
Flink 是如何統(tǒng)一批流引擎的
關(guān)注公眾號:大數(shù)據(jù)技術(shù)派,回復(fù)"資料",領(lǐng)取
1024G資料。
2015 年,F(xiàn)link 的作者就寫了 Apache Flink: Stream and Batch Processing in a Single Engine 這篇論文。本文以這篇論文為引導(dǎo),詳細(xì)講講 Flink 內(nèi)部是如何設(shè)計并實(shí)現(xiàn)批流一體的架構(gòu)。
前言
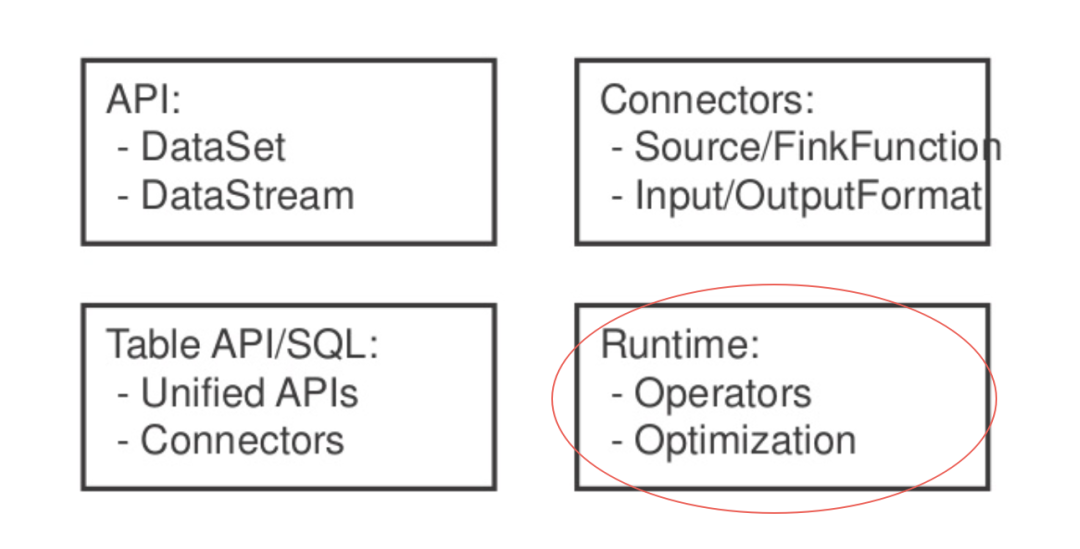
通常我們在 Flink 中說批流一體指的是這四個方向,其中 Runtime 便是 Flink 運(yùn)行時的實(shí)現(xiàn)。
數(shù)據(jù)交換模型
Flink 對于流作業(yè)和批作業(yè)有一個統(tǒng)一的執(zhí)行模型。
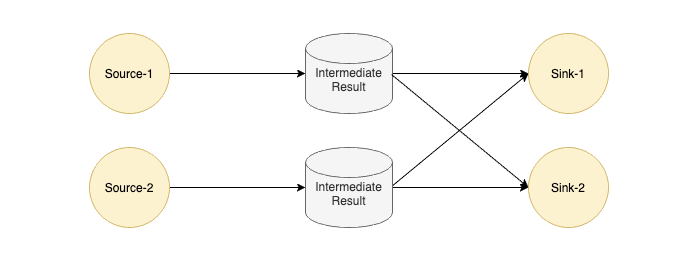
Flink 中每個 Task 的輸出會以 IntermediateResult 做封裝,內(nèi)部并沒有對流和批兩種作業(yè)做一個明確的劃分,只是通過不同類型的 IntermediateResult 來表達(dá) PIPELINED 和 BLOCKING 這兩大類數(shù)據(jù)交換模型。
在了解數(shù)據(jù)交換模型之前,我們來看下為什么 Flink 對作業(yè)類型不作區(qū)分,這樣的好處是什么?
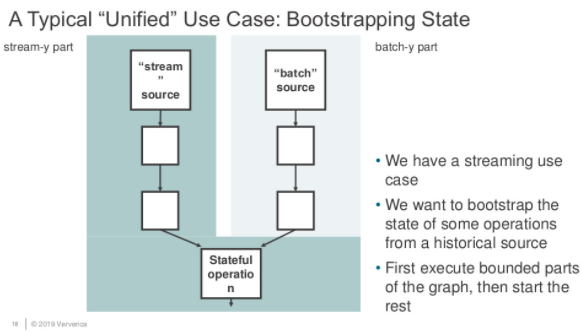
如上圖所示,假如我們有一個工作需要將批式作業(yè)執(zhí)行結(jié)果作為流式作業(yè)的啟動輸入,那怎么辦?這個作業(yè)是算批作業(yè)還是流作業(yè)?
