
深度學(xué)習(xí)多目標(biāo)優(yōu)化的多個(gè)loss應(yīng)該如何權(quán)衡
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


本文介紹了一篇關(guān)于多任務(wù)學(xué)習(xí)的綜述,詳細(xì)介紹了文章中關(guān)于多任務(wù)學(xué)習(xí)的兩個(gè)主要研究方向:task balancing和其他。

看了那么多篇理論慢慢的paper,終于找到一篇比較有工程意義的paper了。
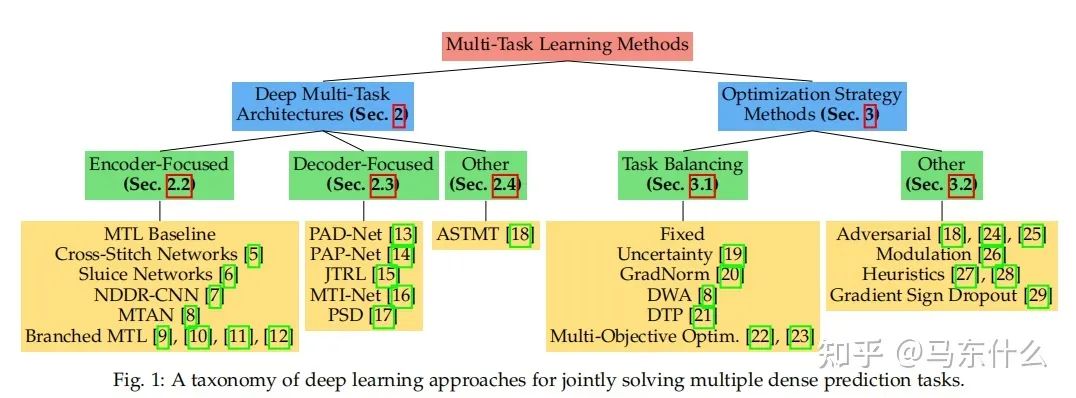
對(duì)于應(yīng)用來說,這樣比較簡(jiǎn)單直接的survey才是王道啊!感覺之前看的多任務(wù)的survey公式和定理太多,還是這樣的文章比較能夠幫助快速上手解決問題。
當(dāng)然這里主要還是介紹optimization strategy部分。
這篇文章提到了多任務(wù)學(xué)習(xí)的兩個(gè)主要研究方向:
1、多任務(wù)學(xué)習(xí)的網(wǎng)絡(luò)結(jié)構(gòu)的構(gòu)造;
2、多任務(wù)學(xué)習(xí)對(duì)標(biāo)的多目標(biāo)優(yōu)化的方法;
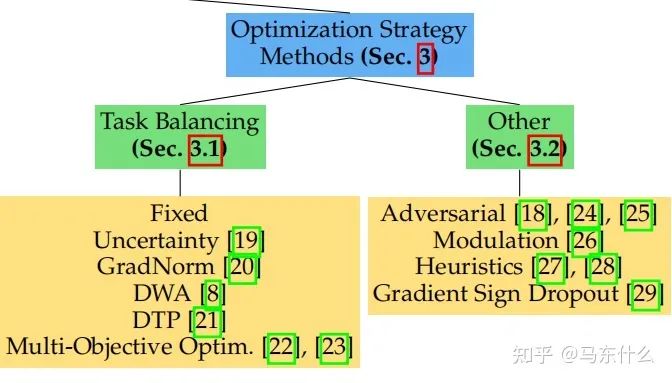
大體上分為兩種:
1、task balancing;
2、others。。。。
MTL中的一個(gè)重大挑戰(zhàn)源于優(yōu)化過程本身。特別是,我們需要仔細(xì)平衡所有任務(wù)的聯(lián)合訓(xùn)練過程,以避免一個(gè)或多個(gè)任務(wù)在網(wǎng)絡(luò)權(quán)值中具有主導(dǎo)影響的情況。極端情況下,當(dāng)某個(gè)任務(wù)的loss非常的大而其它任務(wù)的loss非常的小,此時(shí)多任務(wù)近似退化為單任務(wù)目標(biāo)學(xué)習(xí),網(wǎng)絡(luò)的權(quán)重幾乎完全按照大loss任務(wù)來進(jìn)行更新,逐漸喪失了多任務(wù)學(xué)習(xí)的優(yōu)勢(shì)(具體優(yōu)勢(shì)可見:
馬東什么:多任務(wù)學(xué)習(xí)之非深度看起來頭大的部分
https://zhuanlan.zhihu.com/p/361464660
馬東什么:多任務(wù)學(xué)習(xí)之深度學(xué)習(xí)部分
https://zhuanlan.zhihu.com/p/361915151
第一大類方法 Task Balancing Approaches
