)據(jù)的 ImageNet 數(shù)據(jù)集上將 gMLP 應(yīng)用于圖像分類(lèi)任務(wù),以衡量它在計(jì)算機(jī)視覺(jué)領(lǐng)域的性能。他們將三個(gè) gMLP 變體模型(gMLP-Ti、gMLP-S 和 gMLP-B)與其他基于原始 Transformer 的模型進(jìn)行了對(duì)比,包括 ViT、DeiT 以及其他幾個(gè)有代表性的卷積網(wǎng)絡(luò)。下表 1 給出了上述三個(gè) gMLP 變體的參數(shù)、FLOPS 和生存概率(Survival Probability):
下表 2 為不同模型的對(duì)比結(jié)果。可以看到,gMLP 的 Top-1 準(zhǔn)確率與 DeiT 模型相當(dāng)。這一結(jié)果表明,無(wú)注意力的模型在圖像分類(lèi)任務(wù)上具有與 Transformer 一樣的數(shù)據(jù)高效性。此外,gMLP 可以媲美原始 Transformer,性能僅落后現(xiàn)有性能最佳的 ConvNet 模型和混合注意力模型。MLP-like 模型中的 Tokenization 和嵌入過(guò)程可視作一種卷積研究者對(duì)不同模型在掩碼語(yǔ)言建模任務(wù)(MLM)上的性能進(jìn)行了實(shí)驗(yàn)研究。消融實(shí)驗(yàn):gMLP 中門(mén)控(gating)對(duì) BERT 預(yù)訓(xùn)練的重要性研究者為消融實(shí)驗(yàn)設(shè)置了三個(gè)基準(zhǔn)模型:- 具有 Transformer 架構(gòu)和可學(xué)得絕對(duì)位置嵌入的 BERT;
- 具有 Transformer 架構(gòu)和 T5-style 可學(xué)得相對(duì)位置偏差的 BERT;
- 同上,但在 softmax 內(nèi)部移除了所有與內(nèi)容有關(guān)的項(xiàng),并僅保留相對(duì)位置偏差。