很顯然,以我們的常識是無法定義的,而現(xiàn)有的工業(yè)界的辦法也是如此,將這個作業(yè)拆分為兩個作業(yè),先跑批式作業(yè),再跑流式作業(yè),這樣當(dāng)然可以,但是人工運(yùn)維的成本也是足夠大的:
需要一個外界存儲來管理批作業(yè)的輸出數(shù)據(jù)。 需要一個支持批流作業(yè)依賴的調(diào)度系統(tǒng)。
如果期望實(shí)現(xiàn)這樣一個作業(yè),那么首先執(zhí)行這個作業(yè)的計算引擎的作業(yè)屬性就不能對批作業(yè)和流作業(yè)進(jìn)行強(qiáng)綁定。那么 Flink 能否實(shí)現(xiàn)這樣的需求呢?我們先來看看數(shù)據(jù)交換的具體細(xì)節(jié),最后再來一起看看這個作業(yè)的可行性。
我們以 PIPELINED 數(shù)據(jù)交換模型為例,看看是如何設(shè)計的:
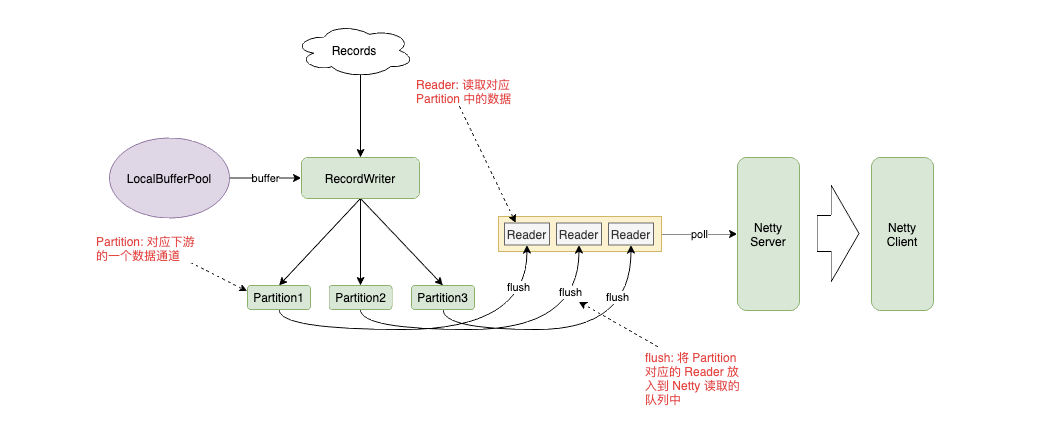
PIPELINED 模式下,RecordWriter 將數(shù)據(jù)放入到 Buffer 中,根據(jù) Key 的路由規(guī)則發(fā)送給對應(yīng)的 Partition,Partition 將自己的數(shù)據(jù)封裝到 Reader 中放入隊(duì)列,讓 Netty Server 從隊(duì)列中讀取數(shù)據(jù),發(fā)送給下游。
我們將數(shù)據(jù)交換模式改為 BLOCKING,會發(fā)現(xiàn)這個設(shè)計也是同樣可行的。Partition 將數(shù)據(jù)寫入到文件,而 Reader 中維護(hù)著文件的句柄,上游任務(wù)結(jié)束后調(diào)度下游任務(wù),而下游任務(wù)通過 Netty Client 的 Partition Request 喚醒對應(yīng)的 Partition 和 Reader,將數(shù)據(jù)拉到下游。
調(diào)度模型
有 LAZY 和 EAGER 兩種調(diào)度模型,默認(rèn)情況下流作業(yè)使用 EAGER,批作業(yè)使用 LAZY。
EAGER
這個很好理解,因?yàn)榱魇阶鳂I(yè)是 All or Nothing 的設(shè)計,要么所有 Task 都 Run 起來,要么就不跑。
LAZY
LAZY 模式就是先調(diào)度上游,等待上游產(chǎn)生數(shù)據(jù)或結(jié)束后再調(diào)度下游。有些類似 Spark 中的 Stage 執(zhí)行模式。
Region Scheduling
可以看到,不管是 EAGER 還是 LAZY 都沒有辦法執(zhí)行我們剛才提出的批流混合的任務(wù),于是社區(qū)提出了 Region Scheduling 來統(tǒng)一批流作業(yè)的調(diào)度,我們先看一下如何定義 Region:
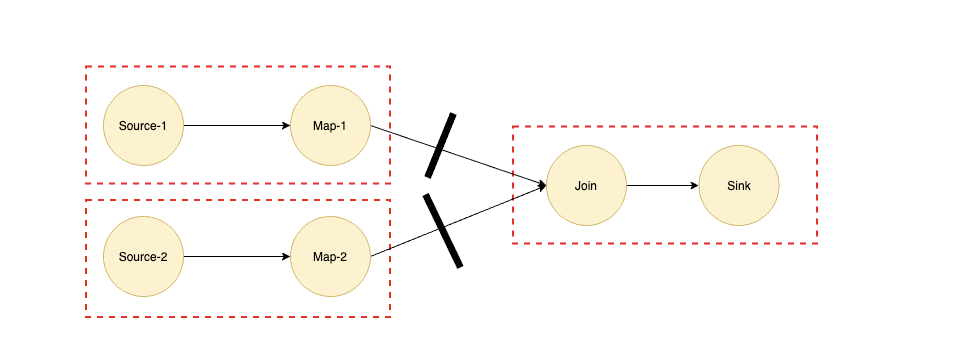