假設(shè)任務(wù)特定權(quán)重的優(yōu)化目標(biāo)wi和任務(wù)特定損失函數(shù)Li:
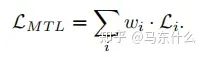
當(dāng)使用隨機(jī)梯度下降來盡量減少上圖方程的總目標(biāo)函數(shù)值(這是深度學(xué)習(xí)時(shí)代的標(biāo)準(zhǔn)方法),對(duì)共享層Wshare中的網(wǎng)絡(luò)權(quán)值通過以下規(guī)則進(jìn)行更新:
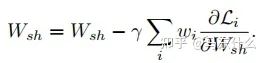
從上圖的方程可以看出:
1、loss大則梯度更新量也大;
2、不同任務(wù)的loss差異大導(dǎo)致模型更新不平衡的本質(zhì)原因在于梯度大小;
3、通過調(diào)整不同任務(wù)的loss權(quán)重wi可以改善這個(gè)問題;
4、直接對(duì)不同任務(wù)的梯度進(jìn)行處理也可以改善這個(gè)問題;
所以,后續(xù)的方法大體分為兩類:
1、在權(quán)重wi上做文章;
2、在梯度上做文章
在權(quán)重上做文章的方法:
1、Uncertainty Weighting
https://arxiv.org/pdf/1705.07115v3.pdf
人工定義多任務(wù)loss的權(quán)重是之前主要的使用方法,這種方法存在許多問題。模型性能對(duì)權(quán)重的選擇非常敏感,如圖所示。
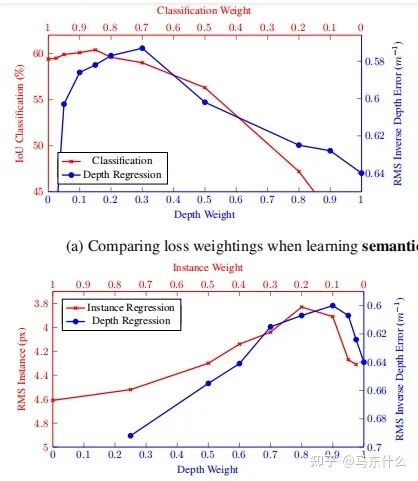
橫軸和縱軸分別是兩個(gè)任務(wù)的權(quán)重,曲線上的點(diǎn)對(duì)應(yīng)不同權(quán)重下多任務(wù)深度學(xué)習(xí)網(wǎng)絡(luò)最終的訓(xùn)練結(jié)果。
這些權(quán)重作為超參數(shù)調(diào)整起來非常的費(fèi)事費(fèi)力,每次測(cè)試通常需要很多的時(shí)間。
在貝葉斯學(xué)習(xí)
https://book.douban.com/subject/26284941/
關(guān)于python概率編程非常推薦這本書,這本也有中文版:
貝葉斯方法:概率編程與貝葉斯推斷
另外,tensorflow-probability在google上有關(guān)于這本書完整的代碼demo,非常淺顯易懂,上手快。
另外也有torch版的pyro
相關(guān)的代碼可見:
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
https://github.com/tensorflow/probability
https://github.com/pyro-ppl/pyro