在下表 3 中,他們將這些基準(zhǔn) BERT 模型與類(lèi)似大小、不同版本的 gMLP 進(jìn)行了對(duì)比。需要注意,表格最后一行 Multiplicative, Split 即上文方法部分描述的空間門(mén)控單元(SGU)。可以看到,SGU 的困惑度低于其他變體,具有 SGU 的 gMLP 得到了與 BERT 相當(dāng)?shù)睦Щ蠖取?/span>
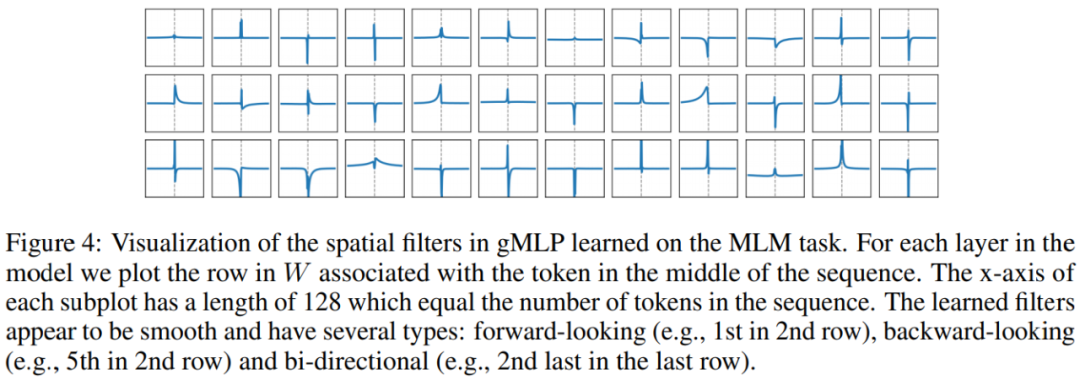
gMLP 學(xué)得的空間投影權(quán)重的可視化如下圖所示
案例研究:模型大小增加時(shí),gMLP 的性能變化在下表 4 中,研究者探究了隨著模型容量的增長(zhǎng),Transformer 與 gMLP 模型的擴(kuò)展性能。結(jié)果表明,在模型容量相當(dāng)時(shí),足夠深度的 gMLP 在困惑度上的表現(xiàn)能夠趕上甚至優(yōu)于 Transformer(困惑度越低,模型效果越好)。
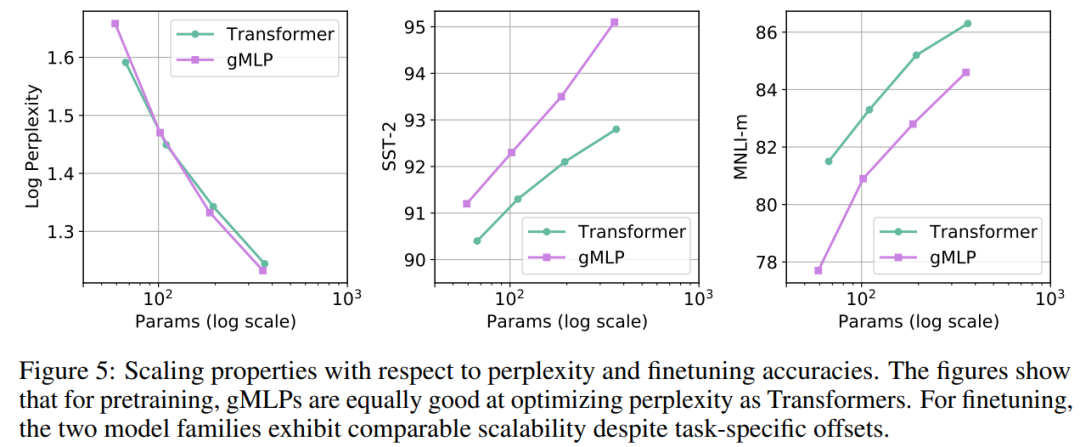
gMLP 和 Transformer 這兩類(lèi)不同架構(gòu)模型的困惑度 - 參數(shù)關(guān)系大體符合冪次定律(如下圖 5 左)。此外,從圖 5 中還可以看到,盡管在預(yù)訓(xùn)練和微調(diào)之間存在特定于架構(gòu)的差異,但 gMLP 和 Transformer 在微調(diào)任務(wù)上均表現(xiàn)出了相當(dāng)?shù)臄U(kuò)展性。這表明,下游任務(wù)上模型的可擴(kuò)展性與自注意力的存在與否無(wú)關(guān)。
消融實(shí)驗(yàn):tiny 注意力在 BERT 微調(diào)中的作用為了脫離注意力的影響,研究者嘗試了一個(gè)混合模型,其中將一個(gè) tiny 自注意力塊與 gMLP 的門(mén)控組件相連。他們將這個(gè)混合模型稱(chēng)為 aMLP(a 表示注意力)。下圖 6(左)為具有 tiny 自注意力塊的混合模型,圖 6(右)為 tiny 注意力模塊的偽代碼