以 Join 算子為例,我們都知道如果 Join 算子的兩個輸入都是海量數(shù)據(jù)的話,那么我們是需要等兩個輸入的數(shù)據(jù)都完全準(zhǔn)備好才能進(jìn)行 Join 操作的,所以 Join 兩條輸入的邊對應(yīng)的數(shù)據(jù)交換模式對應(yīng)的應(yīng)該是 BLOCKING 模式,我們可以根據(jù) BLOCKING 的邊將作業(yè)劃分為多個子 Region,如上圖虛線所示。
如果實(shí)現(xiàn)了 Region Scheduling 之后,我們在上面提到的批流混合的作業(yè)就可以將深色部分流式作業(yè)劃為一個 Region,淺色部分批式作業(yè)再劃分為多個 Region,而淺色部分是深色部分 Region 的輸入,所以根據(jù) Region Scheduling 的原則會優(yōu)先調(diào)度最前面的 Region。
總結(jié)
上面提到了數(shù)據(jù)交換模型和調(diào)度模型,簡單來講其實(shí)就兩句話:
1 實(shí)現(xiàn)了用 PIPELINED 模型去跑批式作業(yè)
用 PIPELINED 模型跑流式作業(yè)和用 BLOCKING 模型跑批式作業(yè)都是沒有什么新奇的。這里提到用 PIPELINED 模式跑批作業(yè),主要是針對實(shí)時分析的場景,以 Spark 為例,在大部分出現(xiàn) Shuffle 或是聚合的場景下都會出現(xiàn)落盤的行為,并且調(diào)度順序是一個一個 Stage 進(jìn)行調(diào)度,極大地降低了數(shù)據(jù)處理的實(shí)時性,而使用 PIPELINED 模式會對性能有一定提升。
可能有人會問類似 Join 的算子如何使用 PIPELINED 數(shù)據(jù)交換模型實(shí)現(xiàn)不落盤的操作?事實(shí)上 Flink 也會落盤,只不過不是在 Join 的兩個輸入端落盤,而是將兩個輸入端的數(shù)據(jù)傳輸?shù)?Join 算子上,內(nèi)存撐不住時再進(jìn)行落盤,海量數(shù)據(jù)下和 Spark 的行為并沒有本質(zhì)區(qū)別,但是在數(shù)據(jù)量中等,內(nèi)存可容納的情況下會帶來很大的收益。
2 集成了一部分調(diào)度系統(tǒng)的功能
根據(jù) Region 來調(diào)度作業(yè)時,Region 內(nèi)部跑的具體是流作業(yè)還是批作業(yè),F(xiàn)link 自身是不關(guān)心的,更關(guān)心的 Region 之間的依賴關(guān)系,一定程度上,利用這種調(diào)度模型我們可以將過去需要拆分為多個作業(yè)的執(zhí)行模式放到一個作業(yè)中來執(zhí)行,比如上面提到的批流混合的作業(yè)。
猜你喜歡
Spark SQL知識點(diǎn)與實(shí)戰(zhàn)
Hive計算最大連續(xù)登陸天數(shù)
Hadoop 數(shù)據(jù)遷移用法詳解
Hbase修復(fù)工具Hbck
數(shù)倉建模分層理論
大數(shù)據(jù)組件重點(diǎn)學(xué)習(xí)這幾個