中,認(rèn)為模型存在兩種不確定性:
張子楊:【實(shí)驗(yàn)筆記】深度學(xué)習(xí)中的兩種不確定性(上)
https://zhuanlan.zhihu.com/p/56986840
1.偶然不確定性
我們初高中學(xué)物理的時(shí)候,老師肯定提過偶然誤差這個(gè)詞。我們做小車下落測(cè)量重力加速度常數(shù)的時(shí)候,每次獲得的值都會(huì)有一個(gè)上下起伏。這是我們因?yàn)闅饬鲾_動(dòng),測(cè)量精度不夠等原因所造成的,是無法被避免的一類誤差。在深度學(xué)習(xí)中,我們把這種誤差叫做偶然不確定性。
從深度學(xué)習(xí)的角度來舉例子,我們舉一個(gè)大家應(yīng)該很比較熟悉的人臉關(guān)鍵點(diǎn)回歸問題[3]:
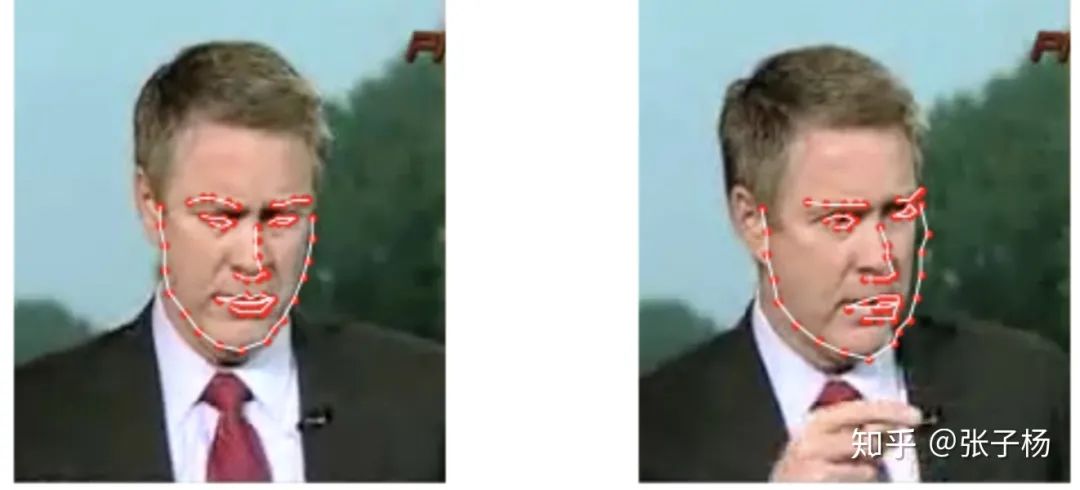
我們可以看到,對(duì)于很相似的一組數(shù)據(jù),dataset的標(biāo)注出現(xiàn)了比較大的誤差(見右圖的右側(cè)邊緣)。這樣的誤差并不是我們模型帶入的,而是數(shù)據(jù)本來就存在誤差。數(shù)據(jù)集里這樣的bias越大,我們的偶然不確定性就應(yīng)該越大。
2.認(rèn)知不確定性
認(rèn)知不確定性是我們模型中存在的不確定性。就拿我們文章一開始舉的例子來說,假設(shè)我們訓(xùn)練一個(gè)分類人臉和猩猩臉的模型,訓(xùn)練中沒有做任何的增強(qiáng),也就是說沒有做數(shù)據(jù)集的旋轉(zhuǎn),模糊等操作。如果我給模型一個(gè)正常的人臉,或者是正常猩猩的臉,我們的模型應(yīng)該對(duì)他所產(chǎn)生的結(jié)果的置信度很高。但是如果我給他貓的照片,一個(gè)模糊處理過得人臉,或者旋轉(zhuǎn)90°的猩猩臉,模型的置信度應(yīng)該會(huì)特別低。換句話說,認(rèn)知不確定性測(cè)量的,是我們的input data是否存在于已經(jīng)見過的數(shù)據(jù)的分布之中。
認(rèn)知不確定性可以通過增加更多的data來緩解,偶然不確定性則需要對(duì)數(shù)據(jù)進(jìn)行統(tǒng)一標(biāo)準(zhǔn)的處理。
偶然不確定性又存在兩種不確定性類別:
(補(bǔ)充:異方差和同方差,以經(jīng)典的線性回歸為例,我們常常假設(shè)線性回歸的誤差項(xiàng)滿足同方差,即誤差項(xiàng)的方差是相同的,如果不相同則為異方差,一個(gè)比較形象的例子:
什么是異方差?為什么異方差的出現(xiàn)通常與模型中某個(gè)解釋變量的變化有關(guān)?