如下表 7 所示,研究者通過(guò)預(yù)訓(xùn)練困惑度和微調(diào)度量指標(biāo)之間的校正曲線探究了 Transformer、gMLP 和 aMLP 的可遷移性。可以看到,就 SST-2 準(zhǔn)確率而言,gMLP 的遷移效果優(yōu)于具有注意力機(jī)制的 Transformer 模型,但在 MNLI 語(yǔ)料庫(kù)上的表現(xiàn)較差,但在加了 tiny 注意力(即 aMLP)之后就縮小了差距。
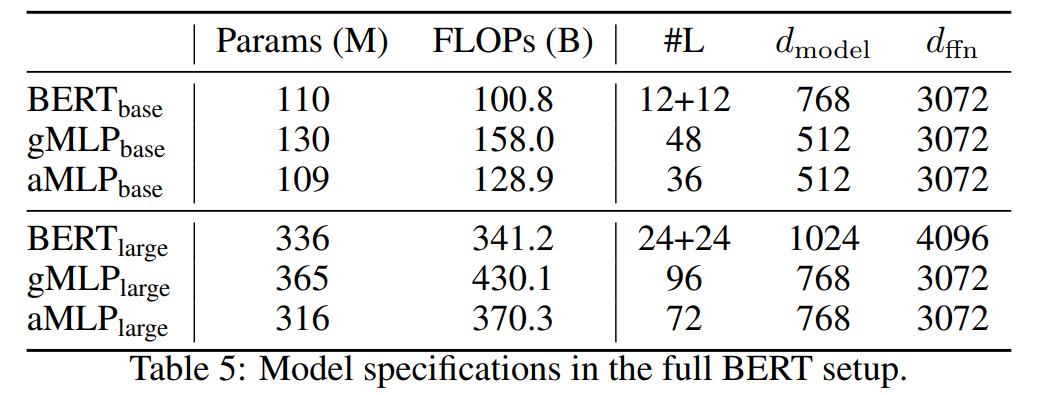
掩碼語(yǔ)言建模任務(wù)的主要結(jié)果研究者展示了完整 BERT 設(shè)置下預(yù)訓(xùn)練和微調(diào)的結(jié)果。他們使用了完整的英語(yǔ) C4 數(shù)據(jù)集,并采用了批大小為 256、最大長(zhǎng)度為 512 和 100 萬(wàn)步訓(xùn)練的常用掩碼語(yǔ)言建模設(shè)置。下表 5 為 BERT、gMLP 和 aMLP 模型的規(guī)格:
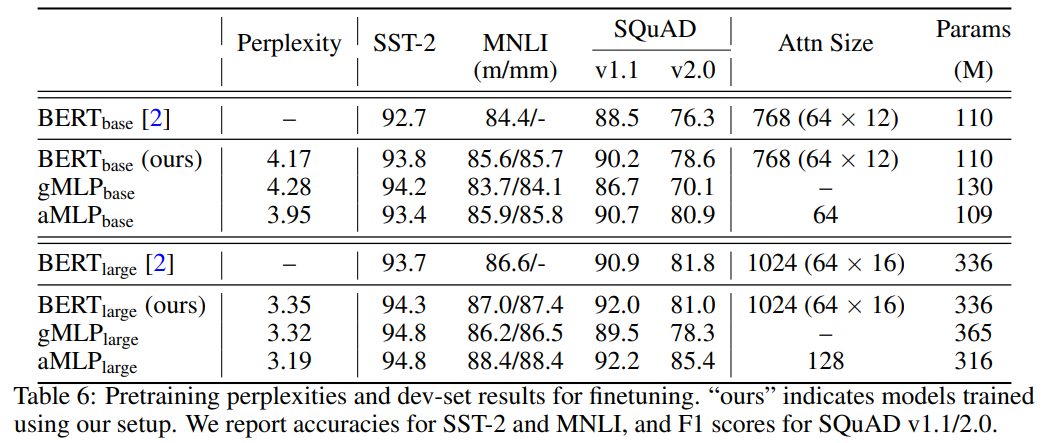
如下表 6 所示,主要結(jié)果與前文結(jié)論保持一致,gMLP 在困惑度指標(biāo)上可以媲美 BERT,模型規(guī)模越大結(jié)果更明顯。
網(wǎng)友質(zhì)疑:這不就是 transformer 嗎不過(guò),對(duì)于這項(xiàng)研究中提出的基于空間門(mén)控單元的 gMLP 架構(gòu),有網(wǎng)友質(zhì)疑:「gMLP 的整體架構(gòu)難道不是更類(lèi)似于 transformer 而不是原始 MLP 嗎?」
也有知乎網(wǎng)友質(zhì)疑到:「空間門(mén)控單元不就是注意力嗎?」另一網(wǎng)友則表示:「不算是注意力可能是因?yàn)闆](méi)有 softmax。」編輯:黃繼彥