https://www.zhihu.com/question/354637231/answer/895286217
1 數(shù)據(jù)依賴性(異方差不確定性)依賴于輸入數(shù)據(jù),模型預(yù)測(cè)結(jié)果的殘差的方差即隨著數(shù)據(jù)的輸入發(fā)生變化;
2、任務(wù)依賴性(同方差不確定性)是不依賴于輸入數(shù)據(jù)的任意不確定性,它與模型輸出無關(guān),是一個(gè)在所有輸入數(shù)據(jù)保持不變的情況下,在不同任務(wù)之間變化的量,因此,它可以被描述為與任務(wù)相關(guān)的不確定性,但是作者并沒有詳細(xì)解釋在多任務(wù)深度學(xué)習(xí)中的同方差不確定性的嚴(yán)格定義,而是認(rèn)為同方差不確定性是由于任務(wù)相關(guān)的權(quán)重引起的。
下面我們定義fW(x)為nn的預(yù)測(cè)值,也就是我們熟悉的y_pred,
對(duì)于回歸型任務(wù),我們定義下面的不確定性:
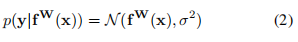
其中 在代碼中的體現(xiàn),是一個(gè)可學(xué)習(xí)的參數(shù),我們用這個(gè)參數(shù)服從的公式2的高斯分布作為同方差不確定性的衡量方法,即以 y_pred為均值向量,**2 作為方差的多元高斯分布;
對(duì)于分類問題有:
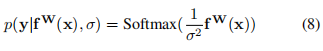
這被稱作是Boltzmann分布,也叫做吉布斯分布.
則在多目標(biāo)的前提下,我們認(rèn)為總的同方差不確定性可以用不同任務(wù)的不確定性的乘積來表示:
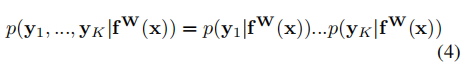
通過對(duì)公式(4)進(jìn)行對(duì)數(shù)變換后可以得到:
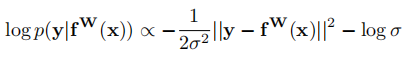
(這個(gè)正比的公式是怎么得到的。。。)
現(xiàn)在讓我們假設(shè)我們的模型輸出由兩個(gè)向量y1和y2組成,每個(gè)向量都遵循一個(gè)高斯分布:
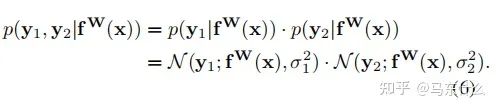
(這里作者沒有說清楚,實(shí)際上這里作者是假設(shè)我們有兩個(gè)回歸型的目標(biāo)任務(wù),并且損失函數(shù)使用的是mse)
然后得到多輸出模型的最小化目標(biāo)函數(shù) L(W、σ1、σ2):

因此,對(duì)于公式(7),在新的回歸型任務(wù)中,我們可以將L1(W)和L2(W)用其它的回歸任務(wù)對(duì)應(yīng)的損失函數(shù)來代替;
對(duì)于分類型任務(wù),作者木有給出最終的化簡(jiǎn)公式,不過對(duì)照下面的一個(gè)分類型任務(wù)+一個(gè)回歸型任務(wù)的化簡(jiǎn)公式:
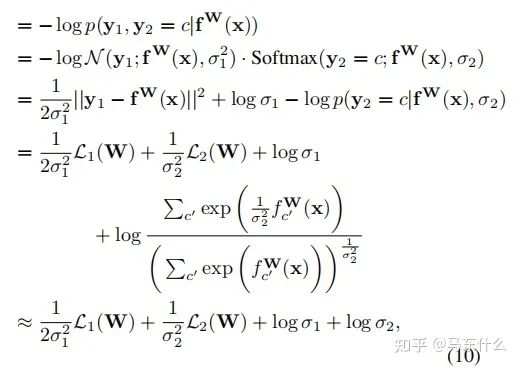
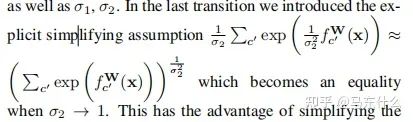
這里補(bǔ)充一下公式10的推導(dǎo)部分,具體的近似在上圖,將上圖帶入公式10即可。至于這個(gè)近似公式怎么來的,我也沒看明白。。。有懂得大佬求指正一下
我們可以先推出單個(gè)回歸型任務(wù)的不確定性度量公式,從而得到分類型任務(wù)的同方差不確定性的近似衡量公式為:
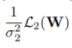
和

的和。
則也可以如法炮制,比較容易地寫出兩個(gè)分類型任務(wù)不確定性的化簡(jiǎn)公式了,簡(jiǎn)單來看就是分母少了2.(推導(dǎo)部分太頭大了就不看了)
這種構(gòu)造可以簡(jiǎn)單地?cái)U(kuò)展到任意離散和連續(xù)損失函數(shù)的組合,允許我們以一種有原則和有充分根據(jù)的方式學(xué)習(xí)每一個(gè)損失的相對(duì)權(quán)重。這種損失是平滑可微的,并且分布形狀很好,使得任務(wù)權(quán)重不會(huì)收斂到零。相比之下,使用直接學(xué)習(xí)權(quán)值會(huì)導(dǎo)致快速收斂到零的權(quán)值。
總結(jié)一下,整體的思路就是用sigma來衡量同方差不確定性,同方差不確定性和任務(wù)有關(guān),同方差不確定性越高的任務(wù)則意味著模任務(wù)相關(guān)的輸出的噪聲越多,任務(wù)越難以學(xué)習(xí),因此在多任務(wù)模型訓(xùn)練的過程中,其對(duì)應(yīng)的sigma會(huì)增大,削弱這類任務(wù)的權(quán)重使得整體的多任務(wù)模型的訓(xùn)練更加順暢和有效。
在代碼實(shí)現(xiàn)上有個(gè)小問題,也是比較常見的實(shí)現(xiàn)和論文存在區(qū)別的地方:
yaringal/multi-task-learning-example
https://github.com/yaringal/multi-task-learning-example/blob/master/multi-task-learning-example-pytorch.ipynb
這個(gè)是原論文作者的實(shí)現(xiàn):基于兩個(gè)回歸型任務(wù),損失函數(shù)mse為前提下得到的
def criterion(y_pred, y_true, log_vars):loss = 0for i in range(len(y_pred)):precision = torch.exp(-log_vars[i])diff = (y_pred[i]-y_true[i])**2. ## mse loss functionloss += torch.sum(precision * diff + log_vars[i], -1)return torch.mean(loss)

原文提到了我們直接定義變量,這個(gè)變量是log(sigma的)(sigma表示的是方差,也就是下圖里面的那個(gè)二次項(xiàng)),這樣可以避免loss公式中除0的問題:
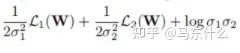
看了一下才發(fā)現(xiàn)這是萬惡的梯度下降法靈活的變量定義導(dǎo)致的,無論是torch還是tf中,變量為2x還是x都沒有區(qū)別,因?yàn)樽罱K常數(shù)項(xiàng)都可以直接融合到變量的求解中,所以之前看的很多的paper的實(shí)現(xiàn)里,常數(shù)項(xiàng)都是直接包含在變量里省去不寫。。真是屑,,,
首先我們定義 log(sigma)=a(a是一個(gè)可學(xué)習(xí)的變量),則 torch.exp(-a)=torch.exp(-log(sigma))=torch.exp(log(sigma**-1))=1/sigma(這里0.5可以省去也可以包含進(jìn)來,因?yàn)槲覀兌x1/2*變量x和直接定義變量x,在梯度下降法求解的過程中沒有太大區(qū)別,然后是常數(shù)項(xiàng)的部分,作者在原文中提到,后面的常數(shù)項(xiàng)并不是很重要,放進(jìn)來作為一種正則乘法太大的sigma(方差),這里后面的常數(shù)項(xiàng),按照代碼的意思,是直接用了sigma方差來代替了標(biāo)準(zhǔn)差,其實(shí)差別也不大)
所以根據(jù)上述的設(shè)定對(duì)下面的代碼做了一些修改:
git上對(duì)應(yīng)的代碼:
https://github.com/Mikoto10032/AutomaticWeightedLoss/blob/master/AutomaticWeightedLoss.py
找了幾個(gè)實(shí)現(xiàn),發(fā)現(xiàn)代碼都有問題,只有這個(gè)git是完全忠于原文的,并且封裝的也比較舒服。
import torchimport torch.nn as nnclass AutomaticWeightedLoss(nn.Module):"""automatically weighted multi-task lossParams:num: int,the number of lossx: multi-task lossExamples:loss1=1loss2=2awl = AutomaticWeightedLoss(2)loss_sum = awl(loss1, loss2)"""def __init__(self, num=2):super(AutomaticWeightedLoss, self).__init__()params = torch.ones(num, requires_grad=True)self.params = torch.nn.Parameter(params) #parameters的封裝使得變量可以容易訪問到def forward(self, *x):loss_sum = 0for i, loss in enumerate(x):loss_sum += 0.5 * torch.exp(-log_vars[i]) * loss + self.params[i]# +1避免了log 0的問題 log sigma部分對(duì)于整體loss的影響不大return loss_sum
關(guān)于權(quán)重項(xiàng)部分
目前看過的三個(gè)git上都沒有對(duì)分類或者是回歸的loss區(qū)別對(duì)待,可以設(shè)置參數(shù)用于定義分類or回歸loss,從而給權(quán)重項(xiàng)部分的分布分別賦予回歸—2,分類—1。很多作者這部分沒有嚴(yán)格按照論文公式來預(yù)測(cè),不過上面的code稍微改動(dòng)一下就可以,但是其實(shí)也不用改。。常數(shù)項(xiàng)在梯度下降的過程中都會(huì)被優(yōu)化算法考慮進(jìn)來的。
適配的話:
from torch import optimfrom AutomaticWeightedLoss import AutomaticWeightedLossmodel = Model()awl = AutomaticWeightedLoss(2) # we have 2 lossesloss_1 = ...loss_2 = ...# learnable parametersoptimizer = optim.Adam([{'params': model.parameters()},{'params': awl.parameters(), 'weight_decay': 0}])for i in range(epoch):for data, label1, label2 in data_loader:# forwardpred1, pred2 = Model(data)# calculate lossesloss1 = loss_1(pred1, label1)loss2 = loss_2(pred2, label2)# weigh lossesloss_sum = awl(loss1, loss2)# backwardoptimizer.zero_grad()loss_sum.backward()optimizer.step()
這種方法的一個(gè)比較核心的問題也比較明顯吧:
1、同方差不確定性衡量的定義方式是否合理;
2、如果在多任務(wù)學(xué)習(xí)中,我們主要是希望主任務(wù)的效果好,輔助任務(wù)的效果可能不是很care,那么如果恰好主任務(wù)是同方差不確定性最高的,則使用這種方法可能會(huì)削弱主任務(wù)的效果,這是最大的問題,因?yàn)檫@種處理的方式針對(duì)的是整個(gè)多任務(wù)模型的總體loss來設(shè)計(jì)的,無法滿足對(duì)特定任務(wù)的不同程度的需求,因?yàn)樽髡咴嫉乃悸肥遣淮_定性越高的任務(wù)越應(yīng)該削弱權(quán)重,但是反過來想,不確定性越高的任務(wù)越難,如果我們反而讓模型重點(diǎn)去學(xué)習(xí)這個(gè)任務(wù),是否可以提高模型的能力;
3、 這里沒有考慮權(quán)重和為1的問題,不過我覺得作者本來也沒打算這么做,影響不大,權(quán)重之和是否為1并不是問題其實(shí),本來多任務(wù)也不一定需要權(quán)重為1的設(shè)定,另外權(quán)重簡(jiǎn)單做歸一化就可以得到權(quán)重為1了。。
4、實(shí)際應(yīng)用的一個(gè)問題,權(quán)重可能會(huì)變成負(fù)數(shù),導(dǎo)致我們最終的loss變成負(fù)數(shù)了。。。也就是部分任務(wù)對(duì)于最終總loss的貢獻(xiàn)是負(fù)貢獻(xiàn),我認(rèn)為可能是這部分任務(wù)的不確定性太大使得模型訓(xùn)練困難,這個(gè)部分我們torch.relu進(jìn)行截?cái)嗑涂梢粤?/p>
2、Grad Norm
梯度歸一化的主要目的在于希望不同任務(wù)任務(wù)對(duì)應(yīng)的梯度具有相似的大小,從而控制多任務(wù)網(wǎng)絡(luò)的訓(xùn)練。通過這樣做,我們鼓勵(lì)網(wǎng)絡(luò)以相同的速度學(xué)習(xí)所有的任務(wù)。grad norm本身不focus于不同任務(wù)之間的權(quán)重,而是將所有任務(wù)等同視之,只是希望所有任務(wù)的更新能夠相對(duì)接近從而避免了某個(gè)任務(wù)收斂了,某個(gè)任務(wù)還在收斂的路上的問題,這樣會(huì)導(dǎo)致:
1、模型訓(xùn)練的效率低,最終運(yùn)行時(shí)間由最復(fù)雜的任務(wù)決定;
2、復(fù)雜任務(wù)收斂的過程中,簡(jiǎn)單任務(wù)的局部最優(yōu)權(quán)重可能會(huì)變差;
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!